6c619397d5
14 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
5ff7062c1c
|
Switch bins from parallel key/value arrays to IndexMaps. (#17819)
Conceptually, bins are ordered hash maps. We currently implement these as a list of keys with an associated hash map. But we already have a data type that implements ordered hash maps directly: `IndexMap`. This patch switches Bevy to use `IndexMap`s for bins. Because we're memory bound, this doesn't affect performance much, but it is cleaner. |
||
|
|
85b366a8a2
|
Cache MeshInputUniform indices in each RenderBin. (#17772)
Currently, we look up each `MeshInputUniform` index in a hash table that maps the main entity ID to the index every frame. This is inefficient, cache unfriendly, and unnecessary, as the `MeshInputUniform` index for an entity remains the same from frame to frame (even if the input uniform changes). This commit changes the `IndexSet` in the `RenderBin` to an `IndexMap` that maps the `MainEntity` to `MeshInputUniformIndex` (a new type that this patch adds for more type safety). On Caldera with parallel `batch_and_prepare_binned_render_phase`, this patch improves that function from 3.18 ms to 2.42 ms, a 31% speedup. |
||
|
|
7fc122ad16
|
Retain bins from frame to frame. (#17698)
This PR makes Bevy keep entities in bins from frame to frame if they haven't changed. This reduces the time spent in `queue_material_meshes` and related functions to near zero for static geometry. This patch uses the same change tick technique that #17567 uses to detect when meshes have changed in such a way as to require re-binning. In order to quickly find the relevant bin for an entity when that entity has changed, we introduce a new type of cache, the *bin key cache*. This cache stores a mapping from main world entity ID to cached bin key, as well as the tick of the most recent change to the entity. As we iterate through the visible entities in `queue_material_meshes`, we check the cache to see whether the entity needs to be re-binned. If it doesn't, then we mark it as clean in the `valid_cached_entity_bin_keys` bit set. If it does, then we insert it into the correct bin, and then mark the entity as clean. At the end, all entities not marked as clean are removed from the bins. This patch has a dramatic effect on the rendering performance of most benchmarks, as it effectively eliminates `queue_material_meshes` from the profile. Note, however, that it generally simultaneously regresses `batch_and_prepare_binned_render_phase` by a bit (not by enough to outweigh the win, however). I believe that's because, before this patch, `queue_material_meshes` put the bins in the CPU cache for `batch_and_prepare_binned_render_phase` to use, while with this patch, `batch_and_prepare_binned_render_phase` must load the bins into the CPU cache itself. On Caldera, this reduces the time spent in `queue_material_meshes` from 5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy right now because of https://github.com/bevyengine/bevy/issues/17535. 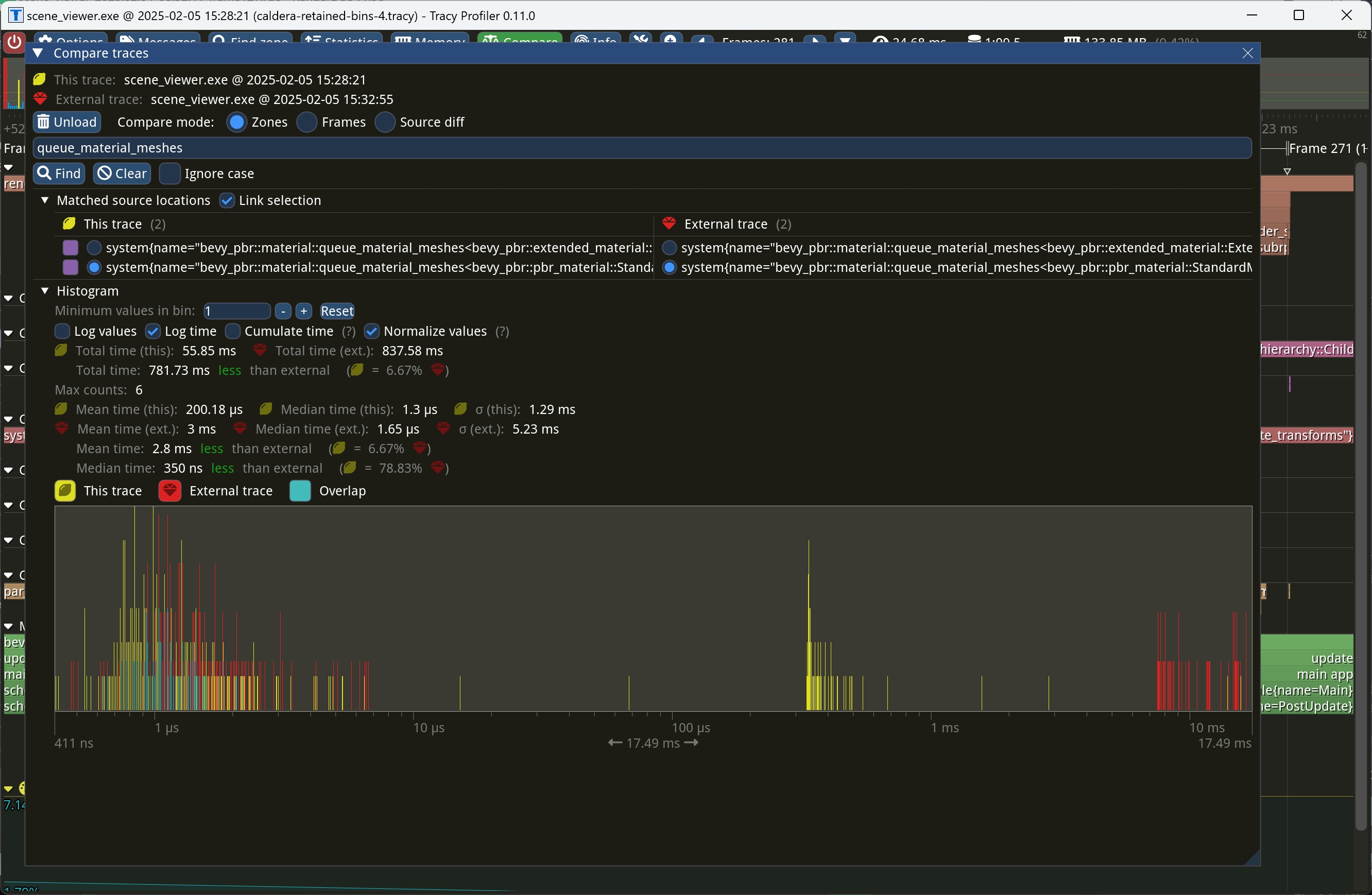 |
||
|
|
44ad3bf62b
|
Move Resource trait to its own file (#17469)
# Objective `bevy_ecs`'s `system` module is something of a grab bag, and *very* large. This is particularly true for the `system_param` module, which is more than 2k lines long! While it could be defensible to put `Res` and `ResMut` there (lol no they're in change_detection.rs, obviously), it doesn't make any sense to put the `Resource` trait there. This is confusing to navigate (and painful to work on and review). ## Solution - Create a root level `bevy_ecs/resource.rs` module to mirror `bevy_ecs/component.rs` - move the `Resource` trait to that module - move the `Resource` derive macro to that module as well (Rust really likes when you pun on the names of the derive macro and trait and put them in the same path) - fix all of the imports ## Notes to reviewers - We could probably move more stuff into here, but I wanted to keep this PR as small as possible given the absurd level of import changes. - This PR is ground work for my upcoming attempts to store resource data on components (resources-as-entities). Splitting this code out will make the work and review a bit easier, and is the sort of overdue refactor that's good to do as part of more meaningful work. ## Testing cargo build works! ## Migration Guide `bevy_ecs::system::Resource` has been moved to `bevy_ecs::resource::Resource`. |
||
|
|
a8f15bd95e
|
Introduce two-level bins for multidrawable meshes. (#16898)
Currently, our batchable binned items are stored in a hash table that maps bin key, which includes the batch set key, to a list of entities. Multidraw is handled by sorting the bin keys and accumulating adjacent bins that can be multidrawn together (i.e. have the same batch set key) into multidraw commands during `batch_and_prepare_binned_render_phase`. This is reasonably efficient right now, but it will complicate future work to retain indirect draw parameters from frame to frame. Consider what must happen when we have retained indirect draw parameters and the application adds a bin (i.e. a new mesh) that shares a batch set key with some pre-existing meshes. (That is, the new mesh can be multidrawn with the pre-existing meshes.) To be maximally efficient, our goal in that scenario will be to update *only* the indirect draw parameters for the batch set (i.e. multidraw command) containing the mesh that was added, while leaving the others alone. That means that we have to quickly locate all the bins that belong to the batch set being modified. In the existing code, we would have to sort the list of bin keys so that bins that can be multidrawn together become adjacent to one another in the list. Then we would have to do a binary search through the sorted list to find the location of the bin that was just added. Next, we would have to widen our search to adjacent indexes that contain the same batch set, doing expensive comparisons against the batch set key every time. Finally, we would reallocate the indirect draw parameters and update the stored pointers to the indirect draw parameters that the bins store. By contrast, it'd be dramatically simpler if we simply changed the way bins are stored to first map from batch set key (i.e. multidraw command) to the bins (i.e. meshes) within that batch set key, and then from each individual bin to the mesh instances. That way, the scenario above in which we add a new mesh will be simpler to handle. First, we will look up the batch set key corresponding to that mesh in the outer map to find an inner map corresponding to the single multidraw command that will draw that batch set. We will know how many meshes the multidraw command is going to draw by the size of that inner map. Then we simply need to reallocate the indirect draw parameters and update the pointers to those parameters within the bins as necessary. There will be no need to do any binary search or expensive batch set key comparison: only a single hash lookup and an iteration over the inner map to update the pointers. This patch implements the above technique. Because we don't have retained bins yet, this PR provides no performance benefits. However, it opens the door to maximally efficient updates when only a small number of meshes change from frame to frame. The main churn that this patch causes is that the *batch set key* (which uniquely specifies a multidraw command) and *bin key* (which uniquely specifies a mesh *within* that multidraw command) are now separate, instead of the batch set key being embedded *within* the bin key. In order to isolate potential regressions, I think that at least #16890, #16836, and #16825 should land before this PR does. ## Migration Guide * The *batch set key* is now separate from the *bin key* in `BinnedPhaseItem`. The batch set key is used to collect multidrawable meshes together. If you aren't using the multidraw feature, you can safely set the batch set key to `()`. |
||
|
|
a371ee3019
|
Remove tracing re-export from bevy_utils (#17161)
# Objective - Contributes to #11478 ## Solution - Made `bevy_utils::tracing` `doc(hidden)` - Re-exported `tracing` from `bevy_log` for end-users - Added `tracing` directly to crates that need it. ## Testing - CI --- ## Migration Guide If you were importing `tracing` via `bevy::utils::tracing`, instead use `bevy::log::tracing`. Note that many items within `tracing` are also directly re-exported from `bevy::log` as well, so you may only need `bevy::log` for the most common items (e.g., `warn!`, `trace!`, etc.). This also applies to the `log_once!` family of macros. ## Notes - While this doesn't reduce the line-count in `bevy_utils`, it further decouples the internal crates from `bevy_utils`, making its eventual removal more feasible in the future. - I have just imported `tracing` as we do for all dependencies. However, a workspace dependency may be more appropriate for version management. |
||
|
|
7767a8d161
|
Refactor batch_and_prepare_binned_render_phase in preparation for bin retention. (#16922)
This commit makes the following changes: * `IndirectParametersBuffer` has been changed from a `BufferVec` to a `RawBufferVec`. This won about 20us or so on Bistro by avoiding `encase` overhead. * The methods on the `GetFullBatchData` trait no longer have the `entity` parameter, as it was unused. * `PreprocessWorkItem`, which specifies a transform-and-cull operation, now supplies the mesh instance uniform output index directly instead of having the shader look it up from the indirect draw parameters. Accordingly, the responsibility of writing the output index to the indirect draw parameters has been moved from the CPU to the GPU. This is in preparation for retained indirect instance draw commands, where the mesh instance uniform output index may change from frame to frame, while the indirect instance draw commands will be cached. We won't want the CPU to have to upload the same indirect draw parameters again and again if a batch didn't change from frame to frame. * `batch_and_prepare_binned_render_phase` and `batch_and_prepare_sorted_render_phase` now allocate indirect draw commands for an entire batch set at a time when possible, instead of one batch at a time. This change will allow us to retain the indirect draw commands for whole batch sets. * `GetFullBatchData::get_batch_indirect_parameters_index` has been replaced with `GetFullBatchData::write_batch_indirect_parameters`, which takes an offset and writes into it instead of allocating. This is necessary in order to use the optimization mentioned in the previous point. * At the WGSL level, `IndirectParameters` has been factored out into `mesh_preprocess_types.wgsl`. This is because we'll need a new compute shader that zeroes out the instance counts in preparation for a new frame. That shader will need to access `IndirectParameters`, so it was moved to a separate file. * Bins are no longer raw vectors but are instances of a separate type, `RenderBin`. This is so that the bin can eventually contain its retained batches. |
||
|
|
f5de3f08fb
|
Use multidraw for opaque meshes when GPU culling is in use. (#16427)
This commit adds support for *multidraw*, which is a feature that allows multiple meshes to be drawn in a single drawcall. `wgpu` currently implements multidraw on Vulkan, so this feature is only enabled there. Multiple meshes can be drawn at once if they're in the same vertex and index buffers and are otherwise placed in the same bin. (Thus, for example, at present the materials and textures must be identical, but see #16368.) Multidraw is a significant performance improvement during the draw phase because it reduces the number of rebindings, as well as the number of drawcalls. This feature is currently only enabled when GPU culling is used: i.e. when `GpuCulling` is present on a camera. Therefore, if you run for example `scene_viewer`, you will not see any performance improvements, because `scene_viewer` doesn't add the `GpuCulling` component to its camera. Additionally, the multidraw feature is only implemented for opaque 3D meshes and not for shadows or 2D meshes. I plan to make GPU culling the default and to extend the feature to shadows in the future. Also, in the future I suspect that polyfilling multidraw on APIs that don't support it will be fruitful, as even without driver-level support use of multidraw allows us to avoid expensive `wgpu` rebindings. |
||
|
|
dd812b3e49
|
Type safe retained render world (#15756)
# Objective In the Render World, there are a number of collections that are derived from Main World entities and are used to drive rendering. The most notable are: - `VisibleEntities`, which is generated in the `check_visibility` system and contains visible entities for a view. - `ExtractedInstances`, which maps entity ids to asset ids. In the old model, these collections were trivially kept in sync -- any extracted phase item could look itself up because the render entity id was guaranteed to always match the corresponding main world id. After #15320, this became much more complicated, and was leading to a number of subtle bugs in the Render World. The main rendering systems, i.e. `queue_material_meshes` and `queue_material2d_meshes`, follow a similar pattern: ```rust for visible_entity in visible_entities.iter::<With<Mesh2d>>() { let Some(mesh_instance) = render_mesh_instances.get_mut(visible_entity) else { continue; }; // Look some more stuff up and specialize the pipeline... let bin_key = Opaque2dBinKey { pipeline: pipeline_id, draw_function: draw_opaque_2d, asset_id: mesh_instance.mesh_asset_id.into(), material_bind_group_id: material_2d.get_bind_group_id().0, }; opaque_phase.add( bin_key, *visible_entity, BinnedRenderPhaseType::mesh(mesh_instance.automatic_batching), ); } ``` In this case, `visible_entities` and `render_mesh_instances` are both collections that are created and keyed by Main World entity ids, and so this lookup happens to work by coincidence. However, there is a major unintentional bug here: namely, because `visible_entities` is a collection of Main World ids, the phase item being queued is created with a Main World id rather than its correct Render World id. This happens to not break mesh rendering because the render commands used for drawing meshes do not access the `ItemQuery` parameter, but demonstrates the confusion that is now possible: our UI phase items are correctly being queued with Render World ids while our meshes aren't. Additionally, this makes it very easy and error prone to use the wrong entity id to look up things like assets. For example, if instead we ignored visibility checks and queued our meshes via a query, we'd have to be extra careful to use `&MainEntity` instead of the natural `Entity`. ## Solution Make all collections that are derived from Main World data use `MainEntity` as their key, to ensure type safety and avoid accidentally looking up data with the wrong entity id: ```rust pub type MainEntityHashMap<V> = hashbrown::HashMap<MainEntity, V, EntityHash>; ``` Additionally, we make all `PhaseItem` be able to provide both their Main and Render World ids, to allow render phase implementors maximum flexibility as to what id should be used to look up data. You can think of this like tracking at the type level whether something in the Render World should use it's "primary key", i.e. entity id, or needs to use a foreign key, i.e. `MainEntity`. ## Testing ##### TODO: This will require extensive testing to make sure things didn't break! Additionally, some extraction logic has become more complicated and needs to be checked for regressions. ## Migration Guide With the advent of the retained render world, collections that contain references to `Entity` that are extracted into the render world have been changed to contain `MainEntity` in order to prevent errors where a render world entity id is used to look up an item by accident. Custom rendering code may need to be changed to query for `&MainEntity` in order to look up the correct item from such a collection. Additionally, users who implement their own extraction logic for collections of main world entity should strongly consider extracting into a different collection that uses `MainEntity` as a key. Additionally, render phases now require specifying both the `Entity` and `MainEntity` for a given `PhaseItem`. Custom render phases should ensure `MainEntity` is available when queuing a phase item. |
||
|
|
44db8b7fac
|
Allow phase items not associated with meshes to be binned. (#14029)
As reported in #14004, many third-party plugins, such as Hanabi, enqueue entities that don't have meshes into render phases. However, the introduction of indirect mode added a dependency on mesh-specific data, breaking this workflow. This is because GPU preprocessing requires that the render phases manage indirect draw parameters, which don't apply to objects that aren't meshes. The existing code skips over binned entities that don't have indirect draw parameters, which causes the rendering to be skipped for such objects. To support this workflow, this commit adds a new field, `non_mesh_items`, to `BinnedRenderPhase`. This field contains a simple list of (bin key, entity) pairs. After drawing batchable and unbatchable objects, the non-mesh items are drawn one after another. Bevy itself doesn't enqueue any items into this list; it exists solely for the application and/or plugins to use. Additionally, this commit switches the asset ID in the standard bin keys to be an untyped asset ID rather than that of a mesh. This allows more flexibility, allowing bins to be keyed off any type of asset. This patch adds a new example, `custom_phase_item`, which simultaneously serves to demonstrate how to use this new feature and to act as a regression test so this doesn't break again. Fixes #14004. ## Changelog ### Added * `BinnedRenderPhase` now contains a `non_mesh_items` field for plugins to add custom items to. |
||
|
|
9da0b2a0ec
|
Make render phases render world resources instead of components. (#13277)
This commit makes us stop using the render world ECS for `BinnedRenderPhase` and `SortedRenderPhase` and instead use resources with `EntityHashMap`s inside. There are three reasons to do this: 1. We can use `clear()` to clear out the render phase collections instead of recreating the components from scratch, allowing us to reuse allocations. 2. This is a prerequisite for retained bins, because components can't be retained from frame to frame in the render world, but resources can. 3. We want to move away from storing anything in components in the render world ECS, and this is a step in that direction. This patch results in a small performance benefit, due to point (1) above. ## Changelog ### Changed * The `BinnedRenderPhase` and `SortedRenderPhase` render world components have been replaced with `ViewBinnedRenderPhases` and `ViewSortedRenderPhases` resources. ## Migration Guide * The `BinnedRenderPhase` and `SortedRenderPhase` render world components have been replaced with `ViewBinnedRenderPhases` and `ViewSortedRenderPhases` resources. Instead of querying for the components, look the camera entity up in the `ViewBinnedRenderPhases`/`ViewSortedRenderPhases` tables. |
||
|
|
16531fb3e3
|
Implement GPU frustum culling. (#12889)
This commit implements opt-in GPU frustum culling, built on top of the infrastructure in https://github.com/bevyengine/bevy/pull/12773. To enable it on a camera, add the `GpuCulling` component to it. To additionally disable CPU frustum culling, add the `NoCpuCulling` component. Note that adding `GpuCulling` without `NoCpuCulling` *currently* does nothing useful. The reason why `GpuCulling` doesn't automatically imply `NoCpuCulling` is that I intend to follow this patch up with GPU two-phase occlusion culling, and CPU frustum culling plus GPU occlusion culling seems like a very commonly-desired mode. Adding the `GpuCulling` component to a view puts that view into *indirect mode*. This mode makes all drawcalls indirect, relying on the mesh preprocessing shader to allocate instances dynamically. In indirect mode, the `PreprocessWorkItem` `output_index` points not to a `MeshUniform` instance slot but instead to a set of `wgpu` `IndirectParameters`, from which it allocates an instance slot dynamically if frustum culling succeeds. Batch building has been updated to allocate and track indirect parameter slots, and the AABBs are now supplied to the GPU as `MeshCullingData`. A small amount of code relating to the frustum culling has been borrowed from meshlets and moved into `maths.wgsl`. Note that standard Bevy frustum culling uses AABBs, while meshlets use bounding spheres; this means that not as much code can be shared as one might think. This patch doesn't provide any way to perform GPU culling on shadow maps, to avoid making this patch bigger than it already is. That can be a followup. ## Changelog ### Added * Frustum culling can now optionally be done on the GPU. To enable it, add the `GpuCulling` component to a camera. * To disable CPU frustum culling, add `NoCpuCulling` to a camera. Note that `GpuCulling` doesn't automatically imply `NoCpuCulling`. |
||
|
|
5f05e75a70
|
Fix 2D BatchedInstanceBuffer clear (#12922)
# Objective - `cargo run --release --example bevymark -- --benchmark --waves 160 --per-wave 1000 --mode mesh2d` runs slower and slower over time due to `no_gpu_preprocessing::write_batched_instance_buffer<bevy_sprite::mesh2d::mesh::Mesh2dPipeline>` taking longer and longer because the `BatchedInstanceBuffer` is not cleared ## Solution - Split the `clear_batched_instance_buffers` system into CPU and GPU versions - Use the CPU version for 2D meshes |
||
|
|
11817f4ba4
|
Generate MeshUniforms on the GPU via compute shader where available. (#12773)
Currently, `MeshUniform`s are rather large: 160 bytes. They're also somewhat expensive to compute, because they involve taking the inverse of a 3x4 matrix. Finally, if a mesh is present in multiple views, that mesh will have a separate `MeshUniform` for each and every view, which is wasteful. This commit fixes these issues by introducing the concept of a *mesh input uniform* and adding a *mesh uniform building* compute shader pass. The `MeshInputUniform` is simply the minimum amount of data needed for the GPU to compute the full `MeshUniform`. Most of this data is just the transform and is therefore only 64 bytes. `MeshInputUniform`s are computed during the *extraction* phase, much like skins are today, in order to avoid needlessly copying transforms around on CPU. (In fact, the render app has been changed to only store the translation of each mesh; it no longer cares about any other part of the transform, which is stored only on the GPU and the main world.) Before rendering, the `build_mesh_uniforms` pass runs to expand the `MeshInputUniform`s to the full `MeshUniform`. The mesh uniform building pass does the following, all on GPU: 1. Copy the appropriate fields of the `MeshInputUniform` to the `MeshUniform` slot. If a single mesh is present in multiple views, this effectively duplicates it into each view. 2. Compute the inverse transpose of the model transform, used for transforming normals. 3. If applicable, copy the mesh's transform from the previous frame for TAA. To support this, we double-buffer the `MeshInputUniform`s over two frames and swap the buffers each frame. The `MeshInputUniform`s for the current frame contain the index of that mesh's `MeshInputUniform` for the previous frame. This commit produces wins in virtually every CPU part of the pipeline: `extract_meshes`, `queue_material_meshes`, `batch_and_prepare_render_phase`, and especially `write_batched_instance_buffer` are all faster. Shrinking the amount of CPU data that has to be shuffled around speeds up the entire rendering process. | Benchmark | This branch | `main` | Speedup | |------------------------|-------------|---------|---------| | `many_cubes -nfc` | 17.259 | 24.529 | 42.12% | | `many_cubes -nfc -vpi` | 302.116 | 312.123 | 3.31% | | `many_foxes` | 3.227 | 3.515 | 8.92% | Because mesh uniform building requires compute shader, and WebGL 2 has no compute shader, the existing CPU mesh uniform building code has been left as-is. Many types now have both CPU mesh uniform building and GPU mesh uniform building modes. Developers can opt into the old CPU mesh uniform building by setting the `use_gpu_uniform_builder` option on `PbrPlugin` to `false`. Below are graphs of the CPU portions of `many-cubes --no-frustum-culling`. Yellow is this branch, red is `main`. `extract_meshes`:  It's notable that we get a small win even though we're now writing to a GPU buffer. `queue_material_meshes`:  There's a bit of a regression here; not sure what's causing it. In any case it's very outweighed by the other gains. `batch_and_prepare_render_phase`:  There's a huge win here, enough to make batching basically drop off the profile. `write_batched_instance_buffer`:  There's a massive improvement here, as expected. Note that a lot of it simply comes from the fact that `MeshInputUniform` is `Pod`. (This isn't a maintainability problem in my view because `MeshInputUniform` is so simple: just 16 tightly-packed words.) ## Changelog ### Added * Per-mesh instance data is now generated on GPU with a compute shader instead of CPU, resulting in rendering performance improvements on platforms where compute shaders are supported. ## Migration guide * Custom render phases now need multiple systems beyond just `batch_and_prepare_render_phase`. Code that was previously creating custom render phases should now add a `BinnedRenderPhasePlugin` or `SortedRenderPhasePlugin` as appropriate instead of directly adding `batch_and_prepare_render_phase`. |