# Objective
Now that #13432 has been merged, it's important we update our reflected
types to properly opt into this feature. If we do not, then this could
cause issues for users downstream who want to make use of
reflection-based cloning.
## Solution
This PR is broken into 4 commits:
1. Add `#[reflect(Clone)]` on all types marked `#[reflect(opaque)]` that
are also `Clone`. This is mandatory as these types would otherwise cause
the cloning operation to fail for any type that contains it at any
depth.
2. Update the reflection example to suggest adding `#[reflect(Clone)]`
on opaque types.
3. Add `#[reflect(clone)]` attributes on all fields marked
`#[reflect(ignore)]` that are also `Clone`. This prevents the ignored
field from causing the cloning operation to fail.
Note that some of the types that contain these fields are also `Clone`,
and thus can be marked `#[reflect(Clone)]`. This makes the
`#[reflect(clone)]` attribute redundant. However, I think it's safer to
keep it marked in the case that the `Clone` impl/derive is ever removed.
I'm open to removing them, though, if people disagree.
4. Finally, I added `#[reflect(Clone)]` on all types that are also
`Clone`. While not strictly necessary, it enables us to reduce the
generated output since we can just call `Clone::clone` directly instead
of calling `PartialReflect::reflect_clone` on each variant/field. It
also means we benefit from any optimizations or customizations made in
the `Clone` impl, including directly dereferencing `Copy` values and
increasing reference counters.
Along with that change I also took the liberty of adding any missing
registrations that I saw could be applied to the type as well, such as
`Default`, `PartialEq`, and `Hash`. There were hundreds of these to
edit, though, so it's possible I missed quite a few.
That last commit is **_massive_**. There were nearly 700 types to
update. So it's recommended to review the first three before moving onto
that last one.
Additionally, I can break the last commit off into its own PR or into
smaller PRs, but I figured this would be the easiest way of doing it
(and in a timely manner since I unfortunately don't have as much time as
I used to for code contributions).
## Testing
You can test locally with a `cargo check`:
```
cargo check --workspace --all-features
```
# Objective
Fix unsound query transmutes on queries obtained from
`Query::as_readonly()`.
The following compiles, and the call to `transmute_lens()` should panic,
but does not:
```rust
fn bad_system(query: Query<&mut A>) {
let mut readonly = query.as_readonly();
let mut lens: QueryLens<&mut A> = readonly.transmute_lens();
let other_readonly: Query<&A> = query.as_readonly();
// `lens` and `other_readonly` alias, and are both alive here!
}
```
To make `Query::as_readonly()` zero-cost, we pointer-cast
`&QueryState<D, F>` to `&QueryState<D::ReadOnly, F>`. This means that
the `component_access` for a read-only query's state may include
accesses for the original mutable version, but the `Query` does not have
exclusive access to those components! `transmute` and `join` use that
access to ensure that a join is valid, and will incorrectly allow a
transmute that includes mutable access.
As a bonus, allow `Query::join`s that output `FilteredEntityRef` or
`FilteredEntityMut` to receive access from the `other` query. Currently
they only receive access from `self`.
## Solution
When transmuting or joining from a read-only query, remove any writes
before performing checking that the transmute is valid. For joins, be
sure to handle the case where one input query was the result of
`as_readonly()` but the other has valid mutable access.
This requires identifying read-only queries, so add a
`QueryData::IS_READ_ONLY` associated constant. Note that we only call
`QueryState::as_transmuted_state()` with `NewD: ReadOnlyQueryData`, so
checking for read-only queries is sufficient to check for
`as_transmuted_state()`.
Removing writes requires allocating a new `FilteredAccess`, so only do
so if the query is read-only and the state has writes. Otherwise, the
existing access is correct and we can continue using a reference to it.
Use the new read-only state to call `NewD::set_access`, so that
transmuting to a `FilteredAccessMut` results in a read-only
`FilteredAccessMut`. Otherwise, it would take the original write access,
and then the transmute would panic because it had too much access.
Note that `join` was previously passing `self.component_access` to
`NewD::set_access`. Switching it to `joined_component_access` also
allows a join that outputs `FilteredEntity(Ref|Mut)` to receive access
from `other`. The fact that it didn't do that before seems like an
oversight, so I didn't try to prevent that change.
## Testing
Added unit tests with the unsound transmute and join.
# Objective
As discussed in #14275, Bevy is currently too prone to panic, and makes
the easy / beginner-friendly way to do a large number of operations just
to panic on failure.
This is seriously frustrating in library code, but also slows down
development, as many of the `Query::single` panics can actually safely
be an early return (these panics are often due to a small ordering issue
or a change in game state.
More critically, in most "finished" products, panics are unacceptable:
any unexpected failures should be handled elsewhere. That's where the
new
With the advent of good system error handling, we can now remove this.
Note: I was instrumental in a) introducing this idea in the first place
and b) pushing to make the panicking variant the default. The
introduction of both `let else` statements in Rust and the fancy system
error handling work in 0.16 have changed my mind on the right balance
here.
## Solution
1. Make `Query::single` and `Query::single_mut` (and other random
related methods) return a `Result`.
2. Handle all of Bevy's internal usage of these APIs.
3. Deprecate `Query::get_single` and friends, since we've moved their
functionality to the nice names.
4. Add detailed advice on how to best handle these errors.
Generally I like the diff here, although `get_single().unwrap()` in
tests is a bit of a downgrade.
## Testing
I've done a global search for `.single` to track down any missed
deprecated usages.
As to whether or not all the migrations were successful, that's what CI
is for :)
## Future work
~~Rename `Query::get_single` and friends to `Query::single`!~~
~~I've opted not to do this in this PR, and smear it across two releases
in order to ease the migration. Successive deprecations are much easier
to manage than the semantics and types shifting under your feet.~~
Cart has convinced me to change my mind on this; see
https://github.com/bevyengine/bevy/pull/18082#discussion_r1974536085.
## Migration guide
`Query::single`, `Query::single_mut` and their `QueryState` equivalents
now return a `Result`. Generally, you'll want to:
1. Use Bevy 0.16's system error handling to return a `Result` using the
`?` operator.
2. Use a `let else Ok(data)` block to early return if it's an expected
failure.
3. Use `unwrap()` or `Ok` destructuring inside of tests.
The old `Query::get_single` (etc) methods which did this have been
deprecated.
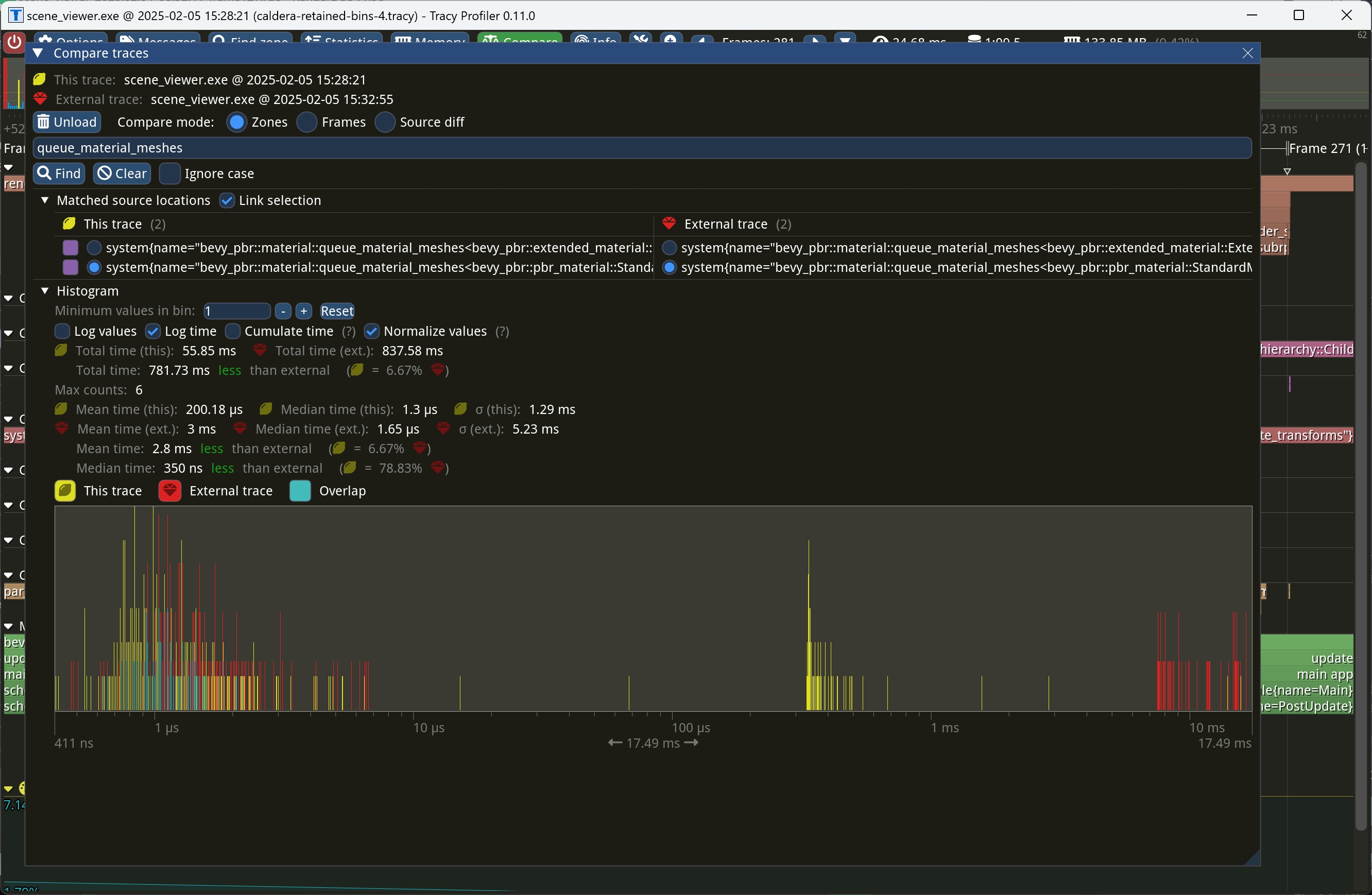
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
# Objective
Fixes#17662
## Solution
Moved `Item` and `fetch` from `WorldQuery` to `QueryData`, and adjusted
their implementations accordingly.
Currently, documentation related to `fetch` is written under
`WorldQuery`. It would be more appropriate to move it to the `QueryData`
documentation for clarity.
I am not very experienced with making contributions. If there are any
mistakes or areas for improvement, I would appreciate any suggestions
you may have.
## Migration Guide
The `WorldQuery::Item` type and `WorldQuery::fetch` method have been
moved to `QueryData`, as they were not useful for `QueryFilter` types.
---------
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
# Objective
- Contributes to #16877
## Solution
- Moved `hashbrown`, `foldhash`, and related types out of `bevy_utils`
and into `bevy_platform_support`
- Refactored the above to match the layout of these types in `std`.
- Updated crates as required.
## Testing
- CI
---
## Migration Guide
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::hash`:
- `FixedState`
- `DefaultHasher`
- `RandomState`
- `FixedHasher`
- `Hashed`
- `PassHash`
- `PassHasher`
- `NoOpHash`
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::collections`:
- `HashMap`
- `HashSet`
- `bevy_utils::hashbrown` has been removed. Instead, import from
`bevy_platform_support::collections` _or_ take a dependency on
`hashbrown` directly.
- `bevy_utils::Entry` has been removed. Instead, import from
`bevy_platform_support::collections::hash_map` or
`bevy_platform_support::collections::hash_set` as appropriate.
- All of the above equally apply to `bevy::utils` and
`bevy::platform_support`.
## Notes
- I left `PreHashMap`, `PreHashMapExt`, and `TypeIdMap` in `bevy_utils`
as they might be candidates for micro-crating. They can always be moved
into `bevy_platform_support` at a later date if desired.
# Objective
`bevy_ecs`'s `system` module is something of a grab bag, and *very*
large. This is particularly true for the `system_param` module, which is
more than 2k lines long!
While it could be defensible to put `Res` and `ResMut` there (lol no
they're in change_detection.rs, obviously), it doesn't make any sense to
put the `Resource` trait there. This is confusing to navigate (and
painful to work on and review).
## Solution
- Create a root level `bevy_ecs/resource.rs` module to mirror
`bevy_ecs/component.rs`
- move the `Resource` trait to that module
- move the `Resource` derive macro to that module as well (Rust really
likes when you pun on the names of the derive macro and trait and put
them in the same path)
- fix all of the imports
## Notes to reviewers
- We could probably move more stuff into here, but I wanted to keep this
PR as small as possible given the absurd level of import changes.
- This PR is ground work for my upcoming attempts to store resource data
on components (resources-as-entities). Splitting this code out will make
the work and review a bit easier, and is the sort of overdue refactor
that's good to do as part of more meaningful work.
## Testing
cargo build works!
## Migration Guide
`bevy_ecs::system::Resource` has been moved to
`bevy_ecs::resource::Resource`.
# Objective
Some types like `RenderEntity` and `MainEntity` are just wrappers around
`Entity`, so they should be able to implement
`EntityBorrow`/`TrustedEntityBorrow`. This allows using them with
`EntitySet` functionality.
The `EntityRef` family are more than direct wrappers around `Entity`,
but can still benefit from being unique in a collection.
## Solution
Implement `EntityBorrow` and `TrustedEntityBorrow` for simple `Entity`
newtypes and `EntityRef` types.
These impls are an explicit decision to have the `EntityRef` types
compare like just `Entity`.
`EntityWorldMut` is omitted from this impl, because it explicitly
contains a `&mut World` as well, and we do not ever use more than one at
a time.
Add `EntityBorrow` to the `bevy_ecs` prelude.
## Migration Guide
`NormalizedWindowRef::entity` has been replaced with an
`EntityBorrow::entity` impl.
# Objective
Fixes#16659
## Solution
- I just added all the `#[reflect(Component)]` attributes where
necessary.
## Testing
I wrote a small program that scans the bevy code for all structs and
enums that derive `Component` and `Reflect`, but don't have the
attribute `#[reflect(Component)]`.
I don't know if this testing program should be part of the testing suite
of bevy. It takes a bit of time to scan the whole codebase. In any case,
I've published it [here](https://github.com/anlumo/bevy-reflect-check).
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- A `Trigger` has multiple associated `Entity`s - the entity observing
the event, and the entity that was targeted by the event.
- The field `entity: Entity` encodes no semantic information about what
the entity is used for, you can already tell that it's an `Entity` by
the type signature!
## Solution
- Rename `trigger.entity()` to `trigger.target()`
---
## Changelog
- `Trigger`s are associated with multiple entities. `Trigger::entity()`
has been renamed to `Trigger::target()` to reflect the semantics of the
entity being returned.
## Migration Guide
- Rename `Trigger::entity()` to `Trigger::target()`.
- Rename `ObserverTrigger::entity` to `ObserverTrigger::target`
# Objective
`TemporaryRenderEntity` currently uses `SparseSet` storage, but doesn't
seem to fit the criteria for a component that would benefit from this.
Typical usage of `TemporaryRenderEntity` (and all current usages of it
in engine as far as I can tell) would be to spawn an entity with it once
and then iterate over it once to despawn that entity.
`SparseSet` is said to be useful for insert/removal perf at the cost of
iteration perf.
## Solution
Use the default table storage
## Testing
Possibly this could show up in stress tests like `many_buttons`. I
didn't do any benchmarking.
# Objective
Original motivation was a bundle I am migrating that is `Copy` which
needs to be synced to the render world. It probably doesn't actually
*need* to be `Copy`, so this isn't critical or anything.
I am continuing to use this bundle while bundles still exist to give
users an easier migration path.
## Solution
These ZSTs might as well be `Copy`. Add `Copy` derives.
# Objective
#15320 is a particularly painful breaking change, and the new
`RenderEntity` in particular is very noisy, with a lot of `let entity =
entity.id()` spam.
## Solution
Implement `WorldQuery`, `QueryData` and `ReadOnlyQueryData` for
`RenderEntity` and `WorldEntity`.
These work the same as the `Entity` impls from a user-facing
perspective: they simply return an owned (copied) `Entity` identifier.
This dramatically reduces noise and eases migration.
Under the hood, these impls defer to the implementations for `&T` for
everything other than the "call .id() for the user" bit, as they involve
read-only access to component data. Doing it this way (as opposed to
implementing a custom fetch, as tried in the first commit) dramatically
reduces the maintenance risk of complex unsafe code outside of
`bevy_ecs`.
To make this easier (and encourage users to do this themselves!), I've
made `ReadFetch` and `WriteFetch` slightly more public: they're no
longer `doc(hidden)`. This is a good change, since trying to vendor the
logic is much worse than just deferring to the existing tested impls.
## Testing
I've run a handful of rendering examples (breakout, alien_cake_addict,
auto_exposure, fog_volumes, box_shadow) and nothing broke.
## Follow-up
We should lint for the uses of `&RenderEntity` and `&MainEntity` in
queries: this is just less nice for no reason.
---------
Co-authored-by: Trashtalk217 <trashtalk217@gmail.com>
# Objective
In the Render World, there are a number of collections that are derived
from Main World entities and are used to drive rendering. The most
notable are:
- `VisibleEntities`, which is generated in the `check_visibility` system
and contains visible entities for a view.
- `ExtractedInstances`, which maps entity ids to asset ids.
In the old model, these collections were trivially kept in sync -- any
extracted phase item could look itself up because the render entity id
was guaranteed to always match the corresponding main world id.
After #15320, this became much more complicated, and was leading to a
number of subtle bugs in the Render World. The main rendering systems,
i.e. `queue_material_meshes` and `queue_material2d_meshes`, follow a
similar pattern:
```rust
for visible_entity in visible_entities.iter::<With<Mesh2d>>() {
let Some(mesh_instance) = render_mesh_instances.get_mut(visible_entity) else {
continue;
};
// Look some more stuff up and specialize the pipeline...
let bin_key = Opaque2dBinKey {
pipeline: pipeline_id,
draw_function: draw_opaque_2d,
asset_id: mesh_instance.mesh_asset_id.into(),
material_bind_group_id: material_2d.get_bind_group_id().0,
};
opaque_phase.add(
bin_key,
*visible_entity,
BinnedRenderPhaseType::mesh(mesh_instance.automatic_batching),
);
}
```
In this case, `visible_entities` and `render_mesh_instances` are both
collections that are created and keyed by Main World entity ids, and so
this lookup happens to work by coincidence. However, there is a major
unintentional bug here: namely, because `visible_entities` is a
collection of Main World ids, the phase item being queued is created
with a Main World id rather than its correct Render World id.
This happens to not break mesh rendering because the render commands
used for drawing meshes do not access the `ItemQuery` parameter, but
demonstrates the confusion that is now possible: our UI phase items are
correctly being queued with Render World ids while our meshes aren't.
Additionally, this makes it very easy and error prone to use the wrong
entity id to look up things like assets. For example, if instead we
ignored visibility checks and queued our meshes via a query, we'd have
to be extra careful to use `&MainEntity` instead of the natural
`Entity`.
## Solution
Make all collections that are derived from Main World data use
`MainEntity` as their key, to ensure type safety and avoid accidentally
looking up data with the wrong entity id:
```rust
pub type MainEntityHashMap<V> = hashbrown::HashMap<MainEntity, V, EntityHash>;
```
Additionally, we make all `PhaseItem` be able to provide both their Main
and Render World ids, to allow render phase implementors maximum
flexibility as to what id should be used to look up data.
You can think of this like tracking at the type level whether something
in the Render World should use it's "primary key", i.e. entity id, or
needs to use a foreign key, i.e. `MainEntity`.
## Testing
##### TODO:
This will require extensive testing to make sure things didn't break!
Additionally, some extraction logic has become more complicated and
needs to be checked for regressions.
## Migration Guide
With the advent of the retained render world, collections that contain
references to `Entity` that are extracted into the render world have
been changed to contain `MainEntity` in order to prevent errors where a
render world entity id is used to look up an item by accident. Custom
rendering code may need to be changed to query for `&MainEntity` in
order to look up the correct item from such a collection. Additionally,
users who implement their own extraction logic for collections of main
world entity should strongly consider extracting into a different
collection that uses `MainEntity` as a key.
Additionally, render phases now require specifying both the `Entity` and
`MainEntity` for a given `PhaseItem`. Custom render phases should ensure
`MainEntity` is available when queuing a phase item.
# Objective
- Closes#15752
Calling the functions `App::observe` and `World::observe` doesn't make
sense because you're not "observing" the `App` or `World`, you're adding
an observer that listens for an event that occurs *within* the `World`.
We should rename them to better fit this.
## Solution
Renames:
- `App::observe` -> `App::add_observer`
- `World::observe` -> `World::add_observer`
- `Commands::observe` -> `Commands::add_observer`
- `EntityWorldMut::observe_entity` -> `EntityWorldMut::observe`
(Note this isn't a breaking change as the original rename was introduced
earlier this cycle.)
## Testing
Reusing current tests.
# Objective
Fixes#15560
Fixes (most of) #15570
Currently a lot of examples (and presumably some user code) depend on
toggling certain render features by adding/removing a single component
to an entity, e.g. `SpotLight` to toggle a light. Because of the
retained render world this no longer works: Extract will add any new
components, but when it is removed the entity persists unchanged in the
render world.
## Solution
Add `SyncComponentPlugin<C: Component>` that registers
`SyncToRenderWorld` as a required component for `C`, and adds a
component hook that will clear all components from the render world
entity when `C` is removed. We add this plugin to
`ExtractComponentPlugin` which fixes most instances of the problem. For
custom extraction logic we can manually add `SyncComponentPlugin` for
that component.
We also rename `WorldSyncPlugin` to `SyncWorldPlugin` so we start a
naming convention like all the `Extract` plugins.
In this PR I also fixed a bunch of breakage related to the retained
render world, stemming from old code that assumed that `Entity` would be
the same in both worlds.
I found that using the `RenderEntity` wrapper instead of `Entity` in
data structures when referring to render world entities makes intent
much clearer, so I propose we make this an official pattern.
## Testing
Run examples like
```
cargo run --features pbr_multi_layer_material_textures --example clearcoat
cargo run --example volumetric_fog
```
and see that they work, and that toggles work correctly. But really we
should test every single example, as we might not even have caught all
the breakage yet.
---
## Migration Guide
The retained render world notes should be updated to explain this edge
case and `SyncComponentPlugin`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Trashtalk217 <trashtalk217@gmail.com>