# Objective
- Fixes#7680
- This is an updated for https://github.com/bevyengine/bevy/pull/8899
which had the same objective but fell a long way behind the latest
changes
## Solution
The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter :
WorldQuery` have been added and some of the types and functions from
`WorldQuery` has been moved into them.
`ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`.
`WorldQueryFilter` is safe (as long as `WorldQuery` is implemented
safely).
`WorldQueryData` is unsafe - safely implementing it requires that
`Self::ReadOnly` is a readonly version of `Self` (this used to be a
safety requirement of `WorldQuery`)
The type parameters `Q` and `F` of `Query` must now implement
`WorldQueryData` and `WorldQueryFilter` respectively.
This makes it impossible to accidentally use a filter in the data
position or vice versa which was something that could lead to bugs.
~~Compile failure tests have been added to check this.~~
It was previously sometimes useful to use `Option<With<T>>` in the data
position. Use `Has<T>` instead in these cases.
The `WorldQuery` derive macro has been split into separate derive macros
for `WorldQueryData` and `WorldQueryFilter`.
Previously it was possible to derive both `WorldQuery` for a struct that
had a mixture of data and filter items. This would not work correctly in
some cases but could be a useful pattern in others. *This is no longer
possible.*
---
## Notes
- The changes outside of `bevy_ecs` are all changing type parameters to
the new types, updating the macro use, or replacing `Option<With<T>>`
with `Has<T>`.
- All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL`
so I moved it to `WorldQueryFilter` and
replaced all calls to it with `true`. That should be the only logic
change outside of the macro generation code.
- `Changed<T>` and `Added<T>` were being generated by a macro that I
have expanded. Happy to revert that if desired.
- The two derive macros share some functions for implementing
`WorldQuery` but the tidiest way I could find to implement them was to
give them a ton of arguments and ask clippy to ignore that.
## Changelog
### Changed
- Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which
now have separate derive macros. It is not possible to derive both for
the same type.
- `Query` now requires that the first type argument implements
`WorldQueryData` and the second implements `WorldQueryFilter`
## Migration Guide
- Update derives
```rust
// old
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA
}
#[derive(WorldQuery)]
struct QueryFilter {
_c: With<ComponentC>
}
// new
#[derive(WorldQueryData)]
#[world_query_data(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA,
}
#[derive(WorldQueryFilter)]
struct QueryFilter {
_c: With<ComponentC>
}
```
- Replace `Option<With<T>>` with `Has<T>`
```rust
/// old
fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>)
{
for (entity, has_a_option) in query.iter(){
let has_a:bool = has_a_option.is_some();
//todo!()
}
}
/// new
fn my_system(query: Query<(Entity, Has<ComponentA>)>)
{
for (entity, has_a) in query.iter(){
//todo!()
}
}
```
- Fix queries which had filters in the data position or vice versa.
```rust
// old
fn my_system(query: Query<(Entity, With<ComponentA>)>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Entity, With<ComponentA>>)
{
for entity in query.iter(){
//todo!()
}
}
// old
fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>)
{
for entity in query.iter(){
//todo!()
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
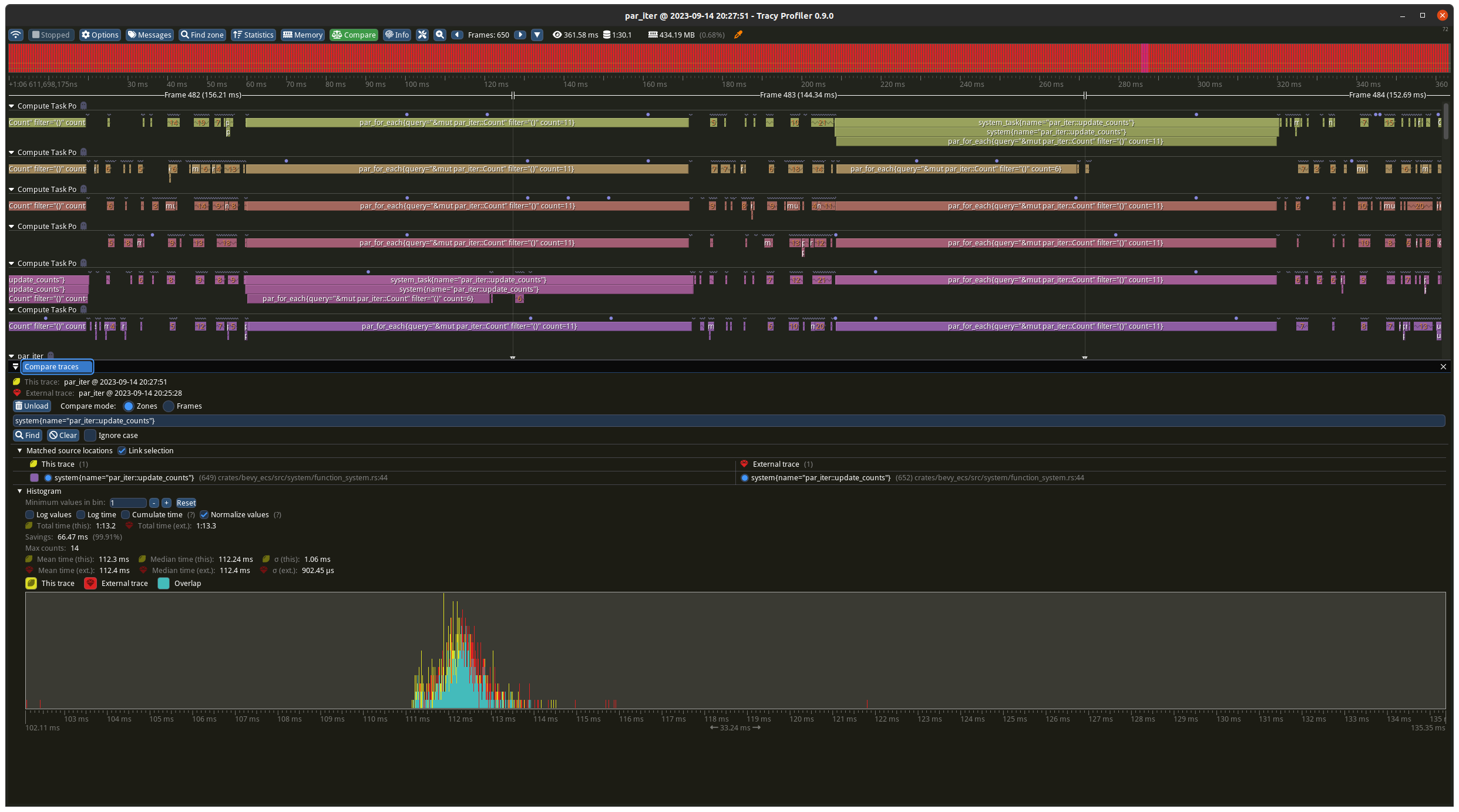
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- The function `QueryParIter::for_each_unchecked` is a footgun: the only
ways to use it soundly can be done in safe code using `for_each` or
`for_each_mut`. See [this discussion on
discord](https://discord.com/channels/691052431525675048/749335865876021248/1118642977275924583).
## Solution
- Make `for_each_unchecked` private.
---
## Changelog
- Removed `QueryParIter::for_each_unchecked`. All use-cases of this
method were either unsound or doable in safe code using `for_each` or
`for_each_mut`.
## Migration Guide
The method `QueryParIter::for_each_unchecked` has been removed -- use
`for_each` or `for_each_mut` instead. If your use case can not be
achieved using either of these, then your code was likely unsound.
If you have a use-case for `for_each_unchecked` that you believe is
sound, please [open an
issue](https://github.com/bevyengine/bevy/issues/new/choose).
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
{kind=link}