# Objective
I've been tinkering with ECS insertion/removal lately, and noticed that
sparse sets just... don't interact with `InsertMode` at all. Sure
enough, using `insert_if_new` with a sparse component does the same
thing as `insert`.
# Solution
- Add a check in `BundleInfo::write_components` to drop the new value if
the entity already has the component and `InsertMode` is `Keep`.
- Add necessary methods to sparse set internals to fetch the drop
function.
# Testing
Minimal reproduction:
<details>
<summary>Code</summary>
```
use bevy::prelude::*;
fn main() {
App::new()
.add_plugins(DefaultPlugins)
.add_systems(Startup, setup)
.add_systems(PostStartup, component_print)
.run();
}
#[derive(Component)]
#[component(storage = "SparseSet")]
struct SparseComponent(u32);
fn setup(mut commands: Commands) {
let mut entity = commands.spawn_empty();
entity.insert(SparseComponent(1));
entity.insert(SparseComponent(2));
let mut entity = commands.spawn_empty();
entity.insert(SparseComponent(3));
entity.insert_if_new(SparseComponent(4));
}
fn component_print(query: Query<&SparseComponent>) {
for component in &query {
info!("{}", component.0);
}
}
```
</details>
Here it is on Bevy Playground (0.15.3):
https://learnbevy.com/playground?share=2a96a68a81e804d3fdd644a833c1d51f7fa8dd33fc6192fbfd077b082a6b1a41
Output on `main`:
```
2025-05-04T17:50:50.401328Z INFO system{name="fork::component_print"}: fork: 2
2025-05-04T17:50:50.401583Z INFO system{name="fork::component_print"}: fork: 4
```
Output with this PR :
```
2025-05-04T17:51:33.461835Z INFO system{name="fork::component_print"}: fork: 2
2025-05-04T17:51:33.462091Z INFO system{name="fork::component_print"}: fork: 3
```
# Objective
- Fixes#17960
## Solution
- Followed the [edition upgrade
guide](https://doc.rust-lang.org/edition-guide/editions/transitioning-an-existing-project-to-a-new-edition.html)
## Testing
- CI
---
## Summary of Changes
### Documentation Indentation
When using lists in documentation, proper indentation is now linted for.
This means subsequent lines within the same list item must start at the
same indentation level as the item.
```rust
/* Valid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
/* Invalid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
```
### Implicit `!` to `()` Conversion
`!` (the never return type, returned by `panic!`, etc.) no longer
implicitly converts to `()`. This is particularly painful for systems
with `todo!` or `panic!` statements, as they will no longer be functions
returning `()` (or `Result<()>`), making them invalid systems for
functions like `add_systems`. The ideal fix would be to accept functions
returning `!` (or rather, _not_ returning), but this is blocked on the
[stabilisation of the `!` type
itself](https://doc.rust-lang.org/std/primitive.never.html), which is
not done.
The "simple" fix would be to add an explicit `-> ()` to system
signatures (e.g., `|| { todo!() }` becomes `|| -> () { todo!() }`).
However, this is _also_ banned, as there is an existing lint which (IMO,
incorrectly) marks this as an unnecessary annotation.
So, the "fix" (read: workaround) is to put these kinds of `|| -> ! { ...
}` closuers into variables and give the variable an explicit type (e.g.,
`fn()`).
```rust
// Valid
let system: fn() = || todo!("Not implemented yet!");
app.add_systems(..., system);
// Invalid
app.add_systems(..., || todo!("Not implemented yet!"));
```
### Temporary Variable Lifetimes
The order in which temporary variables are dropped has changed. The
simple fix here is _usually_ to just assign temporaries to a named
variable before use.
### `gen` is a keyword
We can no longer use the name `gen` as it is reserved for a future
generator syntax. This involved replacing uses of the name `gen` with
`r#gen` (the raw-identifier syntax).
### Formatting has changed
Use statements have had the order of imports changed, causing a
substantial +/-3,000 diff when applied. For now, I have opted-out of
this change by amending `rustfmt.toml`
```toml
style_edition = "2021"
```
This preserves the original formatting for now, reducing the size of
this PR. It would be a simple followup to update this to 2024 and run
`cargo fmt`.
### New `use<>` Opt-Out Syntax
Lifetimes are now implicitly included in RPIT types. There was a handful
of instances where it needed to be added to satisfy the borrow checker,
but there may be more cases where it _should_ be added to avoid
breakages in user code.
### `MyUnitStruct { .. }` is an invalid pattern
Previously, you could match against unit structs (and unit enum
variants) with a `{ .. }` destructuring. This is no longer valid.
### Pretty much every use of `ref` and `mut` are gone
Pattern binding has changed to the point where these terms are largely
unused now. They still serve a purpose, but it is far more niche now.
### `iter::repeat(...).take(...)` is bad
New lint recommends using the more explicit `iter::repeat_n(..., ...)`
instead.
## Migration Guide
The lifetimes of functions using return-position impl-trait (RPIT) are
likely _more_ conservative than they had been previously. If you
encounter lifetime issues with such a function, please create an issue
to investigate the addition of `+ use<...>`.
## Notes
- Check the individual commits for a clearer breakdown for what
_actually_ changed.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
This pr uses the `extern crate self as` trick to make proc macros behave
the same way inside and outside bevy.
# Objective
- Removes noise introduced by `crate as` in the whole bevy repo.
- Fixes#17004.
- Hardens proc macro path resolution.
## TODO
- [x] `BevyManifest` needs cleanup.
- [x] Cleanup remaining `crate as`.
- [x] Add proper integration tests to the ci.
## Notes
- `cargo-manifest-proc-macros` is written by me and based/inspired by
the old `BevyManifest` implementation and
[`bkchr/proc-macro-crate`](https://github.com/bkchr/proc-macro-crate).
- What do you think about the new integration test machinery I added to
the `ci`?
More and better integration tests can be added at a later stage.
The goal of these integration tests is to simulate an actual separate
crate that uses bevy. Ideally they would lightly touch all bevy crates.
## Testing
- Needs RA test
- Needs testing from other users
- Others need to run at least `cargo run -p ci integration-test` and
verify that they work.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Background
In `no_std` compatible crates, there is often an `std` feature which
will allow access to the standard library. Currently, with the `std`
feature _enabled_, the
[`std::prelude`](https://doc.rust-lang.org/std/prelude/index.html) is
implicitly imported in all modules. With the feature _disabled_, instead
the [`core::prelude`](https://doc.rust-lang.org/core/prelude/index.html)
is implicitly imported. This creates a subtle and pervasive issue where
`alloc` items _may_ be implicitly included (if `std` is enabled), or
must be explicitly included (if `std` is not enabled).
# Objective
- Make the implicit imports for `no_std` crates consistent regardless of
what features are/not enabled.
## Solution
- Replace the `cfg_attr` "double negative" `no_std` attribute with
conditional compilation to _include_ `std` as an external crate.
```rust
// Before
#![cfg_attr(not(feature = "std"), no_std)]
// After
#![no_std]
#[cfg(feature = "std")]
extern crate std;
```
- Fix imports that are currently broken but are only now visible with
the above fix.
## Testing
- CI
## Notes
I had previously used the "double negative" version of `no_std` based on
general consensus that it was "cleaner" within the Rust embedded
community. However, this implicit prelude issue likely was considered
when forming this consensus. I believe the reason why is the items most
affected by this issue are provided by the `alloc` crate, which is
rarely used within embedded but extensively used within Bevy.
# Objective
- Fixes#6370
- Closes#6581
## Solution
- Added the following lints to the workspace:
- `std_instead_of_core`
- `std_instead_of_alloc`
- `alloc_instead_of_core`
- Used `cargo +nightly fmt` with [item level use
formatting](https://rust-lang.github.io/rustfmt/?version=v1.6.0&search=#Item%5C%3A)
to split all `use` statements into single items.
- Used `cargo clippy --workspace --all-targets --all-features --fix
--allow-dirty` to _attempt_ to resolve the new linting issues, and
intervened where the lint was unable to resolve the issue automatically
(usually due to needing an `extern crate alloc;` statement in a crate
root).
- Manually removed certain uses of `std` where negative feature gating
prevented `--all-features` from finding the offending uses.
- Used `cargo +nightly fmt` with [crate level use
formatting](https://rust-lang.github.io/rustfmt/?version=v1.6.0&search=#Crate%5C%3A)
to re-merge all `use` statements matching Bevy's previous styling.
- Manually fixed cases where the `fmt` tool could not re-merge `use`
statements due to conditional compilation attributes.
## Testing
- Ran CI locally
## Migration Guide
The MSRV is now 1.81. Please update to this version or higher.
## Notes
- This is a _massive_ change to try and push through, which is why I've
outlined the semi-automatic steps I used to create this PR, in case this
fails and someone else tries again in the future.
- Making this change has no impact on user code, but does mean Bevy
contributors will be warned to use `core` and `alloc` instead of `std`
where possible.
- This lint is a critical first step towards investigating `no_std`
options for Bevy.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
Enabled `check-private-items` in `clippy.toml` and then fixed the
resulting errors. Most of these were simply misformatted and of the
remaining:
- ~Added `#[allow(clippy::missing_safety_doc)]` to~ Removed unsafe from
a pair of functions in `bevy_utils/futures` which are only unsafe so
that they can be passed to a function which requires `unsafe fn`
- Removed `unsafe` from `UnsafeWorldCell::observers` as from what I can
tell it is always safe like `components`, `bundles` etc. (this should be
checked)
- Added safety docs to:
- `Bundles::get_storage_unchecked`: Based on the function that writes to
`dynamic_component_storages`
- `Bundles::get_storages_unchecked`: Based on the function that writes
to `dynamic_bundle_storages`
- `QueryIterationCursor::init_empty`: Duplicated from `init`
- `QueryIterationCursor::peek_last`: Thanks Giooschi (also added
internal unsafe blocks)
- `tests::drop_ptr`: Moved safety comment out to the doc string
This lint would also apply to `missing_errors_doc`, `missing_panics_doc`
and `unnecessary_safety_doc` if we chose to enable any of those at some
point, although there is an open
[issue](https://github.com/rust-lang/rust-clippy/issues/13074) to
separate these options.
# Objective
- fix#12853
- Make `Table::allocate` faster
## Solution
The PR consists of multiple steps:
1) For the component data: create a new data-structure that's similar to
`BlobVec` but doesn't store `len` & `capacity` inside of it: "BlobArray"
(name suggestions welcome)
2) For the `Tick` data: create a new data-structure that's similar to
`ThinSlicePtr` but supports dynamic reallocation: "ThinArrayPtr" (name
suggestions welcome)
3) Create a new data-structure that's very similar to `Column` that
doesn't store `len` & `capacity` inside of it: "ThinColumn"
4) Adjust the `Table` implementation to use `ThinColumn` instead of
`Column`
The result is that only one set of `len` & `capacity` is stored in
`Table`, in `Table::entities`
### Notes Regarding Performance
Apart from shaving off some excess memory in `Table`, the changes have
also brought noteworthy performance improvements:
The previous implementation relied on `Vec::reserve` &
`BlobVec::reserve`, but that redundantly repeated the same if statement
(`capacity` == `len`). Now that check could be made at the `Table` level
because the capacity and length of all the columns are synchronized;
saving N branches per allocation. The result is a respectable
performance improvement per every `Table::reserve` (and subsequently
`Table::allocate`) call.
I'm hesitant to give exact numbers because I don't have a lot of
experience in profiling and benchmarking, but these are the results I
got so far:
*`add_remove_big/table` benchmark after the implementation:*

*`add_remove_big/table` benchmark in main branch (measured in comparison
to the implementation):*

*`add_remove_very_big/table` benchmark after the implementation:*

*`add_remove_very_big/table` benchmark in main branch (measured in
comparison to the implementation):*

cc @james7132 to verify
---
## Changelog
- New data-structure that's similar to `BlobVec` but doesn't store `len`
& `capacity` inside of it: `BlobArray`
- New data-structure that's similar to `ThinSlicePtr` but supports
dynamic allocation:`ThinArrayPtr`
- New data-structure that's very similar to `Column` that doesn't store
`len` & `capacity` inside of it: `ThinColumn`
- Adjust the `Table` implementation to use `ThinColumn` instead of
`Column`
- New benchmark: `add_remove_very_big` to benchmark the performance of
spawning a lot of entities with a lot of components (15) each
## Migration Guide
`Table` now uses `ThinColumn` instead of `Column`. That means that
methods that previously returned `Column`, will now return `ThinColumn`
instead.
`ThinColumn` has a much more limited and low-level API, but you can
still achieve the same things in `ThinColumn` as you did in `Column`.
For example, instead of calling `Column::get_added_tick`, you'd call
`ThinColumn::get_added_ticks_slice` and index it to get the specific
added tick.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Fixes#14974
## Solution
- Replace all* instances of `NonZero*` with `NonZero<*>`
## Testing
- CI passed locally.
---
## Notes
Within the `bevy_reflect` implementations for `std` types,
`impl_reflect_value!()` will continue to use the type aliases instead,
as it inappropriately parses the concrete type parameter as a generic
argument. If the `ZeroablePrimitive` trait was stable, or the macro
could be modified to accept a finite list of types, then we could fully
migrate.
# Objective
Fixes#14782
## Solution
Enable the lint and fix all upcoming hints (`--fix`). Also tried to
figure out the false-positive (see review comment). Maybe split this PR
up into multiple parts where only the last one enables the lint, so some
can already be merged resulting in less many files touched / less
potential for merge conflicts?
Currently, there are some cases where it might be easier to read the
code with the qualifier, so perhaps remove the import of it and adapt
its cases? In the current stage it's just a plain adoption of the
suggestions in order to have a base to discuss.
## Testing
`cargo clippy` and `cargo run -p ci` are happy.
# Objective
Often there are reasons to insert some components (e.g. Transform)
separately from the rest of a bundle (e.g. PbrBundle). However `insert`
overwrites existing components, making this difficult.
See also issue #14397Fixes#2054.
## Solution
This PR adds the method `insert_if_new` to EntityMut and Commands, which
is the same as `insert` except that the old component is kept in case of
conflicts.
It also renames some internal enums (from `ComponentStatus::Mutated` to
`Existing`), to reflect the possible change in meaning.
## Testing
*Did you test these changes? If so, how?*
Added basic unit tests; used the new behavior in my project.
*Are there any parts that need more testing?*
There should be a test that the change time isn't set if a component is
not overwritten; I wasn't sure how to write a test for that case.
*How can other people (reviewers) test your changes? Is there anything
specific they need to know?*
`cargo test` in the bevy_ecs project.
*If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?*
Only tested on Windows, but it doesn't touch anything platform-specific.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective
- Fixes#12976
## Solution
This one is a doozy.
- Run `cargo +beta clippy --workspace --all-targets --all-features` and
fix all issues
- This includes:
- Moving inner attributes to be outer attributes, when the item in
question has both inner and outer attributes
- Use `ptr::from_ref` in more scenarios
- Extend the valid idents list used by `clippy:doc_markdown` with more
names
- Use `Clone::clone_from` when possible
- Remove redundant `ron` import
- Add backticks to **so many** identifiers and items
- I'm sorry whoever has to review this
---
## Changelog
- Added links to more identifiers in documentation.
# Objective
- Part of #11590
- Fix `unsafe_op_in_unsafe_fn` for trivial cases in bevy_ecs
## Solution
Fix `unsafe_op_in_unsafe_fn` in bevy_ecs for trivial cases, i.e., add an
`unsafe` block when the safety comment already exists or add a comment
like "The invariants are uphold by the caller".
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
When `BlobVec::reserve` is called with an argument causing capacity
overflow, in release build capacity overflow is ignored, and capacity is
decreased.
I'm not sure it is possible to exploit this issue using public API of
`bevy_ecs`, but better fix it anyway.
## Solution
Check for capacity overflow.
# Objective
Fix ci hang, so we can merge pr's again.
## Solution
- switch ppa action to use mesa stable versions
https://launchpad.net/~kisak/+archive/ubuntu/turtle
- use commit from #11123
---------
Co-authored-by: Stepan Koltsov <stepan.koltsov@gmail.com>
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
Upon closer inspection, there are a few functions in the ECS that are
not being inlined, even with the highest optimizations and LTO enabled:
- Almost all
[WorldQuery::init_fetch](9fd5f20e25/results/query_get.s (L57))
calls. Affects `Query::get` calls in hot loops. In particular, the
`WorldQuery` implementation for `()` is used *everywhere* as the default
filter and is effectively a no-op.
-
[Entities::get](9fd5f20e25/results/query_get.s (L39)).
Affects `Query::get`, `World::get`, and any component insertion or
removal.
-
[Entities::set](9fd5f20e25/results/entity_remove.s (L2487)).
Affects any component insertion or removal.
-
[Tick::new](9fd5f20e25/results/entity_insert.s (L1368)).
I've only seen this in component insertion and spawning.
- ArchetypeRow::new
- BlobVec::set_len
Almost all of these have trivial or even empty implementations or have
significant opportunity to be optimized into surrounding code when
inlined with LTO enabled.
## Solution
Inline them
# Objective
The usages of the unsafe function `byte_add` are not properly documented.
Follow-up to #7151.
## Solution
Add safety comments to each call-site.
# Objective
- The function `BlobVec::replace_unchecked` has informal use of safety comments.
- This function does strange things with `OwningPtr` in order to get around the borrow checker.
## Solution
- Put safety comments in front of each unsafe operation. Describe the specific invariants of each operation and how they apply here.
- Added a guard type `OnDrop`, which is used to simplify ownership transfer in case of a panic.
---
## Changelog
+ Added the guard type `bevy_utils::OnDrop`.
+ Added conversions from `Ptr`, `PtrMut`, and `OwningPtr` to `NonNull<u8>`.
# Objective
Improve safety testing when using `bevy_ptr` types. This is a follow-up to #7113.
## Solution
Add a debug-only assertion that pointers are aligned when casting to a concrete type. This should very quickly catch any unsoundness from unaligned pointers, even without miri. However, this can have a large negative perf impact on debug builds.
---
## Changelog
Added: `Ptr::deref` will now panic in debug builds if the pointer is not aligned.
Added: `PtrMut::deref_mut` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::read` will now panic in debug builds if the pointer is not aligned.
Added: `OwningPtr::drop_as` will now panic in debug builds if the pointer is not aligned.
# Objective
BlobVec currently relies on a scratch piece of memory allocated at initialization to make a temporary copy of a component when using `swap_remove_and_{forget/drop}`. This is potentially suboptimal as it writes to a, well-known, but random part of memory instead of using the stack.
## Solution
As the `FIXME` in the file states, replace `swap_scratch` with a call to `swap_nonoverlapping::<u8>`. The swapped last entry is returned as a `OwnedPtr`.
In theory, this should be faster as the temporary swap is allocated on the stack, `swap_nonoverlapping` allows for easier vectorization for bigger types, and the same memory is used between the swap and the returned `OwnedPtr`.
# Objective
Fixes#6615.
`BlobVec` does not respect alignment for zero-sized types, which results in UB whenever a ZST with alignment other than 1 is used in the world.
## Solution
Add the fn `bevy_ptr::dangling_with_align`.
---
## Changelog
+ Added the function `dangling_with_align` to `bevy_ptr`, which creates a well-aligned dangling pointer to a type whose alignment is not known at compile time.
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
The first leak:
```rust
#[test]
fn blob_vec_drop_empty_capacity() {
let item_layout = Layout:🆕:<Foo>();
let drop = drop_ptr::<Foo>;
let _ = unsafe { BlobVec::new(item_layout, Some(drop), 0) };
}
```
this is because we allocate the swap scratch in blobvec regardless of what the capacity is, but we only deallocate if capacity is > 0
The second leak:
```rust
#[test]
fn panic_while_overwriting_component() {
let helper = DropTestHelper::new();
let res = panic::catch_unwind(|| {
let mut world = World::new();
world
.spawn()
.insert(helper.make_component(true, 0))
.insert(helper.make_component(false, 1));
println!("Done inserting! Dropping world...");
});
let drop_log = helper.finish(res);
assert_eq!(
&*drop_log,
[
DropLogItem::Create(0),
DropLogItem::Create(1),
DropLogItem::Drop(0),
]
);
}
```
this is caused by us not running the drop impl on the to-be-inserted component if the drop impl of the overwritten component panics
---
managed to figure out where the leaks were by using this 10/10 command
```
cargo --quiet test --lib -- --list | sed 's/: test$//' | MIRIFLAGS="-Zmiri-disable-isolation" xargs -n1 cargo miri test --lib -- --exact
```
which runs every test one by one rather than all at once which let miri actually tell me which test had the leak 🙃
# Objective
Speed up entity moves between tables by reducing the number of copies conducted. Currently three separate copies are conducted: `src[index] -> swap scratch`, `src[last] -> src[index]`, and `swap scratch -> dst[target]`. The first and last copies can be merged by directly using the copy `src[index] -> dst[target]`, which can save quite some time if the component(s) in question are large.
## Solution
This PR does the following:
- Adds `BlobVec::swap_remove_unchecked(usize, PtrMut<'_>)`, which is identical to `swap_remove_and_forget_unchecked`, but skips the `swap_scratch` and directly copies the component into the provided `PtrMut<'_>`.
- Build `Column::initialize_from_unchecked(&mut Column, usize, usize)` on top of it, which uses the above to directly initialize a row from another column.
- Update most of the table move APIs to use `initialize_from_unchecked` instead of a combination of `swap_remove_and_forget_unchecked` and `initialize`.
This is an alternative, though orthogonal, approach to achieve the same performance gains as seen in #4853. This (hopefully) shouldn't run into the same Miri limitations that said PR currently does. After this PR, `swap_remove_and_forget_unchecked` is still in use for Resources and swap_scratch likely still should be removed, so #4853 still has use, even if this PR is merged.
## Performance
TODO: Microbenchmark
This PR shows similar improvements to commands that add or remove table components that result in a table move. When tested on `many_cubes sphere`, some of the more command heavy systems saw notable improvements. In particular, `prepare_uniform_components<T>`, this saw a reduction in time from 1.35ms to 1.13ms (a 16.3% improvement) on my local machine, a similar if not slightly better gain than what #4853 showed [here](https://github.com/bevyengine/bevy/pull/4853#issuecomment-1159346106).
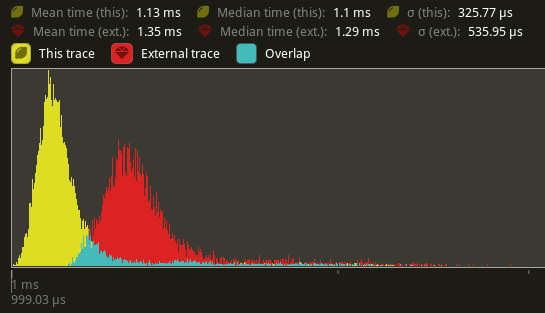
The command heavy `Extract` stage also saw a smaller overall improvement:
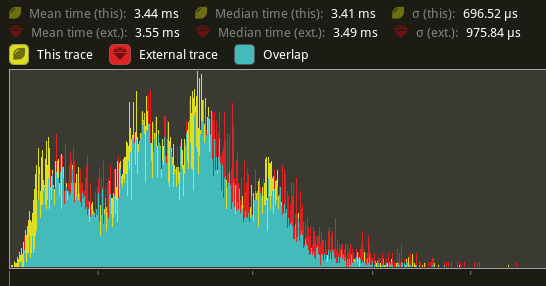
---
## Changelog
Added: `BlobVec::swap_remove_unchecked`.
Added: `Column::initialize_from_unchecked`.
# Objective
Closes#1557. Partially addresses #3362.
Cleanup the public facing API for storage types. Most of these APIs are difficult to use safely when directly interfacing with these types, and is also currently impossible to interact with in normal ECS use as there is no `World::storages_mut`. The majority of these types should be easy enough to read, and perhaps mutate the contents, but never structurally altered without the same checks in the rest of bevy_ecs code. This both cleans up the public facing types and helps use unused code detection to remove a few of the APIs we're not using internally.
## Solution
- Mark all APIs that take `&mut T` under `bevy_ecs::storage` as `pub(crate)` or `pub(super)`
- Cleanup after it all.
Entire type visibility changes:
- `BlobVec` is `pub(super)`, only storage code should be directly interacting with it.
- `SparseArray` is now `pub(crate)` for the entire type. It's an implementation detail for `Table` and `(Component)SparseSet`.
- `TableMoveResult` is now `pub(crate)
---
## Changelog
TODO
## Migration Guide
Dear God, I hope not.
# Objective
Even if bevy itself does not provide any builtin scripting or modding APIs, it should have the foundations for building them yourself.
For that it should be enough to have APIs that are not tied to the actual rust types with generics, but rather accept `ComponentId`s and `bevy_ptr` ptrs.
## Solution
Add the following APIs to bevy
```rust
fn EntityRef::get_by_id(ComponentId) -> Option<Ptr<'w>>;
fn EntityMut::get_by_id(ComponentId) -> Option<Ptr<'_>>;
fn EntityMut::get_mut_by_id(ComponentId) -> Option<MutUntyped<'_>>;
fn World::get_resource_by_id(ComponentId) -> Option<Ptr<'_>>;
fn World::get_resource_mut_by_id(ComponentId) -> Option<MutUntyped<'_>>;
// Safety: `value` must point to a valid value of the component
unsafe fn World::insert_resource_by_id(ComponentId, value: OwningPtr);
fn ComponentDescriptor::new_with_layout(..) -> Self;
fn World::init_component_with_descriptor(ComponentDescriptor) -> ComponentId;
```
~~This PR would definitely benefit from #3001 (lifetime'd pointers) to make sure that the lifetimes of the pointers are valid and the my-move pointer in `insert_resource_by_id` could be an `OwningPtr`, but that can be adapter later if/when #3001 is merged.~~
### Not in this PR
- inserting components on entities (this is very tied to types with bundles and the `BundleInserter`)
- an untyped version of a query (needs good API design, has a large implementation complexity, can be done in a third-party crate)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- We do a lot of function pointer calls in a hot loop (clearing entities in render). This is slow, since calling function pointers cannot be optimised out. We can avoid that in the cases where the function call is a no-op.
- Alternative to https://github.com/bevyengine/bevy/pull/2897
- On my machine, in `many_cubes`, this reduces dropping time from ~150μs to ~80μs.
## Solution
- Make `drop` in `BlobVec` an `Option`, recording whether the given drop impl is required or not.
- Note that this does add branching in some cases - we could consider splitting this into two fields, i.e. unconditionally call the `drop` fn pointer.
- My intuition of how often types stored in `World` should have non-trivial drops makes me think that would be slower, however.
N.B. Even once this lands, we should still test having a 'drop_multiple' variant - for types with a real `Drop` impl, the current implementation is definitely optimal.
1. change `PtrMut::as_ptr(self)` and `OwnedPtr::as_ptr(self)` to take `&self`, otherwise printing the pointer will prevent doing anything else afterwards
2. make all `as_ptr` methods safe. There's nothing unsafe about obtaining a pointer, these kinds of methods are safe in std as well [str::as_ptr](https://doc.rust-lang.org/stable/std/primitive.str.html#method.as_ptr), [Rc::as_ptr](https://doc.rust-lang.org/stable/std/rc/struct.Rc.html#method.as_ptr)
3. rename `offset`/`add` to `byte_offset`/`byte_add`. The unprefixed methods in std add in increments of `std::mem::size_of::<T>`, not in bytes. There's a PR for rust to add these byte_ methods https://github.com/rust-lang/rust/pull/95643 and at the call site it makes it much more clear that you need to do `.byte_add(i * layout_size)` instead of `.add(i)`
# Objective
The pointer types introduced in #3001 are useful not just in `bevy_ecs`, but also in crates like `bevy_reflect` (#4475) or even outside of bevy.
## Solution
Extract `Ptr<'a>`, `PtrMut<'a>`, `OwnedPtr<'a>`, `ThinSlicePtr<'a, T>` and `UnsafeCellDeref` from `bevy_ecs::ptr` into `bevy_ptr`.
**Note:** `bevy_ecs` still reexports the `bevy_ptr` as `bevy_ecs::ptr` so that crates like `bevy_transform` can use the `Bundle` derive without needing to depend on `bevy_ptr` themselves.
# Objective
The `Ptr` types gives free access to the underlying `NonNull<u8>`, which adds more publicly visible pointer wrangling than there needs to be. There are also a few edge cases where Ptr types could be more readily utilized for properly validating the soundness of ECS operations.
## Solution
- Replace `*Ptr(Mut)::inner` with `cast` which requires a concrete type to give the pointer. This function could also have a `debug_assert` with an alignment check to ensure that the pointer is aligned properly, but is currently not included.
- Use `OwningPtr::read` in ECS macros over casting the inner pointer around.
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
# Objective
- Storages are used to store the ECS data.
- They're undocumented.
## Solution
- Add some very basic docs.
## Notes
- Some of this was hard to immediately understand when reading the code, so suggestions on improvements / things to add are particularly welcome.
# Objective
I thought I'd have a go a trying to fix#2597.
Hopefully fixes#2597.
## Solution
I reused the memory pointed to by the value parameter, that is already required by `insert` to not be dropped, to contain the extracted value while dropping it.
# Objective
There is currently a 1-to-1 mapping between components and real rust types. This means that it is impossible for multiple components to be represented by the same rust type or for a component to not have a rust type at all. This means that component types can't be defined in languages other than rust like necessary for scripting or sandboxed (wasm?) plugins.
## Solution
Refactor `ComponentDescriptor` and `Bundle` to remove `TypeInfo`. `Bundle` now uses `ComponentId` instead. `ComponentDescriptor` is now always created from a rust type instead of through the `TypeInfo` indirection. A future PR may make it possible to construct a `ComponentDescriptor` from it's fields without a rust type being involved.
When dropping the data, we originally only checked the size of an individual item instead of the size of the allocation. However with a capacity of 0, we attempt to deallocate a pointer which was not the result of allocation. That is, an item of `Layout { size_: 8, align_: 8 }` produces an array of `Layout { size_: 0, align_: 8 }` when `capacity = 0`.
Fixes#2294
Continuing the work on reducing the safety footguns in the code, I've removed one extra `UnsafeCell` in favour of safe `Cell` usage inisde `ComponentTicks`. That change led to discovery of misbehaving component insert logic, where data wasn't properly dropped when overwritten. Apart from that being fixed, some method names were changed to better convey the "initialize new allocation" and "replace existing allocation" semantic.
Depends on #2221, I will rebase this PR after the dependency is merged. For now, review just the last commit.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
I've noticed that we are overusing interior mutability of the Table data, where in many cases we already own a unique reference to it. That prompted a slight refactor aiming to reduce number of safety constraints that must be manually upheld. Now the majority of those are just about avoiding bound checking, which is relatively easy to prove right.
Another aspect is reducing the complexity of Table struct. Notably, we don't ever use archetypes stored there, so this whole thing goes away. Capacity and grow amount were mostly superficial, as we are already using Vecs inside anyway, so I've got rid of those too. Now the overall table capacity is being driven by the internal entity Vec capacity. This has a side effect of automatically implementing exponential growth pattern for BitVecs reallocations inside Table, which to my measurements slightly improves performance in tests that are heavy on inserts. YMMV, but I hope that those tests were at least remotely correct.
{kind=link}
{kind=link}