de004da8d5
54 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
de004da8d5
|
Rename bevy_render::Color to LegacyColor (#12069)
# Objective The migration process for `bevy_color` (#12013) will be fairly involved: there will be hundreds of affected files, and a large number of APIs. ## Solution To allow us to proceed granularly, we're going to keep both `bevy_color::Color` (new) and `bevy_render::Color` (old) around until the migration is complete. However, simply doing this directly is confusing! They're both called `Color`, making it very hard to tell when a portion of the code has been ported. As discussed in #12056, by renaming the old `Color` type, we can make it easier to gradually migrate over, one API at a time. ## Migration Guide THIS MIGRATION GUIDE INTENTIONALLY LEFT BLANK. This change should not be shipped to end users: delete this section in the final migration guide! --------- Co-authored-by: Alice Cecile <alice.i.cecil@gmail.com> |
||
|
|
3af8526786
|
Stop extracting mesh entities to the render world. (#11803)
This fixes a `FIXME` in `extract_meshes` and results in a performance improvement. As a result of this change, meshes in the render world might not be attached to entities anymore. Therefore, the `entity` parameter to `RenderCommand::render()` is now wrapped in an `Option`. Most applications that use the render app's ECS can simply unwrap the `Option`. Note that for now sprites, gizmos, and UI elements still use the render world as usual. ## Migration guide * For efficiency reasons, some meshes in the render world may not have corresponding `Entity` IDs anymore. As a result, the `entity` parameter to `RenderCommand::render()` is now wrapped in an `Option`. Custom rendering code may need to be updated to handle the case in which no `Entity` exists for an object that is to be rendered. |
||
|
|
21aa5fe2b6
|
Use TypeIdMap whenever possible (#11684)
Use `TypeIdMap<T>` instead of `HashMap<TypeId, T>` - ~~`TypeIdMap` was in `bevy_ecs`. I've kept it there because of #11478~~ - ~~I haven't swapped `bevy_reflect` over because it doesn't depend on `bevy_ecs`, but I'd also be happy with moving `TypeIdMap` to `bevy_utils` and then adding a dependency to that~~ - ~~this is a slight change in the public API of `DrawFunctionsInternal`, does this need to go in the changelog?~~ ## Changelog - moved `TypeIdMap` to `bevy_utils` - changed `DrawFunctionsInternal::indices` to `TypeIdMap` ## Migration Guide - `TypeIdMap` now lives in `bevy_utils` - `DrawFunctionsInternal::indices` now uses a `TypeIdMap`. --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
eb07d16871
|
Revert rendering-related associated type name changes (#11027)
# Objective > Can anyone explain to me the reasoning of renaming all the types named Query to Data. I'm talking about this PR https://github.com/bevyengine/bevy/pull/10779 It doesn't make sense to me that a bunch of types that are used to run queries aren't named Query anymore. Like ViewQuery on the ViewNode is the type of the Query. I don't really understand the point of the rename, it just seems like it hides the fact that a query will run based on those types. [@IceSentry](https://discord.com/channels/691052431525675048/692572690833473578/1184946251431694387) ## Solution Revert several renames in #10779. ## Changelog - `ViewNode::ViewData` is now `ViewNode::ViewQuery` again. ## Migration Guide - This PR amends the migration guide in https://github.com/bevyengine/bevy/pull/10779 --------- Co-authored-by: atlas dostal <rodol@rivalrebels.com> |
||
|
|
189ceaf0d3
|
Replace or document ignored doctests (#11040)
# Objective There are a lot of doctests that are `ignore`d for no documented reason. And that should be fixed. ## Solution I searched the bevy repo with the regex ` ```[a-z,]*ignore ` in order to find all `ignore`d doctests. For each one of the `ignore`d doctests, I did the following steps: 1. Attempt to remove the `ignored` attribute while still passing the test. I did this by adding hidden dummy structs and imports. 2. If step 1 doesn't work, attempt to replace the `ignored` attribute with the `no_run` attribute while still passing the test. 3. If step 2 doesn't work, keep the `ignored` attribute but add documentation for why the `ignored` attribute was added. --------- Co-authored-by: François <mockersf@gmail.com> |
||
|
|
5af2f022d8
|
Rename WorldQueryData & WorldQueryFilter to QueryData & QueryFilter (#10779)
# Rename `WorldQueryData` & `WorldQueryFilter` to `QueryData` & `QueryFilter` Fixes #10776 ## Solution Traits `WorldQueryData` & `WorldQueryFilter` were renamed to `QueryData` and `QueryFilter`, respectively. Related Trait types were also renamed. --- ## Changelog - Trait `WorldQueryData` has been renamed to `QueryData`. Derive macro's `QueryData` attribute `world_query_data` has been renamed to `query_data`. - Trait `WorldQueryFilter` has been renamed to `QueryFilter`. Derive macro's `QueryFilter` attribute `world_query_filter` has been renamed to `query_filter`. - Trait's `ExtractComponent` type `Query` has been renamed to `Data`. - Trait's `GetBatchData` types `Query` & `QueryFilter` has been renamed to `Data` & `Filter`, respectively. - Trait's `ExtractInstance` type `Query` has been renamed to `Data`. - Trait's `ViewNode` type `ViewQuery` has been renamed to `ViewData`. - Trait's `RenderCommand` types `ViewWorldQuery` & `ItemWorldQuery` has been renamed to `ViewData` & `ItemData`, respectively. ## Migration Guide Note: if merged before 0.13 is released, this should instead modify the migration guide of #10776 with the updated names. - Rename `WorldQueryData` & `WorldQueryFilter` trait usages to `QueryData` & `QueryFilter` and their respective derive macro attributes `world_query_data` & `world_query_filter` to `query_data` & `query_filter`. - Rename the following trait type usages: - Trait's `ExtractComponent` type `Query` to `Data`. - Trait's `GetBatchData` type `Query` to `Data`. - Trait's `ExtractInstance` type `Query` to `Data`. - Trait's `ViewNode` type `ViewQuery` to `ViewData`' - Trait's `RenderCommand` types `ViewWolrdQuery` & `ItemWorldQuery` to `ViewData` & `ItemData`, respectively. ```rust // Before #[derive(WorldQueryData)] #[world_query_data(derive(Debug))] struct EmptyQuery { empty: (), } // After #[derive(QueryData)] #[query_data(derive(Debug))] struct EmptyQuery { empty: (), } // Before #[derive(WorldQueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // After #[derive(QueryFilter)] struct CustomQueryFilter<T: Component, P: Component> { _c: With<ComponentC>, _d: With<ComponentD>, _or: Or<(Added<ComponentC>, Changed<ComponentD>, Without<ComponentZ>)>, _generic_tuple: (With<T>, With<P>), } // Before impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Query = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Query>) -> Option<Self::Out> { //... } } // After impl ExtractComponent for ContrastAdaptiveSharpeningSettings { type Data = &'static Self; type Filter = With<Camera>; type Out = (DenoiseCAS, CASUniform); fn extract_component(item: QueryItem<Self::Data>) -> Option<Self::Out> { //... } } // Before impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Query = Entity; type QueryFilter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Query>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // After impl GetBatchData for MeshPipeline { type Param = SRes<RenderMeshInstances>; type Data = Entity; type Filter = With<Mesh3d>; type CompareData = (MaterialBindGroupId, AssetId<Mesh>); type BufferData = MeshUniform; fn get_batch_data( mesh_instances: &SystemParamItem<Self::Param>, entity: &QueryItem<Self::Data>, ) -> (Self::BufferData, Option<Self::CompareData>) { // .... } } // Before impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Query = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Query>) -> Option<Self> { Some(item.id()) } } // After impl<A> ExtractInstance for AssetId<A> where A: Asset, { type Data = Read<Handle<A>>; type Filter = (); fn extract(item: QueryItem<'_, Self::Data>) -> Option<Self> { Some(item.id()) } } // Before impl ViewNode for PostProcessNode { type ViewQuery = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewQuery>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // After impl ViewNode for PostProcessNode { type ViewData = ( &'static ViewTarget, &'static PostProcessSettings, ); fn run( &self, _graph: &mut RenderGraphContext, render_context: &mut RenderContext, (view_target, _post_process_settings): QueryItem<Self::ViewData>, world: &World, ) -> Result<(), NodeRunError> { // ... } } // Before impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewWorldQuery = (); type ItemWorldQuery = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } // After impl<P: CachedRenderPipelinePhaseItem> RenderCommand<P> for SetItemPipeline { type Param = SRes<PipelineCache>; type ViewData = (); type ItemData = (); #[inline] fn render<'w>( item: &P, _view: (), _entity: (), pipeline_cache: SystemParamItem<'w, '_, Self::Param>, pass: &mut TrackedRenderPass<'w>, ) -> RenderCommandResult { // ... } } ``` |
||
|
|
f0a8994f55
|
Split WorldQuery into WorldQueryData and WorldQueryFilter (#9918)
# Objective - Fixes #7680 - This is an updated for https://github.com/bevyengine/bevy/pull/8899 which had the same objective but fell a long way behind the latest changes ## Solution The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter : WorldQuery` have been added and some of the types and functions from `WorldQuery` has been moved into them. `ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`. `WorldQueryFilter` is safe (as long as `WorldQuery` is implemented safely). `WorldQueryData` is unsafe - safely implementing it requires that `Self::ReadOnly` is a readonly version of `Self` (this used to be a safety requirement of `WorldQuery`) The type parameters `Q` and `F` of `Query` must now implement `WorldQueryData` and `WorldQueryFilter` respectively. This makes it impossible to accidentally use a filter in the data position or vice versa which was something that could lead to bugs. ~~Compile failure tests have been added to check this.~~ It was previously sometimes useful to use `Option<With<T>>` in the data position. Use `Has<T>` instead in these cases. The `WorldQuery` derive macro has been split into separate derive macros for `WorldQueryData` and `WorldQueryFilter`. Previously it was possible to derive both `WorldQuery` for a struct that had a mixture of data and filter items. This would not work correctly in some cases but could be a useful pattern in others. *This is no longer possible.* --- ## Notes - The changes outside of `bevy_ecs` are all changing type parameters to the new types, updating the macro use, or replacing `Option<With<T>>` with `Has<T>`. - All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL` so I moved it to `WorldQueryFilter` and replaced all calls to it with `true`. That should be the only logic change outside of the macro generation code. - `Changed<T>` and `Added<T>` were being generated by a macro that I have expanded. Happy to revert that if desired. - The two derive macros share some functions for implementing `WorldQuery` but the tidiest way I could find to implement them was to give them a ton of arguments and ask clippy to ignore that. ## Changelog ### Changed - Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which now have separate derive macros. It is not possible to derive both for the same type. - `Query` now requires that the first type argument implements `WorldQueryData` and the second implements `WorldQueryFilter` ## Migration Guide - Update derives ```rust // old #[derive(WorldQuery)] #[world_query(mutable, derive(Debug))] struct CustomQuery { entity: Entity, a: &'static mut ComponentA } #[derive(WorldQuery)] struct QueryFilter { _c: With<ComponentC> } // new #[derive(WorldQueryData)] #[world_query_data(mutable, derive(Debug))] struct CustomQuery { entity: Entity, a: &'static mut ComponentA, } #[derive(WorldQueryFilter)] struct QueryFilter { _c: With<ComponentC> } ``` - Replace `Option<With<T>>` with `Has<T>` ```rust /// old fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>) { for (entity, has_a_option) in query.iter(){ let has_a:bool = has_a_option.is_some(); //todo!() } } /// new fn my_system(query: Query<(Entity, Has<ComponentA>)>) { for (entity, has_a) in query.iter(){ //todo!() } } ``` - Fix queries which had filters in the data position or vice versa. ```rust // old fn my_system(query: Query<(Entity, With<ComponentA>)>) { for (entity, _) in query.iter(){ //todo!() } } // new fn my_system(query: Query<Entity, With<ComponentA>>) { for entity in query.iter(){ //todo!() } } // old fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>) { for (entity, _) in query.iter(){ //todo!() } } // new fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>) { for entity in query.iter(){ //todo!() } } ``` --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> |
||
|
|
4eafd60ce9
|
Add wgpu_pass method to TrackedRenderPass (#10722)
# Objective - Fixes #10707 ## Solution - Add a method to obtain `RenderPass` to `TrackedRenderPass` simillar to `RenderDevice::wgpu_device` --- ## Changelog Added `wgpu_pass` method to `TrackedRenderPass` |
||
|
|
44928e0df4
|
StandardMaterial Light Transmission (#8015)
# Objective
<img width="1920" alt="Screenshot 2023-04-26 at 01 07 34"
src="https://user-images.githubusercontent.com/418473/234467578-0f34187b-5863-4ea1-88e9-7a6bb8ce8da3.png">
This PR adds both diffuse and specular light transmission capabilities
to the `StandardMaterial`, with support for screen space refractions.
This enables realistically representing a wide range of real-world
materials, such as:
- Glass; (Including frosted glass)
- Transparent and translucent plastics;
- Various liquids and gels;
- Gemstones;
- Marble;
- Wax;
- Paper;
- Leaves;
- Porcelain.
Unlike existing support for transparency, light transmission does not
rely on fixed function alpha blending, and therefore works with both
`AlphaMode::Opaque` and `AlphaMode::Mask` materials.
## Solution
- Introduces a number of transmission related fields in the
`StandardMaterial`;
- For specular transmission:
- Adds logic to take a view main texture snapshot after the opaque
phase; (in order to perform screen space refractions)
- Introduces a new `Transmissive3d` phase to the renderer, to which all
meshes with `transmission > 0.0` materials are sent.
- Calculates a light exit point (of the approximate mesh volume) using
`ior` and `thickness` properties
- Samples the snapshot texture with an adaptive number of taps across a
`roughness`-controlled radius enabling “blurry” refractions
- For diffuse transmission:
- Approximates transmitted diffuse light by using a second, flipped +
displaced, diffuse-only Lambertian lobe for each light source.
## To Do
- [x] Figure out where `fresnel_mix()` is taking place, if at all, and
where `dielectric_specular` is being calculated, if at all, and update
them to use the `ior` value (Not a blocker, just a nice-to-have for more
correct BSDF)
- To the _best of my knowledge, this is now taking place, after
|
||
|
|
450328d15e
|
Replaced parking_lot with std::sync (#9545)
# Objective - Fixes #4610 ## Solution - Replaced all instances of `parking_lot` locks with equivalents from `std::sync`. Acquiring locks within `std::sync` can fail, so `.expect("Lock Poisoned")` statements were added where required. ## Comments In [this comment](https://github.com/bevyengine/bevy/issues/4610#issuecomment-1592407881), the lack of deadlock detection was mentioned as a potential reason to not make this change. From what I can gather, Bevy doesn't appear to be using this functionality within the engine. Unless it was expected that a Bevy consumer was expected to enable and use this functionality, it appears to be a feature lost without consequence. Unfortunately, `cpal` and `wgpu` both still rely on `parking_lot`, leaving it in the dependency graph even after this change. From my basic experimentation, this change doesn't appear to have any performance impacts, positive or negative. I tested this using `bevymark` with 50,000 entities and observed 20ms of frame-time before and after the change. More extensive testing with larger/real projects should probably be done. |
||
|
|
5c884c5a15
|
Automatic batching/instancing of draw commands (#9685)
# Objective - Implement the foundations of automatic batching/instancing of draw commands as the next step from #89 - NOTE: More performance improvements will come when more data is managed and bound in ways that do not require rebinding such as mesh, material, and texture data. ## Solution - The core idea for batching of draw commands is to check whether any of the information that has to be passed when encoding a draw command changes between two things that are being drawn according to the sorted render phase order. These should be things like the pipeline, bind groups and their dynamic offsets, index/vertex buffers, and so on. - The following assumptions have been made: - Only entities with prepared assets (pipelines, materials, meshes) are queued to phases - View bindings are constant across a phase for a given draw function as phases are per-view - `batch_and_prepare_render_phase` is the only system that performs this batching and has sole responsibility for preparing the per-object data. As such the mesh binding and dynamic offsets are assumed to only vary as a result of the `batch_and_prepare_render_phase` system, e.g. due to having to split data across separate uniform bindings within the same buffer due to the maximum uniform buffer binding size. - Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform in arrays in GPU buffers rather than each one being at a dynamic offset in a uniform buffer. This is the same optimisation that was made for 3D not long ago. - Change batch size for a range in `PhaseItem`, adding API for getting or mutating the range. This is more flexible than a size as the length of the range can be used in place of the size, but the start and end can be otherwise whatever is needed. - Add an optional mesh bind group dynamic offset to `PhaseItem`. This avoids having to do a massive table move just to insert `GpuArrayBufferIndex` components. ## Benchmarks All tests have been run on an M1 Max on AC power. `bevymark` and `many_cubes` were modified to use 1920x1080 with a scale factor of 1. I run a script that runs a separate Tracy capture process, and then runs the bevy example with `--features bevy_ci_testing,trace_tracy` and `CI_TESTING_CONFIG=../benchmark.ron` with the contents of `../benchmark.ron`: ```rust ( exit_after: Some(1500) ) ``` ...in order to run each test for 1500 frames. The recent changes to `many_cubes` and `bevymark` added reproducible random number generation so that with the same settings, the same rng will occur. They also added benchmark modes that use a fixed delta time for animations. Combined this means that the same frames should be rendered both on main and on the branch. The graphs compare main (yellow) to this PR (red). ### 3D Mesh `many_cubes --benchmark` <img width="1411" alt="Screenshot 2023-09-03 at 23 42 10" src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4"> The mesh and material are the same for all instances. This is basically the best case for the initial batching implementation as it results in 1 draw for the ~11.7k visible meshes. It gives a ~30% reduction in median frame time. The 1000th frame is identical using the flip tool:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4615 seconds ``` ### 3D Mesh `many_cubes --benchmark --material-texture-count 10` <img width="1404" alt="Screenshot 2023-09-03 at 23 45 18" src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf"> This run uses 10 different materials by varying their textures. The materials are randomly selected, and there is no sorting by material bind group for opaque 3D so any batching is 'random'. The PR produces a ~5% reduction in median frame time. If we were to sort the opaque phase by the material bind group, then this should be a lot faster. This produces about 10.5k draws for the 11.7k visible entities. This makes sense as randomly selecting from 10 materials gives a chance that two adjacent entities randomly select the same material and can be batched. The 1000th frame is identical in flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4537 seconds ``` ### 3D Mesh `many_cubes --benchmark --vary-per-instance` <img width="1394" alt="Screenshot 2023-09-03 at 23 48 44" src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f"> This run varies the material data per instance by randomly-generating its colour. This is the worst case for batching and that it performs about the same as `main` is a good thing as it demonstrates that the batching has minimal overhead when dealing with ~11k visible mesh entities. The 1000th frame is identical according to flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4568 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d` <img width="1412" alt="Screenshot 2023-09-03 at 23 59 56" src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4"> This spawns 160 waves of 1000 quad meshes that are shaded with ColorMaterial. Each wave has a different material so 160 waves currently should result in 160 batches. This results in a 50% reduction in median frame time. Capturing a screenshot of the 1000th frame main vs PR gives:  ``` Mean: 0.001222 Weighted median: 0.750432 1st weighted quartile: 0.453494 3rd weighted quartile: 0.969758 Min: 0.000000 Max: 0.990296 Evaluation time: 0.4255 seconds ``` So they seem to produce the same results. I also double-checked the number of draws. `main` does 160000 draws, and the PR does 160, as expected. ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --material-texture-count 10` <img width="1392" alt="Screenshot 2023-09-04 at 00 09 22" src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c"> This generates 10 textures and generates materials for each of those and then selects one material per wave. The median frame time is reduced by 50%. Similar to the plain run above, this produces 160 draws on the PR and 160000 on `main` and the 1000th frame is identical (ignoring the fps counter text overlay).  ``` Mean: 0.002877 Weighted median: 0.964980 1st weighted quartile: 0.668871 3rd weighted quartile: 0.982749 Min: 0.000000 Max: 0.992377 Evaluation time: 0.4301 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --vary-per-instance` <img width="1396" alt="Screenshot 2023-09-04 at 00 13 53" src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb"> This creates unique materials per instance by randomly-generating the material's colour. This is the worst case for 2D batching. Somehow, this PR manages a 7% reduction in median frame time. Both main and this PR issue 160000 draws. The 1000th frame is the same:  ``` Mean: 0.001214 Weighted median: 0.937499 1st weighted quartile: 0.635467 3rd weighted quartile: 0.979085 Min: 0.000000 Max: 0.988971 Evaluation time: 0.4462 seconds ``` ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite` <img width="1396" alt="Screenshot 2023-09-04 at 12 21 12" src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43"> This just spawns 160 waves of 1000 sprites. There should be and is no notable difference between main and the PR. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --material-texture-count 10` <img width="1389" alt="Screenshot 2023-09-04 at 12 36 08" src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413"> This spawns the sprites selecting a texture at random per instance from the 10 generated textures. This has no significant change vs main and shouldn't. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --vary-per-instance` <img width="1401" alt="Screenshot 2023-09-04 at 12 29 52" src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6"> This sets the sprite colour as being unique per instance. This can still all be drawn using one batch. There should be no difference but the PR produces median frame times that are 4% higher. Investigation showed no clear sources of cost, rather a mix of give and take that should not happen. It seems like noise in the results. ### Summary | Benchmark | % change in median frame time | | ------------- | ------------- | | many_cubes | 🟩 -30% | | many_cubes 10 materials | 🟩 -5% | | many_cubes unique materials | 🟩 ~0% | | bevymark mesh2d | 🟩 -50% | | bevymark mesh2d 10 materials | 🟩 -50% | | bevymark mesh2d unique materials | 🟩 -7% | | bevymark sprite | 🟥 2% | | bevymark sprite 10 materials | 🟥 0.6% | | bevymark sprite unique materials | 🟥 4.1% | --- ## Changelog - Added: 2D and 3D mesh entities that share the same mesh and material (same textures, same data) are now batched into the same draw command for better performance. --------- Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> Co-authored-by: Nicola Papale <nico@nicopap.ch> |
||
|
|
4f1d9a6315
|
Reorder render sets, refactor bevy_sprite to take advantage (#9236)
This is a continuation of this PR: #8062 # Objective - Reorder render schedule sets to allow data preparation when phase item order is known to support improved batching - Part of the batching/instancing etc plan from here: https://github.com/bevyengine/bevy/issues/89#issuecomment-1379249074 - The original idea came from @inodentry and proved to be a good one. Thanks! - Refactor `bevy_sprite` and `bevy_ui` to take advantage of the new ordering ## Solution - Move `Prepare` and `PrepareFlush` after `PhaseSortFlush` - Add a `PrepareAssets` set that runs in parallel with other systems and sets in the render schedule. - Put prepare_assets systems in the `PrepareAssets` set - If explicit dependencies are needed on Mesh or Material RenderAssets then depend on the appropriate system. - Add `ManageViews` and `ManageViewsFlush` sets between `ExtractCommands` and Queue - Move `queue_mesh*_bind_group` to the Prepare stage - Rename them to `prepare_` - Put systems that prepare resources (buffers, textures, etc.) into a `PrepareResources` set inside `Prepare` - Put the `prepare_..._bind_group` systems into a `PrepareBindGroup` set after `PrepareResources` - Move `prepare_lights` to the `ManageViews` set - `prepare_lights` creates views and this must happen before `Queue` - This system needs refactoring to stop handling all responsibilities - Gather lights, sort, and create shadow map views. Store sorted light entities in a resource - Remove `BatchedPhaseItem` - Replace `batch_range` with `batch_size` representing how many items to skip after rendering the item or to skip the item entirely if `batch_size` is 0. - `queue_sprites` has been split into `queue_sprites` for queueing phase items and `prepare_sprites` for batching after the `PhaseSort` - `PhaseItem`s are still inserted in `queue_sprites` - After sorting adjacent compatible sprite phase items are accumulated into `SpriteBatch` components on the first entity of each batch, containing a range of vertex indices. The associated `PhaseItem`'s `batch_size` is updated appropriately. - `SpriteBatch` items are then drawn skipping over the other items in the batch based on the value in `batch_size` - A very similar refactor was performed on `bevy_ui` --- ## Changelog Changed: - Reordered and reworked render app schedule sets. The main change is that data is extracted, queued, sorted, and then prepared when the order of data is known. - Refactor `bevy_sprite` and `bevy_ui` to take advantage of the reordering. ## Migration Guide - Assets such as materials and meshes should now be created in `PrepareAssets` e.g. `prepare_assets<Mesh>` - Queueing entities to `RenderPhase`s continues to be done in `Queue` e.g. `queue_sprites` - Preparing resources (textures, buffers, etc.) should now be done in `PrepareResources`, e.g. `prepare_prepass_textures`, `prepare_mesh_uniforms` - Prepare bind groups should now be done in `PrepareBindGroups` e.g. `prepare_mesh_bind_group` - Any batching or instancing can now be done in `Prepare` where the order of the phase items is known e.g. `prepare_sprites` ## Next Steps - Introduce some generic mechanism to ensure items that can be batched are grouped in the phase item order, currently you could easily have `[sprite at z 0, mesh at z 0, sprite at z 0]` preventing batching. - Investigate improved orderings for building the MeshUniform buffer - Implementing batching across the rest of bevy --------- Co-authored-by: Robert Swain <robert.swain@gmail.com> Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> |
||
|
|
0a11af9375
|
Reduce the size of MeshUniform to improve performance (#9416)
# Objective - Significantly reduce the size of MeshUniform by only including necessary data. ## Solution Local to world, model transforms are affine. This means they only need a 4x3 matrix to represent them. `MeshUniform` stores the current, and previous model transforms, and the inverse transpose of the current model transform, all as 4x4 matrices. Instead we can store the current, and previous model transforms as 4x3 matrices, and we only need the upper-left 3x3 part of the inverse transpose of the current model transform. This change allows us to reduce the serialized MeshUniform size from 208 bytes to 144 bytes, which is over a 30% saving in data to serialize, and VRAM bandwidth and space. ## Benchmarks On an M1 Max, running `many_cubes -- sphere`, main is in yellow, this PR is in red: <img width="1484" alt="Screenshot 2023-08-11 at 02 36 43" src="https://github.com/bevyengine/bevy/assets/302146/7d99c7b3-f2bb-4004-a8d0-4c00f755cb0d"> A reduction in frame time of ~14%. --- ## Changelog - Changed: Redefined `MeshUniform` to improve performance by using 4x3 affine transforms and reconstructing 4x4 matrices in the shader. Helper functions were added to `bevy_pbr::mesh_functions` to unpack the data. `affine_to_square` converts the packed 4x3 in 3x4 matrix data to a 4x4 matrix. `mat2x4_f32_to_mat3x3` converts the 3x3 in mat2x4 + f32 matrix data back into a 3x3. ## Migration Guide Shader code before: ``` var model = mesh[instance_index].model; ``` Shader code after: ``` #import bevy_pbr::mesh_functions affine_to_square var model = affine_to_square(mesh[instance_index].model); ``` |
||
|
|
292e069bb5
|
Apply codebase changes in preparation for StandardMaterial transmission (#8704)
# Objective - Make #8015 easier to review; ## Solution - This commit contains changes not directly related to transmission required by #8015, in easier-to-review, one-change-per-commit form. --- ## Changelog ### Fixed - Clear motion vector prepass using `0.0` instead of `1.0`, to avoid TAA artifacts on transparent objects against the background; ### Added - The `E` mathematical constant is now available for use in shaders, exposed under `bevy_pbr::utils`; - A new `TAA` shader def is now available, for conditionally enabling shader logic via `#ifdef` when TAA is enabled; (e.g. for jittering texture samples) - A new `FallbackImageZero` resource is introduced, for when a fallback image filled with zeroes is required; - A new `RenderPhase<I>::render_range()` method is introduced, for render phases that need to render their items in multiple parceled out “steps”; ### Changed - The `MainTargetTextures` struct now holds both `Texture` and `TextureViews` for the main textures; - The fog shader functions under `bevy_pbr::fog` now take the a `Fog` structure as their first argument, instead of relying on the global `fog` uniform; - The main textures can now be used as copy sources; ## Migration Guide - `ViewTarget::main_texture()` and `ViewTarget::main_texture_other()` now return `&Texture` instead of `&TextureView`. If you were relying on these methods, replace your usage with `ViewTarget::main_texture_view()`and `ViewTarget::main_texture_other_view()`, respectively; - `ViewTarget::sampled_main_texture()` now returns `Option<&Texture>` instead of a `Option<&TextureView>`. If you were relying on this method, replace your usage with `ViewTarget::sampled_main_texture_view()`; - The `apply_fog()`, `linear_fog()`, `exponential_fog()`, `exponential_squared_fog()` and `atmospheric_fog()` functions now take a configurable `Fog` struct. If you were relying on them, update your usage by adding the global `fog` uniform as their first argument; |
||
|
|
71842c5ac9
|
Webgpu support (#8336)
# Objective - Support WebGPU - alternative to #5027 that doesn't need any async / await - fixes #8315 - Surprise fix #7318 ## Solution ### For async renderer initialisation - Update the plugin lifecycle: - app builds the plugin - calls `plugin.build` - registers the plugin - app starts the event loop - event loop waits for `ready` of all registered plugins in the same order - returns `true` by default - then call all `finish` then all `cleanup` in the same order as registered - then execute the schedule In the case of the renderer, to avoid anything async: - building the renderer plugin creates a detached task that will send back the initialised renderer through a mutex in a resource - `ready` will wait for the renderer to be present in the resource - `finish` will take that renderer and place it in the expected resources by other plugins - other plugins (that expect the renderer to be available) `finish` are called and they are able to set up their pipelines - `cleanup` is called, only custom one is still for pipeline rendering ### For WebGPU support - update the `build-wasm-example` script to support passing `--api webgpu` that will build the example with WebGPU support - feature for webgl2 was always enabled when building for wasm. it's now in the default feature list and enabled on all platforms, so check for this feature must also check that the target_arch is `wasm32` --- ## Migration Guide - `Plugin::setup` has been renamed `Plugin::cleanup` - `Plugin::finish` has been added, and plugins adding pipelines should do it in this function instead of `Plugin::build` ```rust // Before impl Plugin for MyPlugin { fn build(&self, app: &mut App) { app.insert_resource::<MyResource> .add_systems(Update, my_system); let render_app = match app.get_sub_app_mut(RenderApp) { Ok(render_app) => render_app, Err(_) => return, }; render_app .init_resource::<RenderResourceNeedingDevice>() .init_resource::<OtherRenderResource>(); } } // After impl Plugin for MyPlugin { fn build(&self, app: &mut App) { app.insert_resource::<MyResource> .add_systems(Update, my_system); let render_app = match app.get_sub_app_mut(RenderApp) { Ok(render_app) => render_app, Err(_) => return, }; render_app .init_resource::<OtherRenderResource>(); } fn finish(&self, app: &mut App) { let render_app = match app.get_sub_app_mut(RenderApp) { Ok(render_app) => render_app, Err(_) => return, }; render_app .init_resource::<RenderResourceNeedingDevice>(); } } ``` |
||
|
|
abf12f3b3b
|
Fixed several missing links in docs. (#8117)
Links in the api docs are nice. I noticed that there were several places where structs / functions and other things were referenced in the docs, but weren't linked. I added the links where possible / logical. --------- Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> Co-authored-by: François <mockersf@gmail.com> |
||
|
|
e9312254d8
|
Non-breaking change* from UK spellings to US (#8291)
Fixes issue mentioned in PR #8285. _Note: By mistake, this is currently dependent on #8285_ # Objective Ensure consistency in the spelling of the documentation. Exceptions: `crates/bevy_mikktspace/src/generated.rs` - Has not been changed from licence to license as it is part of a licensing agreement. Maybe for further consistency, https://github.com/bevyengine/bevy-website should also be given a look. ## Solution ### Changed the spelling of the current words (UK/CN/AU -> US) : cancelled -> canceled (Breaking API changes in #8285) behaviour -> behavior (Breaking API changes in #8285) neighbour -> neighbor grey -> gray recognise -> recognize centre -> center metres -> meters colour -> color ### ~~Update [`engine_style_guide.md`]~~ Moved to #8324 --- ## Changelog Changed UK spellings in documentation to US ## Migration Guide Non-breaking changes* \* If merged after #8285 |
||
|
|
8853bef6df |
implement TypeUuid for primitives and fix multiple-parameter generics having the same TypeUuid (#6633)
# Objective - Fixes #5432 - Fixes #6680 ## Solution - move code responsible for generating the `impl TypeUuid` from `type_uuid_derive` into a new function, `gen_impl_type_uuid`. - this allows the new proc macro, `impl_type_uuid`, to call the code for generation. - added struct `TypeUuidDef` and implemented `syn::Parse` to allow parsing of the input for the new macro. - finally, used the new macro `impl_type_uuid` to implement `TypeUuid` for the standard library (in `crates/bevy_reflect/src/type_uuid_impl.rs`). - fixes #6680 by doing a wrapping add of the param's index to its `TYPE_UUID` Co-authored-by: dis-da-moe <84386186+dis-da-moe@users.noreply.github.com> |
||
|
|
68c94c0732 |
Document usage of SRes::into_inner on the RenderCommand trait (#7224)
# Objective - Fixes: #7187 Since avoiding the `SRes::into_inner` call does not seem to be possible, this PR tries to at least document its usage. I am not sure if I explained the lifetime issue correctly, please let me know if something is incorrect. ## Solution - Add information about the `SRes::into_inner` usage on both `RenderCommand` and `Res` |
||
|
|
40bbbbb34e |
Introduce detailed_trace macro, use in TrackedRenderPass (#7639)
Profiles show that in extremely hot loops, like the draw loops in the renderer, invoking the trace! macro has noticeable overhead, even if the trace log level is not enabled. Solve this by introduce a 'wrapper' detailed_trace macro around trace, that wraps the trace! log statement in a trivially false if statement unless a cargo feature is enabled # Objective - Eliminate significant overhead observed with trace-level logging in render hot loops, even when trace log level is not enabled. - This is an alternative solution to the one proposed in #7223 ## Solution - Introduce a wrapper around the `trace!` macro called `detailed_trace!`. This macro wraps the `trace!` macro with an if statement that is conditional on a new cargo feature, `detailed_trace`. When the feature is not enabled (the default), then the if statement is trivially false and should be optimized away at compile time. - Convert the observed hot occurrences of trace logging in `TrackedRenderPass` with this new macro. Testing the results of ``` cargo run --profile stress-test --features bevy/trace_tracy --example many_cubes -- spheres ```  shows significant improvement of the `main_opaque_pass_3d` of the renderer, a median time decrease from 6.0ms to 3.5ms. --- ## Changelog - For performance reasons, some detailed renderer trace logs now require the use of cargo feature `detailed_trace` in addition to setting the log level to `TRACE` in order to be shown. ## Migration Guide - Some detailed bevy trace events now require the use of the cargo feature `detailed_trace` in addition to enabling `TRACE` level logging to view. Should you wish to see these logs, please compile your code with the bevy feature `detailed_trace`. Currently, the only logs that are affected are the renderer logs pertaining to `TrackedRenderPass` functions |
||
|
|
206c7ce219 |
Migrate engine to Schedule v3 (#7267)
Huge thanks to @maniwani, @devil-ira, @hymm, @cart, @superdump and @jakobhellermann for the help with this PR. # Objective - Followup #6587. - Minimal integration for the Stageless Scheduling RFC: https://github.com/bevyengine/rfcs/pull/45 ## Solution - [x] Remove old scheduling module - [x] Migrate new methods to no longer use extension methods - [x] Fix compiler errors - [x] Fix benchmarks - [x] Fix examples - [x] Fix docs - [x] Fix tests ## Changelog ### Added - a large number of methods on `App` to work with schedules ergonomically - the `CoreSchedule` enum - `App::add_extract_system` via the `RenderingAppExtension` trait extension method - the private `prepare_view_uniforms` system now has a public system set for scheduling purposes, called `ViewSet::PrepareUniforms` ### Removed - stages, and all code that mentions stages - states have been dramatically simplified, and no longer use a stack - `RunCriteriaLabel` - `AsSystemLabel` trait - `on_hierarchy_reports_enabled` run criteria (now just uses an ad hoc resource checking run condition) - systems in `RenderSet/Stage::Extract` no longer warn when they do not read data from the main world - `RunCriteriaLabel` - `transform_propagate_system_set`: this was a nonstandard pattern that didn't actually provide enough control. The systems are already `pub`: the docs have been updated to ensure that the third-party usage is clear. ### Changed - `System::default_labels` is now `System::default_system_sets`. - `App::add_default_labels` is now `App::add_default_sets` - `CoreStage` and `StartupStage` enums are now `CoreSet` and `StartupSet` - `App::add_system_set` was renamed to `App::add_systems` - The `StartupSchedule` label is now defined as part of the `CoreSchedules` enum - `.label(SystemLabel)` is now referred to as `.in_set(SystemSet)` - `SystemLabel` trait was replaced by `SystemSet` - `SystemTypeIdLabel<T>` was replaced by `SystemSetType<T>` - The `ReportHierarchyIssue` resource now has a public constructor (`new`), and implements `PartialEq` - Fixed time steps now use a schedule (`CoreSchedule::FixedTimeStep`) rather than a run criteria. - Adding rendering extraction systems now panics rather than silently failing if no subapp with the `RenderApp` label is found. - the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. - `SceneSpawnerSystem` now runs under `CoreSet::Update`, rather than `CoreStage::PreUpdate.at_end()`. - `bevy_pbr::add_clusters` is no longer an exclusive system - the top level `bevy_ecs::schedule` module was replaced with `bevy_ecs::scheduling` - `tick_global_task_pools_on_main_thread` is no longer run as an exclusive system. Instead, it has been replaced by `tick_global_task_pools`, which uses a `NonSend` resource to force running on the main thread. ## Migration Guide - Calls to `.label(MyLabel)` should be replaced with `.in_set(MySet)` - Stages have been removed. Replace these with system sets, and then add command flushes using the `apply_system_buffers` exclusive system where needed. - The `CoreStage`, `StartupStage, `RenderStage` and `AssetStage` enums have been replaced with `CoreSet`, `StartupSet, `RenderSet` and `AssetSet`. The same scheduling guarantees have been preserved. - Systems are no longer added to `CoreSet::Update` by default. Add systems manually if this behavior is needed, although you should consider adding your game logic systems to `CoreSchedule::FixedTimestep` instead for more reliable framerate-independent behavior. - Similarly, startup systems are no longer part of `StartupSet::Startup` by default. In most cases, this won't matter to you. - For example, `add_system_to_stage(CoreStage::PostUpdate, my_system)` should be replaced with - `add_system(my_system.in_set(CoreSet::PostUpdate)` - When testing systems or otherwise running them in a headless fashion, simply construct and run a schedule using `Schedule::new()` and `World::run_schedule` rather than constructing stages - Run criteria have been renamed to run conditions. These can now be combined with each other and with states. - Looping run criteria and state stacks have been removed. Use an exclusive system that runs a schedule if you need this level of control over system control flow. - For app-level control flow over which schedules get run when (such as for rollback networking), create your own schedule and insert it under the `CoreSchedule::Outer` label. - Fixed timesteps are now evaluated in a schedule, rather than controlled via run criteria. The `run_fixed_timestep` system runs this schedule between `CoreSet::First` and `CoreSet::PreUpdate` by default. - Command flush points introduced by `AssetStage` have been removed. If you were relying on these, add them back manually. - Adding extract systems is now typically done directly on the main app. Make sure the `RenderingAppExtension` trait is in scope, then call `app.add_extract_system(my_system)`. - the `calculate_bounds` system, with the `CalculateBounds` label, is now in `CoreSet::Update`, rather than in `CoreSet::PostUpdate` before commands are applied. You may need to order your movement systems to occur before this system in order to avoid system order ambiguities in culling behavior. - the `RenderLabel` `AppLabel` was renamed to `RenderApp` for clarity - `App::add_state` now takes 0 arguments: the starting state is set based on the `Default` impl. - Instead of creating `SystemSet` containers for systems that run in stages, simply use `.on_enter::<State::Variant>()` or its `on_exit` or `on_update` siblings. - `SystemLabel` derives should be replaced with `SystemSet`. You will also need to add the `Debug`, `PartialEq`, `Eq`, and `Hash` traits to satisfy the new trait bounds. - `with_run_criteria` has been renamed to `run_if`. Run criteria have been renamed to run conditions for clarity, and should now simply return a bool. - States have been dramatically simplified: there is no longer a "state stack". To queue a transition to the next state, call `NextState::set` ## TODO - [x] remove dead methods on App and World - [x] add `App::add_system_to_schedule` and `App::add_systems_to_schedule` - [x] avoid adding the default system set at inappropriate times - [x] remove any accidental cycles in the default plugins schedule - [x] migrate benchmarks - [x] expose explicit labels for the built-in command flush points - [x] migrate engine code - [x] remove all mentions of stages from the docs - [x] verify docs for States - [x] fix uses of exclusive systems that use .end / .at_start / .before_commands - [x] migrate RenderStage and AssetStage - [x] migrate examples - [x] ensure that transform propagation is exported in a sufficiently public way (the systems are already pub) - [x] ensure that on_enter schedules are run at least once before the main app - [x] re-enable opt-in to execution order ambiguities - [x] revert change to `update_bounds` to ensure it runs in `PostUpdate` - [x] test all examples - [x] unbreak directional lights - [x] unbreak shadows (see 3d_scene, 3d_shape, lighting, transparaency_3d examples) - [x] game menu example shows loading screen and menu simultaneously - [x] display settings menu is a blank screen - [x] `without_winit` example panics - [x] ensure all tests pass - [x] SubApp doc test fails - [x] runs_spawn_local tasks fails - [x] [Fix panic_when_hierachy_cycle test hanging](https://github.com/alice-i-cecile/bevy/pull/120) ## Points of Difficulty and Controversy **Reviewers, please give feedback on these and look closely** 1. Default sets, from the RFC, have been removed. These added a tremendous amount of implicit complexity and result in hard to debug scheduling errors. They're going to be tackled in the form of "base sets" by @cart in a followup. 2. The outer schedule controls which schedule is run when `App::update` is called. 3. I implemented `Label for `Box<dyn Label>` for our label types. This enables us to store schedule labels in concrete form, and then later run them. I ran into the same set of problems when working with one-shot systems. We've previously investigated this pattern in depth, and it does not appear to lead to extra indirection with nested boxes. 4. `SubApp::update` simply runs the default schedule once. This sucks, but this whole API is incomplete and this was the minimal changeset. 5. `time_system` and `tick_global_task_pools_on_main_thread` no longer use exclusive systems to attempt to force scheduling order 6. Implemetnation strategy for fixed timesteps 7. `AssetStage` was migrated to `AssetSet` without reintroducing command flush points. These did not appear to be used, and it's nice to remove these bottlenecks. 8. Migration of `bevy_render/lib.rs` and pipelined rendering. The logic here is unusually tricky, as we have complex scheduling requirements. ## Future Work (ideally before 0.10) - Rename schedule_v3 module to schedule or scheduling - Add a derive macro to states, and likely a `EnumIter` trait of some form - Figure out what exactly to do with the "systems added should basically work by default" problem - Improve ergonomics for working with fixed timesteps and states - Polish FixedTime API to match Time - Rebase and merge #7415 - Resolve all internal ambiguities (blocked on better tools, especially #7442) - Add "base sets" to replace the removed default sets. |
||
|
|
88b353c4b1 |
Reduce the use of atomics in the render phase (#7084)
# Objective Speed up the render phase of rendering. An extension of #6885. `SystemState::get` increments the `World`'s change tick atomically every time it's called. This is notably more expensive than a unsynchronized increment, even without contention. It also updates the archetypes, even when there has been nothing to update when it's called repeatedly. ## Solution Piggyback off of #6885. Split `SystemState::validate_world_and_update_archetypes` into `SystemState::validate_world` and `SystemState::update_archetypes`, and make the later `pub`. Then create safe variants of `SystemState::get_unchecked_manual` that still validate the `World` but do not update archetypes and do not increment the change tick using `World::read_change_tick` and `World::change_tick`. Update `RenderCommandState` to call `SystemState::update_archetypes` in `Draw::prepare` and `SystemState::get_manual` in `Draw::draw`. ## Performance There's a slight perf benefit (~2%) for `main_opaque_pass_3d` on `many_foxes` (340.39 us -> 333.32 us) 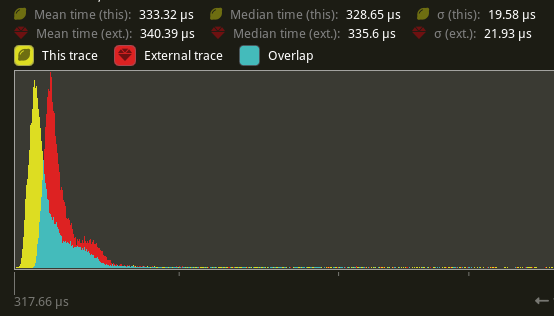 ## Alternatives We can change `SystemState::get` to not increment the `World`'s change tick. Though this would still put updating the archetypes and an atomic read on the hot-path. --- ## Changelog Added: `SystemState::get_manual` Added: `SystemState::get_manual_mut` Added: `SystemState::update_archetypes` |
||
|
|
76de9f9407 |
Improve render phase documentation (#7016)
# Objective The documentation of the bevy_render crate is still pretty incomplete. This PR follows up on #6885 and improves the documentation of the `render_phase` module. This module contains one of our most important rendering abstractions and the current documentation is pretty confusing. This PR tries to clarify what all of these pieces are for and how they work together to form bevy`s modular rendering logic. ## Solution ### Code Reformating - I have moved the `rangefinder` into the `render_phase` module since it is only used there. - I have moved the `PhaseItem` (and the `BatchedPhaseItem`) from `render_phase::draw` over to `render_phase::mod`. This does not change the public-facing API since they are reexported anyway, but this change makes the relation between `RenderPhase` and `PhaseItem` clear and easier to discover. ### Documentation - revised all documentation in the `render_phase` module - added a module-level explanation of how `RenderPhase`s, `RenderPass`es, `PhaseItem`s, `Draw` functions, and `RenderCommands` relate to each other and how they are used --- ## Changelog - The `rangefinder` module has been moved into the `render_phase` module. ## Migration Guide - The `rangefinder` module has been moved into the `render_phase` module. ```rust //old use bevy::render::rangefinder::*; // new use bevy::render::render_phase::rangefinder::*; ``` |
||
|
|
bef9bc1844 |
Reduce branching in TrackedRenderPass (#7053)
# Objective Speed up the render phase for rendering. ## Solution - Follow up #6988 and make the internals of atomic IDs `NonZeroU32`. This niches the `Option`s of the IDs in draw state, which reduces the size and branching behavior when evaluating for equality. - Require `&RenderDevice` to get the device's `Limits` when initializing a `TrackedRenderPass` to preallocate the bind groups and vertex buffer state in `DrawState`, this removes the branch on needing to resize those `Vec`s. ## Performance This produces a similar speed up akin to that of #6885. This shows an approximate 6% speed up in `main_opaque_pass_3d` on `many_foxes` (408.79 us -> 388us). This should be orthogonal to the gains seen there.  --- ## Changelog Added: `RenderContext::begin_tracked_render_pass`. Changed: `TrackedRenderPass` now requires a `&RenderDevice` on construction. Removed: `bevy_render::render_phase::DrawState`. It was not usable in any form outside of `bevy_render`. ## Migration Guide TODO |
||
|
|
2d727afaf7 |
Flatten render commands (#6885)
# Objective Speed up the render phase of rendering. Simplify the trait structure for render commands. ## Solution - Merge `EntityPhaseItem` into `PhaseItem` (`EntityPhaseItem::entity` -> `PhaseItem::entity`) - Merge `EntityRenderCommand` into `RenderCommand`. - Add two associated types to `RenderCommand`: `RenderCommand::ViewWorldQuery` and `RenderCommand::WorldQuery`. - Use the new associated types to construct two `QueryStates`s for `RenderCommandState`. - Hoist any `SQuery<T>` fetches in `EntityRenderCommand`s into the aformentioned two queries. Batch fetch them all at once. ## Performance `main_opaque_pass_3d` is slightly faster on `many_foxes` (427.52us -> 401.15us) 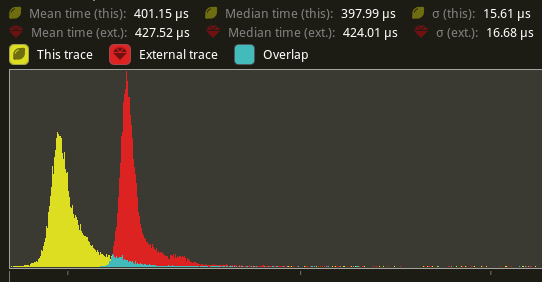 The shadow pass node is also slightly faster (344.52 -> 338.24us) 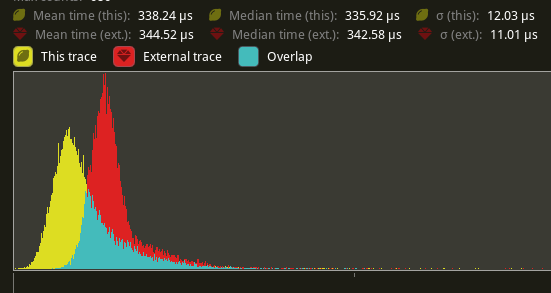 ## Future Work - Can we hoist the view level queries out of the core loop? --- ## Changelog Added: `PhaseItem::entity` Added: `RenderCommand::ViewWorldQuery` associated type. Added: `RenderCommand::ItemorldQuery` associated type. Added: `Draw<T>::prepare` optional trait function. Removed: `EntityPhaseItem` trait ## Migration Guide TODO |
||
|
|
b833bdab17 |
Allow to reuse the same RenderPass for multiple RenderPhases (#7043)
# Objective - The recently merged PR #7013 does not allow multiple `RenderPhase`s to share the same `RenderPass`. - Due to the introduced overhead we want to minimize the number of `RenderPass`es recorded during each frame. ## Solution - Take a constructed `TrackedRenderPass` instead of a `RenderPassDiscriptor` as a parameter to the `RenderPhase::render` method. --- ## Changelog To enable multiple `RenderPhases` to share the same `TrackedRenderPass`, the `RenderPhase::render` signature has changed. ```rust pub fn render<'w>( &self, render_pass: &mut TrackedRenderPass<'w>, world: &'w World, view: Entity) ``` Co-authored-by: Kurt Kühnert <51823519+kurtkuehnert@users.noreply.github.com> |
||
|
|
ca85f6c903 |
Extract common RenderPhase code into render method (#7013)
# Objective All `RenderPhases` follow the same render procedure. The same code is duplicated multiple times across the codebase. ## Solution I simply extracted this code into a method on the `RenderPhase`. This avoids code duplication and makes setting up new `RenderPhases` easier. --- ## Changelog ### Changed You can now set up the rendering code of a `RenderPhase` directly using the `RenderPhase::render` method, instead of implementing it manually in your render graph node. |
||
|
|
bd615cbf8c |
Shrink DrawFunctionId (#6944)
# Objective This includes one part of #4899. The aim is to improve CPU-side rendering performance by reducing the memory footprint and bandwidth required. ## Solution Shrink `DrawFunctionId` to `u32`. Enforce that `u32 as usize` conversions are always safe by forbidding compilation on 16-bit platforms. This shouldn't be a breaking change since #4736 disabled compilation of `bevy_ecs` on those platforms. Shrinking `DrawFunctionId` shrinks all of the `PhaseItem` types, which is integral to sort and render phase performance. Testing against `many_cubes`, the sort phase improved by 22% (174.21us -> 141.76us per frame).  The main opaque pass also imrproved by 9% (5.49ms -> 5.03ms)  Overall frame time improved by 5% (14.85ms -> 14.09ms)  There will be a followup PR that likewise shrinks `CachedRenderPipelineId` which should yield similar results on top of these improvements. |
||
|
|
1af73624fa |
Simplify trait hierarchy for SystemParam (#6865)
# Objective
* Implementing a custom `SystemParam` by hand requires implementing three traits -- four if it is read-only.
* The trait `SystemParamFetch<'w, 's>` is a workaround from before we had generic associated types, and is no longer necessary.
## Solution
* Combine the trait `SystemParamFetch` with `SystemParamState`.
* I decided to remove the `Fetch` name and keep the `State` name, since the former was consistently conflated with the latter.
* Replace the trait `ReadOnlySystemParamFetch` with `ReadOnlySystemParam`, which simplifies trait bounds in generic code.
---
## Changelog
- Removed the trait `SystemParamFetch`, moving its functionality to `SystemParamState`.
- Replaced the trait `ReadOnlySystemParamFetch` with `ReadOnlySystemParam`.
## Migration Guide
The trait `SystemParamFetch` has been removed, and its functionality has been transferred to `SystemParamState`.
```rust
// Before
impl SystemParamState for MyParamState {
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
}
impl<'w, 's> SystemParamFetch<'w, 's> for MyParamState {
type Item = MyParam<'w, 's>;
fn get_param(...) -> Self::Item;
}
// After
impl SystemParamState for MyParamState {
type Item<'w, 's> = MyParam<'w, 's>; // Generic associated types!
fn init(world: &mut World, system_meta: &mut SystemMeta) -> Self { ... }
fn get_param<'w, 's>(...) -> Self::Item<'w, 's>;
}
```
The trait `ReadOnlySystemParamFetch` has been replaced with `ReadOnlySystemParam`.
```rust
// Before
unsafe impl ReadOnlySystemParamFetch for MyParamState {}
// After
unsafe impl<'w, 's> ReadOnlySystemParam for MyParam<'w, 's> {}
```
|
||
|
|
f119d9df8e |
Add DrawFunctionsInternals::id() (#6745)
# Objective - Every usage of `DrawFunctionsInternals::get_id()` was followed by a `.unwrap()`. which just adds boilerplate. ## Solution - Introduce a fallible version of `DrawFunctionsInternals::get_id()` and use it where possible. - I also took the opportunity to improve the error message a little in the case where it fails. --- ## Changelog - Added `DrawFunctionsInternals::id()` |
||
|
|
694c980c82 |
Fix clippy::iter_with_drain (#6485)
# Objective Fixes #6483. - Fix the [`clippy::iter_with_drain`](https://rust-lang.github.io/rust-clippy/master/index.html#iter_with_drain) warnings - From the docs: "`.into_iter()` is simpler with better performance" ## Solution - Replace `.drain(..)` for `Vec` with `.into_iter()` |
||
|
|
dd7ff88760 |
Add multi draw indirect draw calls (#6392)
# Objective - Allows bevy users to dispatch `multi_draw_indirect`, `multi_draw_indexed_indirect`, `multi_draw_indirect_count`, `multi_draw_indexed_indirect_count` draw calls. - Fixes #6216 ## Solution - Added the corresponding wrapper methods to `TrackedRenderPass` --- ## Changelog > Added `multi_draw_*` draw calls to `TrackedRenderPass` Co-authored-by: Zhixing Zhang <me@neoto.xin> |
||
|
|
e71c4d2802 |
fix nightly clippy warnings (#6395)
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
|
||
|
|
128c169503 |
remove copyless (#6100)
# Objective Remove copyless copyless apparently isn't needed anymore to prevent extraneous memcopies and therefore got deprecated: https://github.com/kvark/copyless/issues/22 |
||
|
|
dc3f801239 |
Exclusive Systems Now Implement System. Flexible Exclusive System Params (#6083)
# Objective The [Stageless RFC](https://github.com/bevyengine/rfcs/pull/45) involves allowing exclusive systems to be referenced and ordered relative to parallel systems. We've agreed that unifying systems under `System` is the right move. This is an alternative to #4166 (see rationale in the comments I left there). Note that this builds on the learnings established there (and borrows some patterns). ## Solution This unifies parallel and exclusive systems under the shared `System` trait, removing the old `ExclusiveSystem` trait / impls. This is accomplished by adding a new `ExclusiveFunctionSystem` impl similar to `FunctionSystem`. It is backed by `ExclusiveSystemParam`, which is similar to `SystemParam`. There is a new flattened out SystemContainer api (which cuts out a lot of trait and type complexity). This means you can remove all cases of `exclusive_system()`: ```rust // before commands.add_system(some_system.exclusive_system()); // after commands.add_system(some_system); ``` I've also implemented `ExclusiveSystemParam` for `&mut QueryState` and `&mut SystemState`, which makes this possible in exclusive systems: ```rust fn some_exclusive_system( world: &mut World, transforms: &mut QueryState<&Transform>, state: &mut SystemState<(Res<Time>, Query<&Player>)>, ) { for transform in transforms.iter(world) { println!("{transform:?}"); } let (time, players) = state.get(world); for player in players.iter() { println!("{player:?}"); } } ``` Note that "exclusive function systems" assume `&mut World` is present (and the first param). I think this is a fair assumption, given that the presence of `&mut World` is what defines the need for an exclusive system. I added some targeted SystemParam `static` constraints, which removed the need for this: ``` rust fn some_exclusive_system(state: &mut SystemState<(Res<'static, Time>, Query<&'static Player>)>) {} ``` ## Related - #2923 - #3001 - #3946 ## Changelog - `ExclusiveSystem` trait (and implementations) has been removed in favor of sharing the `System` trait. - `ExclusiveFunctionSystem` and `ExclusiveSystemParam` were added, enabling flexible exclusive function systems - `&mut SystemState` and `&mut QueryState` now implement `ExclusiveSystemParam` - Exclusive and parallel System configuration is now done via a unified `SystemDescriptor`, `IntoSystemDescriptor`, and `SystemContainer` api. ## Migration Guide Calling `.exclusive_system()` is no longer required (or supported) for converting exclusive system functions to exclusive systems: ```rust // Old (0.8) app.add_system(some_exclusive_system.exclusive_system()); // New (0.9) app.add_system(some_exclusive_system); ``` Converting "normal" parallel systems to exclusive systems is done by calling the exclusive ordering apis: ```rust // Old (0.8) app.add_system(some_system.exclusive_system().at_end()); // New (0.9) app.add_system(some_system.at_end()); ``` Query state in exclusive systems can now be cached via ExclusiveSystemParams, which should be preferred for clarity and performance reasons: ```rust // Old (0.8) fn some_system(world: &mut World) { let mut transforms = world.query::<&Transform>(); for transform in transforms.iter(world) { } } // New (0.9) fn some_system(world: &mut World, transforms: &mut QueryState<&Transform>) { for transform in transforms.iter(world) { } } ``` |
||
|
|
e96b21a24a |
Fix DrawFunctionId typo (#5996)
Fix extra slashes visible in documentation of `DrawFunctionId`. Also point to where the type is used. |
||
|
|
992681b59b |
Make Resource trait opt-in, requiring #[derive(Resource)] V2 (#5577)
*This PR description is an edited copy of #5007, written by @alice-i-cecile.* # Objective Follow-up to https://github.com/bevyengine/bevy/pull/2254. The `Resource` trait currently has a blanket implementation for all types that meet its bounds. While ergonomic, this results in several drawbacks: * it is possible to make confusing, silent mistakes such as inserting a function pointer (Foo) rather than a value (Foo::Bar) as a resource * it is challenging to discover if a type is intended to be used as a resource * we cannot later add customization options (see the [RFC](https://github.com/bevyengine/rfcs/blob/main/rfcs/27-derive-component.md) for the equivalent choice for Component). * dependencies can use the same Rust type as a resource in invisibly conflicting ways * raw Rust types used as resources cannot preserve privacy appropriately, as anyone able to access that type can read and write to internal values * we cannot capture a definitive list of possible resources to display to users in an editor ## Notes to reviewers * Review this commit-by-commit; there's effectively no back-tracking and there's a lot of churn in some of these commits. *ira: My commits are not as well organized :')* * I've relaxed the bound on Local to Send + Sync + 'static: I don't think these concerns apply there, so this can keep things simple. Storing e.g. a u32 in a Local is fine, because there's a variable name attached explaining what it does. * I think this is a bad place for the Resource trait to live, but I've left it in place to make reviewing easier. IMO that's best tackled with https://github.com/bevyengine/bevy/issues/4981. ## Changelog `Resource` is no longer automatically implemented for all matching types. Instead, use the new `#[derive(Resource)]` macro. ## Migration Guide Add `#[derive(Resource)]` to all types you are using as a resource. If you are using a third party type as a resource, wrap it in a tuple struct to bypass orphan rules. Consider deriving `Deref` and `DerefMut` to improve ergonomics. `ClearColor` no longer implements `Component`. Using `ClearColor` as a component in 0.8 did nothing. Use the `ClearColorConfig` in the `Camera3d` and `Camera2d` components instead. Co-authored-by: Alice <alice.i.cecile@gmail.com> Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com> Co-authored-by: devil-ira <justthecooldude@gmail.com> Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
cfee0e882e |
Fix various typos (#5417)
## Objective - Fix some typos ## Solution - Fix em. - My favorite was `maxizimed` |
||
|
|
4847f7e3ad |
Update codebase to use IntoIterator where possible. (#5269)
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
|
||
|
|
7e6dd3f03e |
Allow unbatched render phases to use unstable sorts (#5049)
# Objective Partially addresses #4291. Speed up the sort phase for unbatched render phases. ## Solution Split out one of the optimizations in #4899 and allow implementors of `PhaseItem` to change what kind of sort is used when sorting the items in the phase. This currently includes Stable, Unstable, and Unsorted. Each of these corresponds to `Vec::sort_by_key`, `Vec::sort_unstable_by_key`, and no sorting at all. The default is `Unstable`. The last one can be used as a default if users introduce a preliminary depth prepass. ## Performance This will not impact the performance of any batched phases, as it is still using a stable sort. 2D's only phase is unchanged. All 3D phases are unbatched currently, and will benefit from this change. On `many_cubes`, where the primary phase is opaque, this change sees a speed up from 907.02us -> 477.62us, a 47.35% reduction.  ## Future Work There were prior discussions to add support for faster radix sorts in #4291, which in theory should be a `O(n)` instead of a `O(nlog(n))` time. [`voracious`](https://crates.io/crates/voracious_radix_sort) has been proposed, but it seems to be optimize for use cases with more than 30,000 items, which may be atypical for most systems. Another optimization included in #4899 is to reduce the size of a few of the IDs commonly used in `PhaseItem` implementations to shrink the types to make swapping/sorting faster. Both `CachedPipelineId` and `DrawFunctionId` could be reduced to `u32` instead of `usize`. Ideally, this should automatically change to use stable sorts when `BatchedPhaseItem` is implemented on the same phase item type, but this requires specialization, which may not land in stable Rust for a short while. --- ## Changelog Added: `PhaseItem::sort` ## Migration Guide RenderPhases now default to a unstable sort (via `slice::sort_unstable_by_key`). This can typically improve sort phase performance, but may produce incorrect batching results when implementing `BatchedPhaseItem`. To revert to the older stable sort, manually implement `PhaseItem::sort` to implement a stable sort (i.e. via `slice::sort_by_key`). Co-authored-by: Federico Rinaldi <gisquerin@gmail.com> Co-authored-by: Robert Swain <robert.swain@gmail.com> Co-authored-by: colepoirier <colepoirier@gmail.com> |
||
|
|
5e2cfb2f19 |
Camera Driven Viewports (#4898)
# Objective Users should be able to render cameras to specific areas of a render target, which enables scenarios like split screen, minimaps, etc. Builds on the new Camera Driven Rendering added here: #4745 Fixes: #202 Alternative to #1389 and #3626 (which are incompatible with the new Camera Driven Rendering) ## Solution  Cameras can now configure an optional "viewport", which defines a rectangle within their render target to draw to. If a `Viewport` is defined, the camera's `CameraProjection`, `View`, and visibility calculations will use the viewport configuration instead of the full render target. ```rust // This camera will render to the first half of the primary window (on the left side). commands.spawn_bundle(Camera3dBundle { camera: Camera { viewport: Some(Viewport { physical_position: UVec2::new(0, 0), physical_size: UVec2::new(window.physical_width() / 2, window.physical_height()), depth: 0.0..1.0, }), ..default() }, ..default() }); ``` To account for this, the `Camera` component has received a few adjustments: * `Camera` now has some new getter functions: * `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, `projection_matrix` * All computed camera values are now private and live on the `ComputedCameraValues` field (logical/physical width/height, the projection matrix). They are now exposed on `Camera` via getters/setters This wasn't _needed_ for viewports, but it was long overdue. --- ## Changelog ### Added * `Camera` components now have a `viewport` field, which can be set to draw to a portion of a render target instead of the full target. * `Camera` component has some new functions: `logical_viewport_size`, `physical_viewport_size`, `logical_target_size`, `physical_target_size`, and `projection_matrix` * Added a new split_screen example illustrating how to render two cameras to the same scene ## Migration Guide `Camera::projection_matrix` is no longer a public field. Use the new `Camera::projection_matrix()` method instead: ```rust // Bevy 0.7 let projection = camera.projection_matrix; // Bevy 0.8 let projection = camera.projection_matrix(); ``` |
||
|
|
f000c2b951 |
Clippy improvements (#4665)
# Objective Follow up to my previous MR #3718 to add new clippy warnings to bevy: - [x] [~~option_if_let_else~~](https://rust-lang.github.io/rust-clippy/master/#option_if_let_else) (reverted) - [x] [redundant_else](https://rust-lang.github.io/rust-clippy/master/#redundant_else) - [x] [match_same_arms](https://rust-lang.github.io/rust-clippy/master/#match_same_arms) - [x] [semicolon_if_nothing_returned](https://rust-lang.github.io/rust-clippy/master/#semicolon_if_nothing_returned) - [x] [explicit_iter_loop](https://rust-lang.github.io/rust-clippy/master/#explicit_iter_loop) - [x] [map_flatten](https://rust-lang.github.io/rust-clippy/master/#map_flatten) There is one commit per clippy warning, and the matching flags are added to the CI execution. To test the CI execution you may run `cargo run -p ci -- clippy` at the root. I choose the add the flags in the `ci` tool crate to avoid having them in every `lib.rs` but I guess it could become an issue with suprise warnings coming up after a commit/push Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
9e450f2827 |
Compute Pipeline Specialization (#3979)
# Objective - Fixes #3970 - To support Bevy's shader abstraction(shader defs, shader imports and hot shader reloading) for compute shaders, I have followed carts advice and change the `PipelinenCache` to accommodate both compute and render pipelines. ## Solution - renamed `RenderPipelineCache` to `PipelineCache` - Cached Pipelines are now represented by an enum (render, compute) - split the `SpecializedPipelines` into `SpecializedRenderPipelines` and `SpecializedComputePipelines` - updated the game of life example ## Open Questions - should `SpecializedRenderPipelines` and `SpecializedComputePipelines` be merged and how would we do that? - should the `get_render_pipeline` and `get_compute_pipeline` methods be merged? - is pipeline specialization for different entry points a good pattern Co-authored-by: Kurt Kühnert <51823519+Ku95@users.noreply.github.com> Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
40b36927f5 |
Expose draw indirect (#4056)
# Objective - Currently there is now way of making an indirect draw call from a tracked render pass. - This is a very useful feature for GPU based rendering. ## Solution - Expose the `draw_indirect` and `draw_indexed_indirect` methods from the wgpu `RenderPass` in the `TrackedRenderPass`. ## Alternative - #3595: Expose the underlying `RenderPass` directly |
||
|
|
d8974e7c3d |
small and mostly pointless refactoring (#2934)
What is says on the tin. This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance. that said, deriving `Default` for a couple of structs is a nice easy win |
||
|
|
5bb4201f2e |
add informative panic message when adding render commands to a DrawFunctions that does not exist (#3924)
# Objective If a user attempts to `.add_render_command::<P, C>()` on a world that does not contain `DrawFunctions<P>`, the engine panics with a generic `Option::unwrap` message: ``` thread 'main' panicked at 'called `Option::unwrap()` on a `None` value', /[redacted]/bevy/crates/bevy_render/src/render_phase/draw.rs:318:76 ``` ## Solution This PR adds a panic message describing the problem: ``` thread 'main' panicked at 'DrawFunctions<outline::MeshStencil> must be added to the world as a resource before adding render commands to it', /[redacted]/bevy/crates/bevy_render/src/render_phase/draw.rs:322:17 ``` |
||
|
|
e56685370b |
Fix doc_markdown lints in bevy_render (#3479)
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time. This PR fixes lints in the `bevy_render` crate. |
||
|
|
c2da7800e3 |
Add 2d meshes and materials (#3460)
# Objective The current 2d rendering is specialized to render sprites, we need a generic way to render 2d items, using meshes and materials like we have for 3d. ## Solution I cloned a good part of `bevy_pbr` into `bevy_sprite/src/mesh2d`, removed lighting and pbr itself, adapted it to 2d rendering, added a `ColorMaterial`, and modified the sprite rendering to break batches around 2d meshes. ~~The PR is a bit crude; I tried to change as little as I could in both the parts copied from 3d and the current sprite rendering to make reviewing easier. In the future, I expect we could make the sprite rendering a normal 2d material, cleanly integrated with the rest.~~ _edit: see <https://github.com/bevyengine/bevy/pull/3460#issuecomment-1003605194>_ ## Remaining work - ~~don't require mesh normals~~ _out of scope_ - ~~add an example~~ _done_ - support 2d meshes & materials in the UI? - bikeshed names (I didn't think hard about naming, please check if it's fine) ## Remaining questions - ~~should we add a depth buffer to 2d now that there are 2d meshes?~~ _let's revisit that when we have an opaque render phase_ - ~~should we add MSAA support to the sprites, or remove it from the 2d meshes?~~ _I added MSAA to sprites since it's really needed for 2d meshes_ - ~~how to customize vertex attributes?~~ _#3120_ Co-authored-by: Carter Anderson <mcanders1@gmail.com> |
||
|
|
b9c623e4f3 |
Configurable wgpu features/limits priority (#3452)
# Objective - Allow the user to specify the priority when configuring wgpu features/limits and by default use the maximum capabilities of the chosen adapter. ## Solution - Add a `WgpuOptionsPriority` enum with `Compatibility`, `Functionality` and `WebGL2` options. - Add a `priority: WgpuOptionsPriority` member to `WgpuOptions`. - When initialising the renderer, if `WgpuOptions::priority == WgpuOptionsPriority::Functionality`, query the adapter for the available features and limits, use them when creating a device, and update `WgpuOptions` with those values. If `Compatibility` use the behaviour as before this PR. If `WebGL2` then use the WebGL2 downlevel limits as used when when building for wasm, for convenience of testing WebGL2 limits without having to build for wasm. - Add an environment variable `WGPU_OPTIONS_PRIO` that takes `compatibility`, `functionality`, `webgl2`. - Default to `WgpuOptionsPriority::Functionality`. - Insert updated `WgpuOptions` into render app world as well. This is useful for applying the limits when rendering, such as limiting the directional light shadow map texture to 2048x2048 when using WebGL2 downlevel limits but not on wasm. - Reduced `draw_state` logs from `debug` to `trace` and added `debug` level logs for the wgpu features and limits. Use `RUST_LOG=bevy_render=debug` to see the output. |
||
|
|
e43e36696d |
Minor docs edit/add in bevy_render (#3447)
# Objective Docs updates. ## Solution - Detail what `OrthographicCameraBundle::new_2d()` creates. - Fix a few renamed parameters in comments of `TrackedRenderPass`. - Add missing comments for viewport and debug markers. Co-authored-by: Jerome Humbert <djeedai@gmail.com> |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}