# Objective
Fixes#4657
Example code that wasnt panic'ing before this PR (and so was unsound):
```rust
#[test]
#[should_panic = "error[B0001]"]
fn option_has_no_filter_with() {
fn sys(_1: Query<(Option<&A>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn any_of_has_no_filter_with() {
fn sys(_1: Query<(AnyOf<(&A, ())>, &mut B)>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
#[test]
#[should_panic = "error[B0001]"]
fn or_has_no_filter_with() {
fn sys(_1: Query<&mut B, Or<(With<A>, With<B>)>>, _2: Query<&mut B, Without<A>>) {}
let mut world = World::default();
run_system(&mut world, sys);
}
```
## Solution
- Only add the intersection of `with`/`without` accesses of all the elements in `Or/AnyOf` to the world query's `FilteredAccess<ComponentId>` instead of the union.
- `Option`'s fix can be thought of the same way since its basically `AnyOf<T, ()>` but its impl is just simpler as `()` has no `with`/`without` accesses
---
## Changelog
- `Or`/`AnyOf`/`Option` will now report more query conflicts in order to fix unsoundness
## Migration Guide
- If you are now getting query conflicts from `Or`/`AnyOf`/`Option` rip to you and ur welcome for it now being caught
# Objective
We have duplicated code between `QueryIter` and `QueryIterationCursor`. Reuse that code.
## Solution
- Reuse `QueryIterationCursor` inside `QueryIter`.
- Slim down `QueryIter` by removing the `&'w World`. It was only being used by the `size_hint` and `ExactSizeIterator` impls, which can use the QueryState and &Archetypes in the type already.
- Benchmark to make sure there is no significant regression.
Relevant benchmark results seem to show that there is no tangible difference between the two. Everything seems to be either identical or within a workable margin of error here.
```
group embed-cursor main
----- ------------ ----
fragmented_iter/base 1.00 387.4±19.70ns ? ?/sec 1.07 413.1±27.95ns ? ?/sec
many_maps_iter 1.00 27.3±0.22ms ? ?/sec 1.00 27.4±0.10ms ? ?/sec
simple_iter/base 1.00 13.8±0.07µs ? ?/sec 1.00 13.7±0.17µs ? ?/sec
simple_iter/sparse 1.00 61.9±0.37µs ? ?/sec 1.00 62.2±0.64µs ? ?/sec
simple_iter/system 1.00 13.7±0.34µs ? ?/sec 1.00 13.7±0.10µs ? ?/sec
sparse_fragmented_iter/base 1.00 11.0±0.54ns ? ?/sec 1.03 11.3±0.48ns ? ?/sec
world_query_iter/50000_entities_sparse 1.08 105.0±2.68µs ? ?/sec 1.00 97.5±2.18µs ? ?/sec
world_query_iter/50000_entities_table 1.00 27.3±0.13µs ? ?/sec 1.00 27.3±0.37µs ? ?/sec
```
# Objective
Quick followup to #4712.
While updating some [other PRs](https://github.com/bevyengine/bevy/pull/4218), I realized the `ReflectTraits` struct could be improved. The issue with the current implementation is that `ReflectTraits::get_xxx_impl(...)` returns just the _logic_ to the corresponding `Reflect` trait method, rather than the entire function.
This makes it slightly more annoying to manage since the variable names need to be consistent across files. For example, `get_partial_eq_impl` uses a `value` variable. But the name "value" isn't defined in the `get_partial_eq_impl` method, it's defined in three other methods in a completely separate file.
It's not likely to cause any bugs if we keep it as it is since differing variable names will probably just result in a compile error (except in very particular cases). But it would be useful to someone who wanted to edit/add/remove a method.
## Solution
Made `get_hash_impl`, `get_partial_eq_impl` and `get_serialize_impl` return the entire method implementation for `reflect_hash`, `reflect_partial_eq`, and `serializable`, respectively.
As a result of this, those three `Reflect` methods were also given default implementations. This was fairly simple to do since all three could just be made to return `None`.
---
## Changelog
* Small cleanup/refactor to `ReflectTraits` in `bevy_reflect_derive`
* Gave `Reflect::reflect_hash`, `Reflect::reflect_partial_eq`, and `Reflect::serializable` default implementations
# Objective
Support returning data out of with_children to enable the use case of changing the parent commands with data created inside the child builder.
## Solution
Change the with_children closure to return T.
Closes https://github.com/bevyengine/bevy/pull/2817.
---
## Changelog
`BuildChildren::add_children` was added with the ability to return data to use outside the closure (for spawning a new child builder on a returned entity for example).
# Objective
Fixes#4751, zld link error.
## Solution
- Change the `zld` file path in the example to the one homebrew installs to by default, `/usr/local/bin/zld`.
# Objective
- We do a lot of function pointer calls in a hot loop (clearing entities in render). This is slow, since calling function pointers cannot be optimised out. We can avoid that in the cases where the function call is a no-op.
- Alternative to https://github.com/bevyengine/bevy/pull/2897
- On my machine, in `many_cubes`, this reduces dropping time from ~150μs to ~80μs.
## Solution
- Make `drop` in `BlobVec` an `Option`, recording whether the given drop impl is required or not.
- Note that this does add branching in some cases - we could consider splitting this into two fields, i.e. unconditionally call the `drop` fn pointer.
- My intuition of how often types stored in `World` should have non-trivial drops makes me think that would be slower, however.
N.B. Even once this lands, we should still test having a 'drop_multiple' variant - for types with a real `Drop` impl, the current implementation is definitely optimal.
# Objective
- Part of the splitting process of #3692.
## Solution
- Document `keyboard.rs` inside of `bevy_input`.
Co-authored-by: KDecay <KDecayMusic@protonmail.com>
# Objective
Partially addresses #3594.
## Solution
This adds basic benchmarks for `List`, `Map`, and `Struct` implementors, both concrete (`Vec`, `HashMap`, and defined struct types) and dynamic (`DynamicList`, `DynamicMap` and `DynamicStruct`).
A few insights from the benchmarks (all measurements are local on my machine):
- Applying a list with many elements to a list with no elements is slower than applying to a list of the same length:
- 3-4x slower when applying to a `Vec`
- 5-6x slower when applying to a `DynamicList`
I suspect this could be improved by `reserve()`ing the correct length up front, but haven't tested.
- Applying a `DynamicMap` to another `Map` is linear in the number of elements, but applying a `HashMap` seems to be at least quadratic. No intuition on this one.
- Applying like structs (concrete -> concrete, `DynamicStruct` -> `DynamicStruct`) seems to be faster than applying unlike structs.
# Objective
- Transform propogation could stack overflow when there was a cycle.
- I think https://github.com/bevyengine/bevy/pull/4203 would use all available memory.
## Solution
- Make sure that the child entity's `Parent`s are their parents.
This is also required for when parallelising, although as noted in the comment, the naïve solution would be UB.
(The best way to fix this would probably be an `&mut UnsafeCell<T>` `WorldQuery`, or wrapper type with the same effect)
# Objective
`bevy_ptr` works just fine without `std`. Mark it as `no_std`. This should generally be useful for non-bevy use cases, but it also marginally speeds up compilation by allowing the crate to compile without loading the std-lib.
## Solution
Replace `std` with `core`. Added `#![no_std]` to the crate and to the crate's tags.
Also added a missing `#![warn(missing_docs)]` that the other crates have.
# Objective
- Fixes#4456
## Solution
- Removed the `near` and `far` fields from the camera and the views.
---
## Changelog
- Removed the `near` and `far` fields from the camera and the views.
- Removed the `ClusterFarZMode::CameraFarPlane` far z mode.
## Migration Guide
- Cameras no longer accept near and far values during initialization
- `ClusterFarZMode::Constant` should be used with the far value instead of `ClusterFarZMode::CameraFarPlane`
# Objective
Provide a starting point for #3951, or a partial solution.
Providing a few comment blocks to discuss, and hopefully find better one in the process.
## Solution
Since I am pretty new to pretty much anything in this context, I figured I'd just start with a draft for some file level doc blocks. For some of them I found more relevant details (or at least things I considered interessting), for some others there is less.
## Changelog
- Moved some existing comments from main() functions in the 2d examples to the file header level
- Wrote some more comment blocks for most other 2d examples
TODO:
- [x] 2d/sprite_sheet, wasnt able to come up with something good yet
- [x] all other example groups...
Also: Please let me know if the commit style is okay, or to verbose. I could certainly squash these things, or add more details if needed.
I also hope its okay to raise this PR this early, with just a few files changed. Took me long enough and I dont wanted to let it go to waste because I lost motivation to do the whole thing. Additionally I am somewhat uncertain over the style and contents of the commets. So let me know what you thing please.
# Objective
- When Miri is failing, it can be very slow to do so
<img width="1397" alt="Screenshot 2022-05-14 at 03 05 40" src="https://user-images.githubusercontent.com/8672791/168405111-c5e27d63-7a5a-4a5e-b679-abbeeb3201d2.png">
## Solution
- Set the timeout for Miri to 60 minutes (it's 6 hours by default). It runs in around 10 minutes when successful
- Fix cache key as it was set to the same as another task that doesn't build with the same parameters
# Objective
`bevy_ecs` assumes that `u32 as usize` is a lossless operation and in a few cases relies on this for soundness and correctness. The only platforms that Rust compiles to where this invariant is broken are 16-bit systems.
A very clear example of this behavior is in the SparseSetIndex impl for Entity, where it converts a u32 into a usize to act as an index. If usize is 16-bit, the conversion will overflow and provide the caller with the wrong index. This can easily result in previously unforseen aliased mutable borrows (i.e. Query::get_many_mut).
## Solution
Explicitly fail compilation on 16-bit platforms instead of introducing UB.
Properly supporting 16-bit systems will likely need a workable use case first.
---
## Changelog
Removed: Ability to compile `bevy_ecs` on 16-bit platforms.
## Migration Guide
`bevy_ecs` will now explicitly fail to compile on 16-bit platforms. If this is required, there is currently no alternative. Please file an issue (https://github.com/bevyengine/bevy/issues) to help detail your use case.
# Objective
> ℹ️ **Note**: This is a rebased version of #2383. A large portion of it has not been touched (only a few minor changes) so that any additional discussion may happen here. All credit should go to @NathanSWard for their work on the original PR.
- Currently reflection is not supported for arrays.
- Fixes#1213
## Solution
* Implement reflection for arrays via the `Array` trait.
* Note, `Array` is different from `List` in the way that you cannot push elements onto an array as they are statically sized.
* Now `List` is defined as a sub-trait of `Array`.
---
## Changelog
* Added the `Array` reflection trait
* Allows arrays up to length 32 to be reflected via the `Array` trait
## Migration Guide
* The `List` trait now has the `Array` supertrait. This means that `clone_dynamic` will need to specify which version to use:
```rust
// Before
let cloned = my_list.clone_dynamic();
// After
let cloned = List::clone_dynamic(&my_list);
```
* All implementers of `List` will now need to implement `Array` (this mostly involves moving the existing methods to the `Array` impl)
Co-authored-by: NathanW <nathansward@comcast.net>
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
- It's pretty common to want to check if an EventReader has received one or multiple events while also needing to consume the iterator to "clear" the EventReader.
- The current approach is to do something like `events.iter().count() > 0` or `events.iter().last().is_some()`. It's not immediately obvious that the purpose of that is to consume the events and check if there were any events. My solution doesn't really solve that part, but it encapsulates the pattern.
## Solution
- Add a `.clear()` method that consumes the iterator.
- It takes the EventReader by value to make sure it isn't used again after it has been called.
---
## Migration Guide
Not a breaking change, but if you ever found yourself in a situation where you needed to consume the EventReader and check if there was any events you can now use
```rust
fn system(events: EventReader<MyEvent>) {
if !events.is_empty {
events.clear();
// Process the fact that one or more event was received
}
}
```
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
# Objective
`Query::par_for_each` and it's variants do not show up when profiling using `tracy` or other profilers. Failing to show the impact of changing batch size, the overhead of scheduling tasks, overall thread utilization, etc. other than the effect on the surrounding system.
## Solution
Add a child span that is entered on every spawned task.
Example view of the results in `tracy` using a modified `parallel_query`:
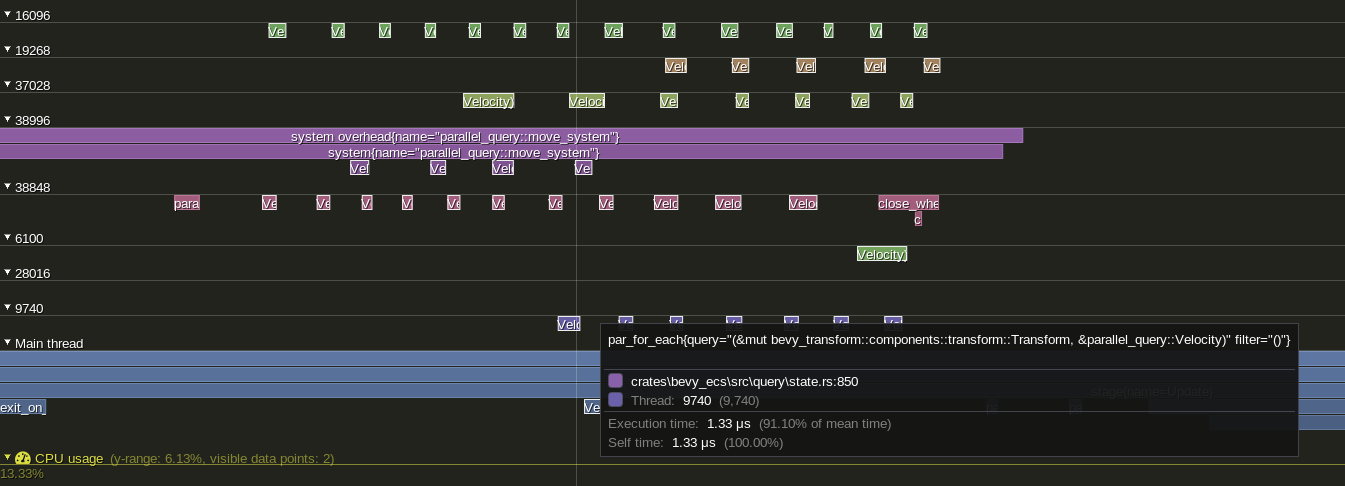
---
## Changelog
Added: `tracing` spans for `Query::par_for_each` and its variants. Spans should now be visible for all
# Objective
The `bevy_reflect_derive` crate is not the cleanest or easiest to follow/maintain. The `lib.rs` file is especially difficult with over 1000 lines of code written in a confusing order. This is just a result of growth within the crate and it would be nice to clean it up for future work.
## Solution
Split `bevy_reflect_derive` into many more submodules. The submodules include:
* `container_attributes` - Code relating to container attributes
* `derive_data` - Code relating to reflection-based derive metadata
* `field_attributes` - Code relating to field attributes
* `impls` - Code containing actual reflection implementations
* `reflect_value` - Code relating to reflection-based value metadata
* `registration` - Code relating to type registration
* `utility` - General-purpose utility functions
This leaves the `lib.rs` file to contain only the public macros, making it much easier to digest (and fewer than 200 lines).
By breaking up the code into smaller modules, we make it easier for future contributors to find the code they're looking for or identify which module best fits their own additions.
### Metadata Structs
This cleanup also adds two big metadata structs: `ReflectFieldAttr` and `ReflectDeriveData`. The former is used to store all attributes for a struct field (if any). The latter is used to store all metadata for struct-based derive inputs.
Both significantly reduce code duplication and make editing these macros much simpler. The tradeoff is that we may collect more metadata than needed. However, this is usually a small thing (such as checking for attributes when they're not really needed or creating a `ReflectFieldAttr` for every field regardless of whether they actually have an attribute).
We could try to remove these tradeoffs and squeeze some more performance out, but doing so might come at the cost of developer experience. Personally, I think it's much nicer to create a `ReflectFieldAttr` for every field since it means I don't have to do two `Option` checks. Others may disagree, though, and so we can discuss changing this either in this PR or in a future one.
### Out of Scope
_Some_ documentation has been added or improved, but ultimately good docs are probably best saved for a dedicated PR.
## 🔍 Focus Points (for reviewers)
I know it's a lot to sift through, so here is a list of **key points for reviewers**:
- The following files contain code that was mostly just relocated:
- `reflect_value.rs`
- `registration.rs`
- `container_attributes.rs` was also mostly moved but features some general cleanup (reducing nesting, removing hardcoded strings, etc.) and lots of doc comments
- Most impl logic was moved from `lib.rs` to `impls.rs`, but they have been significantly modified to use the new `ReflectDeriveData` metadata struct in order to reduce duplication.
- `derive_data.rs` and `field_attributes.rs` contain almost entirely new code and should probably be given the most attention.
- Likewise, `from_reflect.rs` saw major changes using `ReflectDeriveData` so it should also be given focus.
- There was no change to the `lib.rs` exports so the end-user API should be the same.
## Prior Work
This task was initially tackled by @NathanSWard in #2377 (which was closed in favor of this PR), so hats off to them for beating me to the punch by nearly a year!
---
## Changelog
* **[INTERNAL]** Split `bevy_reflect_derive` into smaller submodules
* **[INTERNAL]** Add `ReflectFieldAttr`
* **[INTERNAL]** Add `ReflectDeriveData`
* Add `BevyManifest::get_path_direct()` method (`bevy_macro_utils`)
Co-authored-by: MrGVSV <49806985+MrGVSV@users.noreply.github.com>
# Objective
The frame marker event was emitted in the loop of presenting all the windows. This would mark the frame as finished multiple times if more than one window is used.
## Solution
Move the frame marker to after the `for`-loop, so that it gets executed only once.
# Objective
- The code in `events.rs` was a bit messy. There was lots of duplication between `EventReader` and `ManualEventReader`, and the state management code is not needed.
## Solution
- Clean it up.
## Future work
Should we remove the type parameter from `ManualEventReader`?
It doesn't have any meaning outside of its source `Events`. But there's no real reason why it needs to have a type parameter - it's just plain data. I didn't remove it yet to keep the type safety in some of the users of it (primarily related to `&mut World` usage)
{kind=link}
{kind=link}
{kind=link}