# Objective
- `DynamicUniformBuffer` tries to create a buffer as soon as the changed
flag is set to true. This doesn't work correctly when the buffer wasn't
already created. This currently creates a crash because it's trying to
create a buffer of size 0 if the flag is set but there's no buffer yet.
## Solution
- Don't create a changed buffer until there's data that needs to be
written to a buffer.
## Testing
- run `cargo run --example scene_viewer` and see that it doesn't crash
anymore
Fixes#13235
This is an adoption of #12670 plus some documentation fixes. See that PR
for more details.
---
## Changelog
* Renamed `BufferVec` to `RawBufferVec` and added a new `BufferVec`
type.
## Migration Guide
`BufferVec` has been renamed to `RawBufferVec` and a new similar type
has taken the `BufferVec` name.
---------
Co-authored-by: Patrick Walton <pcwalton@mimiga.net>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
This commit implements opt-in GPU frustum culling, built on top of the
infrastructure in https://github.com/bevyengine/bevy/pull/12773. To
enable it on a camera, add the `GpuCulling` component to it. To
additionally disable CPU frustum culling, add the `NoCpuCulling`
component. Note that adding `GpuCulling` without `NoCpuCulling`
*currently* does nothing useful. The reason why `GpuCulling` doesn't
automatically imply `NoCpuCulling` is that I intend to follow this patch
up with GPU two-phase occlusion culling, and CPU frustum culling plus
GPU occlusion culling seems like a very commonly-desired mode.
Adding the `GpuCulling` component to a view puts that view into
*indirect mode*. This mode makes all drawcalls indirect, relying on the
mesh preprocessing shader to allocate instances dynamically. In indirect
mode, the `PreprocessWorkItem` `output_index` points not to a
`MeshUniform` instance slot but instead to a set of `wgpu`
`IndirectParameters`, from which it allocates an instance slot
dynamically if frustum culling succeeds. Batch building has been updated
to allocate and track indirect parameter slots, and the AABBs are now
supplied to the GPU as `MeshCullingData`.
A small amount of code relating to the frustum culling has been borrowed
from meshlets and moved into `maths.wgsl`. Note that standard Bevy
frustum culling uses AABBs, while meshlets use bounding spheres; this
means that not as much code can be shared as one might think.
This patch doesn't provide any way to perform GPU culling on shadow
maps, to avoid making this patch bigger than it already is. That can be
a followup.
## Changelog
### Added
* Frustum culling can now optionally be done on the GPU. To enable it,
add the `GpuCulling` component to a camera.
* To disable CPU frustum culling, add `NoCpuCulling` to a camera. Note
that `GpuCulling` doesn't automatically imply `NoCpuCulling`.
Currently, `MeshUniform`s are rather large: 160 bytes. They're also
somewhat expensive to compute, because they involve taking the inverse
of a 3x4 matrix. Finally, if a mesh is present in multiple views, that
mesh will have a separate `MeshUniform` for each and every view, which
is wasteful.
This commit fixes these issues by introducing the concept of a *mesh
input uniform* and adding a *mesh uniform building* compute shader pass.
The `MeshInputUniform` is simply the minimum amount of data needed for
the GPU to compute the full `MeshUniform`. Most of this data is just the
transform and is therefore only 64 bytes. `MeshInputUniform`s are
computed during the *extraction* phase, much like skins are today, in
order to avoid needlessly copying transforms around on CPU. (In fact,
the render app has been changed to only store the translation of each
mesh; it no longer cares about any other part of the transform, which is
stored only on the GPU and the main world.) Before rendering, the
`build_mesh_uniforms` pass runs to expand the `MeshInputUniform`s to the
full `MeshUniform`.
The mesh uniform building pass does the following, all on GPU:
1. Copy the appropriate fields of the `MeshInputUniform` to the
`MeshUniform` slot. If a single mesh is present in multiple views, this
effectively duplicates it into each view.
2. Compute the inverse transpose of the model transform, used for
transforming normals.
3. If applicable, copy the mesh's transform from the previous frame for
TAA. To support this, we double-buffer the `MeshInputUniform`s over two
frames and swap the buffers each frame. The `MeshInputUniform`s for the
current frame contain the index of that mesh's `MeshInputUniform` for
the previous frame.
This commit produces wins in virtually every CPU part of the pipeline:
`extract_meshes`, `queue_material_meshes`,
`batch_and_prepare_render_phase`, and especially
`write_batched_instance_buffer` are all faster. Shrinking the amount of
CPU data that has to be shuffled around speeds up the entire rendering
process.
| Benchmark | This branch | `main` | Speedup |
|------------------------|-------------|---------|---------|
| `many_cubes -nfc` | 17.259 | 24.529 | 42.12% |
| `many_cubes -nfc -vpi` | 302.116 | 312.123 | 3.31% |
| `many_foxes` | 3.227 | 3.515 | 8.92% |
Because mesh uniform building requires compute shader, and WebGL 2 has
no compute shader, the existing CPU mesh uniform building code has been
left as-is. Many types now have both CPU mesh uniform building and GPU
mesh uniform building modes. Developers can opt into the old CPU mesh
uniform building by setting the `use_gpu_uniform_builder` option on
`PbrPlugin` to `false`.
Below are graphs of the CPU portions of `many-cubes
--no-frustum-culling`. Yellow is this branch, red is `main`.
`extract_meshes`:

It's notable that we get a small win even though we're now writing to a
GPU buffer.
`queue_material_meshes`:

There's a bit of a regression here; not sure what's causing it. In any
case it's very outweighed by the other gains.
`batch_and_prepare_render_phase`:

There's a huge win here, enough to make batching basically drop off the
profile.
`write_batched_instance_buffer`:

There's a massive improvement here, as expected. Note that a lot of it
simply comes from the fact that `MeshInputUniform` is `Pod`. (This isn't
a maintainability problem in my view because `MeshInputUniform` is so
simple: just 16 tightly-packed words.)
## Changelog
### Added
* Per-mesh instance data is now generated on GPU with a compute shader
instead of CPU, resulting in rendering performance improvements on
platforms where compute shaders are supported.
## Migration guide
* Custom render phases now need multiple systems beyond just
`batch_and_prepare_render_phase`. Code that was previously creating
custom render phases should now add a `BinnedRenderPhasePlugin` or
`SortedRenderPhasePlugin` as appropriate instead of directly adding
`batch_and_prepare_render_phase`.
# Objective
Since BufferVec was first introduced, `bytemuck` has added additional
traits with fewer restrictions than `Pod`. Within BufferVec, we only
rely on the constraints of `bytemuck::cast_slice` to a `u8` slice, which
now only requires `T: NoUninit` which is a strict superset of `Pod`
types.
## Solution
Change out the `Pod` generic type constraint with `NoUninit`. Also
taking the opportunity to substitute `cast_slice` with
`must_cast_slice`, which avoids a runtime panic in place of a compile
time failure if `T` cannot be used.
---
## Changelog
Changed: `BufferVec` now supports working with types containing
`NoUninit` but not `Pod` members.
Changed: `BufferVec` will now fail to compile if used with a type that
cannot be safely read from. Most notably, this includes ZSTs, which
would previously always panic at runtime.
# Objective
Make bevy_utils less of a compilation bottleneck. Tackle #11478.
## Solution
* Move all of the directly reexported dependencies and move them to
where they're actually used.
* Remove the UUID utilities that have gone unused since `TypePath` took
over for `TypeUuid`.
* There was also a extraneous bytemuck dependency on `bevy_core` that
has not been used for a long time (since `encase` became the primary way
to prepare GPU buffers).
* Remove the `all_tuples` macro reexport from bevy_ecs since it's
accessible from `bevy_utils`.
---
## Changelog
Removed: Many of the reexports from bevy_utils (petgraph, uuid, nonmax,
smallvec, and thiserror).
Removed: bevy_core's reexports of bytemuck.
## Migration Guide
bevy_utils' reexports of petgraph, uuid, nonmax, smallvec, and thiserror
have been removed.
bevy_core' reexports of bytemuck's types has been removed.
Add them as dependencies in your own crate instead.
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
# Objective
- Supercedes #8872
- Improve sprite rendering performance after the regression in #9236
## Solution
- Use an instance-rate vertex buffer to store per-instance data.
- Store color, UV offset and scale, and a transform per instance.
- Convert Sprite rect, custom_size, anchor, and flip_x/_y to an affine
3x4 matrix and store the transpose of that in the per-instance data.
This is similar to how MeshUniform uses transpose affine matrices.
- Use a special index buffer that has batches of 6 indices referencing 4
vertices. The lower 2 bits indicate the x and y of a quad such that the
corners are:
```
10 11
00 01
```
UVs are implicit but get modified by UV offset and scale The remaining
upper bits contain the instance index.
## Benchmarks
I will compare versus `main` before #9236 because the results should be
as good as or faster than that. Running `bevymark -- 10000 16` on an M1
Max with `main` at `e8b38925` in yellow, this PR in red:
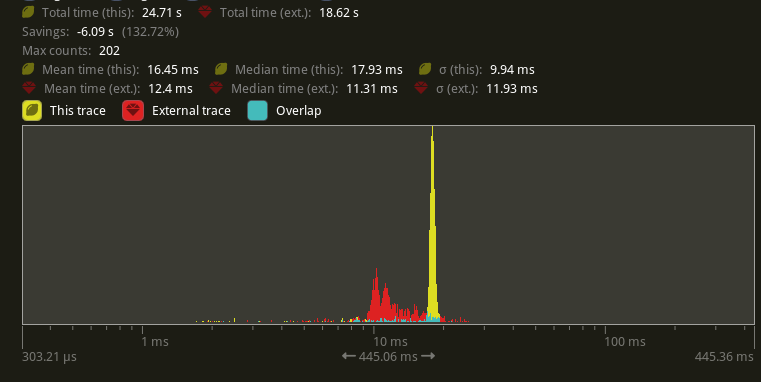
Looking at the median frame times, that's a 37% reduction from before.
---
## Changelog
- Changed: Improved sprite rendering performance by leveraging an
instance-rate vertex buffer.
---------
Co-authored-by: Giacomo Stevanato <giaco.stevanato@gmail.com>
# Objective
- Add a type for uploading a Rust `Vec<T>` to a GPU `array<T>`.
- Makes progress towards https://github.com/bevyengine/bevy/issues/89.
## Solution
- Port @superdump's `BatchedUniformBuffer` to bevy main, as a fallback
for WebGL2, which doesn't support storage buffers.
- Rather than getting an `array<T>` in a shader, you get an `array<T,
N>`, and have to rebind every N elements via dynamic offsets.
- Add `GpuArrayBuffer` to abstract over
`StorageBuffer<Vec<T>>`/`BatchedUniformBuffer`.
## Future Work
Add a shader macro kinda thing to abstract over the following
automatically:
https://github.com/bevyengine/bevy/pull/8204#pullrequestreview-1396911727
---
## Changelog
* Added `GpuArrayBuffer`, `GpuComponentArrayBufferPlugin`,
`GpuArrayBufferable`, and `GpuArrayBufferIndex` types.
* Added `DynamicUniformBuffer::new_with_alignment()`.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Teodor Tanasoaia <28601907+teoxoy@users.noreply.github.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
Co-authored-by: Vincent <9408210+konsolas@users.noreply.github.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
- Fixes#3531
## Solution
- Added an append wrapper to BufferVec based on the function signature
for vec.append()
---
First PR to Bevy. I didn't see any tests for other BufferVec methods
(could have missed them) and currently this method is not used anywhere
in the project. Let me know if there are tests to add or if I should
find somewhere to use append so it is not dead code. The issue mentions
implementing `truncate` and `extend` which were already implemented and
merged
[here](https://github.com/bevyengine/bevy/pull/6833/files#diff-c8fb332382379e383f1811e30c31991b1e0feb38ca436c357971755368012ced)
# Objective
Following #4402, extract systems run on the render world instead of the main world, and allow retained state operations on it's resources. We're currently extracting to `ExtractedJoints` and then copying it twice during Prepare. Once into `SkinnedMeshJoints` and again into the actual GPU buffer.
This makes #4902 obsolete.
## Solution
Cut out the middle copy and directly extract joints into `SkinnedMeshJoints` and remove `ExtractedJoints` entirely.
This also removes the per-frame allocation that is being made to send `ExtractedJoints` into the render world.
## Performance
On my local machine, this halves the time for `prepare_skinned _meshes` on `many_foxes` (195.75us -> 93.93us on average).
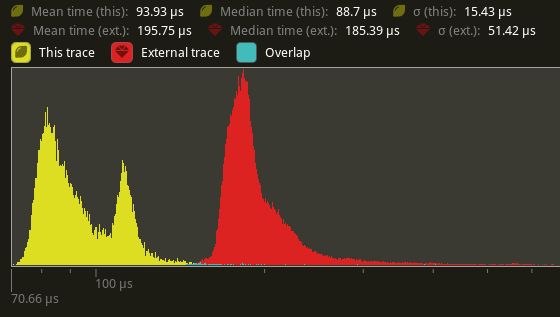
---
## Changelog
Added: `BufferVec::truncate`
Added: `BufferVec::extend`
Changed: `SkinnedMeshJoints::build` now takes a `&mut BufferVec` instead of a `&mut Vec` as a parameter.
Removed: `ExtractedJoints`.
## Migration Guide
`ExtractedJoints` has been removed. Read the bound bones from `SkinnedMeshJoints` instead.
# Objective
- Expose the wgpu debug label on storage buffer types.
## Solution
🐄
- Add an optional cow static string and pass that to the label field of create_buffer_with_data
- This pattern is already used by Bevy for debug tags on bind group and layout descriptors.
---
Example Usage:
A buffer is given a label using the label function. Alternatively a buffer may be labeled when it is created if the default() convention is not used.
Here is the buffer appearing with the correct name in RenderDoc. Previously the buffer would have an anonymous name such as "Buffer223":
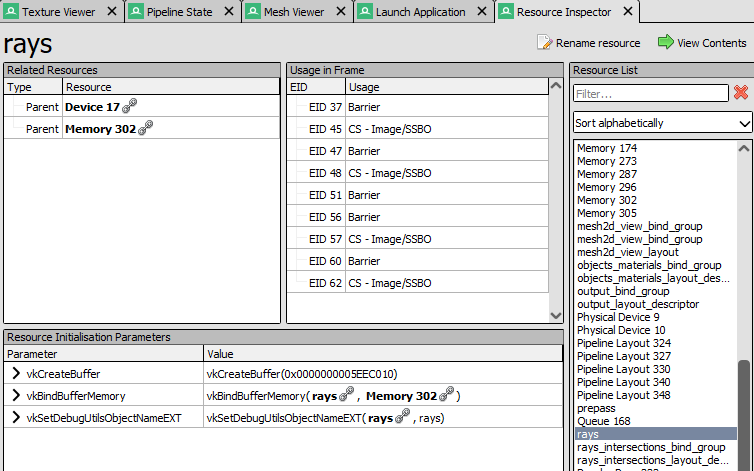
Co-authored-by: rebelroad-reinhart <reinhart@rebelroad.gg>
# Objective
Documents the `BufferVec` render resource.
`BufferVec` is a fairly low level object, that will likely be managed by a higher level API (e.g. through [`encase`](https://github.com/bevyengine/bevy/issues/4272)) in the future. For now, since it is still used by some simple
example crates (e.g. [bevy-vertex-pulling](https://github.com/superdump/bevy-vertex-pulling)), it will be helpful
to provide some simple documentation on what `BufferVec` does.
## Solution
I looked through Discord discussion on `BufferVec`, and found [a comment](https://discord.com/channels/691052431525675048/953222550568173580/956596218857918464 ) by @superdump to be particularly helpful, in the general discussion around `encase`.
I have taken care to clarify where the data is stored (host-side), when the device-side buffer is created (through calls to `reserve`), and when data writes from host to device are scheduled (using `write_buffer` calls).
---
## Changelog
- Added doc string for `BufferVec` and two of its methods: `reserve` and `write_buffer`.
Co-authored-by: Brian Merchant <bhmerchant@gmail.com>
# Objective
The current 2d rendering is specialized to render sprites, we need a generic way to render 2d items, using meshes and materials like we have for 3d.
## Solution
I cloned a good part of `bevy_pbr` into `bevy_sprite/src/mesh2d`, removed lighting and pbr itself, adapted it to 2d rendering, added a `ColorMaterial`, and modified the sprite rendering to break batches around 2d meshes.
~~The PR is a bit crude; I tried to change as little as I could in both the parts copied from 3d and the current sprite rendering to make reviewing easier. In the future, I expect we could make the sprite rendering a normal 2d material, cleanly integrated with the rest.~~ _edit: see <https://github.com/bevyengine/bevy/pull/3460#issuecomment-1003605194>_
## Remaining work
- ~~don't require mesh normals~~ _out of scope_
- ~~add an example~~ _done_
- support 2d meshes & materials in the UI?
- bikeshed names (I didn't think hard about naming, please check if it's fine)
## Remaining questions
- ~~should we add a depth buffer to 2d now that there are 2d meshes?~~ _let's revisit that when we have an opaque render phase_
- ~~should we add MSAA support to the sprites, or remove it from the 2d meshes?~~ _I added MSAA to sprites since it's really needed for 2d meshes_
- ~~how to customize vertex attributes?~~ _#3120_
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This makes the [New Bevy Renderer](#2535) the default (and only) renderer. The new renderer isn't _quite_ ready for the final release yet, but I want as many people as possible to start testing it so we can identify bugs and address feedback prior to release.
The examples are all ported over and operational with a few exceptions:
* I removed a good portion of the examples in the `shader` folder. We still have some work to do in order to make these examples possible / ergonomic / worthwhile: #3120 and "high level shader material plugins" are the big ones. This is a temporary measure.
* Temporarily removed the multiple_windows example: doing this properly in the new renderer will require the upcoming "render targets" changes. Same goes for the render_to_texture example.
* Removed z_sort_debug: entity visibility sort info is no longer available in app logic. we could do this on the "render app" side, but i dont consider it a priority.
{kind=link}
{kind=link}
{kind=link}