0777cc26aa
58 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
ecccd57417
|
Generic system config (#17962)
# Objective Prevents duplicate implementation between IntoSystemConfigs and IntoSystemSetConfigs using a generic, adds a NodeType trait for more config flexibility (opening the door to implement https://github.com/bevyengine/bevy/issues/14195?). ## Solution Followed writeup by @ItsDoot: https://hackmd.io/@doot/rJeefFHc1x Removes IntoSystemConfigs and IntoSystemSetConfigs, instead using IntoNodeConfigs with generics. ## Testing Pending --- ## Showcase N/A ## Migration Guide SystemSetConfigs -> NodeConfigs<InternedSystemSet> SystemConfigs -> NodeConfigs<ScheduleSystem> IntoSystemSetConfigs -> IntoNodeConfigs<InternedSystemSet, M> IntoSystemConfigs -> IntoNodeConfigs<ScheduleSystem, M> --------- Co-authored-by: Christian Hughes <9044780+ItsDoot@users.noreply.github.com> Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
8570af1d96
|
Add print_stdout and print_stderr lints (#17446) (#18233)
# Objective - Prevent usage of `println!`, `eprintln!` and the like because they require `std` - Fixes #17446 ## Solution - Enable the `print_stdout` and `print_stderr` clippy lints - Replace all `println!` and `eprintln!` occurrences with `log::*` where applicable or alternatively ignore the warnings ## Testing - Run `cargo clippy --workspace` to ensure that there are no warnings relating to printing to `stdout` or `stderr` |
||
|
|
246ce590e5
|
Queued component registration (#18173)
# Objective This is an alternative to #17871 and #17701 for tracking issue #18155. This thanks to @maniwani for help with this design. The goal is to enable component ids to be reserved from multiple threads concurrently and with only `&World`. This contributes to assets as entities, read-only query and system parameter initialization, etc. ## What's wrong with #17871 ? In #17871, I used my proposed staging utilities to allow *fully* registering components from any thread concurrently with only `&Components`. However, if we want to pursue components as entities (which is desirable for a great many reasons. See [here](https://discord.com/channels/691052431525675048/692572690833473578/1346499196655505534) on discord), this staging isn't going to work. After all, if registering a component requires spawning an entity, and spawning an entity requires `&mut World`, it is impossible to register a component fully with only `&World`. ## Solution But what if we don't have to register it all the way? What if it's enough to just know the `ComponentId` it will have once it is registered and to queue it to be registered at a later time? Spoiler alert: That is all we need for these features. Here's the basic design: Queue a registration: 1. Check if it has already been registered. 2. Check if it has already been queued. 3. Reserve a `ComponentId`. 4. Queue the registration at that id. Direct (normal) registration: 1. Check if this registration has been queued. 2. If it has, use the queued registration instead. 3. Otherwise, proceed like normal. Appllying the queue: 1. Pop queued items off one by one. 2. Register them directly. One other change: The whole point of this design over #17871 is to facilitate coupling component registration with the World. To ensure that this would fully work with that, I went ahead and moved the `ComponentId` generator onto the world itself. That stemmed a couple of minor organizational changes (see migration guide). As we do components as entities, we will replace this generator with `Entities`, which lives on `World` too. Doing this move early let me verify the design and will reduce migration headaches in the future. If components as entities is as close as I think it is, I don't think splitting this up into different PRs is worth it. If it is not as close as it is, it might make sense to still do #17871 in the meantime (see the risks section). I'll leave it up to y'all what we end up doing though. ## Risks and Testing The biggest downside of this compared to #17871 is that now we have to deal with correct but invalid `ComponentId`s. They are invalid because the component still isn't registered, but they are correct because, once registered, the component will have exactly that id. However, the only time this becomes a problem is if some code violates safety rules by queuing a registration and using the returned id as if it was valid. As this is a new feature though, nothing in Bevy does this, so no new tests were added for it. When we do use it, I left detailed docs to help mitigate issues here, and we can test those usages. Ex: we will want some tests on using queries initialized from queued registrations. ## Migration Guide Component registration can now be queued with only `&World`. To facilitate this, a few APIs needed to be moved around. The following functions have moved from `Components` to `ComponentsRegistrator`: - `register_component` - `register_component_with_descriptor` - `register_resource_with_descriptor` - `register_non_send` - `register_resource` - `register_required_components_manual` Accordingly, functions in `Bundle` and `Component` now take `ComponentsRegistrator` instead of `Components`. You can obtain `ComponentsRegistrator` from the new `World::components_registrator`. You can obtain `ComponentsQueuedRegistrator` from the new `World::components_queue`, and use it to stage component registration if desired. # Open Question Can we verify that it is enough to queue registration with `&World`? I don't think it would be too difficult to package this up into a `Arc<MyComponentsManager>` type thing if we need to, but keeping this on `&World` certainly simplifies things. If we do need the `Arc`, we'll need to look into partitioning `Entities` for components as entities, so we can keep most of the allocation fast on `World` and only keep a smaller partition in the `Arc`. I'd love an SME on assets as entities to shed some light on this. --------- Co-authored-by: andriyDev <andriydzikh@gmail.com> |
||
|
|
5bc1d68a65
|
Deprecated Query::many and many_mut (#18183)
# Objective Alternative to and closes #18120. Sibling to #18082, see that PR for broader reasoning. Folks weren't sold on the name `many` (get_many is clearer, and this is rare), and that PR is much more complex. ## Solution - Simply deprecate `Query::many` and `Query::many_mut` - Clean up internal usages Mentions of this in the docs can wait until it's fully removed in the 0.17 cycle IMO: it's much easier to catch the problems when doing that. ## Testing CI! ## Migration Guide `Query::many` and `Query::many_mut` have been deprecated to reduce panics and API duplication. Use `Query::get_many` and `Query::get_many_mut` instead, and handle the `Result`. --------- Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com> |
||
|
|
1f6642df4c
|
Fix unsound query transmutes on queries obtained from Query::as_readonly() (#17973)
# Objective
Fix unsound query transmutes on queries obtained from
`Query::as_readonly()`.
The following compiles, and the call to `transmute_lens()` should panic,
but does not:
```rust
fn bad_system(query: Query<&mut A>) {
let mut readonly = query.as_readonly();
let mut lens: QueryLens<&mut A> = readonly.transmute_lens();
let other_readonly: Query<&A> = query.as_readonly();
// `lens` and `other_readonly` alias, and are both alive here!
}
```
To make `Query::as_readonly()` zero-cost, we pointer-cast
`&QueryState<D, F>` to `&QueryState<D::ReadOnly, F>`. This means that
the `component_access` for a read-only query's state may include
accesses for the original mutable version, but the `Query` does not have
exclusive access to those components! `transmute` and `join` use that
access to ensure that a join is valid, and will incorrectly allow a
transmute that includes mutable access.
As a bonus, allow `Query::join`s that output `FilteredEntityRef` or
`FilteredEntityMut` to receive access from the `other` query. Currently
they only receive access from `self`.
## Solution
When transmuting or joining from a read-only query, remove any writes
before performing checking that the transmute is valid. For joins, be
sure to handle the case where one input query was the result of
`as_readonly()` but the other has valid mutable access.
This requires identifying read-only queries, so add a
`QueryData::IS_READ_ONLY` associated constant. Note that we only call
`QueryState::as_transmuted_state()` with `NewD: ReadOnlyQueryData`, so
checking for read-only queries is sufficient to check for
`as_transmuted_state()`.
Removing writes requires allocating a new `FilteredAccess`, so only do
so if the query is read-only and the state has writes. Otherwise, the
existing access is correct and we can continue using a reference to it.
Use the new read-only state to call `NewD::set_access`, so that
transmuting to a `FilteredAccessMut` results in a read-only
`FilteredAccessMut`. Otherwise, it would take the original write access,
and then the transmute would panic because it had too much access.
Note that `join` was previously passing `self.component_access` to
`NewD::set_access`. Switching it to `joined_component_access` also
allows a join that outputs `FilteredEntity(Ref|Mut)` to receive access
from `other`. The fact that it didn't do that before seems like an
oversight, so I didn't try to prevent that change.
## Testing
Added unit tests with the unsound transmute and join.
|
||
|
|
2ad5908e58
|
Make Query::single (and friends) return a Result (#18082)
# Objective As discussed in #14275, Bevy is currently too prone to panic, and makes the easy / beginner-friendly way to do a large number of operations just to panic on failure. This is seriously frustrating in library code, but also slows down development, as many of the `Query::single` panics can actually safely be an early return (these panics are often due to a small ordering issue or a change in game state. More critically, in most "finished" products, panics are unacceptable: any unexpected failures should be handled elsewhere. That's where the new With the advent of good system error handling, we can now remove this. Note: I was instrumental in a) introducing this idea in the first place and b) pushing to make the panicking variant the default. The introduction of both `let else` statements in Rust and the fancy system error handling work in 0.16 have changed my mind on the right balance here. ## Solution 1. Make `Query::single` and `Query::single_mut` (and other random related methods) return a `Result`. 2. Handle all of Bevy's internal usage of these APIs. 3. Deprecate `Query::get_single` and friends, since we've moved their functionality to the nice names. 4. Add detailed advice on how to best handle these errors. Generally I like the diff here, although `get_single().unwrap()` in tests is a bit of a downgrade. ## Testing I've done a global search for `.single` to track down any missed deprecated usages. As to whether or not all the migrations were successful, that's what CI is for :) ## Future work ~~Rename `Query::get_single` and friends to `Query::single`!~~ ~~I've opted not to do this in this PR, and smear it across two releases in order to ease the migration. Successive deprecations are much easier to manage than the semantics and types shifting under your feet.~~ Cart has convinced me to change my mind on this; see https://github.com/bevyengine/bevy/pull/18082#discussion_r1974536085. ## Migration guide `Query::single`, `Query::single_mut` and their `QueryState` equivalents now return a `Result`. Generally, you'll want to: 1. Use Bevy 0.16's system error handling to return a `Result` using the `?` operator. 2. Use a `let else Ok(data)` block to early return if it's an expected failure. 3. Use `unwrap()` or `Ok` destructuring inside of tests. The old `Query::get_single` (etc) methods which did this have been deprecated. |
||
|
|
c34a2c2fba
|
Query::get_many should not check for duplicates (#17724)
# Objective Restore the behavior of `Query::get_many` prior to #15858. When passed duplicate `Entity`s, `get_many` is supposed to return results for all of them, since read-only queries don't alias. However, #15858 merged the implementation with `get_many_mut` and caused it to return `QueryEntityError::AliasedMutability`. ## Solution Introduce a new `Query::get_many_readonly` method that consumes the `Query` like `get_many_inner`, but that is constrained to `D: ReadOnlyQueryData` so that it can skip the aliasing check. Implement `Query::get_many` in terms of that new method. Add a test, and a comment explaining why it doesn't match the pattern of the other `&self` methods. |
||
|
|
1b7db895b7
|
Harden proc macro path resolution and add integration tests. (#17330)
This pr uses the `extern crate self as` trick to make proc macros behave the same way inside and outside bevy. # Objective - Removes noise introduced by `crate as` in the whole bevy repo. - Fixes #17004. - Hardens proc macro path resolution. ## TODO - [x] `BevyManifest` needs cleanup. - [x] Cleanup remaining `crate as`. - [x] Add proper integration tests to the ci. ## Notes - `cargo-manifest-proc-macros` is written by me and based/inspired by the old `BevyManifest` implementation and [`bkchr/proc-macro-crate`](https://github.com/bkchr/proc-macro-crate). - What do you think about the new integration test machinery I added to the `ci`? More and better integration tests can be added at a later stage. The goal of these integration tests is to simulate an actual separate crate that uses bevy. Ideally they would lightly touch all bevy crates. ## Testing - Needs RA test - Needs testing from other users - Others need to run at least `cargo run -p ci integration-test` and verify that they work. --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
03af547c28
|
Move Item and fetch to QueryData from WorldQuery (#17679)
# Objective Fixes #17662 ## Solution Moved `Item` and `fetch` from `WorldQuery` to `QueryData`, and adjusted their implementations accordingly. Currently, documentation related to `fetch` is written under `WorldQuery`. It would be more appropriate to move it to the `QueryData` documentation for clarity. I am not very experienced with making contributions. If there are any mistakes or areas for improvement, I would appreciate any suggestions you may have. ## Migration Guide The `WorldQuery::Item` type and `WorldQuery::fetch` method have been moved to `QueryData`, as they were not useful for `QueryFilter` types. --------- Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com> |
||
|
|
b30ee2d051
|
Disallow requesting write resource access in Queries (#17116)
Related to https://github.com/bevyengine/bevy/pull/16843 Since `WorldQuery::Fetch` is `Clone`, it can't store mutable references to resources, so it doesn't make sense to mutably access resources. In that sense, it is hard to find usecases of mutably accessing resources and to clearly define, what mutably accessing resources would mean, so it's been decided to disallow write resource access. Also changed documentation of safety requirements of `WorldQuery::init_fetch` and `WorldQuery::fetch` to clearly state to the caller, what safety invariants they need to uphold. |
||
|
|
0403948aa2
|
Remove Implicit std Prelude from no_std Crates (#17086)
# Background In `no_std` compatible crates, there is often an `std` feature which will allow access to the standard library. Currently, with the `std` feature _enabled_, the [`std::prelude`](https://doc.rust-lang.org/std/prelude/index.html) is implicitly imported in all modules. With the feature _disabled_, instead the [`core::prelude`](https://doc.rust-lang.org/core/prelude/index.html) is implicitly imported. This creates a subtle and pervasive issue where `alloc` items _may_ be implicitly included (if `std` is enabled), or must be explicitly included (if `std` is not enabled). # Objective - Make the implicit imports for `no_std` crates consistent regardless of what features are/not enabled. ## Solution - Replace the `cfg_attr` "double negative" `no_std` attribute with conditional compilation to _include_ `std` as an external crate. ```rust // Before #![cfg_attr(not(feature = "std"), no_std)] // After #![no_std] #[cfg(feature = "std")] extern crate std; ``` - Fix imports that are currently broken but are only now visible with the above fix. ## Testing - CI ## Notes I had previously used the "double negative" version of `no_std` based on general consensus that it was "cleaner" within the Rust embedded community. However, this implicit prelude issue likely was considered when forming this consensus. I believe the reason why is the items most affected by this issue are provided by the `alloc` crate, which is rarely used within embedded but extensively used within Bevy. |
||
|
|
5f4b5a37f1
|
Support declaring resource access in Queries. (#16843)
# Objective Allow resources to be accessed soundly by `QueryData` and `QueryFilter` implementations. This mostly works today, and is used in `bevy-trait-query` and will be used by #16810. The problem is that the access is not made visible to the executor, so it would be possible for a system with resource access in a query to run concurrently with a system that accesses the resource with `ResMut`, resulting in Undefined Behavior. ## Solution Define calling `add_resource_read` or `add_resource_write` in `WorldQuery::update_component_access` to be a supported way to declare resource access in a query. Modify `QueryState::new_with_access` to check for resource access and report it in `archetype_component_acccess`. Modify `FilteredAccess::is_compatible` to consider resource access conflicting even on queries with disjoint filters. |
||
|
|
d70595b667
|
Add core and alloc over std Lints (#15281)
# Objective - Fixes #6370 - Closes #6581 ## Solution - Added the following lints to the workspace: - `std_instead_of_core` - `std_instead_of_alloc` - `alloc_instead_of_core` - Used `cargo +nightly fmt` with [item level use formatting](https://rust-lang.github.io/rustfmt/?version=v1.6.0&search=#Item%5C%3A) to split all `use` statements into single items. - Used `cargo clippy --workspace --all-targets --all-features --fix --allow-dirty` to _attempt_ to resolve the new linting issues, and intervened where the lint was unable to resolve the issue automatically (usually due to needing an `extern crate alloc;` statement in a crate root). - Manually removed certain uses of `std` where negative feature gating prevented `--all-features` from finding the offending uses. - Used `cargo +nightly fmt` with [crate level use formatting](https://rust-lang.github.io/rustfmt/?version=v1.6.0&search=#Crate%5C%3A) to re-merge all `use` statements matching Bevy's previous styling. - Manually fixed cases where the `fmt` tool could not re-merge `use` statements due to conditional compilation attributes. ## Testing - Ran CI locally ## Migration Guide The MSRV is now 1.81. Please update to this version or higher. ## Notes - This is a _massive_ change to try and push through, which is why I've outlined the semi-automatic steps I used to create this PR, in case this fails and someone else tries again in the future. - Making this change has no impact on user code, but does mean Bevy contributors will be warned to use `core` and `alloc` instead of `std` where possible. - This lint is a critical first step towards investigating `no_std` options for Bevy. --------- Co-authored-by: François Mockers <francois.mockers@vleue.com> |
||
|
|
efda7f3f9c
|
Simpler lint fixes: makes ci lints work but disables a lint for now (#15376)
Takes the first two commits from #15375 and adds suggestions from this comment: https://github.com/bevyengine/bevy/pull/15375#issuecomment-2366968300 See #15375 for more reasoning/motivation. ## Rebasing (rerunning) ```rust git switch simpler-lint-fixes git reset --hard main cargo fmt --all -- --unstable-features --config normalize_comments=true,imports_granularity=Crate cargo fmt --all git add --update git commit --message "rustfmt" cargo clippy --workspace --all-targets --all-features --fix cargo fmt --all -- --unstable-features --config normalize_comments=true,imports_granularity=Crate cargo fmt --all git add --update git commit --message "clippy" git cherry-pick e6c0b94f6795222310fb812fa5c4512661fc7887 ``` |
||
|
|
9bda913e36
|
Remove redundent information and optimize dynamic allocations in Table (#12929)
# Objective - fix #12853 - Make `Table::allocate` faster ## Solution The PR consists of multiple steps: 1) For the component data: create a new data-structure that's similar to `BlobVec` but doesn't store `len` & `capacity` inside of it: "BlobArray" (name suggestions welcome) 2) For the `Tick` data: create a new data-structure that's similar to `ThinSlicePtr` but supports dynamic reallocation: "ThinArrayPtr" (name suggestions welcome) 3) Create a new data-structure that's very similar to `Column` that doesn't store `len` & `capacity` inside of it: "ThinColumn" 4) Adjust the `Table` implementation to use `ThinColumn` instead of `Column` The result is that only one set of `len` & `capacity` is stored in `Table`, in `Table::entities` ### Notes Regarding Performance Apart from shaving off some excess memory in `Table`, the changes have also brought noteworthy performance improvements: The previous implementation relied on `Vec::reserve` & `BlobVec::reserve`, but that redundantly repeated the same if statement (`capacity` == `len`). Now that check could be made at the `Table` level because the capacity and length of all the columns are synchronized; saving N branches per allocation. The result is a respectable performance improvement per every `Table::reserve` (and subsequently `Table::allocate`) call. I'm hesitant to give exact numbers because I don't have a lot of experience in profiling and benchmarking, but these are the results I got so far: *`add_remove_big/table` benchmark after the implementation:*  *`add_remove_big/table` benchmark in main branch (measured in comparison to the implementation):*  *`add_remove_very_big/table` benchmark after the implementation:*  *`add_remove_very_big/table` benchmark in main branch (measured in comparison to the implementation):*  cc @james7132 to verify --- ## Changelog - New data-structure that's similar to `BlobVec` but doesn't store `len` & `capacity` inside of it: `BlobArray` - New data-structure that's similar to `ThinSlicePtr` but supports dynamic allocation:`ThinArrayPtr` - New data-structure that's very similar to `Column` that doesn't store `len` & `capacity` inside of it: `ThinColumn` - Adjust the `Table` implementation to use `ThinColumn` instead of `Column` - New benchmark: `add_remove_very_big` to benchmark the performance of spawning a lot of entities with a lot of components (15) each ## Migration Guide `Table` now uses `ThinColumn` instead of `Column`. That means that methods that previously returned `Column`, will now return `ThinColumn` instead. `ThinColumn` has a much more limited and low-level API, but you can still achieve the same things in `ThinColumn` as you did in `Column`. For example, instead of calling `Column::get_added_tick`, you'd call `ThinColumn::get_added_ticks_slice` and index it to get the specific added tick. --------- Co-authored-by: James Liu <contact@jamessliu.com> |
||
|
|
e490b919df
|
inline iter_combinations (#14680)
# Objective - fix #14679 - bevy's performance highly depends on compiler optimization,inline hot function could greatly help compiler to optimize our program |
||
|
|
ec4cf024f8
|
Add a ComponentIndex and update QueryState creation/update to use it (#13460)
# Objective
To implement relations we will need to add a `ComponentIndex`, which is
a map from a Component to the list of archetypes that contain this
component.
One of the reasons is that with fragmenting relations the number of
archetypes will explode, so it will become inefficient to create and
update the query caches by iterating through the list of all archetypes.
In this PR, we introduce the `ComponentIndex`, and we update the
`QueryState` to make use of it:
- if a query has at least 1 required component (i.e. something other
than `()`, `Entity` or `Option<>`, etc.): for each of the required
components we find the list of archetypes that contain it (using the
ComponentIndex). Then, we select the smallest list among these. This
gives a small subset of archetypes to iterate through compared with
iterating through all new archetypes
- if it doesn't, then we keep using the current approach of iterating
through all new archetypes
# Implementation
- This breaks query iteration order, in the sense that we are not
guaranteed anymore to return results in the order in which the
archetypes were created. I think this should be fine because this wasn't
an explicit bevy guarantee so users should not be relying on this. I
updated a bunch of unit tests that were failing because of this.
- I had an issue with the borrow checker because iterating the list of
potential archetypes requires access to `&state.component_access`, which
was conflicting with the calls to
```
if state.new_archetype_internal(archetype) {
state.update_archetype_component_access(archetype, access);
}
```
which need a mutable access to the state.
The solution I chose was to introduce a `QueryStateView` which is a
temporary view into the `QueryState` which enables a "split-borrows"
kind of approach. It is described in detail in this blog post:
https://smallcultfollowing.com/babysteps/blog/2018/11/01/after-nll-interprocedural-conflicts/
# Test
The unit tests pass.
Benchmark results:
```
❯ critcmp main pr
group main pr
----- ---- --
iter_fragmented/base 1.00 342.2±25.45ns ? ?/sec 1.02 347.5±16.24ns ? ?/sec
iter_fragmented/foreach 1.04 165.4±11.29ns ? ?/sec 1.00 159.5±4.27ns ? ?/sec
iter_fragmented/foreach_wide 1.03 3.3±0.04µs ? ?/sec 1.00 3.2±0.06µs ? ?/sec
iter_fragmented/wide 1.03 3.1±0.06µs ? ?/sec 1.00 3.0±0.08µs ? ?/sec
iter_fragmented_sparse/base 1.00 6.5±0.14ns ? ?/sec 1.02 6.6±0.08ns ? ?/sec
iter_fragmented_sparse/foreach 1.00 6.3±0.08ns ? ?/sec 1.04 6.6±0.08ns ? ?/sec
iter_fragmented_sparse/foreach_wide 1.00 43.8±0.15ns ? ?/sec 1.02 44.6±0.53ns ? ?/sec
iter_fragmented_sparse/wide 1.00 29.8±0.44ns ? ?/sec 1.00 29.8±0.26ns ? ?/sec
iter_simple/base 1.00 8.2±0.10µs ? ?/sec 1.00 8.2±0.09µs ? ?/sec
iter_simple/foreach 1.00 3.8±0.02µs ? ?/sec 1.02 3.9±0.03µs ? ?/sec
iter_simple/foreach_sparse_set 1.00 19.0±0.26µs ? ?/sec 1.01 19.3±0.16µs ? ?/sec
iter_simple/foreach_wide 1.00 17.8±0.24µs ? ?/sec 1.00 17.9±0.31µs ? ?/sec
iter_simple/foreach_wide_sparse_set 1.06 95.6±6.23µs ? ?/sec 1.00 90.6±0.59µs ? ?/sec
iter_simple/sparse_set 1.00 19.3±1.63µs ? ?/sec 1.01 19.5±0.29µs ? ?/sec
iter_simple/system 1.00 8.1±0.10µs ? ?/sec 1.00 8.1±0.09µs ? ?/sec
iter_simple/wide 1.05 37.7±2.53µs ? ?/sec 1.00 35.8±0.57µs ? ?/sec
iter_simple/wide_sparse_set 1.00 95.7±1.62µs ? ?/sec 1.00 95.9±0.76µs ? ?/sec
par_iter_simple/with_0_fragment 1.04 35.0±2.51µs ? ?/sec 1.00 33.7±0.49µs ? ?/sec
par_iter_simple/with_1000_fragment 1.00 50.4±2.52µs ? ?/sec 1.01 51.0±3.84µs ? ?/sec
par_iter_simple/with_100_fragment 1.02 40.3±2.23µs ? ?/sec 1.00 39.5±1.32µs ? ?/sec
par_iter_simple/with_10_fragment 1.14 38.8±7.79µs ? ?/sec 1.00 34.0±0.78µs ? ?/sec
```
|
||
|
|
bc82749012
|
Remove APIs deprecated in 0.13 (#11974)
# Objective We deprecated quite a few APIs in 0.13. 0.13 has shipped already. It should be OK to remove them in 0.14's release. Fixes #4059. Fixes #9011. ## Solution Remove them. |
||
|
|
1974723a63
|
Deprecated Various Component Methods from Query and QueryState (#9920)
# Objective - (Partially) Fixes #9904 - Acts on #9910 ## Solution - Deprecated the relevant methods from `Query`, cascading changes as required across Bevy. --- ## Changelog - Deprecated `QueryState::get_component_unchecked_mut` method - Deprecated `Query::get_component` method - Deprecated `Query::get_component_mut` method - Deprecated `Query::component` method - Deprecated `Query::component_mut` method - Deprecated `Query::get_component_unchecked_mut` method ## Migration Guide ### `QueryState::get_component_unchecked_mut` Use `QueryState::get_unchecked_manual` and select for the exact component based on the structure of the exact query as required. ### `Query::(get_)component(_unchecked)(_mut)` Use `Query::get` and select for the exact component based on the structure of the exact query as required. - For mutable access (`_mut`), use `Query::get_mut` - For unchecked access (`_unchecked`), use `Query::get_unchecked` - For panic variants (non-`get_`), add `.unwrap()` ## Notes - `QueryComponentError` can be removed once these deprecated methods are also removed. Due to an interaction with `thiserror`'s derive macro, it is not marked as deprecated. |
||
|
|
ea42d14344
|
Dynamic queries and builder API (#9774)
# Objective Expand the existing `Query` API to support more dynamic use cases i.e. scripting. ## Prior Art - #6390 - #8308 - #10037 ## Solution - Create a `QueryBuilder` with runtime methods to define the set of component accesses for a built query. - Create new `WorldQueryData` implementations `FilteredEntityMut` and `FilteredEntityRef` as variants of `EntityMut` and `EntityRef` that provide run time checked access to the components included in a given query. - Add new methods to `Query` to create "query lens" with a subset of the access of the initial query. ### Query Builder The `QueryBuilder` API allows you to define a query at runtime. At it's most basic use it will simply create a query with the corresponding type signature: ```rust let query = QueryBuilder::<Entity, With<A>>::new(&mut world).build(); // is equivalent to let query = QueryState::<Entity, With<A>>::new(&mut world); ``` Before calling `.build()` you also have the opportunity to add additional accesses and filters. Here is a simple example where we add additional filter terms: ```rust let entity_a = world.spawn((A(0), B(0))).id(); let entity_b = world.spawn((A(0), C(0))).id(); let mut query_a = QueryBuilder::<Entity>::new(&mut world) .with::<A>() .without::<C>() .build(); assert_eq!(entity_a, query_a.single(&world)); ``` This alone is useful in that allows you to decide which archetypes your query will match at runtime. However it is also very limited, consider a case like the following: ```rust let query_a = QueryBuilder::<&A>::new(&mut world) // Add an additional access .data::<&B>() .build(); ``` This will grant the query an additional read access to component B however we have no way of accessing the data while iterating as the type signature still only includes &A. For an even more concrete example of this consider dynamic components: ```rust let query_a = QueryBuilder::<Entity>::new(&mut world) // Adding a filter is easy since it doesn't need be read later .with_id(component_id_a) // How do I access the data of this component? .ref_id(component_id_b) .build(); ``` With this in mind the `QueryBuilder` API seems somewhat incomplete by itself, we need some way method of accessing the components dynamically. So here's one: ### Query Transmutation If the problem is not having the component in the type signature why not just add it? This PR also adds transmute methods to `QueryBuilder` and `QueryState`. Here's a simple example: ```rust world.spawn(A(0)); world.spawn((A(1), B(0))); let mut query = QueryBuilder::<()>::new(&mut world) .with::<B>() .transmute::<&A>() .build(); query.iter(&world).for_each(|a| assert_eq!(a.0, 1)); ``` The `QueryState` and `QueryBuilder` transmute methods look quite similar but are different in one respect. Transmuting a builder will always succeed as it will just add the additional accesses needed for the new terms if they weren't already included. Transmuting a `QueryState` will panic in the case that the new type signature would give it access it didn't already have, for example: ```rust let query = QueryState::<&A, Option<&B>>::new(&mut world); /// This is fine, the access for Option<&A> is less restrictive than &A query.transmute::<Option<&A>>(&world); /// Oh no, this would allow access to &B on entities that might not have it, so it panics query.transmute::<&B>(&world); /// This is right out query.transmute::<&C>(&world); ``` This is quite an appealing API to also have available on `Query` however it does pose one additional wrinkle: In order to to change the iterator we need to create a new `QueryState` to back it. `Query` doesn't own it's own state though, it just borrows it, so we need a place to borrow it from. This is why `QueryLens` exists, it is a place to store the new state so it can be borrowed when you call `.query()` leaving you with an API like this: ```rust fn function_that_takes_a_query(query: &Query<&A>) { // ... } fn system(query: Query<(&A, &B)>) { let lens = query.transmute_lens::<&A>(); let q = lens.query(); function_that_takes_a_query(&q); } ``` Now you may be thinking: Hey, wait a second, you introduced the problem with dynamic components and then described a solution that only works for static components! Ok, you got me, I guess we need a bit more: ### Filtered Entity References Currently the only way you can access dynamic components on entities through a query is with either `EntityMut` or `EntityRef`, however these can access all components and so conflict with all other accesses. This PR introduces `FilteredEntityMut` and `FilteredEntityRef` as alternatives that have additional runtime checking to prevent accessing components that you shouldn't. This way you can build a query with a `QueryBuilder` and actually access the components you asked for: ```rust let mut query = QueryBuilder::<FilteredEntityRef>::new(&mut world) .ref_id(component_id_a) .with(component_id_b) .build(); let entity_ref = query.single(&world); // Returns Some(Ptr) as we have that component and are allowed to read it let a = entity_ref.get_by_id(component_id_a); // Will return None even though the entity does have the component, as we are not allowed to read it let b = entity_ref.get_by_id(component_id_b); ``` For the most part these new structs have the exact same methods as their non-filtered equivalents. Putting all of this together we can do some truly dynamic ECS queries, check out the `dynamic` example to see it in action: ``` Commands: comp, c Create new components spawn, s Spawn entities query, q Query for entities Enter a command with no parameters for usage. > c A, B, C, Data 4 Component A created with id: 0 Component B created with id: 1 Component C created with id: 2 Component Data created with id: 3 > s A, B, Data 1 Entity spawned with id: 0v0 > s A, C, Data 0 Entity spawned with id: 1v0 > q &Data 0v0: Data: [1, 0, 0, 0] 1v0: Data: [0, 0, 0, 0] > q B, &mut Data 0v0: Data: [2, 1, 1, 1] > q B || C, &Data 0v0: Data: [2, 1, 1, 1] 1v0: Data: [0, 0, 0, 0] ``` ## Changelog - Add new `transmute_lens` methods to `Query`. - Add new types `QueryBuilder`, `FilteredEntityMut`, `FilteredEntityRef` and `QueryLens` - `update_archetype_component_access` has been removed, archetype component accesses are now determined by the accesses set in `update_component_access` - Added method `set_access` to `WorldQuery`, this is called before `update_component_access` for queries that have a restricted set of accesses, such as those built by `QueryBuilder` or `QueryLens`. This is primarily used by the `FilteredEntity*` variants and has an empty trait implementation. - Added method `get_state` to `WorldQuery` as a fallible version of `init_state` when you don't have `&mut World` access. ## Future Work Improve performance of `FilteredEntityMut` and `FilteredEntityRef`, currently they have to determine the accesses a query has in a given archetype during iteration which is far from ideal, especially since we already did the work when matching the archetype in the first place. To avoid making more internal API changes I have left it out of this PR. --------- Co-authored-by: Mike Hsu <mike.hsu@gmail.com> |
||
|
|
9c78128e8f
|
Rename Q type parameter to D when referring to WorldQueryData (#10782)
# Objective Since #10776 split `WorldQuery` to `WorldQueryData` and `WorldQueryFilter`, it should be clear that the query is actually composed of two parts. It is not factually correct to call "query" only the data part. Therefore I suggest to rename the `Q` parameter to `D` in `Query` and related items. As far as I know, there shouldn't be breaking changes from renaming generic type parameters. ## Solution I used a combination of rust-analyzer go to reference and `Ctrl-F`ing various patterns to catch as many cases as possible. Hopefully I got them all. Feel free to check if you're concerned of me having missed some. ## Notes This and #10779 have many lines in common, so merging one will cause a lot of merge conflicts to the other. --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
5af2f022d8
|
Rename WorldQueryData & WorldQueryFilter to QueryData & QueryFilter (#10779)
# Rename `WorldQueryData` & `WorldQueryFilter` to `QueryData` & `QueryFilter` Fixes #10776 ## Solution Traits `WorldQueryData` & `WorldQueryFilter` were renamed to `QueryData` and `QueryFilter`, respectively. Related Trait types were also renamed. --- ## Changelog - Trait `WorldQueryData` has been renamed to `QueryData`. Derive macro's `QueryData` attribute `world_query_data` has been renamed to `query_data`. - Trait `WorldQueryFilter` has been renamed to `QueryFilter`. Derive macro's `QueryFilter` attribute `world_query_filter` has been renamed to `query_filter`. - Trait's `ExtractComponent` type `Query` has been renamed to `Data`. - Trait's `GetBatchData` types `Query` & `QueryFilter` has been renamed to `Data` & `Filter`, respectively. - Trait's `ExtractInstance` type `Query` has been renamed to `Data`. - Trait's `ViewNode` type `ViewQuery` has been renamed to `ViewData`. - Trait's `RenderCommand` types `ViewWorldQuery` & `ItemWorldQuery` has been renamed to `ViewData` & `ItemData`, respectively. ## Migration Guide Note: if merged before 0.13 is released, this should instead modify the migration guide of #10776 with the updated names. - Rename `WorldQueryData` & `WorldQueryFilter` trait usages to `QueryData` & `QueryFilter` and their respective derive macro attributes `world_query_data` & `world_query_filter` to `query_data` & `query_filter`. - Rename the following trait type usages: - Trait's `ExtractComponent` type `Query` to `Data`. - Trait's `GetBatchData` type `Query` to `Data`. - Trait's `ExtractInstance` type `Query` to `Data`. - Trait's `ViewNode` type `ViewQuery` to `ViewData`' - Trait's `RenderCommand` types `ViewWolrdQuery` & `ItemWorldQuery` to `ViewData` & `ItemData`, respectively. ```rust // Before #[derive(WorldQueryData)] #[world_query_data(derive(Debug))] struct EmptyQuery { empty: (), } // After #[derive(QueryData)] #[query_data(derive(Debug))] struct EmptyQuery { empty: (), } // Before #[derive(WorldQueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // After #[derive(QueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // Before impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Query = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Query>) -> Option<Self::Out> { //... } } // After impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Data = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Data>) -> Option<Self::Out> { //... } } // Before impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Query = Entity; type QueryFilter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Query>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // After impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Data = Entity; type Filter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Data>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // Before impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Query = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Query>) -> Option<Self> { Some(item.id()) } } // After impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Data = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Data>) -> Option<Self> { Some(item.id()) } } // Before impl ViewNode for PostProcessNode { type ViewQuery = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewQuery>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // After impl ViewNode for PostProcessNode { type ViewData = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewData>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // Before impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewWorldQuery = (); type ItemWorldQuery = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } // After impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewData = (); type ItemData = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } ``` |
||
|
|
2148518758
|
Override QueryIter::fold to port Query::for_each perf gains to select Iterator combinators (#6773)
# Objective After #6547, `Query::for_each` has been capable of automatic vectorization on certain queries, which is seeing a notable (>50% CPU time improvements) for iteration. However, `Query::for_each` isn't idiomatic Rust, and lacks the flexibility of iterator combinators. Ideally, `Query::iter` and friends should be able to achieve the same results. However, this does seem to blocked upstream (rust-lang/rust#104914) by Rust's loop optimizations. ## Solution This is an intermediate solution and refactor. This moves the `Query::for_each` implementation onto the `Iterator::fold` implementation for `QueryIter` instead. This should result in the same automatic vectorization optimization on all `Iterator` functions that internally use fold, including `Iterator::for_each`, `Iterator::count`, etc. With this, it should close the gap between the two completely. Internally, this PR changes `Query::for_each` to use `query.iter().for_each(..)` instead of the duplicated implementation. Separately, the duplicate implementations of internal iteration (i.e. `Query::par_for_each`) now use portions of the current `Query::for_each` implementation factored out into their own functions. This also massively cleans up our internal fragmentation of internal iteration options, deduplicating the iteration code used in `for_each` and `par_iter().for_each()`. --- ## Changelog Changed: `Query::for_each`, `Query::for_each_mut`, `Query::for_each`, and `Query::for_each_mut` have been moved to `QueryIter`'s `Iterator::for_each` implementation, and still retains their performance improvements over normal iteration. These APIs are deprecated in 0.13 and will be removed in 0.14. --------- Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com> Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
f0a8994f55
|
Split WorldQuery into WorldQueryData and WorldQueryFilter (#9918)
# Objective - Fixes #7680 - This is an updated for https://github.com/bevyengine/bevy/pull/8899 which had the same objective but fell a long way behind the latest changes ## Solution The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter : WorldQuery` have been added and some of the types and functions from `WorldQuery` has been moved into them. `ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`. `WorldQueryFilter` is safe (as long as `WorldQuery` is implemented safely). `WorldQueryData` is unsafe - safely implementing it requires that `Self::ReadOnly` is a readonly version of `Self` (this used to be a safety requirement of `WorldQuery`) The type parameters `Q` and `F` of `Query` must now implement `WorldQueryData` and `WorldQueryFilter` respectively. This makes it impossible to accidentally use a filter in the data position or vice versa which was something that could lead to bugs. ~~Compile failure tests have been added to check this.~~ It was previously sometimes useful to use `Option<With<T>>` in the data position. Use `Has<T>` instead in these cases. The `WorldQuery` derive macro has been split into separate derive macros for `WorldQueryData` and `WorldQueryFilter`. Previously it was possible to derive both `WorldQuery` for a struct that had a mixture of data and filter items. This would not work correctly in some cases but could be a useful pattern in others. *This is no longer possible.* --- ## Notes - The changes outside of `bevy_ecs` are all changing type parameters to the new types, updating the macro use, or replacing `Option<With<T>>` with `Has<T>`. - All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL` so I moved it to `WorldQueryFilter` and replaced all calls to it with `true`. That should be the only logic change outside of the macro generation code. - `Changed<T>` and `Added<T>` were being generated by a macro that I have expanded. Happy to revert that if desired. - The two derive macros share some functions for implementing `WorldQuery` but the tidiest way I could find to implement them was to give them a ton of arguments and ask clippy to ignore that. ## Changelog ### Changed - Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which now have separate derive macros. It is not possible to derive both for the same type. - `Query` now requires that the first type argument implements `WorldQueryData` and the second implements `WorldQueryFilter` ## Migration Guide - Update derives ```rust // old #[derive(WorldQuery)] #[world_query(mutable, derive(Debug))] struct CustomQuery { entity: Entity, a: &'static mut ComponentA } #[derive(WorldQuery)] struct QueryFilter { _c: With<ComponentC> } // new #[derive(WorldQueryData)] #[world_query_data(mutable, derive(Debug))] struct CustomQuery { entity: Entity, a: &'static mut ComponentA, } #[derive(WorldQueryFilter)] struct QueryFilter { _c: With<ComponentC> } ``` - Replace `Option<With<T>>` with `Has<T>` ```rust /// old fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>) { for (entity, has_a_option) in query.iter(){ let has_a:bool = has_a_option.is_some(); //todo!() } } /// new fn my_system(query: Query<(Entity, Has<ComponentA>)>) { for (entity, has_a) in query.iter(){ //todo!() } } ``` - Fix queries which had filters in the data position or vice versa. ```rust // old fn my_system(query: Query<(Entity, With<ComponentA>)>) { for (entity, _) in query.iter(){ //todo!() } } // new fn my_system(query: Query<Entity, With<ComponentA>>) { for entity in query.iter(){ //todo!() } } // old fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>) { for (entity, _) in query.iter(){ //todo!() } } // new fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>) { for entity in query.iter(){ //todo!() } } ``` --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
4c6b6fc24a
|
Moved get_component(_unchecked_mut) from Query to QueryState (#9686)
# Objective - Fixes #9683 ## Solution - Moved `get_component` from `Query` to `QueryState`. - Moved `get_component_unchecked_mut` from `Query` to `QueryState`. - Moved `QueryComponentError` from `bevy_ecs::system` to `bevy_ecs::query`. Minor Breaking Change. - Narrowed scope of `unsafe` blocks in `Query` methods. --- ## Migration Guide - `use bevy_ecs::system::QueryComponentError;` -> `use bevy_ecs::query::QueryComponentError;` ## Notes I am not very familiar with unsafe Rust nor its use within Bevy, so I may have committed a Rust faux pas during the migration. --------- Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com> Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com> |
||
|
|
33fdc5f5db
|
Move schedule name into Schedule (#9600)
# Objective - Move schedule name into `Schedule` to allow the schedule name to be used for errors and tracing in Schedule methods - Fixes #9510 ## Solution - Move label onto `Schedule` and adjust api's on `World` and `Schedule` to not pass explicit label where it makes sense to. - add name to errors and tracing. - `Schedule::new` now takes a label so either add the label or use `Schedule::default` which uses a default label. `default` is mostly used in doc examples and tests. --- ## Changelog - move label onto `Schedule` to improve error message and logging for schedules. ## Migration Guide `Schedule::new` and `App::add_schedule` ```rust // old let schedule = Schedule::new(); app.add_schedule(MyLabel, schedule); // new let schedule = Schedule::new(MyLabel); app.add_schedule(schedule); ``` if you aren't using a label and are using the schedule struct directly you can use the default constructor. ```rust // old let schedule = Schedule::new(); schedule.run(world); // new let schedule = Schedule::default(); schedule.run(world); ``` `Schedules:insert` ```rust // old let schedule = Schedule::new(); schedules.insert(MyLabel, schedule); // new let schedule = Schedule::new(MyLabel); schedules.insert(schedule); ``` `World::add_schedule` ```rust // old let schedule = Schedule::new(); world.add_schedule(MyLabel, schedule); // new let schedule = Schedule::new(MyLabel); world.add_schedule(schedule); ``` |
||
|
|
ddbfa48711
|
Simplify parallel iteration methods (#8854)
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
|
||
|
|
6529d2e7f0
|
Added Has<T> WorldQuery type (#8844)
# Objective - Fixes #7811 ## Solution - I added `Has<T>` (and `HasFetch<T>` ) and implemented `WorldQuery`, `ReadonlyWorldQuery`, and `ArchetypeFilter` it - I also added documentation with an example and a unit test I believe I've done everything right but this is my first contribution and I'm not an ECS expert so someone who is should probably check my implementation. I based it on what `Or<With<T>,>`, would do. The only difference is that `Has` does not update component access - adding `Has` to a query should never affect whether or not it is disjoint with another query *I think*. --- ## Changelog ## Added - Added `Has<T>` WorldQuery to find out whether or not an entity has a particular component. --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com> |
||
|
|
32faf4cb5c
|
Document every public item in bevy_ecs (#8731)
# Objective Title. --------- Co-authored-by: François <mockersf@gmail.com> Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> Co-authored-by: James Liu <contact@jamessliu.com> |
||
|
|
a63881905a
|
Pass query change ticks to QueryParIter instead of always using change ticks from World. (#8029)
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com> Co-authored-by: James Liu <contact@jamessliu.com> |
||
|
|
b39f83640f |
Fix some typos (#7763)
# Objective Stumbled on a typo and went on a typo hunt. ## Solution Fix em |
||
|
|
dfea88c64d |
Basic adaptive batching for parallel query iteration (#4777)
# Objective Fixes #3184. Fixes #6640. Fixes #4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark. This PR proposes a naive automatic batch-size computation based on the current state of the `World`. ## Background `Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together. There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded. ## Solution - [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends. - [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD` - [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less. - [x] Early return if there is no matched table/archetype. - [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload. --- ## Changelog Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state. ## Migration Guide The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions. Before: ```rust fn parallel_system(query: Query<&MyComponent>) { query.par_for_each(32, |comp| { ... }); } ``` After: ```rust fn parallel_system(query: Query<&MyComponent>) { query.par_iter().for_each(|comp| { ... }); } ``` Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com> Co-authored-by: Robert Swain <robert.swain@gmail.com> Co-authored-by: François <mockersf@gmail.com> Co-authored-by: Corey Farwell <coreyf@rwell.org> Co-authored-by: Aevyrie <aevyrie@gmail.com> |
||
|
|
3dd8b42f72 |
Fix various typos (#7096)
I stumbled across a typo in some docs. Fixed some more while I was in there. |
||
|
|
15ea93a348 |
Fix size_hint for partially consumed QueryIter and QueryCombinationIter (#5214)
# Objective Fix #5149 ## Solution Instead of returning the **total count** of elements in the `QueryIter` in `size_hint`, we return the **count of remaining elements**. This Fixes #5149 even when #5148 gets merged. - https://github.com/bevyengine/bevy/issues/5149 - https://github.com/bevyengine/bevy/pull/5148 --- ## Changelog - Fix partially consumed `QueryIter` and `QueryCombinationIter` having invalid `size_hint` Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com> |
||
|
|
0e41b79a35 |
debug_checked_unwrap should track its caller (#6452)
# Objective When an error causes `debug_checked_unreachable` to be called, the panic message unhelpfully points to the function definition instead of the place that caused the error. ## Solution Add the `#[track_caller]` attribute in debug mode. |
||
|
|
ec8c8fbc8a |
Remove unnecesary branches/panics from Query accesses (#6461)
# Objective Supercedes #6452. Upon inspection of the [generated assembly](https://gist.github.com/james7132/c2740c6941b80d7912f1e8888e223cbb#file-original-s) of a [simple Bevy binary](https://gist.github.com/james7132/c2740c6941b80d7912f1e8888e223cbb#file-source-rs) compiled with `cargo rustc --release -- --emit asm`, it's apparent that there are multiple unnecessary branches in the generated assembly: ```assembly .LBB5_5: cmpq %r10, %r11 je .LBB5_15 movq (%r11), %rcx movq 328(%r15), %rdx cmpq %rdx, %rcx jae .LBB5_14 movq 312(%r15), %rdi leaq (%rcx,%rcx,2), %rcx shlq $5, %rcx movq 336(%r12), %rdx movq 64(%rdi,%rcx), %rax cmpq %rdx, %rax jbe .LBB5_4 leaq (%rdi,%rcx), %rsi movq 48(%rsi), %rbp shlq $4, %rdx cmpq $0, (%rbp,%rdx) je .LBB5_4 movq 344(%r12), %rbx cmpq %rbx, %rax jbe .LBB5_4 shlq $4, %rbx cmpq $0, (%rbp,%rbx) je .LBB5_4 addq $8, %r11 movq 88(%rdi,%rcx), %rcx testq %rcx, %rcx je .LBB5_5 movq (%rsi), %rax movq 8(%rbp,%rdx), %rdx leaq (%rdx,%rdx,4), %rdi shlq $4, %rdi movq 32(%rax,%rdi), %rdx movq 56(%rax,%rdi), %r8 movq 8(%rbp,%rbx), %rbp leaq (%rbp,%rbp,4), %rbp shlq $4, %rbp movq 32(%rax,%rbp), %r9 xorl %ebp, %ebp jmp .LBB5_13 .p2align 4, 0x90 ``` Almost every one of the instructions starting with `j` is a potential branch, which can significantly slow down accesses. Of these, two labels are both common and never used: ```asm .LBB5_14: leaq __unnamed_2(%rip), %r8 callq _ZN4core9panicking18panic_bounds_check17h70367088e72af65aE ud2 .LBB5_4: callq _ZN8bevy_ecs5query25debug_checked_unreachable17h0855ff520ceaea77E ud2 .seh_endproc ``` These correpsond to subprocedure calls to panicking due to out of bounds from indexing `Tables` and `debug_checked_unreadable`. Both of which should be inlined and optimized out, but are not. ## Solution Make `debug_checked_unreachable` a macro to forcibly inline either `unreachable!()` in debug builds, and `std::hint::unreachable_unchecked()` in release mode. Replace the `Tables` and `Archetype` index access with `get(id).unwrap_or_else(|| debug_checked_unreachable!())` to assume that the table or archetype provided exists. This has no external breaking change of any kind. The equivalent section of code with these changes removes most of the conditional jump instructions: ```asm .LBB5_5: movss (%rbx,%rbp,4), %xmm0 movl %r14d, 4(%r8,%rbp,8) addss (%rdi,%rbp,4), %xmm0 movss %xmm0, (%rdi,%rbp,4) incq %rbp .LBB5_1: cmpq %rdx, %rbp jne .LBB5_5 .p2align 4, 0x90 .LBB5_2: cmpq %rcx, %rax je .LBB5_6 movq (%rax), %rdx addq $8, %rax movq 312(%rsi), %rbp leaq (%rdx,%rdx,2), %rbx shlq $5, %rbx movq 88(%rbp,%rbx), %rdx testq %rdx, %rdx je .LBB5_2 leaq (%rbx,%rbp), %r8 movq 336(%r15), %rdi movq 344(%r15), %r9 movq 48(%rbp,%rbx), %r10 shlq $4, %rdi movq (%r8), %rbx movq 8(%r10,%rdi), %rdi leaq (%rdi,%rdi,4), %rbp shlq $4, %rbp movq 32(%rbx,%rbp), %rdi movq 56(%rbx,%rbp), %r8 shlq $4, %r9 movq 8(%r10,%r9), %rbp leaq (%rbp,%rbp,4), %rbp shlq $4, %rbp movq 32(%rbx,%rbp), %rbx xorl %ebp, %ebp jmp .LBB5_5 .LBB5_6: addq $40, %rsp popq %rbx popq %rbp popq %rdi popq %rsi popq %r14 popq %r15 retq .seh_endproc ``` ## Performance Microbenchmarks results: <details> ``` group main no-panic-query ----- ---- -------------- busy_systems/01x_entities_03_systems 1.20 42.4±2.66µs ? ?/sec 1.00 35.3±1.68µs ? ?/sec busy_systems/01x_entities_06_systems 1.32 83.8±3.50µs ? ?/sec 1.00 63.6±1.72µs ? ?/sec busy_systems/01x_entities_09_systems 1.15 113.3±8.90µs ? ?/sec 1.00 98.2±6.15µs ? ?/sec busy_systems/01x_entities_12_systems 1.27 160.8±32.44µs ? ?/sec 1.00 126.6±4.70µs ? ?/sec busy_systems/01x_entities_15_systems 1.12 179.6±3.71µs ? ?/sec 1.00 160.3±11.03µs ? ?/sec busy_systems/02x_entities_03_systems 1.18 76.8±3.14µs ? ?/sec 1.00 65.2±3.17µs ? ?/sec busy_systems/02x_entities_06_systems 1.16 144.6±6.10µs ? ?/sec 1.00 124.5±5.14µs ? ?/sec busy_systems/02x_entities_09_systems 1.19 215.3±9.18µs ? ?/sec 1.00 181.5±5.67µs ? ?/sec busy_systems/02x_entities_12_systems 1.20 266.7±8.33µs ? ?/sec 1.00 222.0±9.53µs ? ?/sec busy_systems/02x_entities_15_systems 1.23 338.8±10.53µs ? ?/sec 1.00 276.3±6.94µs ? ?/sec busy_systems/03x_entities_03_systems 1.43 113.5±5.06µs ? ?/sec 1.00 79.6±1.49µs ? ?/sec busy_systems/03x_entities_06_systems 1.38 217.3±12.67µs ? ?/sec 1.00 157.5±3.07µs ? ?/sec busy_systems/03x_entities_09_systems 1.23 308.8±24.75µs ? ?/sec 1.00 251.6±8.93µs ? ?/sec busy_systems/03x_entities_12_systems 1.05 347.7±12.43µs ? ?/sec 1.00 330.6±11.43µs ? ?/sec busy_systems/03x_entities_15_systems 1.13 455.5±13.88µs ? ?/sec 1.00 401.7±17.29µs ? ?/sec busy_systems/04x_entities_03_systems 1.24 144.7±5.89µs ? ?/sec 1.00 116.9±6.29µs ? ?/sec busy_systems/04x_entities_06_systems 1.24 282.8±21.40µs ? ?/sec 1.00 228.6±21.31µs ? ?/sec busy_systems/04x_entities_09_systems 1.35 431.8±14.10µs ? ?/sec 1.00 319.6±9.83µs ? ?/sec busy_systems/04x_entities_12_systems 1.16 493.8±22.87µs ? ?/sec 1.00 424.9±15.24µs ? ?/sec busy_systems/04x_entities_15_systems 1.10 587.5±23.25µs ? ?/sec 1.00 531.7±16.32µs ? ?/sec busy_systems/05x_entities_03_systems 1.14 148.2±9.61µs ? ?/sec 1.00 129.5±4.32µs ? ?/sec busy_systems/05x_entities_06_systems 1.31 359.7±17.46µs ? ?/sec 1.00 273.6±10.55µs ? ?/sec busy_systems/05x_entities_09_systems 1.22 473.5±23.11µs ? ?/sec 1.00 389.3±13.62µs ? ?/sec busy_systems/05x_entities_12_systems 1.05 562.9±20.76µs ? ?/sec 1.00 536.5±24.35µs ? ?/sec busy_systems/05x_entities_15_systems 1.23 818.5±28.70µs ? ?/sec 1.00 666.6±45.87µs ? ?/sec contrived/01x_entities_03_systems 1.27 27.5±0.49µs ? ?/sec 1.00 21.6±1.71µs ? ?/sec contrived/01x_entities_06_systems 1.22 49.9±1.18µs ? ?/sec 1.00 40.7±2.62µs ? ?/sec contrived/01x_entities_09_systems 1.30 72.3±2.39µs ? ?/sec 1.00 55.4±2.60µs ? ?/sec contrived/01x_entities_12_systems 1.28 94.3±9.44µs ? ?/sec 1.00 73.7±3.62µs ? ?/sec contrived/01x_entities_15_systems 1.25 118.0±2.43µs ? ?/sec 1.00 94.1±3.99µs ? ?/sec contrived/02x_entities_03_systems 1.23 41.6±1.71µs ? ?/sec 1.00 33.7±2.30µs ? ?/sec contrived/02x_entities_06_systems 1.19 78.6±2.63µs ? ?/sec 1.00 65.9±2.35µs ? ?/sec contrived/02x_entities_09_systems 1.28 113.6±3.60µs ? ?/sec 1.00 88.6±3.60µs ? ?/sec contrived/02x_entities_12_systems 1.20 146.4±5.75µs ? ?/sec 1.00 121.7±3.35µs ? ?/sec contrived/02x_entities_15_systems 1.23 178.5±4.86µs ? ?/sec 1.00 145.7±4.00µs ? ?/sec contrived/03x_entities_03_systems 1.42 58.3±2.77µs ? ?/sec 1.00 41.1±1.54µs ? ?/sec contrived/03x_entities_06_systems 1.32 108.5±7.30µs ? ?/sec 1.00 82.4±4.86µs ? ?/sec contrived/03x_entities_09_systems 1.23 153.7±4.61µs ? ?/sec 1.00 125.0±4.76µs ? ?/sec contrived/03x_entities_12_systems 1.18 197.5±5.12µs ? ?/sec 1.00 166.8±8.14µs ? ?/sec contrived/03x_entities_15_systems 1.23 238.8±6.38µs ? ?/sec 1.00 194.6±4.55µs ? ?/sec contrived/04x_entities_03_systems 1.34 66.4±3.42µs ? ?/sec 1.00 49.5±1.98µs ? ?/sec contrived/04x_entities_06_systems 1.27 134.3±4.86µs ? ?/sec 1.00 105.8±3.58µs ? ?/sec contrived/04x_entities_09_systems 1.26 193.2±3.83µs ? ?/sec 1.00 153.0±5.60µs ? ?/sec contrived/04x_entities_12_systems 1.16 237.1±5.78µs ? ?/sec 1.00 204.9±18.77µs ? ?/sec contrived/04x_entities_15_systems 1.17 289.2±4.76µs ? ?/sec 1.00 246.3±8.57µs ? ?/sec contrived/05x_entities_03_systems 1.26 80.4±2.90µs ? ?/sec 1.00 63.7±3.07µs ? ?/sec contrived/05x_entities_06_systems 1.27 161.6±13.47µs ? ?/sec 1.00 127.2±5.59µs ? ?/sec contrived/05x_entities_09_systems 1.22 228.0±7.76µs ? ?/sec 1.00 186.2±7.68µs ? ?/sec contrived/05x_entities_12_systems 1.20 289.5±6.21µs ? ?/sec 1.00 241.8±7.52µs ? ?/sec contrived/05x_entities_15_systems 1.18 357.3±11.24µs ? ?/sec 1.00 302.7±7.21µs ? ?/sec heavy_compute/base 1.01 302.4±3.52µs ? ?/sec 1.00 300.2±3.40µs ? ?/sec iter_fragmented/base 1.00 348.1±7.51ns ? ?/sec 1.01 351.9±8.32ns ? ?/sec iter_fragmented/foreach 1.03 239.8±23.78ns ? ?/sec 1.00 233.8±18.12ns ? ?/sec iter_fragmented/foreach_wide 1.00 3.9±0.13µs ? ?/sec 1.02 4.0±0.22µs ? ?/sec iter_fragmented/wide 1.18 4.6±0.15µs ? ?/sec 1.00 3.9±0.10µs ? ?/sec iter_fragmented_sparse/base 1.02 8.1±0.15ns ? ?/sec 1.00 7.9±0.56ns ? ?/sec iter_fragmented_sparse/foreach 1.00 7.8±0.22ns ? ?/sec 1.01 7.9±0.62ns ? ?/sec iter_fragmented_sparse/foreach_wide 1.00 37.2±1.17ns ? ?/sec 1.10 40.9±0.95ns ? ?/sec iter_fragmented_sparse/wide 1.09 48.4±2.13ns ? ?/sec 1.00 44.5±18.34ns ? ?/sec iter_simple/base 1.02 8.4±0.10µs ? ?/sec 1.00 8.2±0.14µs ? ?/sec iter_simple/foreach 1.01 8.3±0.07µs ? ?/sec 1.00 8.2±0.09µs ? ?/sec iter_simple/foreach_sparse_set 1.00 25.3±0.32µs ? ?/sec 1.02 25.7±0.42µs ? ?/sec iter_simple/foreach_wide 1.03 41.1±0.94µs ? ?/sec 1.00 39.9±0.41µs ? ?/sec iter_simple/foreach_wide_sparse_set 1.05 123.6±2.05µs ? ?/sec 1.00 118.1±2.78µs ? ?/sec iter_simple/sparse_set 1.14 30.5±1.40µs ? ?/sec 1.00 26.9±0.64µs ? ?/sec iter_simple/system 1.01 8.4±0.25µs ? ?/sec 1.00 8.4±0.11µs ? ?/sec iter_simple/wide 1.18 48.2±0.62µs ? ?/sec 1.00 40.7±0.38µs ? ?/sec iter_simple/wide_sparse_set 1.12 140.8±21.56µs ? ?/sec 1.00 126.0±2.30µs ? ?/sec query_get/50000_entities_sparse 1.17 378.6±7.60µs ? ?/sec 1.00 324.1±23.17µs ? ?/sec query_get/50000_entities_table 1.08 330.9±10.90µs ? ?/sec 1.00 306.8±4.98µs ? ?/sec query_get_component/50000_entities_sparse 1.00 976.7±19.55µs ? ?/sec 1.00 979.8±35.87µs ? ?/sec query_get_component/50000_entities_table 1.00 1029.0±15.11µs ? ?/sec 1.05 1080.0±59.18µs ? ?/sec query_get_component_simple/system 1.13 839.7±14.18µs ? ?/sec 1.00 742.8±10.72µs ? ?/sec query_get_component_simple/unchecked 1.01 909.0±15.17µs ? ?/sec 1.00 898.0±13.56µs ? ?/sec query_get_many_10/50000_calls_sparse 1.04 5.5±0.54ms ? ?/sec 1.00 5.3±0.67ms ? ?/sec query_get_many_10/50000_calls_table 1.01 4.9±0.49ms ? ?/sec 1.00 4.8±0.45ms ? ?/sec query_get_many_2/50000_calls_sparse 1.28 848.4±210.89µs ? ?/sec 1.00 664.8±47.69µs ? ?/sec query_get_many_2/50000_calls_table 1.05 779.0±73.85µs ? ?/sec 1.00 739.2±83.02µs ? ?/sec query_get_many_5/50000_calls_sparse 1.05 2.4±0.37ms ? ?/sec 1.00 2.3±0.33ms ? ?/sec query_get_many_5/50000_calls_table 1.00 1939.9±75.22µs ? ?/sec 1.04 2.0±0.19ms ? ?/sec run_criteria/yes_using_query/001_systems 1.00 3.7±0.38µs ? ?/sec 1.30 4.9±0.14µs ? ?/sec run_criteria/yes_using_query/006_systems 1.00 8.9±0.40µs ? ?/sec 1.17 10.3±0.57µs ? ?/sec run_criteria/yes_using_query/011_systems 1.00 13.9±0.49µs ? ?/sec 1.08 15.0±0.89µs ? ?/sec run_criteria/yes_using_query/016_systems 1.00 18.8±0.74µs ? ?/sec 1.00 18.8±1.43µs ? ?/sec run_criteria/yes_using_query/021_systems 1.07 24.1±0.87µs ? ?/sec 1.00 22.6±1.58µs ? ?/sec run_criteria/yes_using_query/026_systems 1.04 27.9±0.62µs ? ?/sec 1.00 26.8±1.71µs ? ?/sec run_criteria/yes_using_query/031_systems 1.09 33.3±1.03µs ? ?/sec 1.00 30.5±2.18µs ? ?/sec run_criteria/yes_using_query/036_systems 1.14 38.7±0.80µs ? ?/sec 1.00 33.9±1.75µs ? ?/sec run_criteria/yes_using_query/041_systems 1.18 43.7±1.07µs ? ?/sec 1.00 37.0±2.39µs ? ?/sec run_criteria/yes_using_query/046_systems 1.14 47.6±1.16µs ? ?/sec 1.00 41.9±2.09µs ? ?/sec run_criteria/yes_using_query/051_systems 1.17 52.9±2.04µs ? ?/sec 1.00 45.3±1.75µs ? ?/sec run_criteria/yes_using_query/056_systems 1.25 59.2±2.38µs ? ?/sec 1.00 47.2±2.01µs ? ?/sec run_criteria/yes_using_query/061_systems 1.28 66.1±15.84µs ? ?/sec 1.00 51.5±2.47µs ? ?/sec run_criteria/yes_using_query/066_systems 1.28 70.2±2.57µs ? ?/sec 1.00 54.7±2.58µs ? ?/sec run_criteria/yes_using_query/071_systems 1.30 75.5±2.27µs ? ?/sec 1.00 58.2±3.31µs ? ?/sec run_criteria/yes_using_query/076_systems 1.26 81.5±2.66µs ? ?/sec 1.00 64.5±3.13µs ? ?/sec run_criteria/yes_using_query/081_systems 1.29 89.7±2.58µs ? ?/sec 1.00 69.3±3.47µs ? ?/sec run_criteria/yes_using_query/086_systems 1.33 95.6±3.39µs ? ?/sec 1.00 71.8±3.48µs ? ?/sec run_criteria/yes_using_query/091_systems 1.25 102.0±3.67µs ? ?/sec 1.00 81.4±4.82µs ? ?/sec run_criteria/yes_using_query/096_systems 1.33 111.7±3.29µs ? ?/sec 1.00 83.8±4.15µs ? ?/sec run_criteria/yes_using_query/101_systems 1.29 113.2±12.04µs ? ?/sec 1.00 87.7±5.15µs ? ?/sec world_query_for_each/50000_entities_sparse 1.00 47.4±0.51µs ? ?/sec 1.00 47.3±0.33µs ? ?/sec world_query_for_each/50000_entities_table 1.00 27.2±0.50µs ? ?/sec 1.00 27.2±0.17µs ? ?/sec world_query_get/50000_entities_sparse_wide 1.09 210.5±1.78µs ? ?/sec 1.00 192.5±2.61µs ? ?/sec world_query_get/50000_entities_table 1.00 127.7±2.09µs ? ?/sec 1.07 136.2±5.95µs ? ?/sec world_query_get/50000_entities_table_wide 1.00 209.8±2.37µs ? ?/sec 1.15 240.6±2.04µs ? ?/sec world_query_iter/50000_entities_sparse 1.00 54.2±0.36µs ? ?/sec 1.01 54.7±0.61µs ? ?/sec world_query_iter/50000_entities_table 1.00 27.2±0.31µs ? ?/sec 1.00 27.3±0.64µs ? ?/sec ``` </details> NOTE: This PR includes a change to enable LTO on our benchmarks to get a "fully optimized" baseline for our benchmarks. Both the main and the current PR's results were with LTO enabled. |
||
|
|
336049da68 |
Remove outdated uses of single-tuple bundles (#6406)
# Objective Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary. ## Solution Search for regex `\(.+\s*,\)`. This should have found every instance. |
||
|
|
54cf45c5b3 |
Avoid making Fetchs Clone (#5593)
# Objective - Do not implement `Copy` or `Clone` for `Fetch` types as this is kind of sus soundness wise (it feels like cloning an `IterMut` in safe code to me). Cloning a fetch seems important to think about soundness wise when doing it so I prefer this over adding a `Clone` bound to the assoc type definition (i.e. `type Fetch: Clone`) even though that would also solve the other listed things here. - Remove a bunch of `QueryFetch<'w, Q>: Clone` bounds from our API as now all fetches can be "cloned" for use in `iter_combinations`. This should also help avoid the type inference regression ptrification introduced where `for<'a> QueryFetch<'a, Q>: Trait` bounds misbehave since we no longer need any of those kind of higher ranked bounds (although in practice we had none anyway). - Stop being able to "forget" to implement clone for fetches, we've had a lot of issues where either `derive(Clone)` was used instead of a manual impl (so we ended up with too tight bounds on the impl) or flat out forgot to implement Clone at all. With this change all fetches are able to be cloned for `iter_combinations` so this will no longer be possible to mess up. On an unrelated note, while making this PR I realised we probably want safety invariants on `archetype/table_fetch` that nothing aliases the table_row/archetype_index according to the access we set. --- ## Changelog `Clone` and `Copy` were removed from all `Fetch` types. ## Migration Guide - Call `WorldQuery::clone_fetch` instead of `fetch.clone()`. Make sure to add safety comments :) |
||
|
|
45e5eb1db3 |
Remove ExactSizeIterator from QueryCombinationIter (#5895)
# Objective - `QueryCombinationIter` can have sizes greater than `usize::MAX`. - Fixes #5846 ## Solution - Only the implementation of `ExactSizeIterator` has been removed. Instead of using `query_combination.len()`, you can use `query_combination.size_hint().0` to get the same value as before. --- ## Migration Guide - Switch to using other methods of getting the length. |
||
|
|
01aedc8431 |
Spawn now takes a Bundle (#6054)
# Objective Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands). ## Solution All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input: ```rust // before: commands .spawn() .insert((A, B, C)); world .spawn() .insert((A, B, C); // after commands.spawn((A, B, C)); world.spawn((A, B, C)); ``` All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api. By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`). This improves spawn performance by over 10%:  To take this measurement, I added a new `world_spawn` benchmark. Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main. **Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).** --- ## Changelog - All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input - All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api - World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior. ## Migration Guide ```rust // Old (0.8): commands .spawn() .insert_bundle((A, B, C)); // New (0.9) commands.spawn((A, B, C)); // Old (0.8): commands.spawn_bundle((A, B, C)); // New (0.9) commands.spawn((A, B, C)); // Old (0.8): let entity = commands.spawn().id(); // New (0.9) let entity = commands.spawn_empty().id(); // Old (0.8) let entity = world.spawn().id(); // New (0.9) let entity = world.spawn_empty(); ``` |
||
|
|
cd15f0f5be |
Accept Bundles for insert and remove. Deprecate insert/remove_bundle (#6039)
# Objective Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there. ## Solution - Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World) - Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection` - Add `remove_intersection` --- ## Changelog - Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World) - `insert_bundle` and `remove_bundle` are deprecated ## Migration Guide Replace `insert_bundle` with `insert`: ```rust // Old (0.8) commands.spawn().insert_bundle(SomeBundle::default()); // New (0.9) commands.spawn().insert(SomeBundle::default()); ``` Replace `remove_bundle` with `remove`: ```rust // Old (0.8) commands.entity(some_entity).remove_bundle::<SomeBundle>(); // New (0.9) commands.entity(some_entity).remove::<SomeBundle>(); ``` Replace `remove_bundle_intersection` with `remove_intersection`: ```rust // Old (0.8) world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>(); // New (0.9) world.entity_mut(some_entity).remove_intersection::<SomeBundle>(); ``` Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves: ```rust // Old (0.8) commands.spawn() .insert_bundle(SomeBundle::default()) .insert(SomeComponent); // New (0.9) - Option 1 commands.spawn().insert(( SomeBundle::default(), SomeComponent, )) // New (0.9) - Option 2 commands.spawn_bundle(( SomeBundle::default(), SomeComponent, )) ``` ## Next Steps Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`. |
||
|
|
d0e294c86b |
Query filter types must be ReadOnlyWorldQuery (#6008)
# Objective Fixes Issue #6005. ## Solution Replaced WorldQuery with ReadOnlyWorldQuery on F generic in Query filters and QueryState to restrict its trait bound. ## Migration Guide Query filter (`F`) generics are now bound by `ReadOnlyWorldQuery`, rather than `WorldQuery`. If for some reason you were requesting `Query<&A, &mut B>`, please use `Query<&A, With<B>>` instead. |
||
|
|
83a9e16158 |
Replace many_for_each_mut with iter_many_mut. (#5402)
# Objective
Replace `many_for_each_mut` with `iter_many_mut` using the same tricks to avoid aliased mutability that `iter_combinations_mut` uses.
<sub>I tried rebasing the draft PR I made for this before and it died. F</sub>
## Why
`many_for_each_mut` is worse for a few reasons:
1. The closure prevents the use of `continue`, `break`, and `return` behaves like a limited `continue`.
2. rustfmt will crumple it and double the indentation when the line gets too long.
```rust
query.many_for_each_mut(
&entity_list,
|(mut transform, velocity, mut component_c)| {
// Double trouble.
},
);
```
3. It is more surprising to have `many_for_each_mut` as a mutable counterpart to `iter_many` than `iter_many_mut`.
4. It required a separate unsafe fn; more unsafe code to maintain.
5. The `iter_many_mut` API matches the existing `iter_combinations_mut` API.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
|
||
|
|
1ac8a476cf |
remove QF generics from all Query/State methods and types (#5170)
# Objective remove `QF` generics from a bunch of types and methods on query related items. this has a few benefits: - simplifies type signatures `fn iter(&self) -> QueryIter<'_, 's, Q::ReadOnly, F::ReadOnly>` is (imo) conceptually simpler than `fn iter(&self) -> QueryIter<'_, 's, Q, ROQueryFetch<'_, Q>, F>` - `Fetch` is mostly an implementation detail but previously we had to expose it on every `iter` `get` etc method - Allows us to potentially in the future simplify the `WorldQuery` trait hierarchy by removing the `Fetch` trait ## Solution remove the `QF` generic and add a way to (unsafely) turn `&QueryState<Q1, F1>` into `&QueryState<Q2, F2>` --- ## Changelog/Migration Guide The `QF` generic was removed from various `Query` iterator types and some methods, you should update your code to use the type of the corresponding worldquery of the fetch type that was being used, or call `as_readonly`/`as_nop` to convert a querystate to the appropriate type. For example: `.get_single_unchecked_manual::<ROQueryFetch<Q>>(..)` -> `.as_readonly().get_single_unchecked_manual(..)` `my_field: QueryIter<'w, 's, Q, ROQueryFetch<'w, Q>, F>` -> `my_field: QueryIter<'w, 's, Q::ReadOnly, F::ReadOnly>` |
||
|
|
6c06fc5b7c |
Add ExactSizeIterator implementation for QueryCombinatonIter (#5148)
Following https://github.com/bevyengine/bevy/pull/5124 I decided to add the `ExactSizeIterator` impl for `QueryCombinationIter`. Also: - Clean up the tests for `size_hint` and `len` for both the normal `QueryIter` and `QueryCombinationIter`. - Add tests to `QueryCombinationIter` when it shouldn't be `ExactSizeIterator` --- ## Changelog - Added `ExactSizeIterator` implementation for `QueryCombinatonIter` |
||
|
|
1dbb1f7b20 |
Allow iter combinations on custom world queries (#5286)
# Objective - `.iter_combinations_*()` cannot be used on custom derived `WorldQuery`, so this fixes that - Fixes #5284 ## Solution - `#[derive(Clone)]` on the `Fetch` of the proc macro derive. - `#[derive(Clone)]` for `AnyOf` to satisfy tests. |
||
|
|
6e50b249a4 |
Update ExactSizeIterator impl to support archetypal filters (With, Without) (#5124)
# Objective - Fixes #3142 ## Solution - Done according to #3142 - Created new marker trait `ArchetypeFilter` - Implement said trait to: - `With<T>` - `Without<T>` - tuples containing only types that implement `ArchetypeFilter`, from 0 to 15 elements - `Or<T>` where T is a tuple as described previously - Changed `ExactSizeIterator` impl to include a new generic that must implement `WorldQuery` and `ArchetypeFilter` - Added new tests --- ## Changelog ### Added - `Query`s with archetypal filters can now use `.iter().len()` to get the exact size of the iterator. |
||
|
|
9eb69282ef |
Directly copy moved Table components to the target location (#5056)
# Objective Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large. ## Solution This PR does the following: - Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`. - Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column. - Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`. This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged. ## Performance TODO: Microbenchmark This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106). 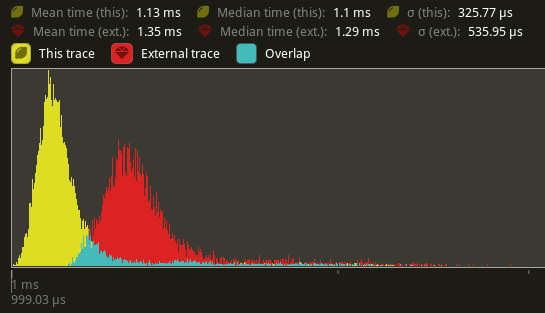 The command heavy `Extract` stage also saw a smaller overall improvement: 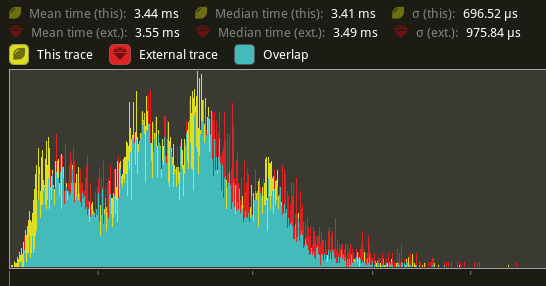 --- ## Changelog Added: `BlobVec::swap_remove_unchecked`. Added: `Column::initialize_from_unchecked`. |
||
|
|
92ddfe8ad4 |
Add methods for querying lists of entities. (#4879)
# Objective
Improve querying ergonomics around collections and iterators of entities.
Example how queries over Children might be done currently.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for child in children.iter() {
if let Ok((bar, children)) = bar_query.get(*child) {
for child in children.iter() {
if let Ok((foo, children)) = foo_query.get(*child) {
// D:
}
}
}
}
}
}
```
Answers #4868
Partially addresses #4864
Fixes #1470
## Solution
Based on the great work by @deontologician in #2563
Added `iter_many` and `many_for_each_mut` to `Query`.
These take a list of entities (Anything that implements `IntoIterator<Item: Borrow<Entity>>`).
`iter_many` returns a `QueryManyIter` iterator over immutable results of a query (mutable data will be cast to an immutable form).
`many_for_each_mut` calls a closure for every result of the query, ensuring not aliased mutability.
This iterator goes over the list of entities in order and returns the result from the query for it. Skipping over any entities that don't match the query.
Also added `unsafe fn iter_many_unsafe`.
### Examples
```rust
#[derive(Component)]
struct Counter {
value: i32
}
#[derive(Component)]
struct Friends {
list: Vec<Entity>,
}
fn system(
friends_query: Query<&Friends>,
mut counter_query: Query<&mut Counter>,
) {
for friends in &friends_query {
for counter in counter_query.iter_many(&friends.list) {
println!("Friend's counter: {:?}", counter.value);
}
counter_query.many_for_each_mut(&friends.list, |mut counter| {
counter.value += 1;
println!("Friend's counter: {:?}", counter.value);
});
}
}
```
Here's how example in the Objective section can be written with this PR.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for (bar, children) in bar_query.iter_many(children) {
for (foo, children) in foo_query.iter_many(children) {
// :D
}
}
}
}
```
## Additional changes
Implemented `IntoIterator` for `&Children` because why not.
## Todo
- Bikeshed!
Co-authored-by: deontologician <deontologician@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
|
||
|
|
f000c2b951 |
Clippy improvements (#4665)
# Objective Follow up to my previous MR #3718 to add new clippy warnings to bevy: - [x] [~~option_if_let_else~~](https://rust-lang.github.io/rust-clippy/master/#option_if_let_else) (reverted) - [x] [redundant_else](https://rust-lang.github.io/rust-clippy/master/#redundant_else) - [x] [match_same_arms](https://rust-lang.github.io/rust-clippy/master/#match_same_arms) - [x] [semicolon_if_nothing_returned](https://rust-lang.github.io/rust-clippy/master/#semicolon_if_nothing_returned) - [x] [explicit_iter_loop](https://rust-lang.github.io/rust-clippy/master/#explicit_iter_loop) - [x] [map_flatten](https://rust-lang.github.io/rust-clippy/master/#map_flatten) There is one commit per clippy warning, and the matching flags are added to the CI execution. To test the CI execution you may run `cargo run -p ci -- clippy` at the root. I choose the add the flags in the `ci` tool crate to avoid having them in every `lib.rs` but I guess it could become an issue with suprise warnings coming up after a commit/push Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
{kind=link}
{kind=link}
{kind=link}