# Objective
Improve the performance of `FilteredEntity(Ref|Mut)` and
`Entity(Ref|Mut)Except`.
`FilteredEntityRef` needs an `Access<ComponentId>` to determine what
components it can access. There is one stored in the query state, but
query items cannot borrow from the state, so it has to `clone()` the
access for each row. Cloning the access involves memory allocations and
can be expensive.
## Solution
Let query items borrow from their query state.
Add an `'s` lifetime to `WorldQuery::Item` and `WorldQuery::Fetch`,
similar to the one in `SystemParam`, and provide `&'s Self::State` to
the fetch so that it can borrow from the state.
Unfortunately, there are a few cases where we currently return query
items from temporary query states: the sorted iteration methods create a
temporary state to query the sort keys, and the
`EntityRef::components<Q>()` methods create a temporary state for their
query.
To allow these to continue to work with most `QueryData`
implementations, introduce a new subtrait `ReleaseStateQueryData` that
converts a `QueryItem<'w, 's>` to `QueryItem<'w, 'static>`, and is
implemented for everything except `FilteredEntity(Ref|Mut)` and
`Entity(Ref|Mut)Except`.
`#[derive(QueryData)]` will generate `ReleaseStateQueryData`
implementations that apply when all of the subqueries implement
`ReleaseStateQueryData`.
This PR does not actually change the implementation of
`FilteredEntity(Ref|Mut)` or `Entity(Ref|Mut)Except`! That will be done
as a follow-up PR so that the changes are easier to review. I have
pushed the changes as chescock/bevy#5.
## Testing
I ran performance traces of many_foxes, both against main and against
chescock/bevy#5, both including #15282. These changes do appear to make
generalized animation a bit faster:
(Red is main, yellow is chescock/bevy#5)

## Migration Guide
The `WorldQuery::Item` and `WorldQuery::Fetch` associated types and the
`QueryItem` and `ROQueryItem` type aliases now have an additional
lifetime parameter corresponding to the `'s` lifetime in `Query`. Manual
implementations of `WorldQuery` will need to update the method
signatures to include the new lifetimes. Other uses of the types will
need to be updated to include a lifetime parameter, although it can
usually be passed as `'_`. In particular, `ROQueryItem` is used when
implementing `RenderCommand`.
Before:
```rust
fn render<'w>(
item: &P,
view: ROQueryItem<'w, Self::ViewQuery>,
entity: Option<ROQueryItem<'w, Self::ItemQuery>>,
param: SystemParamItem<'w, '_, Self::Param>,
pass: &mut TrackedRenderPass<'w>,
) -> RenderCommandResult;
```
After:
```rust
fn render<'w>(
item: &P,
view: ROQueryItem<'w, '_, Self::ViewQuery>,
entity: Option<ROQueryItem<'w, '_, Self::ItemQuery>>,
param: SystemParamItem<'w, '_, Self::Param>,
pass: &mut TrackedRenderPass<'w>,
) -> RenderCommandResult;
```
---
Methods on `QueryState` that take `&mut self` may now result in
conflicting borrows if the query items capture the lifetime of the
mutable reference. This affects `get()`, `iter()`, and others. To fix
the errors, first call `QueryState::update_archetypes()`, and then
replace a call `state.foo(world, param)` with
`state.query_manual(world).foo_inner(param)`. Alternately, you may be
able to restructure the code to call `state.query(world)` once and then
make multiple calls using the `Query`.
Before:
```rust
let mut state: QueryState<_, _> = ...;
let d1 = state.get(world, e1);
let d2 = state.get(world, e2); // Error: cannot borrow `state` as mutable more than once at a time
println!("{d1:?}");
println!("{d2:?}");
```
After:
```rust
let mut state: QueryState<_, _> = ...;
state.update_archetypes(world);
let d1 = state.get_manual(world, e1);
let d2 = state.get_manual(world, e2);
// OR
state.update_archetypes(world);
let d1 = state.query(world).get_inner(e1);
let d2 = state.query(world).get_inner(e2);
// OR
let query = state.query(world);
let d1 = query.get_inner(e1);
let d1 = query.get_inner(e2);
println!("{d1:?}");
println!("{d2:?}");
```
# Objective
Since #18704 is done, we can track the length of unique entity row
collections with only a `u32` and identify an index within that
collection with only a `NonMaxU32`. This leaves an opportunity for
performance improvements.
## Solution
- Use `EntityRow` in sparse sets.
- Change table, entity, and query lengths to be `u32` instead of
`usize`.
- Keep `batching` module `usize` based since that is reused for events,
which may exceed `u32::MAX`.
- Change according `Range<usize>` to `Range<u32>`. This is more
efficient and helps justify safety.
- Change `ArchetypeRow` and `TableRow` to wrap `NonMaxU32` instead of
`u32`.
Justifying `NonMaxU32::new_unchecked` everywhere is predicated on this
safety comment in `Entities::set`: "`location` must be valid for the
entity at `index` or immediately made valid afterwards before handing
control to unknown code." This ensures no entity is in two table rows
for example. That fact is used to argue uniqueness of the entity rows in
each table, archetype, sparse set, query, etc. So if there's no
duplicates, and a maximum total entities of `u32::MAX` none of the
corresponding row ids / indexes can exceed `NonMaxU32`.
## Testing
CI
---------
Co-authored-by: Christian Hughes <9044780+ItsDoot@users.noreply.github.com>
# Objective
The goal of `bevy_platform_support` is to provide a set of platform
agnostic APIs, alongside platform-specific functionality. This is a high
traffic crate (providing things like HashMap and Instant). Especially in
light of https://github.com/bevyengine/bevy/discussions/18799, it
deserves a friendlier / shorter name.
Given that it hasn't had a full release yet, getting this change in
before Bevy 0.16 makes sense.
## Solution
- Rename `bevy_platform_support` to `bevy_platform`.
# Objective
Newest installment of the #16547 series.
In #18319 we introduced `Entity` defaults to accomodate the most common
use case for these types, however that resulted in the switch of the `T`
and `N` generics of `UniqueEntityArray`.
Swapping generics might be somewhat acceptable for `UniqueEntityArray`,
it is not at all acceptable for map and set types, which we would make
generic over `T: EntityEquivalent` in #18408.
Leaving these defaults in place would result in a glaring inconsistency
between these set collections and the others.
Additionally, the current standard in the engine is for "entity" to mean
`Entity`. APIs could be changed to accept `EntityEquivalent`, however
that is a separate and contentious discussion.
## Solution
Name these set collections `UniqueEntityEquivalent*`, and retain the
`UniqueEntity*` name for an alias of the `Entity` case.
While more verbose, this allows for all generics to be in proper order,
full consistency between all set types*, and the "entity" name to be
restricted to `Entity`.
On top of that, `UniqueEntity*` now always have 1 generic less, when
previously this was not enforced for the default case.
*`UniqueEntityIter<I: Iterator<T: EntityEquivalent>>` is the sole
exception to this. Aliases are unable to enforce bounds
(`lazy_type_alias` is needed for this), so for this type, doing this
split would be a mere suggestion, and in no way enforced.
Iterator types are rarely ever named, and this specific one is intended
to be aliased when it sees more use, like we do for the corresponding
set collection iterators.
Furthermore, the `EntityEquivalent` precursor `Borrow<Entity>` was used
exactly because of such iterator bounds!
Because of that, we leave it as is.
While no migration guide for 0.15 users, for those that upgrade from
main:
`UniqueEntityVec<T>` -> `UniqueEntityEquivalentVec<T>`
`UniqueEntitySlice<T>` -> `UniqueEntityEquivalentSlice<T>`
`UniqueEntityArray<N, T>` -> `UniqueEntityEquivalentArray<T, N>`
# Objective
Fixes#9367.
Yet another follow-up to #16547.
These traits were initially based on `Borrow<Entity>` because that trait
was what they were replacing, and it felt close enough in meaning.
However, they ultimately don't quite match: `borrow` always returns
references, whereas `EntityBorrow` always returns a plain `Entity`.
Additionally, `EntityBorrow` can imply that we are borrowing an `Entity`
from the ECS, which is not what it does.
Due to its safety contract, `TrustedEntityBorrow` is important an
important and widely used trait for `EntitySet` functionality.
In contrast, the safe `EntityBorrow` does not see much use, because even
outside of `EntitySet`-related functionality, it is a better idea to
accept `TrustedEntityBorrow` over `EntityBorrow`.
Furthermore, as #9367 points out, abstracting over returning `Entity`
from pointers/structs that contain it can skip some ergonomic friction.
On top of that, there are aspects of #18319 and #18408 that are relevant
to naming:
We've run into the issue that relying on a type default can switch
generic order. This is livable in some contexts, but unacceptable in
others.
To remedy that, we'd need to switch to a type alias approach:
The "defaulted" `Entity` case becomes a
`UniqueEntity*`/`Entity*Map`/`Entity*Set` alias, and the base type
receives a more general name. `TrustedEntityBorrow` does not mesh
clearly with sensible base type names.
## Solution
Replace any `EntityBorrow` bounds with `TrustedEntityBorrow`.
+
Rename them as such:
`EntityBorrow` -> `ContainsEntity`
`TrustedEntityBorrow` -> `EntityEquivalent`
For `EntityBorrow` we produce a change in meaning; We designate it for
types that aren't necessarily strict wrappers around `Entity` or some
pointer to `Entity`, but rather any of the myriad of types that contain
a single associated `Entity`.
This pattern can already be seen in the common `entity`/`id` methods
across the engine.
We do not mean for `ContainsEntity` to be a trait that abstracts input
API (like how `AsRef<T>` is often used, f.e.), because eliding
`entity()` would be too implicit in the general case.
We prefix "Contains" to match the intuition of a struct with an `Entity`
field, like some contain a `length` or `capacity`.
It gives the impression of structure, which avoids the implication of a
relationship to the `ECS`.
`HasEntity` f.e. could be interpreted as "a currently live entity",
As an input trait for APIs like #9367 envisioned, `TrustedEntityBorrow`
is a better fit, because it *does* restrict itself to strict wrappers
and pointers. Which is why we replace any
`EntityBorrow`/`ContainsEntity` bounds with
`TrustedEntityBorrow`/`EntityEquivalent`.
Here, the name `EntityEquivalent` is a lot closer to its actual meaning,
which is "A type that is both equivalent to an `Entity`, and forms the
same total order when compared".
Prior art for this is the
[`Equivalent`](https://docs.rs/hashbrown/latest/hashbrown/trait.Equivalent.html)
trait in `hashbrown`, which utilizes both `Borrow` and `Eq` for its one
blanket impl!
Given that we lose the `Borrow` moniker, and `Equivalent` can carry
various meanings, we expand on the safety comment of `EntityEquivalent`
somewhat. That should help prevent the confusion we saw in
[#18408](https://github.com/bevyengine/bevy/pull/18408#issuecomment-2742094176).
The new name meshes a lot better with the type aliasing approach in
#18408, by aligning with the base name `EntityEquivalentHashMap`.
For a consistent scheme among all set types, we can use this scheme for
the `UniqueEntity*` wrapper types as well!
This allows us to undo the switched generic order that was introduced to
`UniqueEntityArray` by its `Entity` default.
Even without the type aliases, I think these renames are worth doing!
## Migration Guide
Any use of `EntityBorrow` becomes `ContainsEntity`.
Any use of `TrustedEntityBorrow` becomes `EntityEquivalent`.
# Objective
Unlike for their helper typers, the import paths for
`unique_array::UniqueEntityArray`, `unique_slice::UniqueEntitySlice`,
`unique_vec::UniqueEntityVec`, `hash_set::EntityHashSet`,
`hash_map::EntityHashMap`, `index_set::EntityIndexSet`,
`index_map::EntityIndexMap` are quite redundant.
When looking at the structure of `hashbrown`, we can also see that while
both `HashSet` and `HashMap` have their own modules, the main types
themselves are re-exported to the crate level.
## Solution
Re-export the types in their shared `entity` parent module, and simplify
the imports where they're used.
# Objective
Part of the #16547 series.
The entity wrapper types often have some associated types an aliases
with them that cannot be re-exported into an outer module together.
Some helper types are best used with part of their path:
`bevy::ecs::entity::index_set::Slice` as `index_set::Slice`.
This has already been done for `entity::hash_set` and
`entity::hash_map`.
## Solution
Publicize the `index_set`, `index_map`, `unique_vec`, `unique_slice`,
and `unique_array` modules.
## Migration Guide
Any mention or import of types in the affected modules have to add the
respective module name to the import path.
F.e.:
`bevy::ecs::entity::EntityIndexSet` ->
`bevy::ecs::entity::index_set::EntityIndexSet`
# Objective
Simplify the API surface by removing duplicated functionality between
`Query` and `QueryState`.
Reduce the amount of `unsafe` code required in `QueryState`.
This is a follow-up to #15858.
## Solution
Move implementations of `Query` methods from `QueryState` to `Query`.
Instead of the original methods being on `QueryState`, with `Query`
methods calling them by passing the individual parameters, the original
methods are now on `Query`, with `QueryState` methods calling them by
constructing a `Query`.
This also adds two `_inner` methods that were missed in #15858:
`iter_many_unique_inner` and `single_inner`.
One goal here is to be able to deprecate and eventually remove many of
the methods on `QueryState`, reducing the overall API surface. (I
expected to do that in this PR, but this change was large enough on its
own!) Now that the `QueryState` methods each consist of a simple
expression like `self.query(world).get_inner(entity)`, a future PR can
deprecate some or all of them with simple migration instructions.
The other goal is to reduce the amount of `unsafe` code. The current
implementation of a read-only method like `QueryState::get` directly
calls the `unsafe fn get_unchecked_manual` and needs to repeat the proof
that `&World` has enough access. With this change, `QueryState::get` is
entirely safe code, with the proof that `&World` has enough access done
by the `query()` method and shared across all read-only operations.
## Future Work
The next step will be to mark the `QueryState` methods as
`#[deprecated]` and migrate callers to the methods on `Query`.
# Objective
Continuation of #16547.
We do not yet have parallel versions of `par_iter_many` and
`par_iter_many_unique`. It is currently very painful to try and use
parallel iteration over entity lists. Even if a list is not long, each
operation might still be very expensive, and worth parallelizing.
Plus, it has been requested several times!
## Solution
Once again, we implement what we lack!
These parallel iterators collect their input entity list into a
`Vec`/`UniqueEntityVec`, then chunk that over the available threads,
inspired by the original `par_iter`.
Since no order guarantee is given to the caller, we could sort the input
list according to `EntityLocation`, but that would likely only be worth
it for very large entity lists.
There is some duplication which could likely be improved, but I'd like
to leave that for a follow-up.
## Testing
The doc tests on `for_each_init` of `QueryParManyIter` and
`QueryParManyUniqueIter`.
# Objective
- Fixes#14348
- Fixes#14528
- Less complex (but also likely less performant) alternative to #14611
## Solution
- Add a `is_dense` field flag to `QueryIter` indicating whether it is
dense or not, that is whether it can perform dense iteration or not;
- Check this flag any time iteration over a query is performed.
---
It would be nice if someone could try benching this change to see if it
actually matters.
~Note that this not 100% ready for mergin, since there are a bunch of
safety comments on the use of the various `IS_DENSE` for checks that
still need to be updated.~ This is ready modulo benchmarks
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fixes#12966
## Solution
Renaming multi_threaded feature to match snake case
## Migration Guide
Bevy feature multi-threaded should be refered to multi_threaded from now
on.
# Objective
- bevy usually use `Parallel::scope` to collect items from `par_iter`,
but `scope` will be called with every satifified items. it will cause a
lot of unnecessary lookup.
## Solution
- similar to Rayon ,we introduce `for_each_init` for `par_iter` which
only be invoked when spawn a task for a group of items.
---
## Changelog
- added `for_each_init`
## Performance
`check_visibility ` in `many_foxes `

~40% performance gain in `check_visibility`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Allow parallel iteration over events, resolve#10766
## Solution
- Add `EventParIter` which works similarly to `QueryParIter`,
implementing a `for_each{_with_id}` operator.
I chose to not mirror `EventIteratorWithId` and instead implement both
operations on a single struct.
- Reuse `BatchingStrategy` from `QueryParIter`
## Changelog
- `EventReader` now supports parallel event iteration using
`par_read().for_each(|event| ...)`.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
Co-authored-by: Pablo Reinhardt <126117294+pablo-lua@users.noreply.github.com>
# Objective
- I daily drive nightly Rust when developing Bevy, so I notice when new
warnings are raised by `cargo check` and Clippy.
- `cargo +nightly clippy` raises a few of these new warnings.
## Solution
- Fix most warnings from `cargo +nightly clippy`
- I skipped the docs-related warnings because some were covered by
#12692.
- Use `Clone::clone_from` in applicable scenarios, which can sometimes
avoid an extra allocation.
- Implement `Default` for structs that have a `pub const fn new() ->
Self` method.
- Fix an occurrence where generic constraints were defined in both `<C:
Trait>` and `where C: Trait`.
- Removed generic constraints that were implied by the `Bundle` trait.
---
## Changelog
- `BatchingStrategy`, `NonGenericTypeCell`, and `GenericTypeCell` now
implement `Default`.
# Objective
Other than the exposed functions for reading matched tables and
archetypes, a `QueryState` does not actually need both internal Vecs for
storing matched archetypes and tables. In practice, it will only use one
of the two depending on if it uses dense or archetypal iteration.
Same vein as #12474. The goal is to reduce the memory overhead of using
queries, which Bevy itself, ecosystem plugins, and end users are already
fairly liberally using.
## Solution
Add `StorageId`, which is a union over `TableId` and `ArchetypeId`, and
store only one of the two at runtime. Read the slice as if it was one ID
depending on whether the query is dense or not.
This follows in the same vein as #5085; however, this one directly
impacts heap memory usage at runtime, while #5085 primarily targeted
transient pointers that might not actually exist at runtime.
---
## Changelog
Changed: `QueryState::matched_tables` now returns an iterator instead of
a reference to a slice.
Changed: `QueryState::matched_archetypes` now returns an iterator
instead of a reference to a slice.
## Migration Guide
`QueryState::matched_tables` and `QueryState::matched_archetypes` does
not return a reference to a slice, but an iterator instead. You may need
to use iterator combinators or collect them into a Vec to use it as a
slice.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Add the new `-Zcheck-cfg` checks to catch more warnings
- Fixes#12091
## Solution
- Create a new `cfg-check` to the CI that runs `cargo check -Zcheck-cfg
--workspace` using cargo nightly (and fails if there are warnings)
- Fix all warnings generated by the new check
---
## Changelog
- Remove all redundant imports
- Fix cfg wasm32 targets
- Add 3 dead code exceptions (should StandardColor be unused?)
- Convert ios_simulator to a feature (I'm not sure if this is the right
way to do it, but the check complained before)
## Migration Guide
No breaking changes
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Since #10776 split `WorldQuery` to `WorldQueryData` and
`WorldQueryFilter`, it should be clear that the query is actually
composed of two parts. It is not factually correct to call "query" only
the data part. Therefore I suggest to rename the `Q` parameter to `D` in
`Query` and related items.
As far as I know, there shouldn't be breaking changes from renaming
generic type parameters.
## Solution
I used a combination of rust-analyzer go to reference and `Ctrl-F`ing
various patterns to catch as many cases as possible. Hopefully I got
them all. Feel free to check if you're concerned of me having missed
some.
## Notes
This and #10779 have many lines in common, so merging one will cause a
lot of merge conflicts to the other.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
After #6547, `Query::for_each` has been capable of automatic
vectorization on certain queries, which is seeing a notable (>50% CPU
time improvements) for iteration. However, `Query::for_each` isn't
idiomatic Rust, and lacks the flexibility of iterator combinators.
Ideally, `Query::iter` and friends should be able to achieve the same
results. However, this does seem to blocked upstream
(rust-lang/rust#104914) by Rust's loop optimizations.
## Solution
This is an intermediate solution and refactor. This moves the
`Query::for_each` implementation onto the `Iterator::fold`
implementation for `QueryIter` instead. This should result in the same
automatic vectorization optimization on all `Iterator` functions that
internally use fold, including `Iterator::for_each`, `Iterator::count`,
etc.
With this, it should close the gap between the two completely.
Internally, this PR changes `Query::for_each` to use
`query.iter().for_each(..)` instead of the duplicated implementation.
Separately, the duplicate implementations of internal iteration (i.e.
`Query::par_for_each`) now use portions of the current `Query::for_each`
implementation factored out into their own functions.
This also massively cleans up our internal fragmentation of internal
iteration options, deduplicating the iteration code used in `for_each`
and `par_iter().for_each()`.
---
## Changelog
Changed: `Query::for_each`, `Query::for_each_mut`, `Query::for_each`,
and `Query::for_each_mut` have been moved to `QueryIter`'s
`Iterator::for_each` implementation, and still retains their performance
improvements over normal iteration. These APIs are deprecated in 0.13
and will be removed in 0.14.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fixes#7680
- This is an updated for https://github.com/bevyengine/bevy/pull/8899
which had the same objective but fell a long way behind the latest
changes
## Solution
The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter :
WorldQuery` have been added and some of the types and functions from
`WorldQuery` has been moved into them.
`ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`.
`WorldQueryFilter` is safe (as long as `WorldQuery` is implemented
safely).
`WorldQueryData` is unsafe - safely implementing it requires that
`Self::ReadOnly` is a readonly version of `Self` (this used to be a
safety requirement of `WorldQuery`)
The type parameters `Q` and `F` of `Query` must now implement
`WorldQueryData` and `WorldQueryFilter` respectively.
This makes it impossible to accidentally use a filter in the data
position or vice versa which was something that could lead to bugs.
~~Compile failure tests have been added to check this.~~
It was previously sometimes useful to use `Option<With<T>>` in the data
position. Use `Has<T>` instead in these cases.
The `WorldQuery` derive macro has been split into separate derive macros
for `WorldQueryData` and `WorldQueryFilter`.
Previously it was possible to derive both `WorldQuery` for a struct that
had a mixture of data and filter items. This would not work correctly in
some cases but could be a useful pattern in others. *This is no longer
possible.*
---
## Notes
- The changes outside of `bevy_ecs` are all changing type parameters to
the new types, updating the macro use, or replacing `Option<With<T>>`
with `Has<T>`.
- All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL`
so I moved it to `WorldQueryFilter` and
replaced all calls to it with `true`. That should be the only logic
change outside of the macro generation code.
- `Changed<T>` and `Added<T>` were being generated by a macro that I
have expanded. Happy to revert that if desired.
- The two derive macros share some functions for implementing
`WorldQuery` but the tidiest way I could find to implement them was to
give them a ton of arguments and ask clippy to ignore that.
## Changelog
### Changed
- Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which
now have separate derive macros. It is not possible to derive both for
the same type.
- `Query` now requires that the first type argument implements
`WorldQueryData` and the second implements `WorldQueryFilter`
## Migration Guide
- Update derives
```rust
// old
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA
}
#[derive(WorldQuery)]
struct QueryFilter {
_c: With<ComponentC>
}
// new
#[derive(WorldQueryData)]
#[world_query_data(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA,
}
#[derive(WorldQueryFilter)]
struct QueryFilter {
_c: With<ComponentC>
}
```
- Replace `Option<With<T>>` with `Has<T>`
```rust
/// old
fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>)
{
for (entity, has_a_option) in query.iter(){
let has_a:bool = has_a_option.is_some();
//todo!()
}
}
/// new
fn my_system(query: Query<(Entity, Has<ComponentA>)>)
{
for (entity, has_a) in query.iter(){
//todo!()
}
}
```
- Fix queries which had filters in the data position or vice versa.
```rust
// old
fn my_system(query: Query<(Entity, With<ComponentA>)>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Entity, With<ComponentA>>)
{
for entity in query.iter(){
//todo!()
}
}
// old
fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>)
{
for entity in query.iter(){
//todo!()
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
The default division for a `usize` rounds down which means the batch
sizes were too small when the `max_size` isn't exactly divisible by the
batch count.
## Solution
Changing the division to round up fixes this which can dramatically
improve performance when using `par_iter`.
I created a small example to proof this out and measured some results. I
don't know if it's worth committing this permanently so I left it out of
the PR for now.
```rust
use std::{thread, time::Duration};
use bevy::{
prelude::*,
window::{PresentMode, WindowPlugin},
};
fn main() {
App::new()
.add_plugins((DefaultPlugins.set(WindowPlugin {
primary_window: Some(Window {
present_mode: PresentMode::AutoNoVsync,
..default()
}),
..default()
}),))
.add_systems(Startup, spawn)
.add_systems(Update, update_counts)
.run();
}
#[derive(Component, Default, Debug, Clone, Reflect)]
pub struct Count(u32);
fn spawn(mut commands: Commands) {
// Worst case
let tasks = bevy::tasks::available_parallelism() * 5 - 1;
// Best case
// let tasks = bevy::tasks::available_parallelism() * 5 + 1;
for _ in 0..tasks {
commands.spawn(Count(0));
}
}
// changing the bounds of the text will cause a recomputation
fn update_counts(mut count_query: Query<&mut Count>) {
count_query.par_iter_mut().for_each(|mut count| {
count.0 += 1;
thread::sleep(Duration::from_millis(10))
});
}
```
## Results
I ran this four times, with and without the change, with best case
(should favour the old maths) and worst case (should favour the new
maths) task numbers.
### Worst case
Before the change the batches were 9 on each thread, plus the 5
remainder ran on one of the threads in addition. With the change its 10
on each thread apart from one which has 9. The results show a decrease
from ~140ms to ~100ms which matches what you would expect from the maths
(`10 * 10ms` vs `(9 + 4) * 10ms`).

### Best case
Before the change the batches were 10 on each thread, plus the 1
remainder ran on one of the threads in addition. With the change its 11
on each thread apart from one which has 5. The results slightly favour
the new change but are basically identical as the total time is
determined by the worse case which is `11 * 10ms` for both tests.
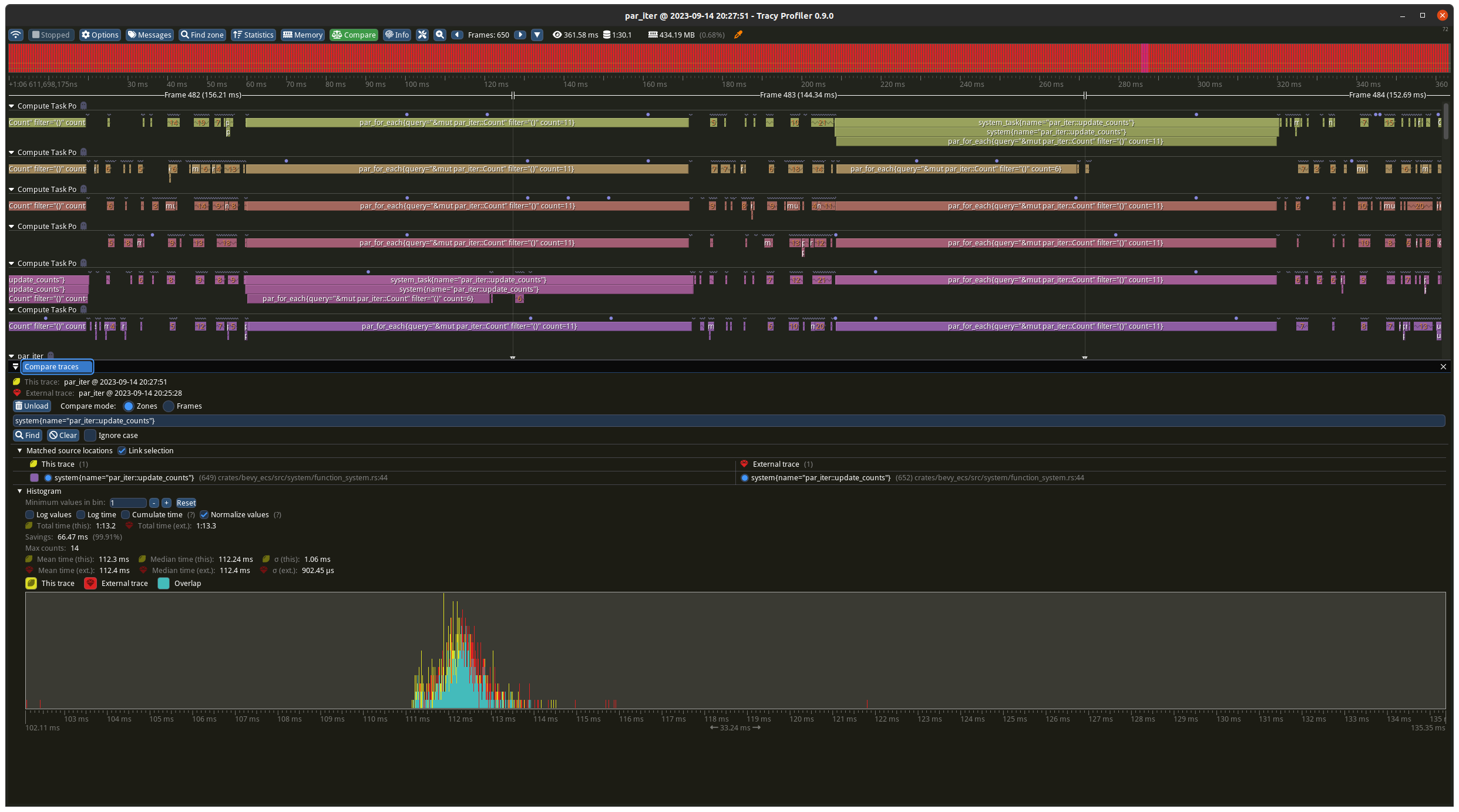
# Objective
The `QueryParIter::for_each_mut` function is required when doing
parallel iteration with mutable queries.
This results in an unfortunate stutter:
`query.par_iter_mut().par_for_each_mut()` ('mut' is repeated).
## Solution
- Make `for_each` compatible with mutable queries, and deprecate
`for_each_mut`. In order to prevent `for_each` from being called
multiple times in parallel, we take ownership of the QueryParIter.
---
## Changelog
- `QueryParIter::for_each` is now compatible with mutable queries.
`for_each_mut` has been deprecated as it is now redundant.
## Migration Guide
The method `QueryParIter::for_each_mut` has been deprecated and is no
longer functional. Use `for_each` instead, which now supports mutable
queries.
```rust
// Before:
query.par_iter_mut().for_each_mut(|x| ...);
// After:
query.par_iter_mut().for_each(|x| ...);
```
The method `QueryParIter::for_each` now takes ownership of the
`QueryParIter`, rather than taking a shared reference.
```rust
// Before:
let par_iter = my_query.par_iter().batching_strategy(my_batching_strategy);
par_iter.for_each(|x| {
// ...Do stuff with x...
par_iter.for_each(|y| {
// ...Do nested stuff with y...
});
});
// After:
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|x| {
// ...Do stuff with x...
my_query.par_iter().batching_strategy(my_batching_strategy).for_each(|y| {
// ...Do nested stuff with y...
});
});
```
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- The function `QueryParIter::for_each_unchecked` is a footgun: the only
ways to use it soundly can be done in safe code using `for_each` or
`for_each_mut`. See [this discussion on
discord](https://discord.com/channels/691052431525675048/749335865876021248/1118642977275924583).
## Solution
- Make `for_each_unchecked` private.
---
## Changelog
- Removed `QueryParIter::for_each_unchecked`. All use-cases of this
method were either unsound or doable in safe code using `for_each` or
`for_each_mut`.
## Migration Guide
The method `QueryParIter::for_each_unchecked` has been removed -- use
`for_each` or `for_each_mut` instead. If your use case can not be
achieved using either of these, then your code was likely unsound.
If you have a use-case for `for_each_unchecked` that you believe is
sound, please [open an
issue](https://github.com/bevyengine/bevy/issues/new/choose).
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
{kind=link}