Even though opaque deferred entities aren't placed into the `Opaque3d`
bin, we still want to cache them as though they were, so that we don't
have to re-queue them every frame. This commit implements that logic,
reducing the time of `queue_material_meshes` to near-zero on Caldera.
# Objective
- Fixes#17960
## Solution
- Followed the [edition upgrade
guide](https://doc.rust-lang.org/edition-guide/editions/transitioning-an-existing-project-to-a-new-edition.html)
## Testing
- CI
---
## Summary of Changes
### Documentation Indentation
When using lists in documentation, proper indentation is now linted for.
This means subsequent lines within the same list item must start at the
same indentation level as the item.
```rust
/* Valid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
/* Invalid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
```
### Implicit `!` to `()` Conversion
`!` (the never return type, returned by `panic!`, etc.) no longer
implicitly converts to `()`. This is particularly painful for systems
with `todo!` or `panic!` statements, as they will no longer be functions
returning `()` (or `Result<()>`), making them invalid systems for
functions like `add_systems`. The ideal fix would be to accept functions
returning `!` (or rather, _not_ returning), but this is blocked on the
[stabilisation of the `!` type
itself](https://doc.rust-lang.org/std/primitive.never.html), which is
not done.
The "simple" fix would be to add an explicit `-> ()` to system
signatures (e.g., `|| { todo!() }` becomes `|| -> () { todo!() }`).
However, this is _also_ banned, as there is an existing lint which (IMO,
incorrectly) marks this as an unnecessary annotation.
So, the "fix" (read: workaround) is to put these kinds of `|| -> ! { ...
}` closuers into variables and give the variable an explicit type (e.g.,
`fn()`).
```rust
// Valid
let system: fn() = || todo!("Not implemented yet!");
app.add_systems(..., system);
// Invalid
app.add_systems(..., || todo!("Not implemented yet!"));
```
### Temporary Variable Lifetimes
The order in which temporary variables are dropped has changed. The
simple fix here is _usually_ to just assign temporaries to a named
variable before use.
### `gen` is a keyword
We can no longer use the name `gen` as it is reserved for a future
generator syntax. This involved replacing uses of the name `gen` with
`r#gen` (the raw-identifier syntax).
### Formatting has changed
Use statements have had the order of imports changed, causing a
substantial +/-3,000 diff when applied. For now, I have opted-out of
this change by amending `rustfmt.toml`
```toml
style_edition = "2021"
```
This preserves the original formatting for now, reducing the size of
this PR. It would be a simple followup to update this to 2024 and run
`cargo fmt`.
### New `use<>` Opt-Out Syntax
Lifetimes are now implicitly included in RPIT types. There was a handful
of instances where it needed to be added to satisfy the borrow checker,
but there may be more cases where it _should_ be added to avoid
breakages in user code.
### `MyUnitStruct { .. }` is an invalid pattern
Previously, you could match against unit structs (and unit enum
variants) with a `{ .. }` destructuring. This is no longer valid.
### Pretty much every use of `ref` and `mut` are gone
Pattern binding has changed to the point where these terms are largely
unused now. They still serve a purpose, but it is far more niche now.
### `iter::repeat(...).take(...)` is bad
New lint recommends using the more explicit `iter::repeat_n(..., ...)`
instead.
## Migration Guide
The lifetimes of functions using return-position impl-trait (RPIT) are
likely _more_ conservative than they had been previously. If you
encounter lifetime issues with such a function, please create an issue
to investigate the addition of `+ use<...>`.
## Notes
- Check the individual commits for a clearer breakdown for what
_actually_ changed.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
## Objective
There's no general error for when an entity doesn't exist, and some
methods are going to need one when they get Resultified. The closest
thing is `EntityFetchError`, but that error has a slightly more specific
purpose.
## Solution
- Added `EntityDoesNotExistError`.
- Contains `Entity` and `EntityDoesNotExistDetails`.
- Changed `EntityFetchError` and `QueryEntityError`:
- Changed `NoSuchEntity` variant to wrap `EntityDoesNotExistError` and
renamed the variant to `EntityDoesNotExist`.
- Renamed `EntityFetchError` to `EntityMutableFetchError` to make its
purpose clearer.
- Renamed `TryDespawnError` to `EntityDespawnError` to make it more
general.
- Changed `World::inspect_entity` to return `Result<[ok],
EntityDoesNotExistError>` instead of panicking.
- Changed `World::get_entity` and `WorldEntityFetch::fetch_ref` to
return `Result<[ok], EntityDoesNotExistError>` instead of `Result<[ok],
Entity>`.
- Changed `UnsafeWorldCell::get_entity` to return
`Result<UnsafeEntityCell, EntityDoesNotExistError>` instead of
`Option<UnsafeEntityCell>`.
## Migration Guide
- `World::inspect_entity` now returns `Result<impl Iterator<Item =
&ComponentInfo>, EntityDoesNotExistError>` instead of `impl
Iterator<Item = &ComponentInfo>`.
- `World::get_entity` now returns `EntityDoesNotExistError` as an error
instead of `Entity`. You can still access the entity's ID through the
error's `entity` field.
- `UnsafeWorldCell::get_entity` now returns `Result<UnsafeEntityCell,
EntityDoesNotExistError>` instead of `Option<UnsafeEntityCell>`.
Currently, invocations of `batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` can't run in parallel because
they write to scene-global GPU buffers. After PR #17698,
`batch_and_prepare_binned_render_phase` started accounting for the
lion's share of the CPU time, causing us to be strongly CPU bound on
scenes like Caldera when occlusion culling was on (because of the
overhead of batching for the Z-prepass). Although I eventually plan to
optimize `batch_and_prepare_binned_render_phase`, we can obtain
significant wins now by parallelizing that system across phases.
This commit splits all GPU buffers that
`batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` touches into separate buffers
for each phase so that the scheduler will run those phases in parallel.
At the end of batch preparation, we gather the render phases up into a
single resource with a new *collection* phase. Because we already run
mesh preprocessing separately for each phase in order to make occlusion
culling work, this is actually a cleaner separation. For example, mesh
output indices (the unique ID that identifies each mesh instance on GPU)
are now guaranteed to be sequential starting from 0, which will simplify
the forthcoming work to remove them in favor of the compute dispatch ID.
On Caldera, this brings the frame time down to approximately 9.1 ms with
occlusion culling on.

Conceptually, bins are ordered hash maps. We currently implement these
as a list of keys with an associated hash map. But we already have a
data type that implements ordered hash maps directly: `IndexMap`. This
patch switches Bevy to use `IndexMap`s for bins. Because we're memory
bound, this doesn't affect performance much, but it is cleaner.
Currently, we look up each `MeshInputUniform` index in a hash table that
maps the main entity ID to the index every frame. This is inefficient,
cache unfriendly, and unnecessary, as the `MeshInputUniform` index for
an entity remains the same from frame to frame (even if the input
uniform changes). This commit changes the `IndexSet` in the `RenderBin`
to an `IndexMap` that maps the `MainEntity` to `MeshInputUniformIndex`
(a new type that this patch adds for more type safety).
On Caldera with parallel `batch_and_prepare_binned_render_phase`, this
patch improves that function from 3.18 ms to 2.42 ms, a 31% speedup.
Currently, we *sweep*, or remove entities from bins when those entities
became invisible or changed phases, during `queue_material_meshes` and
similar phases. This, however, is wrong, because `queue_material_meshes`
executes once per material type, not once per phase. This could result
in sweeping bins multiple times per phase, which can corrupt the bins.
This commit fixes the issue by moving sweeping to a separate system that
runs after queuing.
This manifested itself as entities appearing and disappearing seemingly
at random.
Closes#17759.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
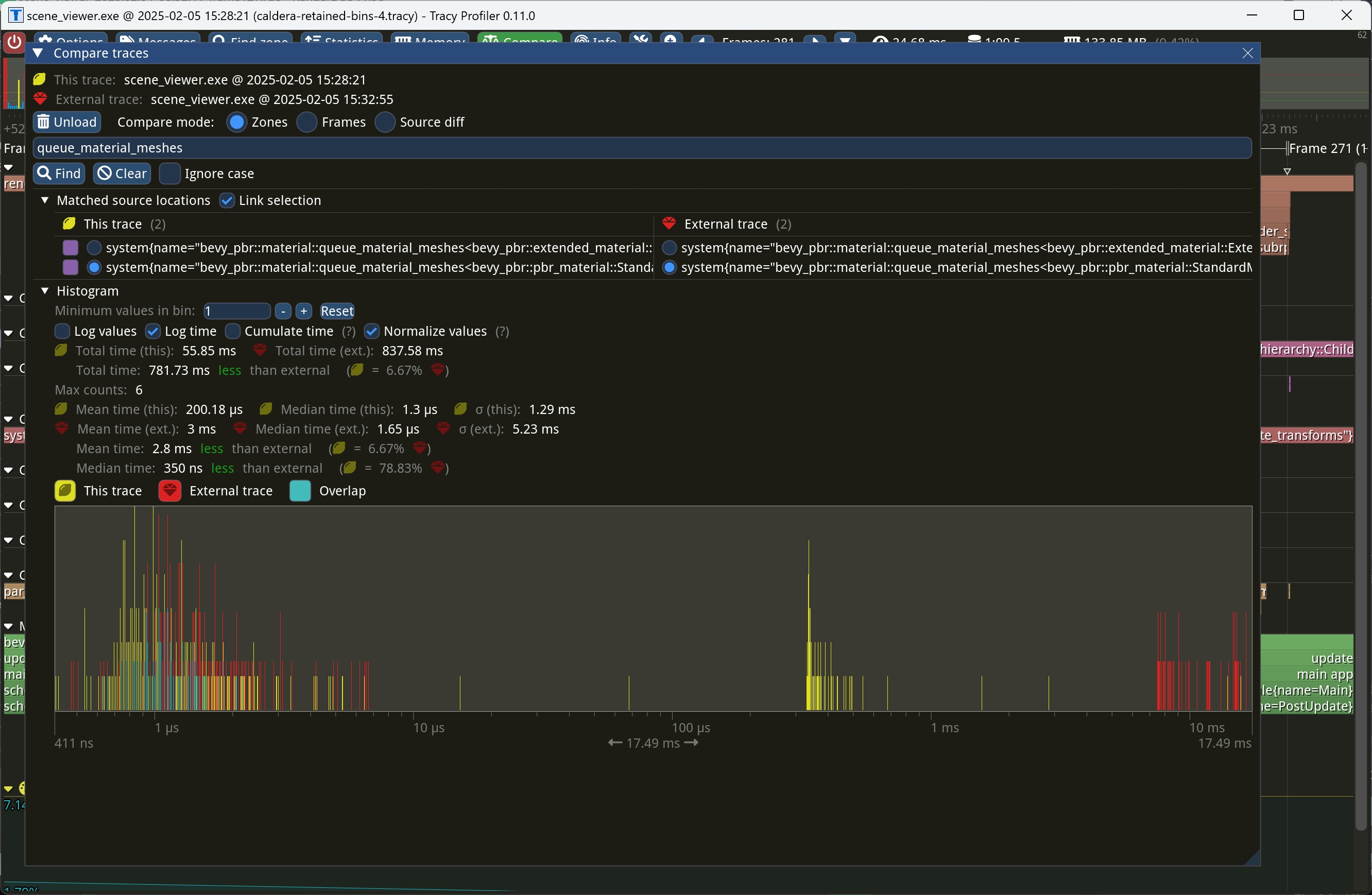
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
Data for the other batches is only accessed by the GPU, not the CPU, so
it's a waste of time and memory to store information relating to those
other batches.
On Bistro, this reduces time spent in
`batch_and_prepare_binned_render_phase` from 85.9 us to 61.2 us, a 40%
speedup.

# Objective
- Contributes to #16877
## Solution
- Moved `hashbrown`, `foldhash`, and related types out of `bevy_utils`
and into `bevy_platform_support`
- Refactored the above to match the layout of these types in `std`.
- Updated crates as required.
## Testing
- CI
---
## Migration Guide
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::hash`:
- `FixedState`
- `DefaultHasher`
- `RandomState`
- `FixedHasher`
- `Hashed`
- `PassHash`
- `PassHasher`
- `NoOpHash`
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::collections`:
- `HashMap`
- `HashSet`
- `bevy_utils::hashbrown` has been removed. Instead, import from
`bevy_platform_support::collections` _or_ take a dependency on
`hashbrown` directly.
- `bevy_utils::Entry` has been removed. Instead, import from
`bevy_platform_support::collections::hash_map` or
`bevy_platform_support::collections::hash_set` as appropriate.
- All of the above equally apply to `bevy::utils` and
`bevy::platform_support`.
## Notes
- I left `PreHashMap`, `PreHashMapExt`, and `TypeIdMap` in `bevy_utils`
as they might be candidates for micro-crating. They can always be moved
into `bevy_platform_support` at a later date if desired.
# Objective
`bevy_ecs`'s `system` module is something of a grab bag, and *very*
large. This is particularly true for the `system_param` module, which is
more than 2k lines long!
While it could be defensible to put `Res` and `ResMut` there (lol no
they're in change_detection.rs, obviously), it doesn't make any sense to
put the `Resource` trait there. This is confusing to navigate (and
painful to work on and review).
## Solution
- Create a root level `bevy_ecs/resource.rs` module to mirror
`bevy_ecs/component.rs`
- move the `Resource` trait to that module
- move the `Resource` derive macro to that module as well (Rust really
likes when you pun on the names of the derive macro and trait and put
them in the same path)
- fix all of the imports
## Notes to reviewers
- We could probably move more stuff into here, but I wanted to keep this
PR as small as possible given the absurd level of import changes.
- This PR is ground work for my upcoming attempts to store resource data
on components (resources-as-entities). Splitting this code out will make
the work and review a bit easier, and is the sort of overdue refactor
that's good to do as part of more meaningful work.
## Testing
cargo build works!
## Migration Guide
`bevy_ecs::system::Resource` has been moved to
`bevy_ecs::resource::Resource`.
This commit allows Bevy to use `multi_draw_indirect_count` for drawing
meshes. The `multi_draw_indirect_count` feature works just like
`multi_draw_indirect`, but it takes the number of indirect parameters
from a GPU buffer rather than specifying it on the CPU.
Currently, the CPU constructs the list of indirect draw parameters with
the instance count for each batch set to zero, uploads the resulting
buffer to the GPU, and dispatches a compute shader that bumps the
instance count for each mesh that survives culling. Unfortunately, this
is inefficient when we support `multi_draw_indirect_count`. Draw
commands corresponding to meshes for which all instances were culled
will remain present in the list when calling
`multi_draw_indirect_count`, causing overhead. Proper use of
`multi_draw_indirect_count` requires eliminating these empty draw
commands.
To address this inefficiency, this PR makes Bevy fully construct the
indirect draw commands on the GPU instead of on the CPU. Instead of
writing instance counts to the draw command buffer, the mesh
preprocessing shader now writes them to a separate *indirect metadata
buffer*. A second compute dispatch known as the *build indirect
parameters* shader runs after mesh preprocessing and converts the
indirect draw metadata into actual indirect draw commands for the GPU.
The build indirect parameters shader operates on a batch at a time,
rather than an instance at a time, and as such each thread writes only 0
or 1 indirect draw parameters, simplifying the current logic in
`mesh_preprocessing`, which currently has to have special cases for the
first mesh in each batch. The build indirect parameters shader emits
draw commands in a tightly packed manner, enabling maximally efficient
use of `multi_draw_indirect_count`.
Along the way, this patch switches mesh preprocessing to dispatch one
compute invocation per render phase per view, instead of dispatching one
compute invocation per view. This is preparation for two-phase occlusion
culling, in which we will have two mesh preprocessing stages. In that
scenario, the first mesh preprocessing stage must only process opaque
and alpha tested objects, so the work items must be separated into those
that are opaque or alpha tested and those that aren't. Thus this PR
splits out the work items into a separate buffer for each phase. As this
patch rewrites so much of the mesh preprocessing infrastructure, it was
simpler to just fold the change into this patch instead of deferring it
to the forthcoming occlusion culling PR.
Finally, this patch changes mesh preprocessing so that it runs
separately for indexed and non-indexed meshes. This is because draw
commands for indexed and non-indexed meshes have different sizes and
layouts. *The existing code is actually broken for non-indexed meshes*,
as it attempts to overlay the indirect parameters for non-indexed meshes
on top of those for indexed meshes. Consequently, right now the
parameters will be read incorrectly when multiple non-indexed meshes are
multi-drawn together. *This is a bug fix* and, as with the change to
dispatch phases separately noted above, was easiest to include in this
patch as opposed to separately.
## Migration Guide
* Systems that add custom phase items now need to populate the indirect
drawing-related buffers. See the `specialized_mesh_pipeline` example for
an example of how this is done.
We won't be able to retain render phases from frame to frame if the keys
are unstable. It's not as simple as simply keying off the main world
entity, however, because some main world entities extract to multiple
render world entities. For example, directional lights extract to
multiple shadow cascades, and point lights extract to one view per
cubemap face. Therefore, we key off a new type, `RetainedViewEntity`,
which contains the main entity plus a *subview ID*.
This is part of the preparation for retained bins.
---------
Co-authored-by: ickshonpe <david.curthoys@googlemail.com>
# Objective
Stumbled upon a `from <-> form` transposition while reviewing a PR,
thought it was interesting, and went down a bit of a rabbit hole.
## Solution
Fix em
# Objective
- https://github.com/bevyengine/bevy/issues/17111
## Solution
Set the `clippy::allow_attributes` and
`clippy::allow_attributes_without_reason` lints to `deny`, and bring
`bevy_render` in line with the new restrictions.
## Testing
`cargo clippy` and `cargo test --package bevy_render` were run, and no
errors were encountered.
Currently, our batchable binned items are stored in a hash table that
maps bin key, which includes the batch set key, to a list of entities.
Multidraw is handled by sorting the bin keys and accumulating adjacent
bins that can be multidrawn together (i.e. have the same batch set key)
into multidraw commands during `batch_and_prepare_binned_render_phase`.
This is reasonably efficient right now, but it will complicate future
work to retain indirect draw parameters from frame to frame. Consider
what must happen when we have retained indirect draw parameters and the
application adds a bin (i.e. a new mesh) that shares a batch set key
with some pre-existing meshes. (That is, the new mesh can be multidrawn
with the pre-existing meshes.) To be maximally efficient, our goal in
that scenario will be to update *only* the indirect draw parameters for
the batch set (i.e. multidraw command) containing the mesh that was
added, while leaving the others alone. That means that we have to
quickly locate all the bins that belong to the batch set being modified.
In the existing code, we would have to sort the list of bin keys so that
bins that can be multidrawn together become adjacent to one another in
the list. Then we would have to do a binary search through the sorted
list to find the location of the bin that was just added. Next, we would
have to widen our search to adjacent indexes that contain the same batch
set, doing expensive comparisons against the batch set key every time.
Finally, we would reallocate the indirect draw parameters and update the
stored pointers to the indirect draw parameters that the bins store.
By contrast, it'd be dramatically simpler if we simply changed the way
bins are stored to first map from batch set key (i.e. multidraw command)
to the bins (i.e. meshes) within that batch set key, and then from each
individual bin to the mesh instances. That way, the scenario above in
which we add a new mesh will be simpler to handle. First, we will look
up the batch set key corresponding to that mesh in the outer map to find
an inner map corresponding to the single multidraw command that will
draw that batch set. We will know how many meshes the multidraw command
is going to draw by the size of that inner map. Then we simply need to
reallocate the indirect draw parameters and update the pointers to those
parameters within the bins as necessary. There will be no need to do any
binary search or expensive batch set key comparison: only a single hash
lookup and an iteration over the inner map to update the pointers.
This patch implements the above technique. Because we don't have
retained bins yet, this PR provides no performance benefits. However, it
opens the door to maximally efficient updates when only a small number
of meshes change from frame to frame.
The main churn that this patch causes is that the *batch set key* (which
uniquely specifies a multidraw command) and *bin key* (which uniquely
specifies a mesh *within* that multidraw command) are now separate,
instead of the batch set key being embedded *within* the bin key.
In order to isolate potential regressions, I think that at least #16890,
#16836, and #16825 should land before this PR does.
## Migration Guide
* The *batch set key* is now separate from the *bin key* in
`BinnedPhaseItem`. The batch set key is used to collect multidrawable
meshes together. If you aren't using the multidraw feature, you can
safely set the batch set key to `()`.
# Objective
- Contributes to #11478
## Solution
- Made `bevy_utils::tracing` `doc(hidden)`
- Re-exported `tracing` from `bevy_log` for end-users
- Added `tracing` directly to crates that need it.
## Testing
- CI
---
## Migration Guide
If you were importing `tracing` via `bevy::utils::tracing`, instead use
`bevy::log::tracing`. Note that many items within `tracing` are also
directly re-exported from `bevy::log` as well, so you may only need
`bevy::log` for the most common items (e.g., `warn!`, `trace!`, etc.).
This also applies to the `log_once!` family of macros.
## Notes
- While this doesn't reduce the line-count in `bevy_utils`, it further
decouples the internal crates from `bevy_utils`, making its eventual
removal more feasible in the future.
- I have just imported `tracing` as we do for all dependencies. However,
a workspace dependency may be more appropriate for version management.
This commit makes the following changes:
* `IndirectParametersBuffer` has been changed from a `BufferVec` to a
`RawBufferVec`. This won about 20us or so on Bistro by avoiding `encase`
overhead.
* The methods on the `GetFullBatchData` trait no longer have the
`entity` parameter, as it was unused.
* `PreprocessWorkItem`, which specifies a transform-and-cull operation,
now supplies the mesh instance uniform output index directly instead of
having the shader look it up from the indirect draw parameters.
Accordingly, the responsibility of writing the output index to the
indirect draw parameters has been moved from the CPU to the GPU. This is
in preparation for retained indirect instance draw commands, where the
mesh instance uniform output index may change from frame to frame, while
the indirect instance draw commands will be cached. We won't want the
CPU to have to upload the same indirect draw parameters again and again
if a batch didn't change from frame to frame.
* `batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` now allocate indirect draw
commands for an entire batch set at a time when possible, instead of one
batch at a time. This change will allow us to retain the indirect draw
commands for whole batch sets.
* `GetFullBatchData::get_batch_indirect_parameters_index` has been
replaced with `GetFullBatchData::write_batch_indirect_parameters`, which
takes an offset and writes into it instead of allocating. This is
necessary in order to use the optimization mentioned in the previous
point.
* At the WGSL level, `IndirectParameters` has been factored out into
`mesh_preprocess_types.wgsl`. This is because we'll need a new compute
shader that zeroes out the instance counts in preparation for a new
frame. That shader will need to access `IndirectParameters`, so it was
moved to a separate file.
* Bins are no longer raw vectors but are instances of a separate type,
`RenderBin`. This is so that the bin can eventually contain its retained
batches.
# Objective
Expand `track_change_detection` feature to also track entity spawns and
despawns. Use this to create better error messages.
# Solution
Adds `Entities::entity_get_spawned_or_despawned_by` as well as `{all
entity reference types}::spawned_by`.
This also removes the deprecated `get_many_entities_mut` & co (and
therefore can't land in 0.15) because we don't yet have no Polonius.
## Testing
Added a test that checks that the locations get updated and these
updates are ordered correctly vs hooks & observers.
---
## Showcase
Access location:
```rust
let mut world = World::new();
let entity = world.spawn_empty().id();
println!("spawned by: {}", world.entity(entity).spawned_by());
```
```
spawned by: src/main.rs:5:24
```
Error message (with `track_change_detection`):
```rust
world.despawn(entity);
world.entity(entity);
```
```
thread 'main' panicked at src/main.rs:11:11:
Entity 0v1#4294967296 was despawned by src/main.rs:10:11
```
and without:
```
thread 'main' panicked at src/main.rs:11:11:
Entity 0v1#4294967296 does not exist (enable `track_change_detection` feature for more details)
```
Similar error messages now also exists for `Query::get`,
`World::entity_mut`, `EntityCommands` creation and everything that
causes `B0003`, e.g.
```
error[B0003]: Could not insert a bundle (of type `MaterialMeshBundle<StandardMaterial>`) for entity Entity { index: 7, generation: 1 }, which was despawned by src/main.rs:10:11. See: https://bevyengine.org/learn/errors/#b0003
```
---------
Co-authored-by: kurk070ff <108901106+kurk070ff@users.noreply.github.com>
Co-authored-by: Freya Pines <freya@MacBookAir.lan>
Co-authored-by: Freya Pines <freya@Freyas-MacBook-Air.local>
Co-authored-by: Matty Weatherley <weatherleymatthew@gmail.com>
This commit adds support for *multidraw*, which is a feature that allows
multiple meshes to be drawn in a single drawcall. `wgpu` currently
implements multidraw on Vulkan, so this feature is only enabled there.
Multiple meshes can be drawn at once if they're in the same vertex and
index buffers and are otherwise placed in the same bin. (Thus, for
example, at present the materials and textures must be identical, but
see #16368.) Multidraw is a significant performance improvement during
the draw phase because it reduces the number of rebindings, as well as
the number of drawcalls.
This feature is currently only enabled when GPU culling is used: i.e.
when `GpuCulling` is present on a camera. Therefore, if you run for
example `scene_viewer`, you will not see any performance improvements,
because `scene_viewer` doesn't add the `GpuCulling` component to its
camera.
Additionally, the multidraw feature is only implemented for opaque 3D
meshes and not for shadows or 2D meshes. I plan to make GPU culling the
default and to extend the feature to shadows in the future. Also, in the
future I suspect that polyfilling multidraw on APIs that don't support
it will be fruitful, as even without driver-level support use of
multidraw allows us to avoid expensive `wgpu` rebindings.
# Objective
- Remove `derive_more`'s error derivation and replace it with
`thiserror`
## Solution
- Added `derive_more`'s `error` feature to `deny.toml` to prevent it
sneaking back in.
- Reverted to `thiserror` error derivation
## Notes
Merge conflicts were too numerous to revert the individual changes, so
this reversion was done manually. Please scrutinise carefully during
review.
# Objective
Fixes#15941
## Solution
Created https://crates.io/crates/variadics_please and moved the code
there; updating references
`bevy_utils/macros` is deleted.
## Testing
cargo check
## Migration Guide
Use `variadics_please::{all_tuples, all_tuples_with_size}` instead of
`bevy::utils::{all_tuples, all_tuples_with_size}`.
# Objective
In the Render World, there are a number of collections that are derived
from Main World entities and are used to drive rendering. The most
notable are:
- `VisibleEntities`, which is generated in the `check_visibility` system
and contains visible entities for a view.
- `ExtractedInstances`, which maps entity ids to asset ids.
In the old model, these collections were trivially kept in sync -- any
extracted phase item could look itself up because the render entity id
was guaranteed to always match the corresponding main world id.
After #15320, this became much more complicated, and was leading to a
number of subtle bugs in the Render World. The main rendering systems,
i.e. `queue_material_meshes` and `queue_material2d_meshes`, follow a
similar pattern:
```rust
for visible_entity in visible_entities.iter::<With<Mesh2d>>() {
let Some(mesh_instance) = render_mesh_instances.get_mut(visible_entity) else {
continue;
};
// Look some more stuff up and specialize the pipeline...
let bin_key = Opaque2dBinKey {
pipeline: pipeline_id,
draw_function: draw_opaque_2d,
asset_id: mesh_instance.mesh_asset_id.into(),
material_bind_group_id: material_2d.get_bind_group_id().0,
};
opaque_phase.add(
bin_key,
*visible_entity,
BinnedRenderPhaseType::mesh(mesh_instance.automatic_batching),
);
}
```
In this case, `visible_entities` and `render_mesh_instances` are both
collections that are created and keyed by Main World entity ids, and so
this lookup happens to work by coincidence. However, there is a major
unintentional bug here: namely, because `visible_entities` is a
collection of Main World ids, the phase item being queued is created
with a Main World id rather than its correct Render World id.
This happens to not break mesh rendering because the render commands
used for drawing meshes do not access the `ItemQuery` parameter, but
demonstrates the confusion that is now possible: our UI phase items are
correctly being queued with Render World ids while our meshes aren't.
Additionally, this makes it very easy and error prone to use the wrong
entity id to look up things like assets. For example, if instead we
ignored visibility checks and queued our meshes via a query, we'd have
to be extra careful to use `&MainEntity` instead of the natural
`Entity`.
## Solution
Make all collections that are derived from Main World data use
`MainEntity` as their key, to ensure type safety and avoid accidentally
looking up data with the wrong entity id:
```rust
pub type MainEntityHashMap<V> = hashbrown::HashMap<MainEntity, V, EntityHash>;
```
Additionally, we make all `PhaseItem` be able to provide both their Main
and Render World ids, to allow render phase implementors maximum
flexibility as to what id should be used to look up data.
You can think of this like tracking at the type level whether something
in the Render World should use it's "primary key", i.e. entity id, or
needs to use a foreign key, i.e. `MainEntity`.
## Testing
##### TODO:
This will require extensive testing to make sure things didn't break!
Additionally, some extraction logic has become more complicated and
needs to be checked for regressions.
## Migration Guide
With the advent of the retained render world, collections that contain
references to `Entity` that are extracted into the render world have
been changed to contain `MainEntity` in order to prevent errors where a
render world entity id is used to look up an item by accident. Custom
rendering code may need to be changed to query for `&MainEntity` in
order to look up the correct item from such a collection. Additionally,
users who implement their own extraction logic for collections of main
world entity should strongly consider extracting into a different
collection that uses `MainEntity` as a key.
Additionally, render phases now require specifying both the `Entity` and
`MainEntity` for a given `PhaseItem`. Custom render phases should ensure
`MainEntity` is available when queuing a phase item.
# Objective
- Fixes#6370
- Closes#6581
## Solution
- Added the following lints to the workspace:
- `std_instead_of_core`
- `std_instead_of_alloc`
- `alloc_instead_of_core`
- Used `cargo +nightly fmt` with [item level use
formatting](https://rust-lang.github.io/rustfmt/?version=v1.6.0&search=#Item%5C%3A)
to split all `use` statements into single items.
- Used `cargo clippy --workspace --all-targets --all-features --fix
--allow-dirty` to _attempt_ to resolve the new linting issues, and
intervened where the lint was unable to resolve the issue automatically
(usually due to needing an `extern crate alloc;` statement in a crate
root).
- Manually removed certain uses of `std` where negative feature gating
prevented `--all-features` from finding the offending uses.
- Used `cargo +nightly fmt` with [crate level use
formatting](https://rust-lang.github.io/rustfmt/?version=v1.6.0&search=#Crate%5C%3A)
to re-merge all `use` statements matching Bevy's previous styling.
- Manually fixed cases where the `fmt` tool could not re-merge `use`
statements due to conditional compilation attributes.
## Testing
- Ran CI locally
## Migration Guide
The MSRV is now 1.81. Please update to this version or higher.
## Notes
- This is a _massive_ change to try and push through, which is why I've
outlined the semi-automatic steps I used to create this PR, in case this
fails and someone else tries again in the future.
- Making this change has no impact on user code, but does mean Bevy
contributors will be warned to use `core` and `alloc` instead of `std`
where possible.
- This lint is a critical first step towards investigating `no_std`
options for Bevy.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
Make it easier to debug why an entity doesn't match a query.
## Solution
List the entities components in `QueryEntityError::QueryDoesNotMatch`'s
message, e.g. `The query does not match the entity 0v1, which has
components foo::Bar, foo::Baz`.
This covers most cases as expected components are typically known and
filtering for change detection is rare when assessing a query by entity
id.
## Testing
Added a test confirming the new message matches the entity's components.
## Migration Guide
- `QueryEntityError` now has a lifetime. Convert it to a custom error if
you need to store it.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: poopy <gonesbird@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/13225
## Solution
Invalidate `TrackedRenderPass` internal state upon accessing internal
`wgpu::RenderPass`.
## Testing
- Tested by calling `set_bind_group` on `RenderPass` returned by
`TrackedRenderPass::wgpu_pass` and checking if in later `set_bind_group`
calls on `TrackedRenderPass` correct bind group is restored.
# Objective
- Fixes#14841
## Solution
- Compute BufferSlice size manually and use it for comparison in
`TrackedRenderPass`
## Testing
- Gizmo example does not crash with #14721 (without system ordering),
and `slice` computes correct size there
---
## Migration Guide
- `TrackedRenderPass::set_vertex_buffer` function has been modified to
update vertex buffers when the same buffer with the same offset is
provided, but its size has changed. Some existing code may rely on the
previous behavior, which did not update the vertex buffer in this
scenario.
---------
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
# Objective
Fixes#14782
## Solution
Enable the lint and fix all upcoming hints (`--fix`). Also tried to
figure out the false-positive (see review comment). Maybe split this PR
up into multiple parts where only the last one enables the lint, so some
can already be merged resulting in less many files touched / less
potential for merge conflicts?
Currently, there are some cases where it might be easier to read the
code with the qualifier, so perhaps remove the import of it and adapt
its cases? In the current stage it's just a plain adoption of the
suggestions in order to have a base to discuss.
## Testing
`cargo clippy` and `cargo run -p ci` are happy.
# Objective
- Fixes#14697
## Solution
This PR modifies the existing `all_tuples!` macro to optionally accept a
`#[doc(fake_variadic)]` attribute in its input. If the attribute is
present, each invocation of the impl macro gets the correct attributes
(i.e. the first impl receives `#[doc(fake_variadic)]` while the other
impls are hidden using `#[doc(hidden)]`.
Impls for the empty tuple (unit type) are left untouched (that's what
the [standard
library](https://doc.rust-lang.org/std/cmp/trait.PartialEq.html#impl-PartialEq-for-())
and
[serde](https://docs.rs/serde/latest/serde/trait.Serialize.html#impl-Serialize-for-())
do).
To work around https://github.com/rust-lang/cargo/issues/8811 and to get
impls on re-exports to correctly show up as variadic, `--cfg docsrs_dep`
is passed when building the docs for the toplevel `bevy` crate.
`#[doc(fake_variadic)]` only works on tuples and fn pointers, so impls
for structs like `AnyOf<(T1, T2, ..., Tn)>` are unchanged.
## Testing
I built the docs locally using `RUSTDOCFLAGS='--cfg docsrs'
RUSTFLAGS='--cfg docsrs_dep' cargo +nightly doc --no-deps --workspace`
and checked the documentation page of a trait both in its original crate
and the re-exported version in `bevy`.
The description should correctly mention for how many tuple items the
trait is implemented.
I added `rustc-args` for docs.rs to the `bevy` crate, I hope there
aren't any other notable crates that re-export `#[doc(fake_variadic)]`
traits.
---
## Showcase
`bevy_ecs::query::QueryData`:
<img width="1015" alt="Screenshot 2024-08-12 at 16 41 28"
src="https://github.com/user-attachments/assets/d40136ed-6731-475f-91a0-9df255cd24e3">
`bevy::ecs::query::QueryData` (re-export):
<img width="1005" alt="Screenshot 2024-08-12 at 16 42 57"
src="https://github.com/user-attachments/assets/71d44cf0-0ab0-48b0-9a51-5ce332594e12">
## Original Description
<details>
Resolves#14697
Submitting as a draft for now, very WIP.
Unfortunately, the docs don't show the variadics nicely when looking at
reexported items.
For example:
`bevy_ecs::bundle::Bundle` correctly shows the variadic impl:

while `bevy::ecs::bundle::Bundle` (the reexport) shows all the impls
(not good):

Built using `RUSTDOCFLAGS='--cfg docsrs' cargo +nightly doc --workspace
--no-deps` (`--no-deps` because of wgpu-core).
Maybe I missed something or this is a limitation in the *totally not
private* `#[doc(fake_variadic)]` thingy. In any case I desperately need
some sleep now :))
</details>
# Objective
- It's possible to have errors in a draw command, but these errors are
ignored
## Solution
- Return a result with the error
## Changelog
Renamed `RenderCommandResult::Failure` to `RenderCommandResult::Skip`
Added a `reason` string parameter to `RenderCommandResult::Failure`
## Migration Guide
If you were using `RenderCommandResult::Failure` to just ignore an error
and retry later, use `RenderCommandResult::Skip` instead.
This wasn't intentional, but this PR should also help with
https://github.com/bevyengine/bevy/issues/12660 since we can turn a few
unwraps into error messages now.
---------
Co-authored-by: Charlotte McElwain <charlotte.c.mcelwain@gmail.com>
As reported in #14004, many third-party plugins, such as Hanabi, enqueue
entities that don't have meshes into render phases. However, the
introduction of indirect mode added a dependency on mesh-specific data,
breaking this workflow. This is because GPU preprocessing requires that
the render phases manage indirect draw parameters, which don't apply to
objects that aren't meshes. The existing code skips over binned entities
that don't have indirect draw parameters, which causes the rendering to
be skipped for such objects.
To support this workflow, this commit adds a new field,
`non_mesh_items`, to `BinnedRenderPhase`. This field contains a simple
list of (bin key, entity) pairs. After drawing batchable and unbatchable
objects, the non-mesh items are drawn one after another. Bevy itself
doesn't enqueue any items into this list; it exists solely for the
application and/or plugins to use.
Additionally, this commit switches the asset ID in the standard bin keys
to be an untyped asset ID rather than that of a mesh. This allows more
flexibility, allowing bins to be keyed off any type of asset.
This patch adds a new example, `custom_phase_item`, which simultaneously
serves to demonstrate how to use this new feature and to act as a
regression test so this doesn't break again.
Fixes#14004.
## Changelog
### Added
* `BinnedRenderPhase` now contains a `non_mesh_items` field for plugins
to add custom items to.
# Objective
- Fixes#10909
- Fixes#8492
## Solution
- Name all matrices `x_from_y`, for example `world_from_view`.
## Testing
- I've tested most of the 3D examples. The `lighting` example
particularly should hit a lot of the changes and appears to run fine.
---
## Changelog
- Renamed matrices across the engine to follow a `y_from_x` naming,
making the space conversion more obvious.
## Migration Guide
- `Frustum`'s `from_view_projection`, `from_view_projection_custom_far`
and `from_view_projection_no_far` were renamed to
`from_clip_from_world`, `from_clip_from_world_custom_far` and
`from_clip_from_world_no_far`.
- `ComputedCameraValues::projection_matrix` was renamed to
`clip_from_view`.
- `CameraProjection::get_projection_matrix` was renamed to
`get_clip_from_view` (this affects implementations on `Projection`,
`PerspectiveProjection` and `OrthographicProjection`).
- `ViewRangefinder3d::from_view_matrix` was renamed to
`from_world_from_view`.
- `PreviousViewData`'s members were renamed to `view_from_world` and
`clip_from_world`.
- `ExtractedView`'s `projection`, `transform` and `view_projection` were
renamed to `clip_from_view`, `world_from_view` and `clip_from_world`.
- `ViewUniform`'s `view_proj`, `unjittered_view_proj`,
`inverse_view_proj`, `view`, `inverse_view`, `projection` and
`inverse_projection` were renamed to `clip_from_world`,
`unjittered_clip_from_world`, `world_from_clip`, `world_from_view`,
`view_from_world`, `clip_from_view` and `view_from_clip`.
- `GpuDirectionalCascade::view_projection` was renamed to
`clip_from_world`.
- `MeshTransforms`' `transform` and `previous_transform` were renamed to
`world_from_local` and `previous_world_from_local`.
- `MeshUniform`'s `transform`, `previous_transform`,
`inverse_transpose_model_a` and `inverse_transpose_model_b` were renamed
to `world_from_local`, `previous_world_from_local`,
`local_from_world_transpose_a` and `local_from_world_transpose_b` (the
`Mesh` type in WGSL mirrors this, however `transform` and
`previous_transform` were named `model` and `previous_model`).
- `Mesh2dTransforms::transform` was renamed to `world_from_local`.
- `Mesh2dUniform`'s `transform`, `inverse_transpose_model_a` and
`inverse_transpose_model_b` were renamed to `world_from_local`,
`local_from_world_transpose_a` and `local_from_world_transpose_b` (the
`Mesh2d` type in WGSL mirrors this).
- In WGSL, in `bevy_pbr::mesh_functions`, `get_model_matrix` and
`get_previous_model_matrix` were renamed to `get_world_from_local` and
`get_previous_world_from_local`.
- In WGSL, `bevy_sprite::mesh2d_functions::get_model_matrix` was renamed
to `get_world_from_local`.
This commit makes us stop using the render world ECS for
`BinnedRenderPhase` and `SortedRenderPhase` and instead use resources
with `EntityHashMap`s inside. There are three reasons to do this:
1. We can use `clear()` to clear out the render phase collections
instead of recreating the components from scratch, allowing us to reuse
allocations.
2. This is a prerequisite for retained bins, because components can't be
retained from frame to frame in the render world, but resources can.
3. We want to move away from storing anything in components in the
render world ECS, and this is a step in that direction.
This patch results in a small performance benefit, due to point (1)
above.
## Changelog
### Changed
* The `BinnedRenderPhase` and `SortedRenderPhase` render world
components have been replaced with `ViewBinnedRenderPhases` and
`ViewSortedRenderPhases` resources.
## Migration Guide
* The `BinnedRenderPhase` and `SortedRenderPhase` render world
components have been replaced with `ViewBinnedRenderPhases` and
`ViewSortedRenderPhases` resources. Instead of querying for the
components, look the camera entity up in the
`ViewBinnedRenderPhases`/`ViewSortedRenderPhases` tables.
This commit implements opt-in GPU frustum culling, built on top of the
infrastructure in https://github.com/bevyengine/bevy/pull/12773. To
enable it on a camera, add the `GpuCulling` component to it. To
additionally disable CPU frustum culling, add the `NoCpuCulling`
component. Note that adding `GpuCulling` without `NoCpuCulling`
*currently* does nothing useful. The reason why `GpuCulling` doesn't
automatically imply `NoCpuCulling` is that I intend to follow this patch
up with GPU two-phase occlusion culling, and CPU frustum culling plus
GPU occlusion culling seems like a very commonly-desired mode.
Adding the `GpuCulling` component to a view puts that view into
*indirect mode*. This mode makes all drawcalls indirect, relying on the
mesh preprocessing shader to allocate instances dynamically. In indirect
mode, the `PreprocessWorkItem` `output_index` points not to a
`MeshUniform` instance slot but instead to a set of `wgpu`
`IndirectParameters`, from which it allocates an instance slot
dynamically if frustum culling succeeds. Batch building has been updated
to allocate and track indirect parameter slots, and the AABBs are now
supplied to the GPU as `MeshCullingData`.
A small amount of code relating to the frustum culling has been borrowed
from meshlets and moved into `maths.wgsl`. Note that standard Bevy
frustum culling uses AABBs, while meshlets use bounding spheres; this
means that not as much code can be shared as one might think.
This patch doesn't provide any way to perform GPU culling on shadow
maps, to avoid making this patch bigger than it already is. That can be
a followup.
## Changelog
### Added
* Frustum culling can now optionally be done on the GPU. To enable it,
add the `GpuCulling` component to a camera.
* To disable CPU frustum culling, add `NoCpuCulling` to a camera. Note
that `GpuCulling` doesn't automatically imply `NoCpuCulling`.
Currently, `MeshUniform`s are rather large: 160 bytes. They're also
somewhat expensive to compute, because they involve taking the inverse
of a 3x4 matrix. Finally, if a mesh is present in multiple views, that
mesh will have a separate `MeshUniform` for each and every view, which
is wasteful.
This commit fixes these issues by introducing the concept of a *mesh
input uniform* and adding a *mesh uniform building* compute shader pass.
The `MeshInputUniform` is simply the minimum amount of data needed for
the GPU to compute the full `MeshUniform`. Most of this data is just the
transform and is therefore only 64 bytes. `MeshInputUniform`s are
computed during the *extraction* phase, much like skins are today, in
order to avoid needlessly copying transforms around on CPU. (In fact,
the render app has been changed to only store the translation of each
mesh; it no longer cares about any other part of the transform, which is
stored only on the GPU and the main world.) Before rendering, the
`build_mesh_uniforms` pass runs to expand the `MeshInputUniform`s to the
full `MeshUniform`.
The mesh uniform building pass does the following, all on GPU:
1. Copy the appropriate fields of the `MeshInputUniform` to the
`MeshUniform` slot. If a single mesh is present in multiple views, this
effectively duplicates it into each view.
2. Compute the inverse transpose of the model transform, used for
transforming normals.
3. If applicable, copy the mesh's transform from the previous frame for
TAA. To support this, we double-buffer the `MeshInputUniform`s over two
frames and swap the buffers each frame. The `MeshInputUniform`s for the
current frame contain the index of that mesh's `MeshInputUniform` for
the previous frame.
This commit produces wins in virtually every CPU part of the pipeline:
`extract_meshes`, `queue_material_meshes`,
`batch_and_prepare_render_phase`, and especially
`write_batched_instance_buffer` are all faster. Shrinking the amount of
CPU data that has to be shuffled around speeds up the entire rendering
process.
| Benchmark | This branch | `main` | Speedup |
|------------------------|-------------|---------|---------|
| `many_cubes -nfc` | 17.259 | 24.529 | 42.12% |
| `many_cubes -nfc -vpi` | 302.116 | 312.123 | 3.31% |
| `many_foxes` | 3.227 | 3.515 | 8.92% |
Because mesh uniform building requires compute shader, and WebGL 2 has
no compute shader, the existing CPU mesh uniform building code has been
left as-is. Many types now have both CPU mesh uniform building and GPU
mesh uniform building modes. Developers can opt into the old CPU mesh
uniform building by setting the `use_gpu_uniform_builder` option on
`PbrPlugin` to `false`.
Below are graphs of the CPU portions of `many-cubes
--no-frustum-culling`. Yellow is this branch, red is `main`.
`extract_meshes`:

It's notable that we get a small win even though we're now writing to a
GPU buffer.
`queue_material_meshes`:

There's a bit of a regression here; not sure what's causing it. In any
case it's very outweighed by the other gains.
`batch_and_prepare_render_phase`:

There's a huge win here, enough to make batching basically drop off the
profile.
`write_batched_instance_buffer`:

There's a massive improvement here, as expected. Note that a lot of it
simply comes from the fact that `MeshInputUniform` is `Pod`. (This isn't
a maintainability problem in my view because `MeshInputUniform` is so
simple: just 16 tightly-packed words.)
## Changelog
### Added
* Per-mesh instance data is now generated on GPU with a compute shader
instead of CPU, resulting in rendering performance improvements on
platforms where compute shaders are supported.
## Migration guide
* Custom render phases now need multiple systems beyond just
`batch_and_prepare_render_phase`. Code that was previously creating
custom render phases should now add a `BinnedRenderPhasePlugin` or
`SortedRenderPhasePlugin` as appropriate instead of directly adding
`batch_and_prepare_render_phase`.
# Objective
This is a necessary precursor to #9122 (this was split from that PR to
reduce the amount of code to review all at once).
Moving `!Send` resource ownership to `App` will make it unambiguously
`!Send`. `SubApp` must be `Send`, so it can't wrap `App`.
## Solution
Refactor `App` and `SubApp` to not have a recursive relationship. Since
`SubApp` no longer wraps `App`, once `!Send` resources are moved out of
`World` and into `App`, `SubApp` will become unambiguously `Send`.
There could be less code duplication between `App` and `SubApp`, but
that would break `App` method chaining.
## Changelog
- `SubApp` no longer wraps `App`.
- `App` fields are no longer publicly accessible.
- `App` can no longer be converted into a `SubApp`.
- Various methods now return references to a `SubApp` instead of an
`App`.
## Migration Guide
- To construct a sub-app, use `SubApp::new()`. `App` can no longer
convert into `SubApp`.
- If you implemented a trait for `App`, you may want to implement it for
`SubApp` as well.
- If you're accessing `app.world` directly, you now have to use
`app.world()` and `app.world_mut()`.
- `App::sub_app` now returns `&SubApp`.
- `App::sub_app_mut` now returns `&mut SubApp`.
- `App::get_sub_app` now returns `Option<&SubApp>.`
- `App::get_sub_app_mut` now returns `Option<&mut SubApp>.`
Today, we sort all entities added to all phases, even the phases that
don't strictly need sorting, such as the opaque and shadow phases. This
results in a performance loss because our `PhaseItem`s are rather large
in memory, so sorting is slow. Additionally, determining the boundaries
of batches is an O(n) process.
This commit makes Bevy instead applicable place phase items into *bins*
keyed by *bin keys*, which have the invariant that everything in the
same bin is potentially batchable. This makes determining batch
boundaries O(1), because everything in the same bin can be batched.
Instead of sorting each entity, we now sort only the bin keys. This
drops the sorting time to near-zero on workloads with few bins like
`many_cubes --no-frustum-culling`. Memory usage is improved too, with
batch boundaries and dynamic indices now implicit instead of explicit.
The improved memory usage results in a significant win even on
unbatchable workloads like `many_cubes --no-frustum-culling
--vary-material-data-per-instance`, presumably due to cache effects.
Not all phases can be binned; some, such as transparent and transmissive
phases, must still be sorted. To handle this, this commit splits
`PhaseItem` into `BinnedPhaseItem` and `SortedPhaseItem`. Most of the
logic that today deals with `PhaseItem`s has been moved to
`SortedPhaseItem`. `BinnedPhaseItem` has the new logic.
Frame time results (in ms/frame) are as follows:
| Benchmark | `binning` | `main` | Speedup |
| ------------------------ | --------- | ------- | ------- |
| `many_cubes -nfc -vpi` | 232.179 | 312.123 | 34.43% |
| `many_cubes -nfc` | 25.874 | 30.117 | 16.40% |
| `many_foxes` | 3.276 | 3.515 | 7.30% |
(`-nfc` is short for `--no-frustum-culling`; `-vpi` is short for
`--vary-per-instance`.)
---
## Changelog
### Changed
* Render phases have been split into binned and sorted phases. Binned
phases, such as the common opaque phase, achieve improved CPU
performance by avoiding the sorting step.
## Migration Guide
- `PhaseItem` has been split into `BinnedPhaseItem` and
`SortedPhaseItem`. If your code has custom `PhaseItem`s, you will need
to migrate them to one of these two types. `SortedPhaseItem` requires
the fewest code changes, but you may want to pick `BinnedPhaseItem` if
your phase doesn't require sorting, as that enables higher performance.
## Tracy graphs
`many-cubes --no-frustum-culling`, `main` branch:
<img width="1064" alt="Screenshot 2024-03-12 180037"
src="https://github.com/bevyengine/bevy/assets/157897/e1180ce8-8e89-46d2-85e3-f59f72109a55">
`many-cubes --no-frustum-culling`, this branch:
<img width="1064" alt="Screenshot 2024-03-12 180011"
src="https://github.com/bevyengine/bevy/assets/157897/0899f036-6075-44c5-a972-44d95895f46c">
You can see that `batch_and_prepare_binned_render_phase` is a much
smaller fraction of the time. Zooming in on that function, with yellow
being this branch and red being `main`, we see:
<img width="1064" alt="Screenshot 2024-03-12 175832"
src="https://github.com/bevyengine/bevy/assets/157897/0dfc8d3f-49f4-496e-8825-a66e64d356d0">
The binning happens in `queue_material_meshes`. Again with yellow being
this branch and red being `main`:
<img width="1064" alt="Screenshot 2024-03-12 175755"
src="https://github.com/bevyengine/bevy/assets/157897/b9b20dc1-11c8-400c-a6cc-1c2e09c1bb96">
We can see that there is a small regression in `queue_material_meshes`
performance, but it's not nearly enough to outweigh the large gains in
`batch_and_prepare_binned_render_phase`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
It's useful to have access to render pipeline statistics, since they
provide more information than FPS alone. For example, the number of
drawn triangles can be used to debug culling and LODs. The number of
fragment shader invocations can provide a more stable alternative metric
than GPU elapsed time.
See also: Render node GPU timing overlay #8067, which doesn't provide
pipeline statistics, but adds a nice overlay.
## Solution
Add `RenderDiagnosticsPlugin`, which enables collecting pipeline
statistics and CPU & GPU timings.
---
## Changelog
- Add `RenderDiagnosticsPlugin`
- Add `RenderContext::diagnostic_recorder` method
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Make bevy_utils less of a compilation bottleneck. Tackle #11478.
## Solution
* Move all of the directly reexported dependencies and move them to
where they're actually used.
* Remove the UUID utilities that have gone unused since `TypePath` took
over for `TypeUuid`.
* There was also a extraneous bytemuck dependency on `bevy_core` that
has not been used for a long time (since `encase` became the primary way
to prepare GPU buffers).
* Remove the `all_tuples` macro reexport from bevy_ecs since it's
accessible from `bevy_utils`.
---
## Changelog
Removed: Many of the reexports from bevy_utils (petgraph, uuid, nonmax,
smallvec, and thiserror).
Removed: bevy_core's reexports of bytemuck.
## Migration Guide
bevy_utils' reexports of petgraph, uuid, nonmax, smallvec, and thiserror
have been removed.
bevy_core' reexports of bytemuck's types has been removed.
Add them as dependencies in your own crate instead.
# Objective
- We should move towards a consistent use of the new `bevy_color` crate.
- As discussed in #12089, splitting this work up into small pieces makes
it easier to review.
## Solution
- Port all uses of `LegacyColor` in the `bevy_core_pipeline` to
`LinearRgba`
- `LinearRgba` is the correct type to use for internal rendering types
- Added `LinearRgba::BLACK` and `WHITE` (used during migration)
- Add `LinearRgba::grey` to more easily construct balanced grey colors
(used during migration)
- Add a conversion from `LinearRgba` to `wgpu::Color`. The converse was
not done at this time, as this is typically a user error.
I did not change the field type of the clear color on the cameras: as
this is user-facing, this should be done in concert with the other
configurable fields.
## Migration Guide
`ColorAttachment` now stores a `LinearRgba` color, rather than a Bevy
0.13 `Color`.
`set_blend_constant` now takes a `LinearRgba` argument, rather than a
Bevy 0.13 `Color`.
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
# Objective
The migration process for `bevy_color` (#12013) will be fairly involved:
there will be hundreds of affected files, and a large number of APIs.
## Solution
To allow us to proceed granularly, we're going to keep both
`bevy_color::Color` (new) and `bevy_render::Color` (old) around until
the migration is complete.
However, simply doing this directly is confusing! They're both called
`Color`, making it very hard to tell when a portion of the code has been
ported.
As discussed in #12056, by renaming the old `Color` type, we can make it
easier to gradually migrate over, one API at a time.
## Migration Guide
THIS MIGRATION GUIDE INTENTIONALLY LEFT BLANK.
This change should not be shipped to end users: delete this section in
the final migration guide!
---------
Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com>
This fixes a `FIXME` in `extract_meshes` and results in a performance
improvement.
As a result of this change, meshes in the render world might not be
attached to entities anymore. Therefore, the `entity` parameter to
`RenderCommand::render()` is now wrapped in an `Option`. Most
applications that use the render app's ECS can simply unwrap the
`Option`.
Note that for now sprites, gizmos, and UI elements still use the render
world as usual.
## Migration guide
* For efficiency reasons, some meshes in the render world may not have
corresponding `Entity` IDs anymore. As a result, the `entity` parameter
to `RenderCommand::render()` is now wrapped in an `Option`. Custom
rendering code may need to be updated to handle the case in which no
`Entity` exists for an object that is to be rendered.
Use `TypeIdMap<T>` instead of `HashMap<TypeId, T>`
- ~~`TypeIdMap` was in `bevy_ecs`. I've kept it there because of
#11478~~
- ~~I haven't swapped `bevy_reflect` over because it doesn't depend on
`bevy_ecs`, but I'd also be happy with moving `TypeIdMap` to
`bevy_utils` and then adding a dependency to that~~
- ~~this is a slight change in the public API of
`DrawFunctionsInternal`, does this need to go in the changelog?~~
## Changelog
- moved `TypeIdMap` to `bevy_utils`
- changed `DrawFunctionsInternal::indices` to `TypeIdMap`
## Migration Guide
- `TypeIdMap` now lives in `bevy_utils`
- `DrawFunctionsInternal::indices` now uses a `TypeIdMap`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
> Can anyone explain to me the reasoning of renaming all the types named
Query to Data. I'm talking about this PR
https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to
me that a bunch of types that are used to run queries aren't named Query
anymore. Like ViewQuery on the ViewNode is the type of the Query. I
don't really understand the point of the rename, it just seems like it
hides the fact that a query will run based on those types.
[@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387)
## Solution
Revert several renames in #10779.
## Changelog
- `ViewNode::ViewData` is now `ViewNode::ViewQuery` again.
## Migration Guide
- This PR amends the migration guide in
https://github.com/bevyengine/bevy/pull/10779
---------
Co-authored-by: atlas dostal <rodol@rivalrebels.com>
# Objective
There are a lot of doctests that are `ignore`d for no documented reason.
And that should be fixed.
## Solution
I searched the bevy repo with the regex ` ```[a-z,]*ignore ` in order to
find all `ignore`d doctests. For each one of the `ignore`d doctests, I
did the following steps:
1. Attempt to remove the `ignored` attribute while still passing the
test. I did this by adding hidden dummy structs and imports.
2. If step 1 doesn't work, attempt to replace the `ignored` attribute
with the `no_run` attribute while still passing the test.
3. If step 2 doesn't work, keep the `ignored` attribute but add
documentation for why the `ignored` attribute was added.
---------
Co-authored-by: François <mockersf@gmail.com>