# Objective
Fixes#12752. Fixes#12750. Document the runtime complexity of all of
the `O(1)` operations on the individual APIs.
## Solution
* Mirror `Query::contains` onto `QueryState::contains`
* Make `QueryState::as_nop` pub(crate)
* Make `NopWorldQuery` pub(crate)
* Document all of the O(1) operations on Query and QueryState.
# Objective
I'm reading through the ecs query code for the first time, and updating
the docs:
- fixed some typos
- added some docs about things I was confused about (in particular what
the difference between `matches_component_set` and
`update_component_access` was)
# Objective
`QueryState::archetype_component_access` is only really ever used to
extend `SystemMeta`'s. It can be removed to save some memory for every
`Query` in an app.
## Solution
* Remove it.
* Have `new_archetype` pass in a `&mut Access<ArchetypeComponentId>`
instead and pull it from `SystemMeta` directly.
* Split `QueryState::new` from `QueryState::new_with_access` and a
common `QueryState::new_uninitialized`.
* Split `new_archetype` into an internal and public version. Call the
internal version in `update_archetypes`.
This should make it faster to construct new QueryStates, and by proxy
lenses and joins as well.
`matched_tables` also similarly is only used to deduplicate inserting
into `matched_table_ids`. If we can find another efficient way to do so,
it might also be worth removing.
The [generated
assembly](https://github.com/james7132/bevy_asm_tests/compare/main...remove-query-state-archetype-component-access#diff-496530101f0b16e495b7e9b77c0e906ae3068c8adb69ed36c92d5a1be5a9efbe)
reflects this well, with all of the access related updates in
`QueryState` being removed.
---
## Changelog
Removed: `QueryState::archetype_component_access`.
Changed: `QueryState::new_archetype` now takes a `&mut
Access<ArchetypeComponentId>` argument, which will be updated with the
new accesses.
Changed: `QueryState::update_archetype_component_access` now takes a
`&mut Access<ArchetypeComponentId>` argument, which will be updated with
the new accesses.
## Migration Guide
TODO
# Objective
Improve code quality involving fixedbitset.
## Solution
Update to fixedbitset 0.5. Use the new `grow_and_insert` function
instead of `grow` and `insert` functions separately.
This should also speed up most of the set operations involving
fixedbitset. They should be ~2x faster, but testing this against the
stress tests seems to show little to no difference. The multithreaded
executor doesn't seem to be all that much faster in many_cubes and
many_foxes. These use cases are likely dominated by other operations or
the bitsets aren't big enough to make them the bottleneck.
This introduces a duplicate dependency due to petgraph and wgpu, but the
former may take some time to update.
## Changelog
Removed: `Access::grow`
## Migration Guide
`Access::grow` has been removed. It's no longer needed. Remove all
references to it.
# Objective
- Add a way to combine 2 queries together in a similar way to
`Query::transmute_lens`
- Fixes#1658
## Solution
- Use a similar method to query transmute, but take the intersection of
matched archetypes between the 2 queries and the union of the accesses
to create the new underlying QueryState.
---
## Changelog
- Add query joins
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fix#10876. Improve `Query` and `QueryState`'s docs.
## Solution
Explicitly denote that Query is always guaranteed to return results from
all matching entities once and only once for each entity, and that
iteration order is not guaranteed in any way.
# Objective
- Add the new `-Zcheck-cfg` checks to catch more warnings
- Fixes#12091
## Solution
- Create a new `cfg-check` to the CI that runs `cargo check -Zcheck-cfg
--workspace` using cargo nightly (and fails if there are warnings)
- Fix all warnings generated by the new check
---
## Changelog
- Remove all redundant imports
- Fix cfg wasm32 targets
- Add 3 dead code exceptions (should StandardColor be unused?)
- Convert ios_simulator to a feature (I'm not sure if this is the right
way to do it, but the check complained before)
## Migration Guide
No breaking changes
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Part of #11590
- Fix `unsafe_op_in_unsafe_fn` for trivial cases in bevy_ecs
## Solution
Fix `unsafe_op_in_unsafe_fn` in bevy_ecs for trivial cases, i.e., add an
`unsafe` block when the safety comment already exists or add a comment
like "The invariants are uphold by the caller".
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
We deprecated quite a few APIs in 0.13. 0.13 has shipped already. It
should be OK to remove them in 0.14's release. Fixes#4059. Fixes#9011.
## Solution
Remove them.
# Objective
It would be useful to be able to inspect a `QueryState`'s accesses so we
can detect when the data it accesses changes without having to iterate
it. However there are two things preventing this:
* These accesses are unnecessarily encapsulated.
* `Has<T>` indirectly accesses `T`, but does not register it.
## Solution
* Expose accesses and matches used by `QueryState`.
* Add the notion of "archetypal" accesses, which are not accessed
directly, but whose presence in an archetype affects a query result.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- (Partially) Fixes#9904
- Acts on #9910
## Solution
- Deprecated the relevant methods from `Query`, cascading changes as
required across Bevy.
---
## Changelog
- Deprecated `QueryState::get_component_unchecked_mut` method
- Deprecated `Query::get_component` method
- Deprecated `Query::get_component_mut` method
- Deprecated `Query::component` method
- Deprecated `Query::component_mut` method
- Deprecated `Query::get_component_unchecked_mut` method
## Migration Guide
### `QueryState::get_component_unchecked_mut`
Use `QueryState::get_unchecked_manual` and select for the exact
component based on the structure of the exact query as required.
### `Query::(get_)component(_unchecked)(_mut)`
Use `Query::get` and select for the exact component based on the
structure of the exact query as required.
- For mutable access (`_mut`), use `Query::get_mut`
- For unchecked access (`_unchecked`), use `Query::get_unchecked`
- For panic variants (non-`get_`), add `.unwrap()`
## Notes
- `QueryComponentError` can be removed once these deprecated methods are
also removed. Due to an interaction with `thiserror`'s derive macro, it
is not marked as deprecated.
# Objective
Fixes#11311
## Solution
Adds an example to the documentation for `par_iter_mut`. I didn't add
any examples to `par_iter`, because I couldn't think of a good example
and I figure users can infer that `par_iter` and `par_iter_mut` are
similar.
# Objective
Expand the existing `Query` API to support more dynamic use cases i.e.
scripting.
## Prior Art
- #6390
- #8308
- #10037
## Solution
- Create a `QueryBuilder` with runtime methods to define the set of
component accesses for a built query.
- Create new `WorldQueryData` implementations `FilteredEntityMut` and
`FilteredEntityRef` as variants of `EntityMut` and `EntityRef` that
provide run time checked access to the components included in a given
query.
- Add new methods to `Query` to create "query lens" with a subset of the
access of the initial query.
### Query Builder
The `QueryBuilder` API allows you to define a query at runtime. At it's
most basic use it will simply create a query with the corresponding type
signature:
```rust
let query = QueryBuilder::<Entity, With<A>>::new(&mut world).build();
// is equivalent to
let query = QueryState::<Entity, With<A>>::new(&mut world);
```
Before calling `.build()` you also have the opportunity to add
additional accesses and filters. Here is a simple example where we add
additional filter terms:
```rust
let entity_a = world.spawn((A(0), B(0))).id();
let entity_b = world.spawn((A(0), C(0))).id();
let mut query_a = QueryBuilder::<Entity>::new(&mut world)
.with::<A>()
.without::<C>()
.build();
assert_eq!(entity_a, query_a.single(&world));
```
This alone is useful in that allows you to decide which archetypes your
query will match at runtime. However it is also very limited, consider a
case like the following:
```rust
let query_a = QueryBuilder::<&A>::new(&mut world)
// Add an additional access
.data::<&B>()
.build();
```
This will grant the query an additional read access to component B
however we have no way of accessing the data while iterating as the type
signature still only includes &A. For an even more concrete example of
this consider dynamic components:
```rust
let query_a = QueryBuilder::<Entity>::new(&mut world)
// Adding a filter is easy since it doesn't need be read later
.with_id(component_id_a)
// How do I access the data of this component?
.ref_id(component_id_b)
.build();
```
With this in mind the `QueryBuilder` API seems somewhat incomplete by
itself, we need some way method of accessing the components dynamically.
So here's one:
### Query Transmutation
If the problem is not having the component in the type signature why not
just add it? This PR also adds transmute methods to `QueryBuilder` and
`QueryState`. Here's a simple example:
```rust
world.spawn(A(0));
world.spawn((A(1), B(0)));
let mut query = QueryBuilder::<()>::new(&mut world)
.with::<B>()
.transmute::<&A>()
.build();
query.iter(&world).for_each(|a| assert_eq!(a.0, 1));
```
The `QueryState` and `QueryBuilder` transmute methods look quite similar
but are different in one respect. Transmuting a builder will always
succeed as it will just add the additional accesses needed for the new
terms if they weren't already included. Transmuting a `QueryState` will
panic in the case that the new type signature would give it access it
didn't already have, for example:
```rust
let query = QueryState::<&A, Option<&B>>::new(&mut world);
/// This is fine, the access for Option<&A> is less restrictive than &A
query.transmute::<Option<&A>>(&world);
/// Oh no, this would allow access to &B on entities that might not have it, so it panics
query.transmute::<&B>(&world);
/// This is right out
query.transmute::<&C>(&world);
```
This is quite an appealing API to also have available on `Query` however
it does pose one additional wrinkle: In order to to change the iterator
we need to create a new `QueryState` to back it. `Query` doesn't own
it's own state though, it just borrows it, so we need a place to borrow
it from. This is why `QueryLens` exists, it is a place to store the new
state so it can be borrowed when you call `.query()` leaving you with an
API like this:
```rust
fn function_that_takes_a_query(query: &Query<&A>) {
// ...
}
fn system(query: Query<(&A, &B)>) {
let lens = query.transmute_lens::<&A>();
let q = lens.query();
function_that_takes_a_query(&q);
}
```
Now you may be thinking: Hey, wait a second, you introduced the problem
with dynamic components and then described a solution that only works
for static components! Ok, you got me, I guess we need a bit more:
### Filtered Entity References
Currently the only way you can access dynamic components on entities
through a query is with either `EntityMut` or `EntityRef`, however these
can access all components and so conflict with all other accesses. This
PR introduces `FilteredEntityMut` and `FilteredEntityRef` as
alternatives that have additional runtime checking to prevent accessing
components that you shouldn't. This way you can build a query with a
`QueryBuilder` and actually access the components you asked for:
```rust
let mut query = QueryBuilder::<FilteredEntityRef>::new(&mut world)
.ref_id(component_id_a)
.with(component_id_b)
.build();
let entity_ref = query.single(&world);
// Returns Some(Ptr) as we have that component and are allowed to read it
let a = entity_ref.get_by_id(component_id_a);
// Will return None even though the entity does have the component, as we are not allowed to read it
let b = entity_ref.get_by_id(component_id_b);
```
For the most part these new structs have the exact same methods as their
non-filtered equivalents.
Putting all of this together we can do some truly dynamic ECS queries,
check out the `dynamic` example to see it in action:
```
Commands:
comp, c Create new components
spawn, s Spawn entities
query, q Query for entities
Enter a command with no parameters for usage.
> c A, B, C, Data 4
Component A created with id: 0
Component B created with id: 1
Component C created with id: 2
Component Data created with id: 3
> s A, B, Data 1
Entity spawned with id: 0v0
> s A, C, Data 0
Entity spawned with id: 1v0
> q &Data
0v0: Data: [1, 0, 0, 0]
1v0: Data: [0, 0, 0, 0]
> q B, &mut Data
0v0: Data: [2, 1, 1, 1]
> q B || C, &Data
0v0: Data: [2, 1, 1, 1]
1v0: Data: [0, 0, 0, 0]
```
## Changelog
- Add new `transmute_lens` methods to `Query`.
- Add new types `QueryBuilder`, `FilteredEntityMut`, `FilteredEntityRef`
and `QueryLens`
- `update_archetype_component_access` has been removed, archetype
component accesses are now determined by the accesses set in
`update_component_access`
- Added method `set_access` to `WorldQuery`, this is called before
`update_component_access` for queries that have a restricted set of
accesses, such as those built by `QueryBuilder` or `QueryLens`. This is
primarily used by the `FilteredEntity*` variants and has an empty trait
implementation.
- Added method `get_state` to `WorldQuery` as a fallible version of
`init_state` when you don't have `&mut World` access.
## Future Work
Improve performance of `FilteredEntityMut` and `FilteredEntityRef`,
currently they have to determine the accesses a query has in a given
archetype during iteration which is far from ideal, especially since we
already did the work when matching the archetype in the first place. To
avoid making more internal API changes I have left it out of this PR.
---------
Co-authored-by: Mike Hsu <mike.hsu@gmail.com>
# Objective
There are a lot of doctests that are `ignore`d for no documented reason.
And that should be fixed.
## Solution
I searched the bevy repo with the regex ` ```[a-z,]*ignore ` in order to
find all `ignore`d doctests. For each one of the `ignore`d doctests, I
did the following steps:
1. Attempt to remove the `ignored` attribute while still passing the
test. I did this by adding hidden dummy structs and imports.
2. If step 1 doesn't work, attempt to replace the `ignored` attribute
with the `no_run` attribute while still passing the test.
3. If step 2 doesn't work, keep the `ignored` attribute but add
documentation for why the `ignored` attribute was added.
---------
Co-authored-by: François <mockersf@gmail.com>
# Objective
Fix ci hang, so we can merge pr's again.
## Solution
- switch ppa action to use mesa stable versions
https://launchpad.net/~kisak/+archive/ubuntu/turtle
- use commit from #11123
---------
Co-authored-by: Stepan Koltsov <stepan.koltsov@gmail.com>
# Objective
The definition of several `QueryState` methods use unnecessary explicit
lifetimes, which adds to visual noise.
## Solution
Elide the lifetimes.
# Objective
Since #10776 split `WorldQuery` to `WorldQueryData` and
`WorldQueryFilter`, it should be clear that the query is actually
composed of two parts. It is not factually correct to call "query" only
the data part. Therefore I suggest to rename the `Q` parameter to `D` in
`Query` and related items.
As far as I know, there shouldn't be breaking changes from renaming
generic type parameters.
## Solution
I used a combination of rust-analyzer go to reference and `Ctrl-F`ing
various patterns to catch as many cases as possible. Hopefully I got
them all. Feel free to check if you're concerned of me having missed
some.
## Notes
This and #10779 have many lines in common, so merging one will cause a
lot of merge conflicts to the other.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fixes#10806
## Solution
Replaced `new` and `index` methods for both `TableRow` and `TableId`
with `from_*` and `as_*` methods. These remove the need to perform
casting at call sites, reducing the total number of casts in the Bevy
codebase. Within these methods, an appropriate `debug_assertion` ensures
the cast will behave in an expected manner (no wrapping, etc.). I am
using a `debug_assertion` instead of an `assert` to reduce any possible
runtime overhead, however minimal. This choice is something I am open to
changing (or leaving up to another PR) if anyone has any strong
arguments for it.
---
## Changelog
- `ComponentSparseSet::sparse` stores a `TableRow` instead of a `u32`
(private change)
- Replaced `TableRow::new` and `TableRow::index` methods with
`TableRow::from_*` and `TableRow::as_*`, with `debug_assertions`
protecting any internal casting.
- Replaced `TableId::new` and `TableId::index` methods with
`TableId::from_*` and `TableId::as_*`, with `debug_assertions`
protecting any internal casting.
- All `TableId` methods are now `const`
## Migration Guide
- `TableRow::new` -> `TableRow::from_usize`
- `TableRow::index` -> `TableRow::as_usize`
- `TableId::new` -> `TableId::from_usize`
- `TableId::index` -> `TableId::as_usize`
---
## Notes
I have chosen to remove the `index` and `new` methods for the following
chain of reasoning:
- Across the codebase, `new` was called with a mixture of `u32` and
`usize` values. Likewise for `index`.
- Choosing `new` to either be `usize` or `u32` would break half of these
call-sites, requiring `as` casting at the site.
- Adding a second method `new_u32` or `new_usize` avoids the above, bu
looks visually inconsistent.
- Therefore, they should be replaced with `from_*` and `as_*` methods
instead.
Worth noting is that by updating `ComponentSparseSet`, there are now
zero instances of interacting with the inner value of `TableRow` as a
`u32`, it is exclusively used as a `usize` value (due to interactions
with methods like `len` and slice indexing). I have left the `as_u32`
and `from_u32` methods as the "proper" constructors/getters.
# Objective
Resolves Issue #10772.
## Solution
Added the deprecated warning for QueryState::for_each_unchecked, as
noted in the comments of PR #6773.
Followed the wording in the deprecation messages for `for_each` and
`for_each_mut`
# Objective
After #6547, `Query::for_each` has been capable of automatic
vectorization on certain queries, which is seeing a notable (>50% CPU
time improvements) for iteration. However, `Query::for_each` isn't
idiomatic Rust, and lacks the flexibility of iterator combinators.
Ideally, `Query::iter` and friends should be able to achieve the same
results. However, this does seem to blocked upstream
(rust-lang/rust#104914) by Rust's loop optimizations.
## Solution
This is an intermediate solution and refactor. This moves the
`Query::for_each` implementation onto the `Iterator::fold`
implementation for `QueryIter` instead. This should result in the same
automatic vectorization optimization on all `Iterator` functions that
internally use fold, including `Iterator::for_each`, `Iterator::count`,
etc.
With this, it should close the gap between the two completely.
Internally, this PR changes `Query::for_each` to use
`query.iter().for_each(..)` instead of the duplicated implementation.
Separately, the duplicate implementations of internal iteration (i.e.
`Query::par_for_each`) now use portions of the current `Query::for_each`
implementation factored out into their own functions.
This also massively cleans up our internal fragmentation of internal
iteration options, deduplicating the iteration code used in `for_each`
and `par_iter().for_each()`.
---
## Changelog
Changed: `Query::for_each`, `Query::for_each_mut`, `Query::for_each`,
and `Query::for_each_mut` have been moved to `QueryIter`'s
`Iterator::for_each` implementation, and still retains their performance
improvements over normal iteration. These APIs are deprecated in 0.13
and will be removed in 0.14.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Shorten paths by removing unnecessary prefixes
## Solution
- Remove the prefixes from many paths which do not need them. Finding
the paths was done automatically using built-in refactoring tools in
Jetbrains RustRover.
# Objective
- Fixes#7680
- This is an updated for https://github.com/bevyengine/bevy/pull/8899
which had the same objective but fell a long way behind the latest
changes
## Solution
The traits `WorldQueryData : WorldQuery` and `WorldQueryFilter :
WorldQuery` have been added and some of the types and functions from
`WorldQuery` has been moved into them.
`ReadOnlyWorldQuery` has been replaced with `ReadOnlyWorldQueryData`.
`WorldQueryFilter` is safe (as long as `WorldQuery` is implemented
safely).
`WorldQueryData` is unsafe - safely implementing it requires that
`Self::ReadOnly` is a readonly version of `Self` (this used to be a
safety requirement of `WorldQuery`)
The type parameters `Q` and `F` of `Query` must now implement
`WorldQueryData` and `WorldQueryFilter` respectively.
This makes it impossible to accidentally use a filter in the data
position or vice versa which was something that could lead to bugs.
~~Compile failure tests have been added to check this.~~
It was previously sometimes useful to use `Option<With<T>>` in the data
position. Use `Has<T>` instead in these cases.
The `WorldQuery` derive macro has been split into separate derive macros
for `WorldQueryData` and `WorldQueryFilter`.
Previously it was possible to derive both `WorldQuery` for a struct that
had a mixture of data and filter items. This would not work correctly in
some cases but could be a useful pattern in others. *This is no longer
possible.*
---
## Notes
- The changes outside of `bevy_ecs` are all changing type parameters to
the new types, updating the macro use, or replacing `Option<With<T>>`
with `Has<T>`.
- All `WorldQueryData` types always returned `true` for `IS_ARCHETYPAL`
so I moved it to `WorldQueryFilter` and
replaced all calls to it with `true`. That should be the only logic
change outside of the macro generation code.
- `Changed<T>` and `Added<T>` were being generated by a macro that I
have expanded. Happy to revert that if desired.
- The two derive macros share some functions for implementing
`WorldQuery` but the tidiest way I could find to implement them was to
give them a ton of arguments and ask clippy to ignore that.
## Changelog
### Changed
- Split `WorldQuery` into `WorldQueryData` and `WorldQueryFilter` which
now have separate derive macros. It is not possible to derive both for
the same type.
- `Query` now requires that the first type argument implements
`WorldQueryData` and the second implements `WorldQueryFilter`
## Migration Guide
- Update derives
```rust
// old
#[derive(WorldQuery)]
#[world_query(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA
}
#[derive(WorldQuery)]
struct QueryFilter {
_c: With<ComponentC>
}
// new
#[derive(WorldQueryData)]
#[world_query_data(mutable, derive(Debug))]
struct CustomQuery {
entity: Entity,
a: &'static mut ComponentA,
}
#[derive(WorldQueryFilter)]
struct QueryFilter {
_c: With<ComponentC>
}
```
- Replace `Option<With<T>>` with `Has<T>`
```rust
/// old
fn my_system(query: Query<(Entity, Option<With<ComponentA>>)>)
{
for (entity, has_a_option) in query.iter(){
let has_a:bool = has_a_option.is_some();
//todo!()
}
}
/// new
fn my_system(query: Query<(Entity, Has<ComponentA>)>)
{
for (entity, has_a) in query.iter(){
//todo!()
}
}
```
- Fix queries which had filters in the data position or vice versa.
```rust
// old
fn my_system(query: Query<(Entity, With<ComponentA>)>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Entity, With<ComponentA>>)
{
for entity in query.iter(){
//todo!()
}
}
// old
fn my_system(query: Query<AnyOf<(&ComponentA, With<ComponentB>)>>)
{
for (entity, _) in query.iter(){
//todo!()
}
}
// new
fn my_system(query: Query<Option<&ComponentA>, Or<(With<ComponentA>, With<ComponentB>)>>)
{
for entity in query.iter(){
//todo!()
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Objective
---------
- Since #6742, It is not possible to build an `ArchetypeId` from a
`ArchetypeGeneration`
- This was useful to 3rd party crate extending the base bevy ECS
capabilities, such as [`bevy_ecs_dynamic`] and now
[`bevy_mod_dynamic_query`]
- Making `ArchetypeGeneration` opaque this way made it completely
useless, and removed the ability to limit archetype updates to a subset
of archetypes.
- Making the `index` method on `ArchetypeId` private prevented the use
of bitfields and other optimized data structure to store sets of
archetype ids. (without `transmute`)
This PR is not a simple reversal of the change. It exposes a different
API, rethought to keep the private stuff private and the public stuff
less error-prone.
- Add a `StartRange<ArchetypeGeneration>` `Index` implementation to
`Archetypes`
- Instead of converting the generation into an index, then creating a
ArchetypeId from that index, and indexing `Archetypes` with it, use
directly the old `ArchetypeGeneration` to get the range of new
archetypes.
From careful benchmarking, it seems to also be a performance improvement
(~0-5%) on add_archetypes.
---
Changelog
---------
- Added `impl Index<RangeFrom<ArchetypeGeneration>> for Archetypes` this
allows you to get a slice of newly added archetypes since the last
recorded generation.
- Added `ArchetypeId::index` and `ArchetypeId::new` methods. It should
enable 3rd party crates to use the `Archetypes` API in a meaningful way.
[`bevy_ecs_dynamic`]:
https://github.com/jakobhellermann/bevy_ecs_dynamic/tree/main
[`bevy_mod_dynamic_query`]:
https://github.com/nicopap/bevy_mod_dynamic_query/
---------
Co-authored-by: vero <email@atlasdostal.com>
# Objective
We've done a lot of work to remove the pattern of a `&World` with
interior mutability (#6404, #8833). However, this pattern still persists
within `bevy_ecs` via the `unsafe_world` method.
## Solution
* Make `unsafe_world` private. Adjust any callsites to use
`UnsafeWorldCell` for interior mutability.
* Add `UnsafeWorldCell::removed_components`, since it is always safe to
access the removed components collection through `UnsafeWorldCell`.
## Future Work
Remove/hide `UnsafeWorldCell::world_metadata`, once we have provided
safe ways of accessing all world metadata.
---
## Changelog
+ Added `UnsafeWorldCell::removed_components`, which provides read-only
access to a world's collection of removed components.
# Objective
Improve code-gen for `QueryState::validate_world` and
`SystemState::validate_world`.
## Solution
* Move panics into separate, non-inlined functions, to reduce the code
size of the outer methods.
* Mark the panicking functions with `#[cold]` to help the compiler
optimize for the happy path.
* Mark the functions with `#[track_caller]` to make debugging easier.
---------
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
- Fixes#9683
## Solution
- Moved `get_component` from `Query` to `QueryState`.
- Moved `get_component_unchecked_mut` from `Query` to `QueryState`.
- Moved `QueryComponentError` from `bevy_ecs::system` to
`bevy_ecs::query`. Minor Breaking Change.
- Narrowed scope of `unsafe` blocks in `Query` methods.
---
## Migration Guide
- `use bevy_ecs::system::QueryComponentError;` -> `use
bevy_ecs::query::QueryComponentError;`
## Notes
I am not very familiar with unsafe Rust nor its use within Bevy, so I
may have committed a Rust faux pas during the migration.
---------
Co-authored-by: Zac Harrold <zharrold@c5prosolutions.com>
Co-authored-by: Tristan Guichaoua <33934311+tguichaoua@users.noreply.github.com>
# Objective
`QueryState::is_empty` is unsound, as it does not validate the world. If
a mismatched world is passed in, then the query filter may cast a
component to an incorrect type, causing undefined behavior.
## Solution
Add world validation. To prevent a performance regression in `Query`
(whose world does not need to be validated), the unchecked function
`is_empty_unsafe_world_cell` has been added. This also allows us to
remove one of the last usages of the private function
`UnsafeWorldCell::unsafe_world`, which takes us a step towards being
able to remove that method entirely.
# Objective
* `Local` and `SystemName` implement `Debug` manually, but they could
derive it.
* `QueryState` and `dyn System` have unconventional debug formatting.
# Objective
Fixes#6689.
## Solution
Add `single-threaded` as an optional non-default feature to `bevy_ecs`
and `bevy_tasks` that:
- disable the `ParallelExecutor` as a default runner
- disables the multi-threaded `TaskPool`
- internally replace `QueryParIter::for_each` calls with
`Query::for_each`.
Removed the `Mutex` and `Arc` usage in the single-threaded task pool.

## Future Work/TODO
Create type aliases for `Mutex`, `Arc` that change to single-threaaded
equivalents where possible.
---
## Changelog
Added: Optional default feature `multi-theaded` to that enables
multithreaded parallelism in the engine. Disabling it disables all
multithreading in exchange for higher single threaded performance. Does
nothing on WASM targets.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Title. This is necessary in order to update
[`bevy-trait-query`](https://crates.io/crates/bevy-trait-query) to Bevy
0.11.
---
## Changelog
Added the unsafe function `UnsafeWorldCell::storages`, which provides
unchecked access to the internal data stores of a `World`.
# Objective
Follow-up to #6404 and #8292.
Mutating the world through a shared reference is surprising, and it
makes the meaning of `&World` unclear: sometimes it gives read-only
access to the entire world, and sometimes it gives interior mutable
access to only part of it.
This is an up-to-date version of #6972.
## Solution
Use `UnsafeWorldCell` for all interior mutability. Now, `&World`
*always* gives you read-only access to the entire world.
---
## Changelog
TODO - do we still care about changelogs?
## Migration Guide
Mutating any world data using `&World` is now considered unsound -- the
type `UnsafeWorldCell` must be used to achieve interior mutability. The
following methods now accept `UnsafeWorldCell` instead of `&World`:
- `QueryState`: `get_unchecked`, `iter_unchecked`,
`iter_combinations_unchecked`, `for_each_unchecked`,
`get_single_unchecked`, `get_single_unchecked_manual`.
- `SystemState`: `get_unchecked_manual`
```rust
let mut world = World::new();
let mut query = world.query::<&mut T>();
// Before:
let t1 = query.get_unchecked(&world, entity_1);
let t2 = query.get_unchecked(&world, entity_2);
// After:
let world_cell = world.as_unsafe_world_cell();
let t1 = query.get_unchecked(world_cell, entity_1);
let t2 = query.get_unchecked(world_cell, entity_2);
```
The methods `QueryState::validate_world` and
`SystemState::matches_world` now take a `WorldId` instead of `&World`:
```rust
// Before:
query_state.validate_world(&world);
// After:
query_state.validate_world(world.id());
```
The methods `QueryState::update_archetypes` and
`SystemState::update_archetypes` now take `UnsafeWorldCell` instead of
`&World`:
```rust
// Before:
query_state.update_archetypes(&world);
// After:
query_state.update_archetypes(world.as_unsafe_world_cell_readonly());
```
# Objective
The method `QueryState::par_iter` does not currently force the query to
be read-only. This means you can unsoundly mutate a world through an
immutable reference in safe code.
```rust
fn bad_system(world: &World, mut query: Local<QueryState<&mut T>>) {
query.par_iter(world).for_each_mut(|mut x| *x = unsoundness);
}
```
## Solution
Use read-only versions of the `WorldQuery` types.
---
## Migration Guide
The function `QueryState::par_iter` now forces any world accesses to be
read-only, similar to how `QueryState::iter` works. Any code that
previously mutated the world using this method was *unsound*. If you
need to mutate the world, use `par_iter_mut` instead.
# Objective
`QueryState` exposes a `get_manual` and `iter_manual` method. However,
there is now `iter_many_manual`.
`iter_many_manual` is useful when you have a `&World` (eg: the `world`
in a `Scene`) and want to run a query several times on it (eg:
iteratively navigate a hierarchy by calling `iter_many` on `Children`
component).
`iter_many`'s need for a `&mut World` makes the API much less flexible.
The exclusive access pattern requires doing some very funky dance and
excludes a category of algorithms for hierarchy traversal.
## Solution
- Add a `iter_many_manual` method to `QueryState`
### Alternative
My current workaround is to use `get_manual`. However, this doesn't
benefit from the optimizations on `QueryManyIter`.
---
## Changelog
- Add a `iter_many_manual` method to `QueryState`
# Objective
Title.
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
Add documentation to `Query` and `QueryState` errors in bevy_ecs
(`QuerySingleError`, `QueryEntityError`, `QueryComponentError`)
## Solution
- Change display message for `QueryEntityError::QueryDoesNotMatch`: this
error can also happen when the entity has a component which is filtered
out (with `Without<C>`)
- Fix wrong reference in the documentation of `Query::get_component` and
`Query::get_component_mut` from `QueryEntityError` to
`QueryComponentError`
- Complete the documentation of the three error enum variants.
- Add examples for `QueryComponentError::MissingReadAccess` and
`QueryComponentError::MissingWriteAccess`
- Add reference to `QueryState` in `QueryEntityError`'s documentation.
---
## Migration Guide
Expect `QueryEntityError::QueryDoesNotMatch`'s display message to
change? Not sure that counts.
---------
Co-authored-by: harudagondi <giogdeasis@gmail.com>
# Objective
The documentation on `QueryState::for_each_unchecked` incorrectly says
that it can only be used with read-only queries.
## Solution
Remove the inaccurate sentence.
# Objective
Several `Query` methods unnecessarily place the call to `Query::update_archetypes` inside of unsafe blocks.
## Solution
Move the method calls out of the unsafe blocks.
# Objective
Fixes#3184. Fixes#6640. Fixes#4798. Using `Query::par_for_each(_mut)` currently requires a `batch_size` parameter, which affects how it chunks up large archetypes and tables into smaller chunks to run in parallel. Tuning this value is difficult, as the performance characteristics entirely depends on the state of the `World` it's being run on. Typically, users will just use a flat constant and just tune it by hand until it performs well in some benchmarks. However, this is both error prone and risks overfitting the tuning on that benchmark.
This PR proposes a naive automatic batch-size computation based on the current state of the `World`.
## Background
`Query::par_for_each(_mut)` schedules a new Task for every archetype or table that it matches. Archetypes/tables larger than the batch size are chunked into smaller tasks. Assuming every entity matched by the query has an identical workload, this makes the worst case scenario involve using a batch size equal to the size of the largest matched archetype or table. Conversely, a batch size of `max {archetype, table} size / thread count * COUNT_PER_THREAD` is likely the sweetspot where the overhead of scheduling tasks is minimized, at least not without grouping small archetypes/tables together.
There is also likely a strict minimum batch size below which the overhead of scheduling these tasks is heavier than running the entire thing single-threaded.
## Solution
- [x] Remove the `batch_size` from `Query(State)::par_for_each` and friends.
- [x] Add a check to compute `batch_size = max {archeytpe/table} size / thread count * COUNT_PER_THREAD`
- [x] ~~Panic if thread count is 0.~~ Defer to `for_each` if the thread count is 1 or less.
- [x] Early return if there is no matched table/archetype.
- [x] Add override option for users have queries that strongly violate the initial assumption that all iterated entities have an equal workload.
---
## Changelog
Changed: `Query::par_for_each(_mut)` has been changed to `Query::par_iter(_mut)` and will now automatically try to produce a batch size for callers based on the current `World` state.
## Migration Guide
The `batch_size` parameter for `Query(State)::par_for_each(_mut)` has been removed. These calls will automatically compute a batch size for you. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_iter().for_each(|comp| {
...
});
}
```
Co-authored-by: Arnav Choubey <56453634+x-52@users.noreply.github.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Corey Farwell <coreyf@rwell.org>
Co-authored-by: Aevyrie <aevyrie@gmail.com>
# Objective
I was reading through the bevy_ecs code, trying to understand how everything works.
I was getting a bit confused when reading the doc comment for the `new_archetype` function; it looks like it doesn't create a new archetype but instead updates some internal state in the SystemParam to facility QueryIteration.
(I still couldn't find where a new archetype was actually created)
## Solution
- Adding a doc comment with a more correct explanation.
If it's deemed correct, I can also update the doc-comment for the other `new_archetype` calls
# Objective
`Query::get` and other random access methods require looking up `EntityLocation` for every provided entity, then always looking up the `Archetype` to get the table ID and table row. This requires 4 total random fetches from memory: the `Entities` lookup, the `Archetype` lookup, the table row lookup, and the final fetch from table/sparse sets. If `EntityLocation` contains the table ID and table row, only the `Entities` lookup and the final storage fetch are required.
## Solution
Add `TableId` and table row to `EntityLocation`. Ensure it's updated whenever entities are moved around. To ensure `EntityMeta` does not grow bigger, both `TableId` and `ArchetypeId` have been shrunk to u32, and the archetype index and table row are stored as u32s instead of as usizes. This should shrink `EntityMeta` by 4 bytes, from 24 to 20 bytes, as there is no padding anymore due to the change in alignment.
This idea was partially concocted by @BoxyUwU.
## Performance
This should restore the `Query::get` "gains" lost to #6625 that were introduced in #4800 without being unsound, and also incorporates some of the memory usage reductions seen in #3678.
This also removes the same lookups during add/remove/spawn commands, so there may be a bit of a speedup in commands and `Entity{Ref,Mut}`.
---
## Changelog
Added: `EntityLocation::table_id`
Added: `EntityLocation::table_row`.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup>- 1 archetypes.
Changed: `World`s can now only hold a maximum of 2<sup>32</sup> - 1 tables.
## Migration Guide
A `World` can only hold a maximum of 2<sup>32</sup> - 1 archetypes and tables now. If your use case requires more than this, please file an issue explaining your use case.
# Objective
Prevent future unsoundness that was seen in #6623.
## Solution
Newtype both indexes in `Archetype` and `Table` as `ArchetypeRow` and `TableRow`. This avoids weird numerical manipulation on the indices, and can be stored and treated opaquely. Also enforces the source and destination of where these indices at a type level.
---
## Changelog
Changed: `Archetype` indices and `Table` rows have been newtyped as `ArchetypeRow` and `TableRow`.
# Objective
- Fixes#6812.
## Solution
- Replaced `World::read_change_ticks` with `World::change_ticks` within `bevy_ecs` crate in places where `World` references were mutable.
---
# Objective
Document `bevy_ecs::archetype` and and declutter the public documentation for the module by making types non-`pub`.
Addresses #3362 for `bevy_ecs::archetype`.
## Solution
- Add module level documentation.
- Add type and API level documentation for all public facing types.
- Make `ArchetypeId`, `ArchetypeGeneration`, and `ArchetypeComponentId` truly opaque IDs that are not publicly constructable.
- Make `AddBundle` non-pub, make `Edges::get_add_bundle` return a `Option<ArchetypeId>` and fork the existing function into `Edges::get_add_bundle_internal`.
- Remove `pub(crate)` on fields that have a corresponding pub accessor function.
- Removed the `Archetypes: Default` impl, opting for a `pub(crate) fn new` alternative instead.
---
## Changelog
Added: `ArchetypeGeneration` now implements `Ord` and `PartialOrd`.
Removed: `Archetypes`'s `Default` implementation.
Removed: `Archetype::new` and `Archetype::is_empty`.
Removed: `ArchetypeId::new` and `ArchetypeId::value`.
Removed: `ArchetypeGeneration::value`
Removed: `ArchetypeIdentity`.
Removed: `ArchetypeComponentId::new` and `ArchetypeComponentId::value`.
Removed: `AddBundle`. `Edges::get_add_bundle` now returns `Option<ArchetypeId>`
# Objective
Replace `WorldQueryGats` trait with actual gats
## Solution
Replace `WorldQueryGats` trait with actual gats
---
## Changelog
- Replaced `WorldQueryGats` trait with actual gats
## Migration Guide
- Replace usage of `WorldQueryGats` assoc types with the actual gats on `WorldQuery` trait
# Objective
* Add benchmarks for `Query::get_many`.
* Speed up `Query::get_many`.
## Solution
Previously, `get_many` and `get_many_mut` used the method `array::map`, which tends to optimize very poorly. This PR replaces uses of that method with loops.
## Benchmarks
| Benchmark name | Execution time | Change from this PR |
|--------------------------------------|----------------|---------------------|
| query_get_many_2/50000_calls_table | 1.3732 ms | -24.967% |
| query_get_many_2/50000_calls_sparse | 1.3826 ms | -24.572% |
| query_get_many_5/50000_calls_table | 2.6833 ms | -30.681% |
| query_get_many_5/50000_calls_sparse | 2.9936 ms | -30.672% |
| query_get_many_10/50000_calls_table | 5.7771 ms | -36.950% |
| query_get_many_10/50000_calls_sparse | 7.4345 ms | -36.987% |
# Objective
- fix new clippy lints before they get stable and break CI
## Solution
- run `clippy --fix` to auto-fix machine-applicable lints
- silence `clippy::should_implement_trait` for `fn HandleId::default<T: Asset>`
## Changes
- always prefer `format!("{inline}")` over `format!("{}", not_inline)`
- prefer `Box::default` (or `Box::<T>::default` if necessary) over `Box::new(T::default())`
# Objective
Clean up code surrounding fetch by pulling out the common parts into the iteration code.
## Solution
Merge `Fetch::table_fetch` and `Fetch::archetype_fetch` into a single API: `Fetch::fetch(&mut self, entity: &Entity, table_row: &usize)`. This provides everything any fetch requires to internally decide which storage to read from and get the underlying data. All of these functions are marked as `#[inline(always)]` and the arguments are passed as references to attempt to optimize out the argument that isn't being used.
External to `Fetch`, Query iteration has been changed to keep track of the table row and entity outside of fetch, which moves a lot of the expensive bookkeeping `Fetch` structs had previously done internally into the outer loop.
~~TODO: Benchmark, docs~~ Done.
---
## Changelog
Changed: `Fetch::table_fetch` and `Fetch::archetype_fetch` have been merged into a single `Fetch::fetch` function.
## Migration Guide
TODO
Co-authored-by: Brian Merchant <bhmerchang@gmail.com>
Co-authored-by: Saverio Miroddi <saverio.pub2@gmail.com>
# Objective
I was trying to implement a collision system for my game, and believed that the iter_combinations method might be what I need. But I couldn't find a simple explanation of what a combination was in Bevy and thought it could use some more explanation.
## Solution
I added some description to the documentation that can hopefully further elaborate on what a combination is.
I also changed up the docs for the method because a combination is a different thing than a permutation but the Bevy docs seemed to use them interchangeably.
Add the following message:
```
Items are returned in the order of the list of entities.
Entities that don't match the query are skipped.
```
Additionally, the docs in `iter.rs` and `state.rs` were updated to match those in `query.rs`.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Speed up queries that are fragmented over many empty archetypes and tables.
## Solution
Add a early-out to check if the table or archetype is empty before iterating over it. This adds an extra branch for every archetype matched, but skips setting the archetype/table to the underlying state and any iteration over it.
This may not be worth it for the default `Query::iter` and maybe even the `Query::for_each` implementations, but this definitely avoids scheduling unnecessary tasks in the `Query::par_for_each` case.
Ideally, `matched_archetypes` should only contain archetypes where there's actually work to do, but this would add a `O(n)` flat cost to every call to `update_archetypes` that scales with the number of matched archetypes.
TODO: Benchmark
# Objective
There is currently no good way of getting the width (# of components) of a table outside of `bevy_ecs`.
# Solution
Added the methods `Table::{component_count, component_capacity}`
For consistency and clarity, renamed `Table::{len, capacity}` to `entity_count` and `entity_capacity`.
## Changelog
- Added the methods `Table::component_count` and `Table::component_capacity`
- Renamed `Table::len` and `Table::capacity` to `entity_count` and `entity_capacity`
## Migration Guide
Any use of `Table::len` should now be `Table::entity_count`. Any use of `Table::capacity` should now be `Table::entity_capacity`.
# Objective
- Adding Debug implementations for App, Stage, Schedule, Query, QueryState.
- Fixes#1130.
## Solution
- Implemented std::fmt::Debug for a number of structures.
---
## Changelog
Also added Debug implementations for ParallelSystemExecutor, SingleThreadedExecutor, various RunCriteria structures, SystemContainer, and SystemDescriptor.
Opinions are sure to differ as to what information to provide in a Debug implementation. Best guess was taken for this initial version for these structures.
Co-authored-by: targrub <62773321+targrub@users.noreply.github.com>
# Objective
Now that we can consolidate Bundles and Components under a single insert (thanks to #2975 and #6039), almost 100% of world spawns now look like `world.spawn().insert((Some, Tuple, Here))`. Spawning an entity without any components is an extremely uncommon pattern, so it makes sense to give spawn the "first class" ergonomic api. This consolidated api should be made consistent across all spawn apis (such as World and Commands).
## Solution
All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input:
```rust
// before:
commands
.spawn()
.insert((A, B, C));
world
.spawn()
.insert((A, B, C);
// after
commands.spawn((A, B, C));
world.spawn((A, B, C));
```
All existing instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api. A new `spawn_empty` has been added, replacing the old `spawn` api.
By allowing `world.spawn(some_bundle)` to replace `world.spawn().insert(some_bundle)`, this opened the door to removing the initial entity allocation in the "empty" archetype / table done in `spawn()` (and subsequent move to the actual archetype in `.insert(some_bundle)`).
This improves spawn performance by over 10%:

To take this measurement, I added a new `world_spawn` benchmark.
Unfortunately, optimizing `Commands::spawn` is slightly less trivial, as Commands expose the Entity id of spawned entities prior to actually spawning. Doing the optimization would (naively) require assurances that the `spawn(some_bundle)` command is applied before all other commands involving the entity (which would not necessarily be true, if memory serves). Optimizing `Commands::spawn` this way does feel possible, but it will require careful thought (and maybe some additional checks), which deserves its own PR. For now, it has the same performance characteristics of the current `Commands::spawn_bundle` on main.
**Note that 99% of this PR is simple renames and refactors. The only code that needs careful scrutiny is the new `World::spawn()` impl, which is relatively straightforward, but it has some new unsafe code (which re-uses battle tested BundlerSpawner code path).**
---
## Changelog
- All `spawn` apis (`World::spawn`, `Commands:;spawn`, `ChildBuilder::spawn`, and `WorldChildBuilder::spawn`) now accept a bundle as input
- All instances of `spawn_bundle` have been deprecated in favor of the new `spawn` api
- World and Commands now have `spawn_empty()`, which is equivalent to the old `spawn()` behavior.
## Migration Guide
```rust
// Old (0.8):
commands
.spawn()
.insert_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
commands.spawn_bundle((A, B, C));
// New (0.9)
commands.spawn((A, B, C));
// Old (0.8):
let entity = commands.spawn().id();
// New (0.9)
let entity = commands.spawn_empty().id();
// Old (0.8)
let entity = world.spawn().id();
// New (0.9)
let entity = world.spawn_empty();
```
# Objective
Fixes Issue #6005.
## Solution
Replaced WorldQuery with ReadOnlyWorldQuery on F generic in Query filters and QueryState to restrict its trait bound.
## Migration Guide
Query filter (`F`) generics are now bound by `ReadOnlyWorldQuery`, rather than `WorldQuery`. If for some reason you were requesting `Query<&A, &mut B>`, please use `Query<&A, With<B>>` instead.
# Objective
Simplify the worldquery trait hierarchy as much as possible by putting it all in one trait. If/when gats are stabilised this can be trivially migrated over to use them, although that's not why I made this PR, those reasons are:
- Moves all of the conceptually related unsafe code for a worldquery next to eachother
- Removes now unnecessary traits simplifying the "type system magic" in bevy_ecs
---
## Changelog
All methods/functions/types/consts on `FetchState` and `Fetch` traits have been moved to the `WorldQuery` trait and the other traits removed. `WorldQueryGats` now only contains an `Item` and `Fetch` assoc type.
## Migration Guide
Implementors should move items in impls to the `WorldQuery/Gats` traits and remove any `Fetch`/`FetchState` impls
Any use sites of items in the `Fetch`/`FetchState` traits should be updated to use the `WorldQuery` trait items instead
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Replace `many_for_each_mut` with `iter_many_mut` using the same tricks to avoid aliased mutability that `iter_combinations_mut` uses.
<sub>I tried rebasing the draft PR I made for this before and it died. F</sub>
## Why
`many_for_each_mut` is worse for a few reasons:
1. The closure prevents the use of `continue`, `break`, and `return` behaves like a limited `continue`.
2. rustfmt will crumple it and double the indentation when the line gets too long.
```rust
query.many_for_each_mut(
&entity_list,
|(mut transform, velocity, mut component_c)| {
// Double trouble.
},
);
```
3. It is more surprising to have `many_for_each_mut` as a mutable counterpart to `iter_many` than `iter_many_mut`.
4. It required a separate unsafe fn; more unsafe code to maintain.
5. The `iter_many_mut` API matches the existing `iter_combinations_mut` API.
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
remove `QF` generics from a bunch of types and methods on query related items. this has a few benefits:
- simplifies type signatures `fn iter(&self) -> QueryIter<'_, 's, Q::ReadOnly, F::ReadOnly>` is (imo) conceptually simpler than `fn iter(&self) -> QueryIter<'_, 's, Q, ROQueryFetch<'_, Q>, F>`
- `Fetch` is mostly an implementation detail but previously we had to expose it on every `iter` `get` etc method
- Allows us to potentially in the future simplify the `WorldQuery` trait hierarchy by removing the `Fetch` trait
## Solution
remove the `QF` generic and add a way to (unsafely) turn `&QueryState<Q1, F1>` into `&QueryState<Q2, F2>`
---
## Changelog/Migration Guide
The `QF` generic was removed from various `Query` iterator types and some methods, you should update your code to use the type of the corresponding worldquery of the fetch type that was being used, or call `as_readonly`/`as_nop` to convert a querystate to the appropriate type. For example:
`.get_single_unchecked_manual::<ROQueryFetch<Q>>(..)` -> `.as_readonly().get_single_unchecked_manual(..)`
`my_field: QueryIter<'w, 's, Q, ROQueryFetch<'w, Q>, F>` -> `my_field: QueryIter<'w, 's, Q::ReadOnly, F::ReadOnly>`
# Objective
- Added a bunch of backticks to things that should have them, like equations, abstract variable names,
- Changed all small x, y, and z to capitals X, Y, Z.
This might be more annoying than helpful; Feel free to refuse this PR.
Remove unnecessary calls to `iter()`/`iter_mut()`.
Mainly updates the use of queries in our code, docs, and examples.
```rust
// From
for _ in list.iter() {
for _ in list.iter_mut() {
// To
for _ in &list {
for _ in &mut list {
```
We already enable the pedantic lint [clippy::explicit_iter_loop](https://rust-lang.github.io/rust-clippy/stable/) inside of Bevy. However, this only warns for a few known types from the standard library.
## Note for reviewers
As you can see the additions and deletions are exactly equal.
Maybe give it a quick skim to check I didn't sneak in a crypto miner, but you don't have to torture yourself by reading every line.
I already experienced enough pain making this PR :)
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
`SAFETY` comments are meant to be placed before `unsafe` blocks and should contain the reasoning of why in this case the usage of unsafe is okay. This is useful when reading the code because it makes it clear which assumptions are required for safety, and makes it easier to spot possible unsoundness holes. It also forces the code writer to think of something to write and maybe look at the safety contracts of any called unsafe methods again to double-check their correct usage.
There's a clippy lint called `undocumented_unsafe_blocks` which warns when using a block without such a comment.
## Solution
- since clippy expects `SAFETY` instead of `SAFE`, rename those
- add `SAFETY` comments in more places
- for the last remaining 3 places, add an `#[allow()]` and `// TODO` since I wasn't comfortable enough with the code to justify their safety
- add ` #![warn(clippy::undocumented_unsafe_blocks)]` to `bevy_ecs`
### Note for reviewers
The first commit only renames `SAFETY` to `SAFE` so it doesn't need a thorough review.
cb042a416e..55cef2d6fa is the diff for all other changes.
### Safety comments where I'm not too familiar with the code
774012ece5/crates/bevy_ecs/src/entity/mod.rs (L540-L546)774012ece5/crates/bevy_ecs/src/world/entity_ref.rs (L249-L252)
### Locations left undocumented with a `TODO` comment
5dde944a30/crates/bevy_ecs/src/schedule/executor_parallel.rs (L196-L199)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L287-L289)5dde944a30/crates/bevy_ecs/src/world/entity_ref.rs (L413-L415)
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Nightly clippy lints should be fixed before they get stable and break CI
## Solution
- fix new clippy lints
- ignore `significant_drop_in_scrutinee` since it isn't relevant in our loop https://github.com/rust-lang/rust-clippy/issues/8987
```rust
for line in io::stdin().lines() {
...
}
```
Co-authored-by: Jakob Hellermann <hellermann@sipgate.de>
# Objective
- Fix a type inference regression introduced by #3001
- Make read only bounds on world queries more user friendly
ptrification required you to write `Q::Fetch: ReadOnlyFetch` as `for<'w> QueryFetch<'w, Q>: ReadOnlyFetch` which has the same type inference problem as `for<'w> QueryFetch<'w, Q>: FilterFetch<'w>` had, i.e. the following code would error:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: WorldQuery>(a: Query<Q, ()>)
where
for<'w> QueryFetch<'w, Q>: ReadOnlyFetch,
{
}
```
`for<..>` bounds are also rather user unfriendly..
## Solution
Remove the `ReadOnlyFetch` trait in favour of a `ReadOnlyWorldQuery` trait, and remove `WorldQueryGats::ReadOnlyFetch` in favor of `WorldQuery::ReadOnly` allowing the previous code snippet to be written as:
```rust
#[derive(Component)]
struct Foo;
fn bar(a: Query<(&Foo, Without<Foo>)>) {
foo(a);
}
fn foo<Q: ReadOnlyWorldQuery>(a: Query<Q, ()>) {}
```
This avoids the `for<...>` bound which makes the code simpler and also fixes the type inference issue.
The reason for moving the two functions out of `FetchState` and into `WorldQuery` is to allow the world query `&mut T` to share a `State` with the `&T` world query so that it can have `type ReadOnly = &T`. Presumably it would be possible to instead have a `ReadOnlyRefMut<T>` world query and then do `type ReadOnly = ReadOnlyRefMut<T>` much like how (before this PR) we had a `ReadOnlyWriteFetch<T>`. A side benefit of the current solution in this PR is that it will likely make it easier in the future to support an API such as `Query<&mut T> -> Query<&T>`. The primary benefit IMO is just that `ReadOnlyRefMut<T>` and its associated fetch would have to reimplement all of the logic that the `&T` world query impl does but this solution avoids that :)
---
## Changelog/Migration Guide
The trait `ReadOnlyFetch` has been replaced with `ReadOnlyWorldQuery` along with the `WorldQueryGats::ReadOnlyFetch` assoc type which has been replaced with `<WorldQuery::ReadOnly as WorldQueryGats>::Fetch`
- Any where clauses such as `QueryFetch<Q>: ReadOnlyFetch` should be replaced with `Q: ReadOnlyWorldQuery`.
- Any custom world query impls should implement `ReadOnlyWorldQuery` insead of `ReadOnlyFetch`
Functions `update_component_access` and `update_archetype_component_access` have been moved from the `FetchState` trait to `WorldQuery`
- Any callers should now call `Q::update_component_access(state` instead of `state.update_component_access` (and `update_archetype_component_access` respectively)
- Any custom world query impls should move the functions from the `FetchState` impl to `WorldQuery` impl
`WorldQuery` has been made an `unsafe trait`, `FetchState` has been made a safe `trait`. (I think this is how it should have always been, but regardless this is _definitely_ necessary now that the two functions have been moved to `WorldQuery`)
- If you have a custom `FetchState` impl make it a normal `impl` instead of `unsafe impl`
- If you have a custom `WorldQuery` impl make it an `unsafe impl`, if your code was sound before it is going to still be sound
Right now, a direct reference to the target TaskPool is required to launch tasks on the pools, despite the three newtyped pools (AsyncComputeTaskPool, ComputeTaskPool, and IoTaskPool) effectively acting as global instances. The need to pass a TaskPool reference adds notable friction to spawning subtasks within existing tasks. Possible use cases for this may include chaining tasks within the same pool like spawning separate send/receive I/O tasks after waiting on a network connection to be established, or allowing cross-pool dependent tasks like starting dependent multi-frame computations following a long I/O load.
Other task execution runtimes provide static access to spawning tasks (i.e. `tokio::spawn`), which is notably easier to use than the reference passing required by `bevy_tasks` right now.
This PR makes does the following:
* Adds `*TaskPool::init` which initializes a `OnceCell`'ed with a provided TaskPool. Failing if the pool has already been initialized.
* Adds `*TaskPool::get` which fetches the initialized global pool of the respective type or panics. This generally should not be an issue in normal Bevy use, as the pools are initialized before they are accessed.
* Updated default task pool initialization to either pull the global handles and save them as resources, or if they are already initialized, pull the a cloned global handle as the resource.
This should make it notably easier to build more complex task hierarchies for dependent tasks. It should also make writing bevy-adjacent, but not strictly bevy-only plugin crates easier, as the global pools ensure it's all running on the same threads.
One alternative considered is keeping a thread-local reference to the pool for all threads in each pool to enable the same `tokio::spawn` interface. This would spawn tasks on the same pool that a task is currently running in. However this potentially leads to potential footgun situations where long running blocking tasks run on `ComputeTaskPool`.
# Objective
Improve querying ergonomics around collections and iterators of entities.
Example how queries over Children might be done currently.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for child in children.iter() {
if let Ok((bar, children)) = bar_query.get(*child) {
for child in children.iter() {
if let Ok((foo, children)) = foo_query.get(*child) {
// D:
}
}
}
}
}
}
```
Answers #4868
Partially addresses #4864Fixes#1470
## Solution
Based on the great work by @deontologician in #2563
Added `iter_many` and `many_for_each_mut` to `Query`.
These take a list of entities (Anything that implements `IntoIterator<Item: Borrow<Entity>>`).
`iter_many` returns a `QueryManyIter` iterator over immutable results of a query (mutable data will be cast to an immutable form).
`many_for_each_mut` calls a closure for every result of the query, ensuring not aliased mutability.
This iterator goes over the list of entities in order and returns the result from the query for it. Skipping over any entities that don't match the query.
Also added `unsafe fn iter_many_unsafe`.
### Examples
```rust
#[derive(Component)]
struct Counter {
value: i32
}
#[derive(Component)]
struct Friends {
list: Vec<Entity>,
}
fn system(
friends_query: Query<&Friends>,
mut counter_query: Query<&mut Counter>,
) {
for friends in &friends_query {
for counter in counter_query.iter_many(&friends.list) {
println!("Friend's counter: {:?}", counter.value);
}
counter_query.many_for_each_mut(&friends.list, |mut counter| {
counter.value += 1;
println!("Friend's counter: {:?}", counter.value);
});
}
}
```
Here's how example in the Objective section can be written with this PR.
```rust
fn system(foo_query: Query<(&Foo, &Children)>, bar_query: Query<(&Bar, &Children)>) {
for (foo, children) in &foo_query {
for (bar, children) in bar_query.iter_many(children) {
for (foo, children) in foo_query.iter_many(children) {
// :D
}
}
}
}
```
## Additional changes
Implemented `IntoIterator` for `&Children` because why not.
## Todo
- Bikeshed!
Co-authored-by: deontologician <deontologician@gmail.com>
Co-authored-by: devil-ira <justthecooldude@gmail.com>
# Objective
Fixes#3183. Requiring a `&TaskPool` parameter is sort of meaningless if the only correct one is to use the one provided by `Res<ComputeTaskPool>` all the time.
## Solution
Have `QueryState` save a clone of the `ComputeTaskPool` which is used for all `par_for_each` functions.
~~Adds a small overhead of the internal `Arc` clone as a part of the startup, but the ergonomics win should be well worth this hardly-noticable overhead.~~
Updated the docs to note that it will panic the task pool is not present as a resource.
# Future Work
If https://github.com/bevyengine/rfcs/pull/54 is approved, we can replace these resource lookups with a static function call instead to get the `ComputeTaskPool`.
---
## Changelog
Removed: The `task_pool` parameter of `Query(State)::par_for_each(_mut)`. These calls will use the `World`'s `ComputeTaskPool` resource instead.
## Migration Guide
The `task_pool` parameter for `Query(State)::par_for_each(_mut)` has been removed. Remove these parameters from all calls to these functions.
Before:
```rust
fn parallel_system(
task_pool: Res<ComputeTaskPool>,
query: Query<&MyComponent>,
) {
query.par_for_each(&task_pool, 32, |comp| {
...
});
}
```
After:
```rust
fn parallel_system(query: Query<&MyComponent>) {
query.par_for_each(32, |comp| {
...
});
}
```
If using `Query(State)` outside of a system run by the scheduler, you may need to manually configure and initialize a `ComputeTaskPool` as a resource in the `World`.
# Objective
- Rebase of #3159.
- Fixes https://github.com/bevyengine/bevy/issues/3156
- add #[inline] to single related functions so that they matches with other function defs
## Solution
* added functions to QueryState
* get_single_unchecked_manual
* get_single_unchecked
* get_single
* get_single_mut
* single
* single_mut
* make Query::get_single use QueryState::get_single_unchecked_manual
* added #[inline]
---
## Changelog
### Added
Functions `QueryState::single`, `QueryState::get_single`, `QueryState::single_mut`, `QueryState::get_single_mut`, `QueryState::get_single_unchecked`, `QueryState::get_single_unchecked_manual`.
### Changed
`QuerySingleError` is now in the `state` module.
## Migration Guide
Change `query::QuerySingleError` to `state::QuerySingleError`
Co-authored-by: 2ne1ugly <chattermin@gmail.com>
Co-authored-by: 2ne1ugly <47616772+2ne1ugly@users.noreply.github.com>
# Objective
the code in these fns are always identical so stop having two functions
## Solution
make them the same function
---
## Changelog
change `matches_archetype` and `matches_table` to `fn matches_component_set(&self, &SparseArray<ComponentId, usize>) -> bool` then do extremely boring updating of all `FetchState` impls
## Migration Guide
- move logic of `matches_archetype` and `matches_table` into `matches_component_set` in any manual `FetchState` impls
# Objective
`Query::par_for_each` and it's variants do not show up when profiling using `tracy` or other profilers. Failing to show the impact of changing batch size, the overhead of scheduling tasks, overall thread utilization, etc. other than the effect on the surrounding system.
## Solution
Add a child span that is entered on every spawned task.
Example view of the results in `tracy` using a modified `parallel_query`:
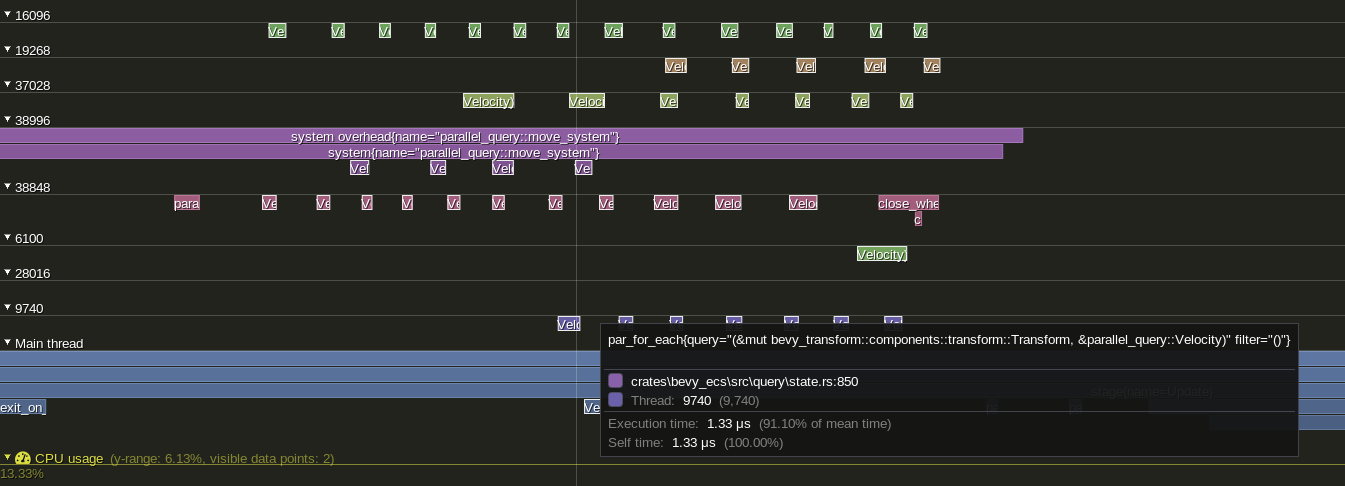
---
## Changelog
Added: `tracing` spans for `Query::par_for_each` and its variants. Spans should now be visible for all
# Objective
`bevy_ecs` has large amounts of unsafe code which is hard to get right and makes it difficult to audit for soundness.
## Solution
Introduce lifetimed, type-erased pointers: `Ptr<'a>` `PtrMut<'a>` `OwningPtr<'a>'` and `ThinSlicePtr<'a, T>` which are newtypes around a raw pointer with a lifetime and conceptually representing strong invariants about the pointee and validity of the pointer.
The process of converting bevy_ecs to use these has already caught multiple cases of unsound behavior.
## Changelog
TL;DR for release notes: `bevy_ecs` now uses lifetimed, type-erased pointers internally, significantly improving safety and legibility without sacrificing performance. This should have approximately no end user impact, unless you were meddling with the (unfortunately public) internals of `bevy_ecs`.
- `Fetch`, `FilterFetch` and `ReadOnlyFetch` trait no longer have a `'state` lifetime
- this was unneeded
- `ReadOnly/Fetch` associated types on `WorldQuery` are now on a new `WorldQueryGats<'world>` trait
- was required to work around lack of Generic Associated Types (we wish to express `type Fetch<'a>: Fetch<'a>`)
- `derive(WorldQuery)` no longer requires `'w` lifetime on struct
- this was unneeded, and improves the end user experience
- `EntityMut::get_unchecked_mut` returns `&'_ mut T` not `&'w mut T`
- allows easier use of unsafe API with less footguns, and can be worked around via lifetime transmutery as a user
- `Bundle::from_components` now takes a `ctx` parameter to pass to the `FnMut` closure
- required because closure return types can't borrow from captures
- `Fetch::init` takes `&'world World`, `Fetch::set_archetype` takes `&'world Archetype` and `&'world Tables`, `Fetch::set_table` takes `&'world Table`
- allows types implementing `Fetch` to store borrows into world
- `WorldQuery` trait now has a `shrink` fn to shorten the lifetime in `Fetch::<'a>::Item`
- this works around lack of subtyping of assoc types, rust doesnt allow you to turn `<T as Fetch<'static>>::Item'` into `<T as Fetch<'a>>::Item'`
- `QueryCombinationsIter` requires this
- Most types implementing `Fetch` now have a lifetime `'w`
- allows the fetches to store borrows of world data instead of using raw pointers
## Migration guide
- `EntityMut::get_unchecked_mut` returns a more restricted lifetime, there is no general way to migrate this as it depends on your code
- `Bundle::from_components` implementations must pass the `ctx` arg to `func`
- `Bundle::from_components` callers have to use a fn arg instead of closure captures for borrowing from world
- Remove lifetime args on `derive(WorldQuery)` structs as it is nonsensical
- `<Q as WorldQuery>::ReadOnly/Fetch` should be changed to either `RO/QueryFetch<'world>` or `<Q as WorldQueryGats<'world>>::ReadOnly/Fetch`
- `<F as Fetch<'w, 's>>` should be changed to `<F as Fetch<'w>>`
- Change the fn sigs of `Fetch::init/set_archetype/set_table` to match respective trait fn sigs
- Implement the required `fn shrink` on any `WorldQuery` implementations
- Move assoc types `Fetch` and `ReadOnlyFetch` on `WorldQuery` impls to `WorldQueryGats` impls
- Pass an appropriate `'world` lifetime to whatever fetch struct you are for some reason using
### Type inference regression
in some cases rustc may give spurrious errors when attempting to infer the `F` parameter on a query/querystate this can be fixed by manually specifying the type, i.e. `QueryState:🆕:<_, ()>(world)`. The error is rather confusing:
```rust=
error[E0271]: type mismatch resolving `<() as Fetch<'_>>::Item == bool`
--> crates/bevy_pbr/src/render/light.rs:1413:30
|
1413 | main_view_query: QueryState::new(world),
| ^^^^^^^^^^^^^^^ expected `bool`, found `()`
|
= note: required because of the requirements on the impl of `for<'x> FilterFetch<'x>` for `<() as WorldQueryGats<'x>>::Fetch`
note: required by a bound in `bevy_ecs::query::QueryState::<Q, F>::new`
--> crates/bevy_ecs/src/query/state.rs:49:32
|
49 | for<'x> QueryFetch<'x, F>: FilterFetch<'x>,
| ^^^^^^^^^^^^^^^ required by this bound in `bevy_ecs::query::QueryState::<Q, F>::new`
```
---
Made with help from @BoxyUwU and @alice-i-cecile
Co-authored-by: Boxy <supbscripter@gmail.com>
# Objective
Reduce from scratch build time.
## Solution
Reduce the size of the critical path by removing dependencies between crates where not necessary. For `cargo check --no-default-features` this reduced build time from ~51s to ~45s. For some commits I am not completely sure if the tradeoff between build time reduction and convenience caused by the commit is acceptable. If not, I can drop them.
# Objective
Make `FromWorld` more useful for abstractions with a form similar to
```rs
trait FancyAbstraction {
type PreInitializedData: FromWorld;
}
```
## Solution
Add a `FromWorld` implementation for `SystemState` as well as a way to group together multiple `FromWorld` implementing types as one.
Note: I plan to follow up this PR with another to add `Local` support to exclusive systems, which should get a fair amount of use from the `FromWorld` implementation on `SystemState`.
# Objective
- std's new APIs do the same thing as `Query::get_multiple_mut`, but are called `get_many`: https://github.com/rust-lang/rust/pull/83608
## Solution
- Find and replace `get_multiple` with `get_many`
# Objective
- The inability to have multiple active mutable borrows into a query is a common source of borrow-checker pain for users.
- This is a pointless restriction if and only if we can guarantee that the entities they are accessing are unique.
- This could already by bypassed with get_unchecked, but that is an extremely unsafe API.
- Closes https://github.com/bevyengine/bevy/issues/2042.
## Solution
- Add `get_multiple`, `get_multiple_mut` and their unchecked equivalents (`multiple` and `multiple_mut`) to `Query` and `QueryState`.
- Improve the `QueryEntityError` type to provide more useful error information.
## Changelog
- Added `get_multiple`, `get_multiple_mut` and their unchecked equivalents (`multiple` and `multiple_mut`) to Query and QueryState.
## Migration Guide
- The `QueryEntityError` enum now has a `AliasedMutability variant, and returns the offending entity.
## Context
This is a fresh attempt at #3333; rebasing was behaving very badly and it was important to rebase on top of the recent query soundness fixes. Many thanks to all the reviewers in that thread, especially @BoxyUwU for the help with lifetimes.
## To-do
- [x] Add compile fail tests
- [x] Successfully deduplicate code
- [x] Decide what to do about failing doc tests
- [x] Get some reviews for lifetime soundness
What is says on the tin.
This has got more to do with making `clippy` slightly more *quiet* than it does with changing anything that might greatly impact readability or performance.
that said, deriving `Default` for a couple of structs is a nice easy win
# Objective
- Fixes#3616
## Solution
- As described in the issue, documentation for `iter_manual` was copied from `iter_combinations` and did not reflect the behavior of the method. I've pulled some information from #2351 to create a more accurate description.
#3457 adds the `doc_markdown` clippy lint, which checks doc comments to make sure code identifiers are escaped with backticks. This causes a lot of lint errors, so this is one of a number of PR's that will fix those lint errors one crate at a time.
This PR fixes lints in the `bevy_ecs` crate.
A sample implementation of how to have `iter()` work on mutable queries without breaking aliasing rules.
# Objective
- Fixes#753
## Solution
- Added a ReadOnlyFetch to WorldQuery that is the `&T` version of `&mut T` that is used to specify the return type for read only operations like `iter()`.
- ~~As the comment suggests specifying the bound doesn't work due to restrictions on defining recursive implementations (like `Or`). However bounds on the functions are fine~~ Never mind I misread how `Or` was constructed, bounds now exist.
- Note that the only mutable one has a new `Fetch` for readonly as the `State` has to be the same for any of this to work
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This implements the most minimal variant of #1843 - a derive for marker trait. This is a prerequisite to more complicated features like statically defined storage type or opt-out component reflection.
In order to make component struct's purpose explicit and avoid misuse, it must be annotated with `#[derive(Component)]` (manual impl is discouraged for compatibility). Right now this is just a marker trait, but in the future it might be expanded. Making this change early allows us to make further changes later without breaking backward compatibility for derive macro users.
This already prevents a lot of issues, like using bundles in `insert` calls. Primitive types are no longer valid components as well. This can be easily worked around by adding newtype wrappers and deriving `Component` for them.
One funny example of prevented bad code (from our own tests) is when an newtype struct or enum variant is used. Previously, it was possible to write `insert(Newtype)` instead of `insert(Newtype(value))`. That code compiled, because function pointers (in this case newtype struct constructor) implement `Send + Sync + 'static`, so we allowed them to be used as components. This is no longer the case and such invalid code will trigger a compile error.
Co-authored-by: = <=>
Co-authored-by: TheRawMeatball <therawmeatball@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
This updates the `pipelined-rendering` branch to use the latest `bevy_ecs` from `main`. This accomplishes a couple of goals:
1. prepares for upcoming `custom-shaders` branch changes, which were what drove many of the recent bevy_ecs changes on `main`
2. prepares for the soon-to-happen merge of `pipelined-rendering` into `main`. By including bevy_ecs changes now, we make that merge simpler / easier to review.
I split this up into 3 commits:
1. **add upstream bevy_ecs**: please don't bother reviewing this content. it has already received thorough review on `main` and is a literal copy/paste of the relevant folders (the old folders were deleted so the directories are literally exactly the same as `main`).
2. **support manual buffer application in stages**: this is used to enable the Extract step. we've already reviewed this once on the `pipelined-rendering` branch, but its worth looking at one more time in the new context of (1).
3. **support manual archetype updates in QueryState**: same situation as (2).
# Objective
- QueryState is lacking documentation.
Fixes#2090
## Solution
- Provide documentation that mirrors Query (as suggested in #2090) and modify as needed.
Co-authored-by: James Leflang <59455417+jleflang@users.noreply.github.com>
# Objective
Enable using exact World lifetimes during read-only access . This is motivated by the new renderer's need to allow read-only world-only queries to outlive the query itself (but still be constrained by the world lifetime).
For example:
115b170d1f/pipelined/bevy_pbr2/src/render/mod.rs (L774)
## Solution
Split out SystemParam state and world lifetimes and pipe those lifetimes up to read-only Query ops (and add into_inner for Res). According to every safety test I've run so far (except one), this is safe (see the temporary safety test commit). Note that changing the mutable variants to the new lifetimes would allow aliased mutable pointers (try doing that to see how it affects the temporary safety tests).
The new state lifetime on SystemParam does make `#[derive(SystemParam)]` more cumbersome (the current impl requires PhantomData if you don't use both lifetimes). We can make this better by detecting whether or not a lifetime is used in the derive and adjusting accordingly, but that should probably be done in its own pr.
## Why is this a draft?
The new lifetimes break QuerySet safety in one very specific case (see the query_set system in system_safety_test). We need to solve this before we can use the lifetimes given.
This is due to the fact that QuerySet is just a wrapper over Query, which now relies on world lifetimes instead of `&self` lifetimes to prevent aliasing (but in systems, each Query has its own implied lifetime, not a centralized world lifetime). I believe the fix is to rewrite QuerySet to have its own World lifetime (and own the internal reference). This will complicate the impl a bit, but I think it is doable. I'm curious if anyone else has better ideas.
Personally, I think these new lifetimes need to happen. We've gotta have a way to directly tie read-only World queries to the World lifetime. The new renderer is the first place this has come up, but I doubt it will be the last. Worst case scenario we can come up with a second `WorldLifetimeQuery<Q, F = ()>` parameter to enable these read-only scenarios, but I'd rather not add another type to the type zoo.
## Problem
- The `Query` struct does not provide an easy way to check if it is empty.
- Specifically, users have to use `.iter().peekable()` or `.iter().next().is_none()` which is not very ergonomic.
- Fixes: #2270
## Solution
- Implement an `is_empty` function for queries to more easily check if the query is empty.
- simplified code around archetype generations a little bit, as the special case value is not actually needed
- removed unnecessary UnsafeCell around pointer value that is never updated through shared references
- fixed and added a test for correct drop behaviour when removing sparse components through remove_bundle command
Related to [discussion on discord](https://discord.com/channels/691052431525675048/742569353878437978/824731187724681289)
With const generics, it is now possible to write generic iterator over multiple entities at once.
This enables patterns of query iterations like
```rust
for [e1, e2, e3] in query.iter_combinations() {
// do something with relation of all three entities
}
```
The compiler is able to infer the correct iterator for given size of array, so either of those work
```rust
for [e1, e2] in query.iter_combinations() { ... }
for [e1, e2, e3] in query.iter_combinations() { ... }
```
This feature can be very useful for systems like collision detection.
When you ask for permutations of size K of N entities:
- if K == N, you get one result of all entities
- if K < N, you get all possible subsets of N with size K, without repetition
- if K > N, the result set is empty (no permutation of size K exist)
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
{kind=link}
{kind=link}
{kind=link}