# Objective
- Fixes#10806
## Solution
Replaced `new` and `index` methods for both `TableRow` and `TableId`
with `from_*` and `as_*` methods. These remove the need to perform
casting at call sites, reducing the total number of casts in the Bevy
codebase. Within these methods, an appropriate `debug_assertion` ensures
the cast will behave in an expected manner (no wrapping, etc.). I am
using a `debug_assertion` instead of an `assert` to reduce any possible
runtime overhead, however minimal. This choice is something I am open to
changing (or leaving up to another PR) if anyone has any strong
arguments for it.
---
## Changelog
- `ComponentSparseSet::sparse` stores a `TableRow` instead of a `u32`
(private change)
- Replaced `TableRow::new` and `TableRow::index` methods with
`TableRow::from_*` and `TableRow::as_*`, with `debug_assertions`
protecting any internal casting.
- Replaced `TableId::new` and `TableId::index` methods with
`TableId::from_*` and `TableId::as_*`, with `debug_assertions`
protecting any internal casting.
- All `TableId` methods are now `const`
## Migration Guide
- `TableRow::new` -> `TableRow::from_usize`
- `TableRow::index` -> `TableRow::as_usize`
- `TableId::new` -> `TableId::from_usize`
- `TableId::index` -> `TableId::as_usize`
---
## Notes
I have chosen to remove the `index` and `new` methods for the following
chain of reasoning:
- Across the codebase, `new` was called with a mixture of `u32` and
`usize` values. Likewise for `index`.
- Choosing `new` to either be `usize` or `u32` would break half of these
call-sites, requiring `as` casting at the site.
- Adding a second method `new_u32` or `new_usize` avoids the above, bu
looks visually inconsistent.
- Therefore, they should be replaced with `from_*` and `as_*` methods
instead.
Worth noting is that by updating `ComponentSparseSet`, there are now
zero instances of interacting with the inner value of `TableRow` as a
`u32`, it is exclusively used as a `usize` value (due to interactions
with methods like `len` and slice indexing). I have left the `as_u32`
and `from_u32` methods as the "proper" constructors/getters.
# Objective
Resolves Issue #10772.
## Solution
Added the deprecated warning for QueryState::for_each_unchecked, as
noted in the comments of PR #6773.
Followed the wording in the deprecation messages for `for_each` and
`for_each_mut`
# Objective
After #6547, `Query::for_each` has been capable of automatic
vectorization on certain queries, which is seeing a notable (>50% CPU
time improvements) for iteration. However, `Query::for_each` isn't
idiomatic Rust, and lacks the flexibility of iterator combinators.
Ideally, `Query::iter` and friends should be able to achieve the same
results. However, this does seem to blocked upstream
(rust-lang/rust#104914) by Rust's loop optimizations.
## Solution
This is an intermediate solution and refactor. This moves the
`Query::for_each` implementation onto the `Iterator::fold`
implementation for `QueryIter` instead. This should result in the same
automatic vectorization optimization on all `Iterator` functions that
internally use fold, including `Iterator::for_each`, `Iterator::count`,
etc.
With this, it should close the gap between the two completely.
Internally, this PR changes `Query::for_each` to use
`query.iter().for_each(..)` instead of the duplicated implementation.
Separately, the duplicate implementations of internal iteration (i.e.
`Query::par_for_each`) now use portions of the current `Query::for_each`
implementation factored out into their own functions.
This also massively cleans up our internal fragmentation of internal
iteration options, deduplicating the iteration code used in `for_each`
and `par_iter().for_each()`.
---
## Changelog
Changed: `Query::for_each`, `Query::for_each_mut`, `Query::for_each`,
and `Query::for_each_mut` have been moved to `QueryIter`'s
`Iterator::for_each` implementation, and still retains their performance
improvements over normal iteration. These APIs are deprecated in 0.13
and will be removed in 0.14.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
# Objective
Related to #10612.
Enable the
[`clippy::manual_let_else`](https://rust-lang.github.io/rust-clippy/master/#manual_let_else)
lint as a warning. The `let else` form seems more idiomatic to me than a
`match`/`if else` that either match a pattern or diverge, and from the
clippy doc, the lint doesn't seem to have any possible false positive.
## Solution
Add the lint as warning in `Cargo.toml`, refactor places where the lint
triggers.
# Objective
- Fixes#7680
- This is an updated for https://github.com/bevyengine/bevy/pull/8899
which had the same objective but fell a long way behind the latest
changes
## Solution
The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter :
WorldQuery` have been added and some of the types and functions from
`WorldQuery` has been moved into them.
`ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`.
`WorldQueryFilter` is safe (as long as `WorldQuery` is implemented
safely).
`WorldQueryData` is unsafe - safely implementing it requires that
`Self::ReadOnly` is a readonly version of `Self` (this used to be a
safety requirement of `WorldQuery`)
The type parameters `Q` and `F` of `Query` must now implement
`WorldQueryData` and `WorldQueryFilter` respectively.
This makes it impossible to accidentally use a filter in the data
position or vice versa which was something that could lead to bugs.
~~Compile failure tests have been added to check this.~~
It was previously sometimes useful to use `Option<With<T>>` in the data
position. Use `Has<T>` instead in these cases.
The `WorldQuery` derive macro has been split into separate derive macros
for `WorldQueryData` and `WorldQueryFilter`.
Previously it was possible to derive both `WorldQuery` for a struct that
had a mixture of data and filter items. This would not work correctly in
some cases but could be a useful pattern in others. *This is no longer
possible.*
---
## Notes
- The changes outside of `bevy_ecs` are all changing type parameters to
the new types, updating the macro use, or replacing `Option<With<T>>`
with `Has<T>`.
- All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL`
so I moved it to `WorldQueryFilter` and
replaced all calls to it with `true`. That should be the only logic
change outside of the macro generation code.
- `Changed<T>` and `Added<T>` were being generated by a macro that I
have expanded. Happy to revert that if desired.
- The two derive macros share some functions for implementing
`WorldQuery` but the tidiest way I could find to implement them was to
give them a ton of arguments and ask clippy to ignore that.
## Changelog
### Changed
- Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which
now have separate derive macros. It is not possible to derive both for
the same type.
- `Query` now requires that the first type argument implements
`WorldQueryData` and the second implements `WorldQueryFilter`
## Migration Guide
- Update derives
```rust
// old
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA
}
#[derive(WorldQuery)]
struct QueryFilter {
_c: With<ComponentC>
}
// new
#[derive(WorldQueryData)]
#[world_query_data(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA,
}
#[derive(WorldQueryFilter)]
struct QueryFilter {
_c: With<ComponentC>
}
```
- Replace `Option<With<T>>` with `Has<T>`
```rust
/// old
fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>)
{
for (entity, has_a_option) in query.iter(){
let has_a:bool = has_a_option.is_some();
//todo!()
}
}
/// new
fn my_system(query: Query<(Entity, Has<ComponentA>)>)
{
for (entity, has_a) in query.iter(){
//todo!()
}
}
```
- Fix queries which had filters in the data position or vice versa.
```rust
// old
fn my_system(query: Query<(Entity, With<ComponentA>)>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Entity, With<ComponentA>>)
{
for entity in query.iter(){
//todo!()
}
}
// old
fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>)
{
for entity in query.iter(){
//todo!()
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Explain https://github.com/bevyengine/bevy/issues/10625.
This might be obvious to those familiar with Bevy internals, but it
surprised me.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Align all error-like types to implement `Error`.
Fixes #10176
## Solution
- Derive `Error` on more types
- Refactor instances of manual implementations that could be derived
This adds thiserror as a dependency to bevy_transform, which might
increase compilation time -- but I don't know of any situation where you
might only use that but not any other crate that pulls in bevy_utils.
The `contributors` example has a `LoadContributorsError` type, but as
it's an example I have not updated it. Doing that would mean either
having a `use bevy_internal::utils::thiserror::Error;` in an example
file, or adding `thiserror` as a dev-dependency to the main `bevy`
crate.
---
## Changelog
- All `…Error` types now implement the `Error` trait
# Objective
- Updates for rust 1.73
## Solution
- new doc check for `redundant_explicit_links`
- updated to text for compile fail tests
---
## Changelog
- updates for rust 1.73
Objective
---------
- Since #6742, It is not possible to build an `ArchetypeId` from a
`ArchetypeGeneration`
- This was useful to 3rd party crate extending the base bevy ECS
capabilities, such as [`bevy_ecs_dynamic`] and now
[`bevy_mod_dynamic_query`]
- Making `ArchetypeGeneration` opaque this way made it completely
useless, and removed the ability to limit archetype updates to a subset
of archetypes.
- Making the `index` method on `ArchetypeId` private prevented the use
of bitfields and other optimized data structure to store sets of
archetype ids. (without `transmute`)
This PR is not a simple reversal of the change. It exposes a different
API, rethought to keep the private stuff private and the public stuff
less error-prone.
- Add a `StartRange<ArchetypeGeneration>` `Index` implementation to
`Archetypes`
- Instead of converting the generation into an index, then creating a
ArchetypeId from that index, and indexing `Archetypes` with it, use
directly the old `ArchetypeGeneration` to get the range of new
archetypes.
From careful benchmarking, it seems to also be a performance improvement
(~0-5%) on add_archetypes.
---
Changelog
---------
- Added `impl Index<RangeFrom<ArchetypeGeneration>> for Archetypes` this
allows you to get a slice of newly added archetypes since the last
recorded generation.
- Added `ArchetypeId::index` and `ArchetypeId::new` methods. It should
enable 3rd party crates to use the `Archetypes` API in a meaningful way.
[`bevy_ecs_dynamic`]:
https://github.com/jakobhellermann/bevy_ecs_dynamic/tree/main
[`bevy_mod_dynamic_query`]:
https://github.com/nicopap/bevy_mod_dynamic_query/
---------
Co-authored-by: vero <email@atlasdostal.com>
# Objective
We've done a lot of work to remove the pattern of a `&World` with
interior mutability (#6404, #8833). However, this pattern still persists
within `bevy_ecs` via the `unsafe_world` method.
## Solution
* Make `unsafe_world` private. Adjust any callsites to use
`UnsafeWorldCell` for interior mutability.
* Add `UnsafeWorldCell::removed_components`, since it is always safe to
access the removed components collection through `UnsafeWorldCell`.
## Future Work
Remove/hide `UnsafeWorldCell::world_metadata`, once we have provided
safe ways of accessing all world metadata.
---
## Changelog
+ Added `UnsafeWorldCell::removed_components`, which provides read-only
access to a world's collection of removed components.
# Objective
Improve code-gen for `QueryState::validate_world` and
`SystemState::validate_world`.
## Solution
* Move panics into separate, non-inlined functions, to reduce the code
size of the outer methods.
* Mark the panicking functions with `#[cold]` to help the compiler
optimize for the happy path.
* Mark the functions with `#[track_caller]` to make debugging easier.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Currently, in bevy, it's valid to do `Query<&mut Foo, Changed<Foo>>`.
This assumes that `filter_fetch` and `fetch` are mutually exclusive,
because of the mutable reference to the tick that `Mut<Foo>` implies and
the reference that `Changed<Foo>` implies. However nothing guarantees
that.
## Solution
Documenting this assumption as a safety invariant is the least thing.
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
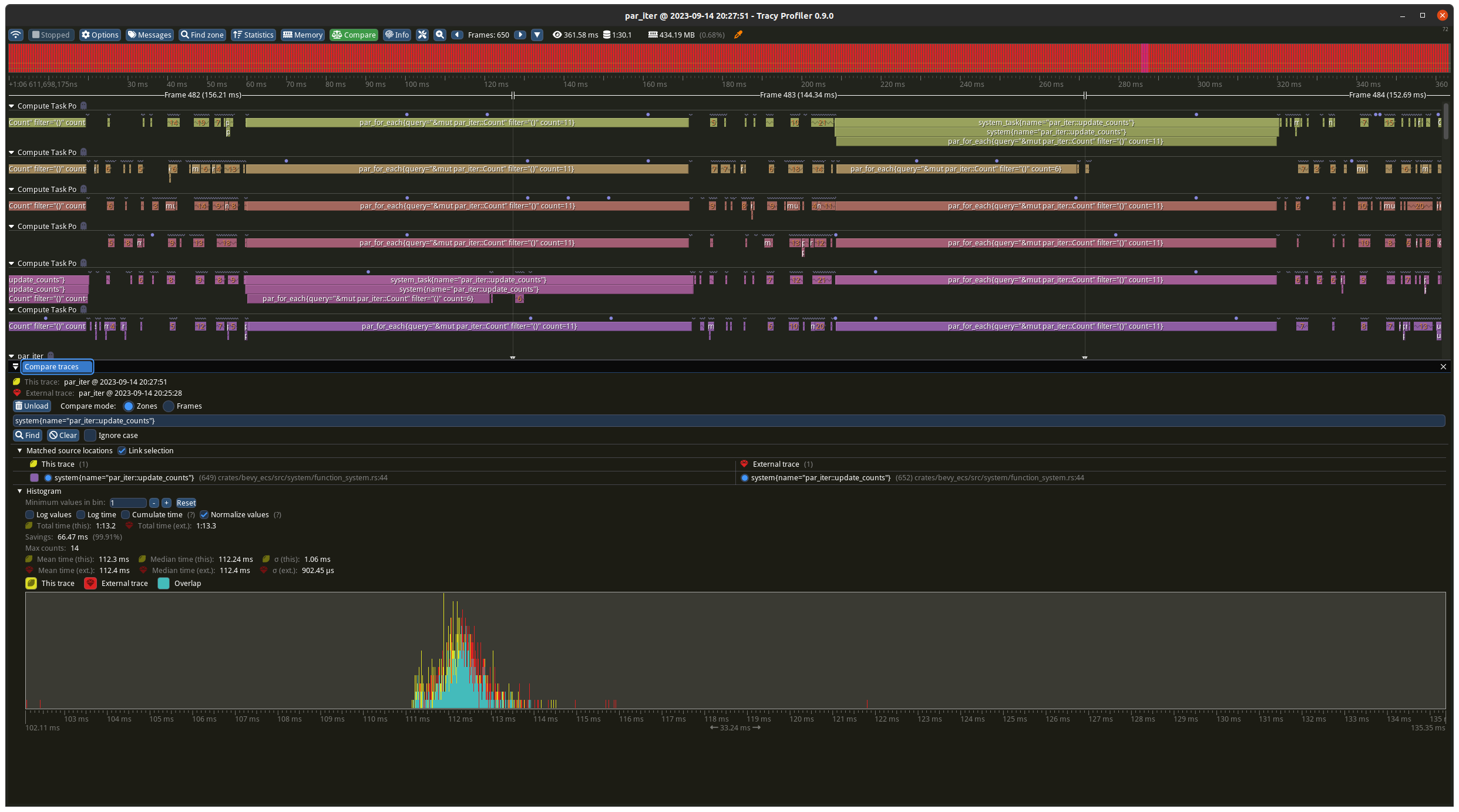
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
# Objective
- The tick access methods mention "ticks" (as in: plural). Yet, most of
them only access a single tick.
## Solution
- Rename those methods and fix docs to reflect the singular aspect of
the return values
---
## Migration Guide
The following method names were renamed, from `foo_ticks_bar` to
`foo_tick_bar` (`ticks` is now singular, `tick`):
- `ComponentSparseSet::get_added_ticks` → `get_added_tick`
- `ComponentSparseSet::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks` → `get_added_tick`
- `Column::get_changed_ticks` → `get_changed_tick`
- `Column::get_added_ticks_unchecked` → `get_added_tick_unchecked`
- `Column::get_changed_ticks_unchecked` → `get_changed_tick_unchecked`
# Objective
- Fixes#9683
## Solution
- Moved `get_component` from `Query` to `QueryState`.
- Moved `get_component_unchecked_mut` from `Query` to `QueryState`.
- Moved `QueryComponentError` from `bevy_ecs::system` to
`bevy_ecs::query`. Minor Breaking Change.
- Narrowed scope of `unsafe` blocks in `Query` methods.
---
## Migration Guide
- `use bevy_ecs::system::QueryComponentError;` -> `use
bevy_ecs::query::QueryComponentError;`
## Notes
I am not very familiar with unsafe Rust nor its use within Bevy, so I
may have committed a Rust faux pas during the migration.
---------
Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com>
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
`QueryState::is_empty` is unsound, as it does not validate the world. If
a mismatched world is passed in, then the query filter may cast a
component to an incorrect type, causing undefined behavior.
## Solution
Add world validation. To prevent a performance regression in `Query`
(whose world does not need to be validated), the unchecked function
`is_empty_unsafe_world_cell` has been added. This also allows us to
remove one of the last usages of the private function
`UnsafeWorldCell::unsafe_world`, which takes us a step towards being
able to remove that method entirely.
# Objective
Fix#4278Fix#5504Fix#9422
Provide safe ways to borrow an entire entity, while allowing disjoint
mutable access. `EntityRef` and `EntityMut` are not suitable for this,
since they provide access to the entire world -- they are just helper
types for working with `&World`/`&mut World`.
This has potential uses for reflection and serialization
## Solution
Remove `EntityRef::world`, which allows it to soundly be used within
queries.
`EntityMut` no longer supports structural world mutations, which allows
multiple instances of it to exist for different entities at once.
Structural world mutations are performed using the new type
`EntityWorldMut`.
```rust
fn disjoint_system(
q2: Query<&mut A>,
q1: Query<EntityMut, Without<A>>,
) { ... }
let [entity1, entity2] = world.many_entities_mut([id1, id2]);
*entity1.get_mut::<T>().unwrap() = *entity2.get().unwrap();
for entity in world.iter_entities_mut() {
...
}
```
---
## Changelog
- Removed `EntityRef::world`, to fix a soundness issue with queries.
+ Removed the ability to structurally mutate the world using
`EntityMut`, which allows it to be used in queries.
+ Added `EntityWorldMut`, which is used to perform structural mutations
that are no longer allowed using `EntityMut`.
## Migration Guide
**Note for maintainers: ensure that the guide for #9604 is updated
accordingly.**
Removed the method `EntityRef::world`, to fix a soundness issue with
queries. If you need access to `&World` while using an `EntityRef`,
consider passing the world as a separate parameter.
`EntityMut` can no longer perform 'structural' world mutations, such as
adding or removing components, or despawning the entity. Additionally,
`EntityMut::world`, `EntityMut::world_mut` , and
`EntityMut::world_scope` have been removed.
Instead, use the newly-added type `EntityWorldMut`, which is a helper
type for working with `&mut World`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Move schedule name into `Schedule` to allow the schedule name to be
used for errors and tracing in Schedule methods
- Fixes#9510
## Solution
- Move label onto `Schedule` and adjust api's on `World` and `Schedule`
to not pass explicit label where it makes sense to.
- add name to errors and tracing.
- `Schedule::new` now takes a label so either add the label or use
`Schedule::default` which uses a default label. `default` is mostly used
in doc examples and tests.
---
## Changelog
- move label onto `Schedule` to improve error message and logging for
schedules.
## Migration Guide
`Schedule::new` and `App::add_schedule`
```rust
// old
let schedule = Schedule::new();
app.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
app.add_schedule(schedule);
```
if you aren't using a label and are using the schedule struct directly
you can use the default constructor.
```rust
// old
let schedule = Schedule::new();
schedule.run(world);
// new
let schedule = Schedule::default();
schedule.run(world);
```
`Schedules:insert`
```rust
// old
let schedule = Schedule::new();
schedules.insert(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
schedules.insert(schedule);
```
`World::add_schedule`
```rust
// old
let schedule = Schedule::new();
world.add_schedule(MyLabel, schedule);
// new
let schedule = Schedule::new(MyLabel);
world.add_schedule(schedule);
```
# Objective
* `Local` and `SystemName` implement `Debug` manually, but they could
derive it.
* `QueryState` and `dyn System` have unconventional debug formatting.
# Objective
Cloning a `WorldQuery` type's "fetch" struct was made unsafe in #5593,
by adding the `unsafe fn clone_fetch` to `WorldQuery`. However, as that
method's documentation explains, it is not the right place to put the
safety invariant:
> While calling this method on its own cannot cause UB it is marked
`unsafe` as the caller must ensure that the returned value is not used
in any way that would cause two `QueryItem<Self>` for the same
`archetype_index` or `table_row` to be alive at the same time.
You can clone a fetch struct all you want and it will never cause
undefined behavior -- in order for something to go wrong, you need to
improperly call `WorldQuery::fetch` with it (which is marked unsafe).
Additionally, making it unsafe to clone a fetch struct does not even
prevent undefined behavior, since there are other ways to incorrectly
use a fetch struct. For example, you could just call fetch more than
once for the same entity, which is not currently forbidden by any
documented invariants.
## Solution
Document a safety invariant on `WorldQuery::fetch` that requires the
caller to not create aliased `WorldQueryItem`s for mutable types. Remove
the `clone_fetch` function, and add the bound `Fetch: Clone` instead.
---
## Changelog
- Removed the associated function `WorldQuery::clone_fetch`, and added a
`Clone` bound to `WorldQuery::Fetch`.
## Migration Guide
### `fetch` invariants
The function `WorldQuery::fetch` has had the following safety invariant
added:
> If this type does not implement `ReadOnlyWorldQuery`, then the caller
must ensure that it is impossible for more than one `Self::Item` to
exist for the same entity at any given time.
This invariant was always required for soundness, but was previously
undocumented. If you called this function manually anywhere, you should
check to make sure that this invariant is not violated.
### Removed `clone_fetch`
The function `WorldQuery::clone_fetch` has been removed. The associated
type `WorldQuery::Fetch` now has the bound `Clone`.
Before:
```rust
struct MyFetch<'w> { ... }
unsafe impl WorldQuery for MyQuery {
...
type Fetch<'w> = MyFetch<'w>
unsafe fn clone_fetch<'w>(fetch: &Self::Fetch<'w>) -> Self::Fetch<'w> {
MyFetch {
field1: fetch.field1,
field2: fetch.field2.clone(),
...
}
}
}
```
After:
```rust
#[derive(Clone)]
struct MyFetch<'w> { ... }
unsafe impl WorldQuery for MyQuery {
...
type Fetch<'w> = MyFetch<'w>;
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Title. This is necessary in order to update
[`bevy-trait-query`](https://crates.io/crates/bevy-trait-query) to Bevy
0.11.
---
## Changelog
Added the unsafe function `UnsafeWorldCell::storages`, which provides
unchecked access to the internal data stores of a `World`.
# Objective
Partially address #5504. Fix#4278. Provide "whole entity" access in
queries. This can be useful when you don't know at compile time what
you're accessing (i.e. reflection via `ReflectComponent`).
## Solution
Implement `WorldQuery` for `EntityRef`.
- This provides read-only access to the entire entity, and supports
anything that `EntityRef` can normally do.
- It matches all archetypes and tables and will densely iterate when
possible.
- It marks all of the ArchetypeComponentIds of a matched archetype as
read.
- Adding it to a query will cause it to panic if used in conjunction
with any other mutable access.
- Expanded the docs on Query to advertise this feature.
- Added tests to ensure the panics were working as intended.
- Added `EntityRef` to the ECS prelude.
To make this safe, `EntityRef::world` was removed as it gave potential
`UnsafeCell`-like access to other parts of the `World` including aliased
mutable access to the components it would otherwise read safely.
## Performance
Not great beyond the additional parallelization opportunity over
exclusive systems. The `EntityRef` is fetched from `Entities` like any
other call to `World::entity`, which can be very random access heavy.
This could be simplified if `ArchetypeRow` is available in
`WorldQuery::fetch`'s arguments, but that's likely not something we
should optimize for.
## Future work
An equivalent API where it gives mutable access to all components on a
entity can be done with a scoped version of `EntityMut` where it does
not provide `&mut World` access nor allow for structural changes to the
entity is feasible as well. This could be done as a safe alternative to
exclusive system when structural mutation isn't required or the target
set of entities is scoped.
---
## Changelog
Added: `Access::has_any_write`
Added: `EntityRef` now implements `WorldQuery`. Allows read-only access
to the entire entity, incompatible with any other mutable access, can be
mixed with `With`/`Without` filters for more targeted use.
Added: `EntityRef` to `bevy::ecs::prelude`.
Removed: `EntityRef::world`
## Migration Guide
TODO
---------
Co-authored-by: Carter Weinberg <weinbergcarter@gmail.com>
Co-authored-by: Jakob Hellermann <jakob.hellermann@protonmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
`WorldQuery::Fetch` is a type used to optimize the implementation of
queries. These types are hidden and not intended to be outside of the
engine, so there is no need to provide type aliases to make it easier to
refer to them. If a user absolutely needs to refer to one of these
types, they can always just refer to the associated type directly.
## Solution
Deprecate these type aliases.
---
## Changelog
- Deprecated the type aliases `QueryFetch` and `ROQueryFetch`.
## Migration Guide
The type aliases `bevy_ecs::query::QueryFetch` and `ROQueryFetch` have
been deprecated. If you need to refer to a `WorldQuery` struct's fetch
type, refer to the associated type defined on `WorldQuery` directly:
```rust
// Before:
type MyFetch<'w> = QueryFetch<'w, MyQuery>;
type MyFetchReadOnly<'w> = ROQueryFetch<'w, MyQuery>;
// After:
type MyFetch<'w> = <MyQuery as WorldQuery>::Fetch;
type MyFetchReadOnly<'w> = <<MyQuery as WorldQuery>::ReadOnly as WorldQuery>::Fetch;
```
# Objective
- Fixes#7811
## Solution
- I added `Has<T>` (and `HasFetch<T>` ) and implemented `WorldQuery`,
`ReadonlyWorldQuery`, and `ArchetypeFilter` it
- I also added documentation with an example and a unit test
I believe I've done everything right but this is my first contribution
and I'm not an ECS expert so someone who is should probably check my
implementation. I based it on what `Or<With<T>,>`, would do. The only
difference is that `Has` does not update component access - adding `Has`
to a query should never affect whether or not it is disjoint with
another query *I think*.
---
## Changelog
## Added
- Added `Has<T>` WorldQuery to find out whether or not an entity has a
particular component.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
# Objective
- The function `QueryParIter::for_each_unchecked` is a footgun: the only
ways to use it soundly can be done in safe code using `for_each` or
`for_each_mut`. See [this discussion on
discord](https://discord.com/channels/691052431525675048/749335865876021248/1118642977275924583).
## Solution
- Make `for_each_unchecked` private.
---
## Changelog
- Removed `QueryParIter::for_each_unchecked`. All use-cases of this
method were either unsound or doable in safe code using `for_each` or
`for_each_mut`.
## Migration Guide
The method `QueryParIter::for_each_unchecked` has been removed -- use
`for_each` or `for_each_mut` instead. If your use case can not be
achieved using either of these, then your code was likely unsound.
If you have a use-case for `for_each_unchecked` that you believe is
sound, please [open an
issue](https://github.com/bevyengine/bevy/issues/new/choose).
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
The method `QueryState::par_iter` does not currently force the query to
be read-only. This means you can unsoundly mutate a world through an
immutable reference in safe code.
```rust
fn bad_system(world: &World, mut query: Local<QueryState<&mut T>>) {
query.par_iter(world).for_each_mut(|mut x| *x = unsoundness);
}
```
## Solution
Use read-only versions of the `WorldQuery` types.
---
## Migration Guide
The function `QueryState::par_iter` now forces any world accesses to be
read-only, similar to how `QueryState::iter` works. Any code that
previously mutated the world using this method was *unsound*. If you
need to mutate the world, use `par_iter_mut` instead.
# Objective
`QueryState` exposes a `get_manual` and `iter_manual` method. However,
there is now `iter_many_manual`.
`iter_many_manual` is useful when you have a `&World` (eg: the `world`
in a `Scene`) and want to run a query several times on it (eg:
iteratively navigate a hierarchy by calling `iter_many` on `Children`
component).
`iter_many`'s need for a `&mut World` makes the API much less flexible.
The exclusive access pattern requires doing some very funky dance and
excludes a category of algorithms for hierarchy traversal.
## Solution
- Add a `iter_many_manual` method to `QueryState`
### Alternative
My current workaround is to use `get_manual`. However, this doesn't
benefit from the optimizations on `QueryManyIter`.
---
## Changelog
- Add a `iter_many_manual` method to `QueryState`
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Add documentation to `Query` and `QueryState` errors in bevy_ecs
(`QuerySingleError`, `QueryEntityError`, `QueryComponentError`)
## Solution
- Change display message for `QueryEntityError::QueryDoesNotMatch`: this
error can also happen when the entity has a component which is filtered
out (with `Without<C>`)
- Fix wrong reference in the documentation of `Query::get_component` and
`Query::get_component_mut` from `QueryEntityError` to
`QueryComponentError`
- Complete the documentation of the three error enum variants.
- Add examples for `QueryComponentError::MissingReadAccess` and
`QueryComponentError::MissingWriteAccess`
- Add reference to `QueryState` in `QueryEntityError`'s documentation.
---
## Migration Guide
Expect `QueryEntityError::QueryDoesNotMatch`'s display message to
change? Not sure that counts.
---------
Co-authored-by: harudagondi <giogdeasis@gmail.com>
Links in the api docs are nice. I noticed that there were several places
where structs / functions and other things were referenced in the docs,
but weren't linked. I added the links where possible / logical.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
# Objective
This PR attempts to improve query compatibility checks in scenarios
involving `Or` filters.
Currently, for the following two disjoint queries, Bevy will throw a
panic:
```
fn sys(_: Query<&mut C, Or<(With<A>, With<B>)>>, _: Query<&mut C, (Without<A>, Without<B>)>) {}
```
This PR addresses this particular scenario.
## Solution
`FilteredAccess::with` now stores a vector of `AccessFilters`
(representing a pair of `with` and `without` bitsets), where each member
represents an `Or` "variant".
Filters like `(With<A>, Or<(With<B>, Without<C>)>` are expected to be
expanded into `A * B + A * !C`.
When calculating whether queries are compatible, every `AccessFilters`
of a query is tested for incompatibility with every `AccessFilters` of
another query.
---
## Changelog
- Improved system and query data access compatibility checks in
scenarios involving `Or` filters
---------
Co-authored-by: MinerSebas <66798382+MinerSebas@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Upon closer inspection, there are a few functions in the ECS that are
not being inlined, even with the highest optimizations and LTO enabled:
- Almost all
[WorldQuery::init_fetch](9fd5f20e25/results/query_get.s (L57))
calls. Affects `Query::get` calls in hot loops. In particular, the
`WorldQuery` implementation for `()` is used *everywhere* as the default
filter and is effectively a no-op.
-
[Entities::get](9fd5f20e25/results/query_get.s (L39)).
Affects `Query::get`, `World::get`, and any component insertion or
removal.
-
[Entities::set](9fd5f20e25/results/entity_remove.s (L2487)).
Affects any component insertion or removal.
-
[Tick::new](9fd5f20e25/results/entity_insert.s (L1368)).
I've only seen this in component insertion and spawning.
- ArchetypeRow::new
- BlobVec::set_len
Almost all of these have trivial or even empty implementations or have
significant opportunity to be optimized into surrounding code when
inlined with LTO enabled.
## Solution
Inline them
Fixes issue mentioned in PR #8285.
_Note: By mistake, this is currently dependent on #8285_
# Objective
Ensure consistency in the spelling of the documentation.
Exceptions:
`crates/bevy_mikktspace/src/generated.rs` - Has not been changed from
licence to license as it is part of a licensing agreement.
Maybe for further consistency,
https://github.com/bevyengine/bevy-website should also be given a look.
## Solution
### Changed the spelling of the current words (UK/CN/AU -> US) :
cancelled -> canceled (Breaking API changes in #8285)
behaviour -> behavior (Breaking API changes in #8285)
neighbour -> neighbor
grey -> gray
recognise -> recognize
centre -> center
metres -> meters
colour -> color
### ~~Update [`engine_style_guide.md`]~~ Moved to #8324
---
## Changelog
Changed UK spellings in documentation to US
## Migration Guide
Non-breaking changes*
\* If merged after #8285
# Objective
The `#[derive(WorldQuery)]` macro currently only supports structs with
named fields.
Same motivation as #6957. Remove sharp edges from the derive macro, make
it just work more often.
## Solution
Support tuple structs.
---
## Changelog
+ Added support for tuple structs to the `#[derive(WorldQuery)]` macro.
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Follow-up to #8030.
Now that `SystemParam` and `WorldQuery` are implemented for
`PhantomData`, the `ignore` attributes are now unnecessary.
---
## Changelog
- Removed the attributes `#[system_param(ignore)]` and
`#[world_query(ignore)]`.
## Migration Guide
The attributes `#[system_param(ignore)]` and `#[world_query]` ignore
have been removed. If you were using either of these with `PhantomData`
fields, you can simply remove the attribute:
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's, Marker> {
...
// Before:
#[system_param(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
#[derive(WorldQuery)]
struct MyQuery<Marker> {
...
// Before:
#[world_query(ignore)
_marker: PhantomData<Marker>,
// After:
_marker: PhantomData<Marker>,
}
```
If you were using this for another type that implements `Default`,
consider wrapping that type in `Local<>` (this only works for
`SystemParam`):
```rust
#[derive(SystemParam)]
struct MyParam<'w, 's> {
// Before:
#[system_param(ignore)]
value: MyDefaultType, // This will be initialized using `Default` each time `MyParam` is created.
// After:
value: Local<MyDefaultType>, // This will be initialized using `Default` the first time `MyParam` is created.
}
```
If you are implementing either trait and need to preserve the exact
behavior of the old `ignore` attributes, consider manually implementing
`SystemParam` or `WorldQuery` for a wrapper struct that uses the
`Default` trait:
```rust
// Before:
#[derive(WorldQuery)
struct MyQuery {
#[world_query(ignore)]
str: String,
}
// After:
#[derive(WorldQuery)
struct MyQuery {
str: DefaultQuery<String>,
}
pub struct DefaultQuery<T: Default>(pub T);
unsafe impl<T: Default> WorldQuery for DefaultQuery<T> {
type Item<'w> = Self;
...
unsafe fn fetch<'w>(...) -> Self::Item<'w> {
Self(T::default())
}
}
```
# Objective
When using `PhantomData` fields with the `#[derive(SystemParam)]` or
`#[derive(WorldQuery)]` macros, the user is required to add the
`#[system_param(ignore)]` attribute so that the macro knows to treat
that field specially. This is undesirable, since it makes the macro more
fragile and less consistent.
## Solution
Implement `SystemParam` and `WorldQuery` for `PhantomData`. This makes
the `ignore` attributes unnecessary.
Some internal changes make the derive macro compatible with types that
have invariant lifetimes, which fixes#8192. From what I can tell, this
fix requires `PhantomData` to implement `SystemParam` in order to ensure
that all of a type's generic parameters are always constrained.
---
## Changelog
+ Implemented `SystemParam` and `WorldQuery` for `PhantomData<T>`.
+ Fixed a miscompilation caused when invariant lifetimes were used with
the `SystemParam` macro.
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
`ChangeTrackers<>` is a `WorldQuery` type that lets you access the change ticks for a component. #7097 has added `Ref<>`, which gives access to a component's value in addition to its change ticks. Since bevy's access model does not separate a component's value from its change ticks, there is no benefit to using `ChangeTrackers<T>` over `Ref<T>`.
## Solution
Deprecate `ChangeTrackers<>`.
---
## Changelog
* `ChangeTrackers<T>` has been deprecated. It will be removed in Bevy 0.11.
## Migration Guide
`ChangeTrackers<T>` has been deprecated, and will be removed in the next release. Any usage should be replaced with `Ref<T>`.
```rust
// Before (0.9)
fn my_system(q: Query<(&MyComponent, ChangeTrackers<MyComponent>)>) {
for (value, trackers) in &q {
if trackers.is_changed() {
// Do something with `value`.
}
}
}
// After (0.10)
fn my_system(q: Query<Ref<MyComponent>>) {
for value in &q {
if value.is_changed() {
// Do something with `value`.
}
}
}
```
# Objective
- Fixes#5432
- Fixes#6680
## Solution
- move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`.
- this allows the new proc macro, `impl_type_uuid`, to call the code for generation.
- added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro.
- finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`).
- fixes#6680 by doing a wrapping add of the param's index to its `TYPE_UUID`
Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com>
# Objective
Clarify what the function is actually calculating.
The `Tick::is_older_than` function is actually calculating whether the tick is newer than the system's `last_change_tick`, not older. As far as I can tell, the engine was using it correctly everywhere already.
## Solution
- Rename the function.
---
## Changelog
- `Tick::is_older_than` was renamed to `Tick::is_newer_than`. This is not a functional change, since that was what was always being calculated, despite the wrong name.
## Migration Guide
- Replace usages of `Tick::is_older_than` with `Tick::is_newer_than`.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
# Objective
- Fixes#7066
## Solution
- Split the ChangeDetection trait into ChangeDetection and ChangeDetectionMut
- Added Ref as equivalent to &T with change detection
---
## Changelog
- Support for Ref which allow inspecting change detection flags in an immutable way
## Migration Guide
- While bevy prelude includes both ChangeDetection and ChangeDetectionMut any code explicitly referencing ChangeDetection might need to be updated to ChangeDetectionMut or both. Specifically any reading logic requires ChangeDetection while writes requires ChangeDetectionMut.
use bevy_ecs::change_detection::DetectChanges -> use bevy_ecs::change_detection::{DetectChanges, DetectChangesMut}
- Previously Res had methods to access change detection `is_changed` and `is_added` those methods have been moved to the `DetectChanges` trait. If you are including bevy prelude you will have access to these types otherwise you will need to `use bevy_ecs::change_detection::DetectChanges` to continue using them.
# Objective
`Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required.
## Solution
Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment.
This idea was partially concocted by @BoxyUwU.
## Performance
This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678.
This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`.
---
## Changelog
Added: `EntityLocation::table_id`
Added: `EntityLocation::table_row`.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables.
## Migration Guide
A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective
#6547 accidentally broke change detection for SparseSet components by using `Ticks::from_tick_cells` with the wrong argument order.
## Solution
Use the right argument order. Add a regression test.
# Objective
Prevent future unsoundness that was seen in #6623.
## Solution
Newtype both indexes in `Archetype` and `Table` as `ArchetypeRow` and `TableRow`. This avoids weird numerical manipulation on the indices, and can be stored and treated opaquely. Also enforces the source and destination of where these indices at a type level.
---
## Changelog
Changed: `Archetype` indices and `Table` rows have been newtyped as `ArchetypeRow` and `TableRow`.
# Objective
- Fixes#6812.
## Solution
- Replaced `World::read_change_ticks` with `World::change_ticks` within `bevy_ecs` crate in places where `World` references were mutable.
---
# Objective
Document `bevy_ecs::archetype` and and declutter the public documentation for the module by making types non-`pub`.
Addresses #3362 for `bevy_ecs::archetype`.
## Solution
- Add module level documentation.
- Add type and API level documentation for all public facing types.
- Make `ArchetypeId`, `ArchetypeGeneration`, and `ArchetypeComponentId` truly opaque IDs that are not publicly constructable.
- Make `AddBundle` non-pub, make `Edges::get_add_bundle` return a `Option<ArchetypeId>` and fork the existing function into `Edges::get_add_bundle_internal`.
- Remove `pub(crate)` on fields that have a corresponding pub accessor function.
- Removed the `Archetypes: Default` impl, opting for a `pub(crate) fn new` alternative instead.
---
## Changelog
Added: `ArchetypeGeneration` now implements `Ord` and `PartialOrd`.
Removed: `Archetypes`'s `Default` implementation.
Removed: `Archetype::new` and `Archetype::is_empty`.
Removed: `ArchetypeId::new` and `ArchetypeId::value`.
Removed: `ArchetypeGeneration::value`
Removed: `ArchetypeIdentity`.
Removed: `ArchetypeComponentId::new` and `ArchetypeComponentId::value`.
Removed: `AddBundle`. `Edges::get_add_bundle` now returns `Option<ArchetypeId>`
# Objective
Fixes#4884. `ComponentTicks` stores both added and changed ticks contiguously in the same 8 bytes. This is convenient when passing around both together, but causes half the bytes fetched from memory for the purposes of change detection to effectively go unused. This is inefficient when most queries (no filter, mutating *something*) only write out to the changed ticks.
## Solution
Split the storage for change detection ticks into two separate `Vec`s inside `Column`. Fetch only what is needed during iteration.
This also potentially also removes one blocker from autovectorization of dense queries.
EDIT: This is confirmed to enable autovectorization of dense queries in `for_each` and `par_for_each` where possible. Unfortunately `iter` has other blockers that prevent it.
### TODO
- [x] Microbenchmark
- [x] Check if this allows query iteration to autovectorize simple loops.
- [x] Clean up all of the spurious tuples now littered throughout the API
### Open Questions
- ~~Is `Mut::is_added` absolutely necessary? Can we not just use `Added` or `ChangeTrackers`?~~ It's optimized out if unused.
- ~~Does the fetch of the added ticks get optimized out if not used?~~ Yes it is.
---
## Changelog
Added: `Tick`, a wrapper around a single change detection tick.
Added: `Column::get_added_ticks`
Added: `Column::get_column_ticks`
Added: `SparseSet::get_added_ticks`
Added: `SparseSet::get_column_ticks`
Changed: `Column` now stores added and changed ticks separately internally.
Changed: Most APIs returning `&UnsafeCell<ComponentTicks>` now returns `TickCells` instead, which contains two separate `&UnsafeCell<Tick>` for either component ticks.
Changed: `Query::for_each(_mut)`, `Query::par_for_each(_mut)` will now leverage autovectorization to speed up query iteration where possible.
## Migration Guide
TODO
# Objective
Fix#5149
## Solution
Instead of returning the **total count** of elements in the `QueryIter` in
`size_hint`, we return the **count of remaining elements**. This
Fixes#5149 even when #5148 gets merged.
- https://github.com/bevyengine/bevy/issues/5149
- https://github.com/bevyengine/bevy/pull/5148
---
## Changelog
- Fix partially consumed `QueryIter` and `QueryCombinationIter` having invalid `size_hint`
Co-authored-by: Nicola Papale <nicopap@users.noreply.github.com>
# Objective
* Enable `Res` and `Query` parameter mutual exclusion
* Required for https://github.com/bevyengine/bevy/pull/5080
The `FilteredAccessSet::get_conflicts` methods didn't work properly with
`Res` and `ResMut` parameters. Because those added their access by using
the `combined_access_mut` method and directly modifying the global
access state of the FilteredAccessSet. This caused an inconsistency,
because get_conflicts assumes that ALL added access have a corresponding
`FilteredAccess` added to the `filtered_accesses` field.
In practice, that means that SystemParam that adds their access through
the `Access` returned by `combined_access_mut` and the ones that add
their access using the `add` method lived in two different universes. As
a result, they could never be mutually exclusive.
## Solution
This commit fixes it by removing the `combined_access_mut` method. This
ensures that the `combined_access` field of FilteredAccessSet is always
updated consistently with the addition of a filter. When checking for
filtered access, it is now possible to account for `Res` and `ResMut`
invalid access. This is currently not needed, but might be in the
future.
We add the `add_unfiltered_{read,write}` methods to replace previous
usages of `combined_access_mut`.
We also add improved Debug implementations on FixedBitSet so that their
meaning is much clearer in debug output.
---
## Changelog
* Fix `Res` and `Query` parameter never being mutually exclusive.
## Migration Guide
Note: this mostly changes ECS internals, but since the API is public, it is technically breaking:
* Removed `FilteredAccessSet::combined_access_mut`
* Replace _immutable_ usage of those by `combined_access`
* For _mutable_ usages, use the new `add_unfiltered_{read,write}` methods instead of `combined_access_mut` followed by `add_{read,write}`
# Objective
When an error causes `debug_checked_unreachable` to be called, the panic message unhelpfully points to the function definition instead of the place that caused the error.
## Solution
Add the `#[track_caller]` attribute in debug mode.
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
# Objective
* Add benchmarks for `Query::get_many`.
* Speed up `Query::get_many`.
## Solution
Previously, `get_many` and `get_many_mut` used the method `array::map`, which tends to optimize very poorly. This PR replaces uses of that method with loops.
## Benchmarks
| Benchmark name | Execution time | Change from this PR |
|--------------------------------------|----------------|---------------------|
| query_get_many_2/50000_calls_table | 1.3732 ms | -24.967% |
| query_get_many_2/50000_calls_sparse | 1.3826 ms | -24.572% |
| query_get_many_5/50000_calls_table | 2.6833 ms | -30.681% |
| query_get_many_5/50000_calls_sparse | 2.9936 ms | -30.672% |
| query_get_many_10/50000_calls_table | 5.7771 ms | -36.950% |
| query_get_many_10/50000_calls_sparse | 7.4345 ms | -36.987% |
# Objective
Add documentation `#[world_query(ignore)]`. Fixes#6283.
---
I've only described it's behavior so far (which appears to be the same as with `system_param`). Is there another use-case for this besides with `PhantomData`? I could only find a single usage of this construct on GitHub, which is [here](ffcb816927/bevy/examples/ecs/custom_query_param.rs (L102)).
I was also wondering if it would make sense to add a usage example to the `custom_query_example`? 🤔 That's why it's currently still in there.
Co-authored-by: Lucas Jenß <243719+x3ro@users.noreply.github.com>
# Objective
Bevy still has many instances of using single-tuples `(T,)` to create a bundle. Due to #2975, this is no longer necessary.
## Solution
Search for regex `\(.+\s*,\)`. This should have found every instance.
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
## Solution
Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used.
External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop.
~~TODO: Benchmark, docs~~ Done.
---
## Changelog
Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function.
## Migration Guide
TODO
Co-authored-by: Brian Merchant <bhmerchang@gmail.com>
Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective
- Do not implement `Copy` or `Clone` for `Fetch` types as this is kind of sus soundness wise (it feels like cloning an `IterMut` in safe code to me). Cloning a fetch seems important to think about soundness wise when doing it so I prefer this over adding a `Clone` bound to the assoc type definition (i.e. `type Fetch: Clone`) even though that would also solve the other listed things here.
- Remove a bunch of `QueryFetch<'w, Q>: Clone` bounds from our API as now all fetches can be "cloned" for use in `iter_combinations`. This should also help avoid the type inference regression ptrification introduced where `for<'a> QueryFetch<'a, Q>: Trait` bounds misbehave since we no longer need any of those kind of higher ranked bounds (although in practice we had none anyway).
- Stop being able to "forget" to implement clone for fetches, we've had a lot of issues where either `derive(Clone)` was used instead of a manual impl (so we ended up with too tight bounds on the impl) or flat out forgot to implement Clone at all. With this change all fetches are able to be cloned for `iter_combinations` so this will no longer be possible to mess up.
On an unrelated note, while making this PR I realised we probably want safety invariants on `archetype/table_fetch` that nothing aliases the table_row/archetype_index according to the access we set.
---
## Changelog
`Clone` and `Copy` were removed from all `Fetch` types.
## Migration Guide
- Call `WorldQuery::clone_fetch` instead of `fetch.clone()`. Make sure to add safety comments :)
# Objective
I was trying to implement a collision system for my game, and believed that the iter_combinations method might be what I need. But I couldn't find a simple explanation of what a combination was in Bevy and thought it could use some more explanation.
## Solution
I added some description to the documentation that can hopefully further elaborate on what a combination is.
I also changed up the docs for the method because a combination is a different thing than a permutation but the Bevy docs seemed to use them interchangeably.
# Objective
- `QueryCombinationIter` can have sizes greater than `usize::MAX`.
- Fixes#5846
## Solution
- Only the implementation of `ExactSizeIterator` has been removed. Instead of using `query_combination.len()`, you can use `query_combination.size_hint().0` to get the same value as before.
---
## Migration Guide
- Switch to using other methods of getting the length.
Add the following message:
```
Items are returned in the order of the list of entities.
Entities that don't match the query are skipped.
```
Additionally, the docs in `iter.rs` and `state.rs` were updated to match those in `query.rs`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Speed up queries that are fragmented over many empty archetypes and tables.
## Solution
Add a early-out to check if the table or archetype is empty before iterating over it. This adds an extra branch for every archetype matched, but skips setting the archetype/table to the underlying state and any iteration over it.
This may not be worth it for the default `Query::iter` and maybe even the `Query::for_each` implementations, but this definitely avoids scheduling unnecessary tasks in the `Query::par_for_each` case.
Ideally, `matched_archetypes` should only contain archetypes where there's actually work to do, but this would add a `O(n)` flat cost to every call to `update_archetypes` that scales with the number of matched archetypes.
TODO: Benchmark
# Objective
There is currently no good way of getting the width (# of components) of a table outside of `bevy_ecs`.
# Solution
Added the methods `Table::{component_count, component_capacity}`
For consistency and clarity, renamed `Table::{len, capacity}` to `entity_count` and `entity_capacity`.
## Changelog
- Added the methods `Table::component_count` and `Table::component_capacity`
- Renamed `Table::len` and `Table::capacity` to `entity_count` and `entity_capacity`
## Migration Guide
Any use of `Table::len` should now be `Table::entity_count`. Any use of `Table::capacity` should now be `Table::entity_capacity`.
# Objective
- Adding Debug implementations for App, Stage, Schedule, Query, QueryState.
- Fixes#1130.
## Solution
- Implemented std::fmt::Debug for a number of structures.
---
## Changelog
Also added Debug implementations for ParallelSystemExecutor, SingleThreadedExecutor, various RunCriteria structures, SystemContainer, and SystemDescriptor.
Opinions are sure to differ as to what information to provide in a Debug implementation. Best guess was taken for this initial version for these structures.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
Take advantage of the "impl Bundle for Component" changes in #2975 / add the follow up changes discussed there.
## Solution
- Change `insert` and `remove` to accept a Bundle instead of a Component (for both Commands and World)
- Deprecate `insert_bundle`, `remove_bundle`, and `remove_bundle_intersection`
- Add `remove_intersection`
---
## Changelog
- Change `insert` and `remove` now accept a Bundle instead of a Component (for both Commands and World)
- `insert_bundle` and `remove_bundle` are deprecated
## Migration Guide
Replace `insert_bundle` with `insert`:
```rust
// Old (0.8)
commands.spawn().insert_bundle(SomeBundle::default());
// New (0.9)
commands.spawn().insert(SomeBundle::default());
```
Replace `remove_bundle` with `remove`:
```rust
// Old (0.8)
commands.entity(some_entity).remove_bundle::<SomeBundle>();
// New (0.9)
commands.entity(some_entity).remove::<SomeBundle>();
```
Replace `remove_bundle_intersection` with `remove_intersection`:
```rust
// Old (0.8)
world.entity_mut(some_entity).remove_bundle_intersection::<SomeBundle>();
// New (0.9)
world.entity_mut(some_entity).remove_intersection::<SomeBundle>();
```
Consider consolidating as many operations as possible to improve ergonomics and cut down on archetype moves:
```rust
// Old (0.8)
commands.spawn()
.insert_bundle(SomeBundle::default())
.insert(SomeComponent);
// New (0.9) - Option 1
commands.spawn().insert((
SomeBundle::default(),
SomeComponent,
))
// New (0.9) - Option 2
commands.spawn_bundle((
SomeBundle::default(),
SomeComponent,
))
```
## Next Steps
Consider changing `spawn` to accept a bundle and deprecate `spawn_bundle`.
# Objective
Fixes Issue #6005.
## Solution
Replaced WorldQuery with ReadOnlyWorldQuery on F generic in Query filters and QueryState to restrict its trait bound.
## Migration Guide
Query filter (`F`) generics are now bound by `ReadOnlyWorldQuery`, rather than `WorldQuery`. If for some reason you were requesting `Query<&A, &mut B>`, please use `Query<&A, With<B>>` instead.
Make API users aware that the type aliases `QueryItem` and `QueryFetch` can be used instead of the more bloated alternative with `WorldQueryGats`.
Fixes#5842
# Objective
- Document `QueryCombinationIter`
## Solution
- Describe the item, add usage and examples
- Copy notes about the number of query items generated from the corresponding query methods (they will be removed in #5742 ([motivation]))
## Additional notes
- Derived from #4989
[motivation]: https://github.com/bevyengine/bevy/pull/4989#issuecomment-1208421496
# Objective
Simplify the worldquery trait hierarchy as much as possible by putting it all in one trait. If/when gats are stabilised this can be trivially migrated over to use them, although that's not why I made this PR, those reasons are:
- Moves all of the conceptually related unsafe code for a worldquery next to eachother
- Removes now unnecessary traits simplifying the "type system magic" in bevy_ecs
---
## Changelog
All methods/functions/types/consts on `FetchState` and `Fetch` traits have been moved to the `WorldQuery` trait and the other traits removed. `WorldQueryGats` now only contains an `Item` and `Fetch` assoc type.
## Migration Guide
Implementors should move items in impls to the `WorldQuery/Gats` traits and remove any `Fetch`/`FetchState` impls
Any use sites of items in the `Fetch`/`FetchState` traits should be updated to use the `WorldQuery` trait items instead
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Replace `many_for_each_mut` with `iter_many_mut` using the same tricks to avoid aliased mutability that `iter_combinations_mut` uses.
<sub>I tried rebasing the draft PR I made for this before and it died. F</sub>
## Why
`many_for_each_mut` is worse for a few reasons:
1. The closure prevents the use of `continue`, `break`, and `return` behaves like a limited `continue`.
2. rustfmt will crumple it and double the indentation when the line gets too long.
```rust
query.many_for_each_mut(
&entity_list,
|(mut transform, velocity, mut component_c)| {
// Double trouble.
},
);
```
3. It is more surprising to have `many_for_each_mut` as a mutable counterpart to `iter_many` than `iter_many_mut`.
4. It required a separate unsafe fn; more unsafe code to maintain.
5. The `iter_many_mut` API matches the existing `iter_combinations_mut` API.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
{kind=link}
{kind=link}