# Objective
Transparently uses simple `EnvironmentMapLight`s to mimic
`AmbientLight`s. Implements the first part of #17468, but I can
implement hemispherical lights in this PR too if needed.
## Solution
- A function `EnvironmentMapLight::solid_color(&mut Assets<Image>,
Color)` is provided to make an environment light with a solid color.
- A new system is added to `SimulationLightSystems` that maps
`AmbientLight`s on views or the world to a corresponding
`EnvironmentMapLight`.
I have never worked with (or on) Bevy before, so nitpicky comments on
how I did things are appreciated :).
## Testing
Testing was done on a modified version of the `3d/lighting` example,
where I removed all lights except the ambient light. I have not included
the example, but can if required.
## Migration
`bevy_pbr::AmbientLight` has been deprecated, so all usages of it should
be replaced by a `bevy_pbr::EnvironmentMapLight` created with
`EnvironmentMapLight::solid_color` placed on the camera. There is no
alternative to ambient lights as resources.
# Objective
Fixes#18095
## Solution
Update the feature gates so that `Taa`, etc are added if
- Not on wasm
- OR using webgpu
## Testing
Check that `Taa` is disabled with appropriate messaging on webgl2
```
cargo run -p build-wasm-example -- --api webgl2 transmission && basic-http-server examples/wasm/
```
Check that `Taa` works on webgpu in chrome
```
cargo run -p build-wasm-example -- --api webgpu transmission && basic-http-server examples/wasm/
```
Check that `Taa` still works in a native build
```
cargo run -example transmission
```
# Objective
As discussed in #14275, Bevy is currently too prone to panic, and makes
the easy / beginner-friendly way to do a large number of operations just
to panic on failure.
This is seriously frustrating in library code, but also slows down
development, as many of the `Query::single` panics can actually safely
be an early return (these panics are often due to a small ordering issue
or a change in game state.
More critically, in most "finished" products, panics are unacceptable:
any unexpected failures should be handled elsewhere. That's where the
new
With the advent of good system error handling, we can now remove this.
Note: I was instrumental in a) introducing this idea in the first place
and b) pushing to make the panicking variant the default. The
introduction of both `let else` statements in Rust and the fancy system
error handling work in 0.16 have changed my mind on the right balance
here.
## Solution
1. Make `Query::single` and `Query::single_mut` (and other random
related methods) return a `Result`.
2. Handle all of Bevy's internal usage of these APIs.
3. Deprecate `Query::get_single` and friends, since we've moved their
functionality to the nice names.
4. Add detailed advice on how to best handle these errors.
Generally I like the diff here, although `get_single().unwrap()` in
tests is a bit of a downgrade.
## Testing
I've done a global search for `.single` to track down any missed
deprecated usages.
As to whether or not all the migrations were successful, that's what CI
is for :)
## Future work
~~Rename `Query::get_single` and friends to `Query::single`!~~
~~I've opted not to do this in this PR, and smear it across two releases
in order to ease the migration. Successive deprecations are much easier
to manage than the semantics and types shifting under your feet.~~
Cart has convinced me to change my mind on this; see
https://github.com/bevyengine/bevy/pull/18082#discussion_r1974536085.
## Migration guide
`Query::single`, `Query::single_mut` and their `QueryState` equivalents
now return a `Result`. Generally, you'll want to:
1. Use Bevy 0.16's system error handling to return a `Result` using the
`?` operator.
2. Use a `let else Ok(data)` block to early return if it's an expected
failure.
3. Use `unwrap()` or `Ok` destructuring inside of tests.
The old `Query::get_single` (etc) methods which did this have been
deprecated.
# Objective
There are currently three ways to access the parent stored on a ChildOf
relationship:
1. `child_of.parent` (field accessor)
2. `child_of.get()` (get function)
3. `**child_of` (Deref impl)
I will assert that we should only have one (the field accessor), and
that the existence of the other implementations causes confusion and
legibility issues. The deref approach is heinous, and `child_of.get()`
is significantly less clear than `child_of.parent`.
## Solution
Remove `impl Deref for ChildOf` and `ChildOf::get`.
The one "downside" I'm seeing is that:
```rust
entity.get::<ChildOf>().map(ChildOf::get)
```
Becomes this:
```rust
entity.get::<ChildOf>().map(|c| c.parent)
```
I strongly believe that this is worth the increased clarity and
consistency. I'm also not really a huge fan of the "pass function
pointer to map" syntax. I think most people don't think this way about
maps. They think in terms of a function that takes the item in the
Option and returns the result of some action on it.
## Migration Guide
```rust
// Before
**child_of
// After
child_of.parent
// Before
child_of.get()
// After
child_of.parent
// Before
entity.get::<ChildOf>().map(ChildOf::get)
// After
entity.get::<ChildOf>().map(|c| c.parent)
```
## Objective
Alternative to #18001.
- Now that systems can handle the `?` operator, `get_entity` returning
`Result` would be more useful than `Option`.
- With `get_entity` being more flexible, combined with entity commands
now checking the entity's existence automatically, the panic in `entity`
isn't really necessary.
## Solution
- Changed `Commands::get_entity` to return `Result<EntityCommands,
EntityDoesNotExistError>`.
- Removed panic from `Commands::entity`.
# Objective
fixes#17896
## Solution
Change ChildOf ( Entity ) to ChildOf { parent: Entity }
by doing this we also allow users to use named structs for relationship
derives, When you have more than 1 field in a struct with named fields
the macro will look for a field with the attribute #[relationship] and
all of the other fields should implement the Default trait. Unnamed
fields are still supported.
When u have a unnamed struct with more than one field the macro will
fail.
Do we want to support something like this ?
```rust
#[derive(Component)]
#[relationship_target(relationship = ChildOf)]
pub struct Children (#[relationship] Entity, u8);
```
I could add this, it but doesn't seem nice.
## Testing
crates/bevy_ecs - cargo test
## Showcase
```rust
use bevy_ecs::component::Component;
use bevy_ecs::entity::Entity;
#[derive(Component)]
#[relationship(relationship_target = Children)]
pub struct ChildOf {
#[relationship]
pub parent: Entity,
internal: u8,
};
#[derive(Component)]
#[relationship_target(relationship = ChildOf)]
pub struct Children {
children: Vec<Entity>
};
```
---------
Co-authored-by: Tim Overbeek <oorbecktim@Tims-MacBook-Pro.local>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-042.client.nl.eduvpn.org>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-059.client.nl.eduvpn.org>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-054.client.nl.eduvpn.org>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-027.client.nl.eduvpn.org>
# Objective
So far, built-in BRP methods allow users to interact with entities'
components, but global resources have remained beyond its reach. The
goal of this PR is to take the first steps in rectifying this shortfall.
## Solution
Added five new default methods to BRP:
- `bevy/get_resource`: Extracts the value of a given resource from the
world.
- `bevy/insert_resource`: Serializes an input value to a given resource
type and inserts it into the world.
- `bevy/remove_resource`: Removes the given resource from the world.
- `bevy/mutate_resource`: Replaces the value of a field in a given
resource with the result of serializing a given input value.
- `bevy/list_resources`: Lists all resources in the type registry with
an available `ReflectResource`.
## Testing
Added a test resource to the `server` example scene that you can use to
mess around with the new BRP methods.
## Showcase
Resources can now be retrieved and manipulated remotely using a handful
of new BRP methods. For example, a resource that looks like this:
```rust
#[derive(Resource, Reflect, Serialize, Deserialize)]
#[reflect(Resource, Serialize, Deserialize)]
pub struct PlayerSpawnSettings {
pub location: Vec2,
pub lives: u8,
}
```
can be manipulated remotely as follows.
Retrieving the value of the resource:
```json
{
"jsonrpc": "2.0",
"id": 1,
"method": "bevy/get_resource",
"params": {
"resource": "path::to::my::module::PlayerSpawnSettings"
}
}
```
Inserting a resource value into the world:
```json
{
"jsonrpc": "2.0",
"id": 2,
"method": "bevy/insert_resource",
"params": {
"resource": "path::to::my::module::PlayerSpawnSettings",
"value": {
"location": [
2.5,
2.5
],
"lives": 25
}
}
}
```
Removing the resource from the world:
```json
{
"jsonrpc": "2.0",
"id": 3,
"method": "bevy/remove_resource",
"params": {
"resource": "path::to::my::module::PlayerSpawnSettings"
}
}
```
Mutating a field of the resource specified by a path:
```json
{
"jsonrpc": "2.0",
"id": 4,
"method": "bevy/mutate_resource",
"params": {
"resource": "path::to::my::module::PlayerSpawnSettings",
"path": ".location.x",
"value": -3.0
}
}
```
Listing all manipulable resources in the type registry:
```json
{
"jsonrpc": "2.0",
"id": 5,
"method": "bevy/list_resources"
}
```
# Objective
Implements and closes#17515
## Solution
Add `uv_transform` to `ColorMaterial`
## Testing
Create a example similar to `repeated_texture` but for `Mesh2d` and
`MeshMaterial2d<ColorMaterial>`
## Showcase

## Migration Guide
Add `uv_transform` field to constructors of `ColorMaterial`
# Objective
I noticed when I was looking at the embedded assets example that there
wasn't any comments on it to indicate what an embedded asset is and why
anyone would want to make one.
## Solution
I added some more comments to the example that gives more detail about
embedded assets and how they work. Feel free to be aggressive with
rewriting these comments however, I just think the example could use
something haha.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fix https://github.com/bevyengine/bevy/issues/17108
See
https://github.com/bevyengine/bevy/issues/17108#issuecomment-2653020889
## Solution
- Make the query match `&Pickable` instead `Option<&Pickable>`
## Testing
- Run the `sprite_picking` example and everything still work
## Migration Guide
- Sprite picking are now opt-in, make sure you insert `Pickable`
component when using sprite picking.
```diff
-commands.spawn(Sprite { .. } );
+commands.spawn((Sprite { .. }, Pickable::default());
```
# Objective
- Fixes#17960
## Solution
- Followed the [edition upgrade
guide](https://doc.rust-lang.org/edition-guide/editions/transitioning-an-existing-project-to-a-new-edition.html)
## Testing
- CI
---
## Summary of Changes
### Documentation Indentation
When using lists in documentation, proper indentation is now linted for.
This means subsequent lines within the same list item must start at the
same indentation level as the item.
```rust
/* Valid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
/* Invalid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
```
### Implicit `!` to `()` Conversion
`!` (the never return type, returned by `panic!`, etc.) no longer
implicitly converts to `()`. This is particularly painful for systems
with `todo!` or `panic!` statements, as they will no longer be functions
returning `()` (or `Result<()>`), making them invalid systems for
functions like `add_systems`. The ideal fix would be to accept functions
returning `!` (or rather, _not_ returning), but this is blocked on the
[stabilisation of the `!` type
itself](https://doc.rust-lang.org/std/primitive.never.html), which is
not done.
The "simple" fix would be to add an explicit `-> ()` to system
signatures (e.g., `|| { todo!() }` becomes `|| -> () { todo!() }`).
However, this is _also_ banned, as there is an existing lint which (IMO,
incorrectly) marks this as an unnecessary annotation.
So, the "fix" (read: workaround) is to put these kinds of `|| -> ! { ...
}` closuers into variables and give the variable an explicit type (e.g.,
`fn()`).
```rust
// Valid
let system: fn() = || todo!("Not implemented yet!");
app.add_systems(..., system);
// Invalid
app.add_systems(..., || todo!("Not implemented yet!"));
```
### Temporary Variable Lifetimes
The order in which temporary variables are dropped has changed. The
simple fix here is _usually_ to just assign temporaries to a named
variable before use.
### `gen` is a keyword
We can no longer use the name `gen` as it is reserved for a future
generator syntax. This involved replacing uses of the name `gen` with
`r#gen` (the raw-identifier syntax).
### Formatting has changed
Use statements have had the order of imports changed, causing a
substantial +/-3,000 diff when applied. For now, I have opted-out of
this change by amending `rustfmt.toml`
```toml
style_edition = "2021"
```
This preserves the original formatting for now, reducing the size of
this PR. It would be a simple followup to update this to 2024 and run
`cargo fmt`.
### New `use<>` Opt-Out Syntax
Lifetimes are now implicitly included in RPIT types. There was a handful
of instances where it needed to be added to satisfy the borrow checker,
but there may be more cases where it _should_ be added to avoid
breakages in user code.
### `MyUnitStruct { .. }` is an invalid pattern
Previously, you could match against unit structs (and unit enum
variants) with a `{ .. }` destructuring. This is no longer valid.
### Pretty much every use of `ref` and `mut` are gone
Pattern binding has changed to the point where these terms are largely
unused now. They still serve a purpose, but it is far more niche now.
### `iter::repeat(...).take(...)` is bad
New lint recommends using the more explicit `iter::repeat_n(..., ...)`
instead.
## Migration Guide
The lifetimes of functions using return-position impl-trait (RPIT) are
likely _more_ conservative than they had been previously. If you
encounter lifetime issues with such a function, please create an issue
to investigate the addition of `+ use<...>`.
## Notes
- Check the individual commits for a clearer breakdown for what
_actually_ changed.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
Fixes#17856.
## Migration Guide
- `EventWriter::send` has been renamed to `EventWriter::write`.
- `EventWriter::send_batch` has been renamed to
`EventWriter::write_batch`.
- `EventWriter::send_default` has been renamed to
`EventWriter::write_default`.
---------
Co-authored-by: François Mockers <mockersf@gmail.com>
Two-phase occlusion culling can be helpful for shadow maps just as it
can for a prepass, in order to reduce vertex and alpha mask fragment
shading overhead. This patch implements occlusion culling for shadow
maps from directional lights, when the `OcclusionCulling` component is
present on the entities containing the lights. Shadow maps from point
lights are deferred to a follow-up patch. Much of this patch involves
expanding the hierarchical Z-buffer to cover shadow maps in addition to
standard view depth buffers.
The `scene_viewer` example has been updated to add `OcclusionCulling` to
the directional light that it creates.
This improved the performance of the rend3 sci-fi test scene when
enabling shadows.
Currently, Bevy's implementation of bindless resources is rather
unusual: every binding in an object that implements `AsBindGroup` (most
commonly, a material) becomes its own separate binding array in the
shader. This is inefficient for two reasons:
1. If multiple materials reference the same texture or other resource,
the reference to that resource will be duplicated many times. This
increases `wgpu` validation overhead.
2. It creates many unused binding array slots. This increases `wgpu` and
driver overhead and makes it easier to hit limits on APIs that `wgpu`
currently imposes tight resource limits on, like Metal.
This PR fixes these issues by switching Bevy to use the standard
approach in GPU-driven renderers, in which resources are de-duplicated
and passed as global arrays, one for each type of resource.
Along the way, this patch introduces per-platform resource limits and
bumps them from 16 resources per binding array to 64 resources per bind
group on Metal and 2048 resources per bind group on other platforms.
(Note that the number of resources per *binding array* isn't the same as
the number of resources per *bind group*; as it currently stands, if all
the PBR features are turned on, Bevy could pack as many as 496 resources
into a single slab.) The limits have been increased because `wgpu` now
has universal support for partially-bound binding arrays, which mean
that we no longer need to fill the binding arrays with fallback
resources on Direct3D 12. The `#[bindless(LIMIT)]` declaration when
deriving `AsBindGroup` can now simply be written `#[bindless]` in order
to have Bevy choose a default limit size for the current platform.
Custom limits are still available with the new
`#[bindless(limit(LIMIT))]` syntax: e.g. `#[bindless(limit(8))]`.
The material bind group allocator has been completely rewritten. Now
there are two allocators: one for bindless materials and one for
non-bindless materials. The new non-bindless material allocator simply
maintains a 1:1 mapping from material to bind group. The new bindless
material allocator maintains a list of slabs and allocates materials
into slabs on a first-fit basis. This unfortunately makes its
performance O(number of resources per object * number of slabs), but the
number of slabs is likely to be low, and it's planned to become even
lower in the future with `wgpu` improvements. Resources are
de-duplicated with in a slab and reference counted. So, for instance, if
multiple materials refer to the same texture, that texture will exist
only once in the appropriate binding array.
To support these new features, this patch adds the concept of a
*bindless descriptor* to the `AsBindGroup` trait. The bindless
descriptor allows the material bind group allocator to probe the layout
of the material, now that an array of `BindGroupLayoutEntry` records is
insufficient to describe the group. The `#[derive(AsBindGroup)]` has
been heavily modified to support the new features. The most important
user-facing change to that macro is that the struct-level `uniform`
attribute, `#[uniform(BINDING_NUMBER, StandardMaterial)]`, now reads
`#[uniform(BINDLESS_INDEX, MATERIAL_UNIFORM_TYPE,
binding_array(BINDING_NUMBER)]`, allowing the material to specify the
binding number for the binding array that holds the uniform data.
To make this patch simpler, I removed support for bindless
`ExtendedMaterial`s, as well as field-level bindless uniform and storage
buffers. I intend to add back support for these as a follow-up. Because
they aren't in any released Bevy version yet, I figured this was OK.
Finally, this patch updates `StandardMaterial` for the new bindless
changes. Generally, code throughout the PBR shaders that looked like
`base_color_texture[slot]` now looks like
`bindless_2d_textures[material_indices[slot].base_color_texture]`.
This patch fixes a system hang that I experienced on the [Caldera test]
when running with `caldera --random-materials --texture-count 100`. The
time per frame is around 19.75 ms, down from 154.2 ms in Bevy 0.14: a
7.8× speedup.
[Caldera test]: https://github.com/DGriffin91/bevy_caldera_scene
Deferred rendering currently doesn't support occlusion culling. This PR
implements it in a straightforward way, mirroring what we already do for
the non-deferred pipeline.
On the rend3 sci-fi base test scene, this resulted in roughly a 2×
speedup when applied on top of my other patches. For that scene, it was
useful to add another option, `--add-light`, which forces the addition
of a shadow-casting light, to the scene viewer, which I included in this
patch.
This adds an option to animate the materials in the `many_cubes` stress
test. Each material instance `base_color` is varied each frame.
This has been tested in conjunction with the
`--vary-material-data-per-instance` and `--material-texture-count`
options.
If `--vary-material-data-per-instance` is not used it will just update
the single material, otherwise it will update all of them. If
`--material-texture-count` is used the `base_color` is multiplied with
the texture so the effect is still visible.
Because this test is focused on the performance of updating material
data and not the performance of bevy's color system it uses its own
function (`fast_hue_to_rgb`) to quickly set the hue. This appeared to be
around 8x faster than using `base_color.set_hue(hue)` in the tight loop.
Currently, Bevy rebuilds the buffer containing all the transforms for
joints every frame, during the extraction phase. This is inefficient in
cases in which many skins are present in the scene and their joints
don't move, such as the Caldera test scene.
To address this problem, this commit switches skin extraction to use a
set of retained GPU buffers with allocations managed by the offset
allocator. I use fine-grained change detection in order to determine
which skins need updating. Note that the granularity is on the level of
an entire skin, not individual joints. Using the change detection at
that level would yield poor performance in common cases in which an
entire skin is animated at once. Also, this patch yields additional
performance from the fact that changing joint transforms no longer
requires the skinned mesh to be re-extracted.
Note that this optimization can be a double-edged sword. In
`many_foxes`, fine-grained change detection regressed the performance of
`extract_skins` by 3.4x. This is because every joint is updated every
frame in that example, so change detection is pointless and is pure
overhead. Because the `many_foxes` workload is actually representative
of animated scenes, this patch includes a heuristic that disables
fine-grained change detection if the number of transformed entities in
the frame exceeds a certain fraction of the total number of joints.
Currently, this threshold is set to 25%. Note that this is a crude
heuristic, because it doesn't distinguish between the number of
transformed *joints* and the number of transformed *entities*; however,
it should be good enough to yield the optimum code path most of the
time.
Finally, this patch fixes a bug whereby skinned meshes are actually
being incorrectly retained if the buffer offsets of the joints of those
skinned meshes changes from frame to frame. To fix this without
retaining skins, we would have to re-extract every skinned mesh every
frame. Doing this was a significant regression on Caldera. With this PR,
by contrast, mesh joints stay at the same buffer offset, so we don't
have to update the `MeshInputUniform` containing the buffer offset every
frame. This also makes PR #17717 easier to implement, because that PR
uses the buffer offset from the previous frame, and the logic for
calculating that is simplified if the previous frame's buffer offset is
guaranteed to be identical to that of the current frame.
On Caldera, this patch reduces the time spent in `extract_skins` from
1.79 ms to near zero. On `many_foxes`, this patch regresses the
performance of `extract_skins` by approximately 10%-25%, depending on
the number of foxes. This has only a small impact on frame rate.
The GPU can fill out many of the fields in `IndirectParametersMetadata`
using information it already has:
* `early_instance_count` and `late_instance_count` are always
initialized to zero.
* `mesh_index` is already present in the work item buffer as the
`input_index` of the first work item in each batch.
This patch moves these fields to a separate buffer, the *GPU indirect
parameters metadata* buffer. That way, it avoids having to write them on
CPU during `batch_and_prepare_binned_render_phase`. This effectively
reduces the number of bits that that function must write per mesh from
160 to 64 (in addition to the 64 bits per mesh *instance*).
Additionally, this PR refactors `UntypedPhaseIndirectParametersBuffers`
to add another layer, `MeshClassIndirectParametersBuffers`, which allows
abstracting over the buffers corresponding indexed and non-indexed
meshes. This patch doesn't make much use of this abstraction, but
forthcoming patches will, and it's overall a cleaner approach.
This didn't seem to have much of an effect by itself on
`batch_and_prepare_binned_render_phase` time, but subsequent PRs
dependent on this PR yield roughly a 2× speedup.
# Objective
Fix panic in `custom_render_phase`.
This example was broken by #17764, but that breakage evolved into a
panic after #17849. This new panic seems to illustrate the problem in a
pretty straightforward way.
```
2025-02-15T00:44:11.833622Z INFO bevy_diagnostic::system_information_diagnostics_plugin::internal: SystemInfo { os: "macOS 15.3 Sequoia", kernel: "24.3.0", cpu: "Apple M4 Max", core_count: "16", memory: "64.0 GiB" }
2025-02-15T00:44:11.908328Z INFO bevy_render::renderer: AdapterInfo { name: "Apple M4 Max", vendor: 0, device: 0, device_type: IntegratedGpu, driver: "", driver_info: "", backend: Metal }
2025-02-15T00:44:12.314930Z INFO bevy_winit::system: Creating new window App (0v1)
thread 'Compute Task Pool (1)' panicked at /Users/me/src/bevy/crates/bevy_ecs/src/system/function_system.rs:216:28:
bevy_render::batching::gpu_preprocessing::batch_and_prepare_sorted_render_phase<custom_render_phase::Stencil3d, custom_render_phase::StencilPipeline> could not access system parameter ResMut<PhaseBatchedInstanceBuffers<Stencil3d, MeshUniform>>
```
## Solution
Add a `SortedRenderPhasePlugin` for the custom phase.
## Testing
`cargo run --example custom_render_phase`
# Objective
Fixes#17851
## Solution
Align the `slider` uniform to 16 bytes by making it a `vec4`.
## Testing
Run the example using:
```
cargo run -p build-wasm-example -- --api webgl2 ui_material
basic-http-server examples/wasm/
```
The `output_index` field is only used in direct mode, and the
`indirect_parameters_index` field is only used in indirect mode.
Consequently, we can combine them into a single field, reducing the size
of `PreprocessWorkItem`, which
`batch_and_prepare_{binned,sorted}_render_phase` must construct every
frame for every mesh instance, from 96 bits to 64 bits.
Currently, invocations of `batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` can't run in parallel because
they write to scene-global GPU buffers. After PR #17698,
`batch_and_prepare_binned_render_phase` started accounting for the
lion's share of the CPU time, causing us to be strongly CPU bound on
scenes like Caldera when occlusion culling was on (because of the
overhead of batching for the Z-prepass). Although I eventually plan to
optimize `batch_and_prepare_binned_render_phase`, we can obtain
significant wins now by parallelizing that system across phases.
This commit splits all GPU buffers that
`batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` touches into separate buffers
for each phase so that the scheduler will run those phases in parallel.
At the end of batch preparation, we gather the render phases up into a
single resource with a new *collection* phase. Because we already run
mesh preprocessing separately for each phase in order to make occlusion
culling work, this is actually a cleaner separation. For example, mesh
output indices (the unique ID that identifies each mesh instance on GPU)
are now guaranteed to be sequential starting from 0, which will simplify
the forthcoming work to remove them in favor of the compute dispatch ID.
On Caldera, this brings the frame time down to approximately 9.1 ms with
occlusion culling on.

# Objective
Tidy up a few little things I noticed while working with this example
## Solution
- Fix manual resetting of a repeating timer
- Use atlas image size instead of hardcoded value. Atlases are always
512x512 right now, but hopefully not in the future.
- Pluralize a variable name for a variable holding a `Vec`
# Objective
I'm working on some PRs involving our font atlases and it would be nice
to be able to test these scenarios separately to better understand the
performance tradeoffs in different situations.
## Solution
Add a `many-font-sizes` option.
The old behavior is still available by running with `--many-glyphs
--many-font-sizes`.
## Testing
`cargo run --example many_text2d --release`
`cargo run --example many_text2d --release -- --many-glyphs`
`cargo run --example many_text2d --release -- --many-font-sizes`
`cargo run --example many_text2d --release -- --many-glyphs
--many-font-sizes`
# Objective
Fixes#17810
Y'all picked the option I already implemented, yay.
## Solution
Add a system that panics if the load state of an asset is `Failed`.
## Testing
`cargo run --example scene`
- Tested with valid scene file
- Introduced a syntax error in the scene file
- Deleted the scene file
## Objective
Get rid of a redundant Cargo feature flag.
## Solution
Use the built-in `target_abi = "sim"` instead of a custom Cargo feature
flag, which is set for the iOS (and visionOS and tvOS) simulator. This
has been stable since Rust 1.78.
In the future, some of this may become redundant if Wgpu implements
proper supper for the iOS Simulator:
https://github.com/gfx-rs/wgpu/issues/7057
CC @mockersf who implemented [the original
fix](https://github.com/bevyengine/bevy/pull/10178).
## Testing
- Open mobile example in Xcode.
- Launch the simulator.
- See that no errors are emitted.
- Remove the code cfg-guarded behind `target_abi = "sim"`.
- See that an error now happens.
(I haven't actually performed these steps on the latest `main`, because
I'm hitting an unrelated error (EDIT: It was
https://github.com/bevyengine/bevy/pull/17637). But tested it on
0.15.0).
---
## Migration Guide
> If you're using a project that builds upon the mobile example, remove
the `ios_simulator` feature from your `Cargo.toml` (Bevy now handles
this internally).
Currently, we look up each `MeshInputUniform` index in a hash table that
maps the main entity ID to the index every frame. This is inefficient,
cache unfriendly, and unnecessary, as the `MeshInputUniform` index for
an entity remains the same from frame to frame (even if the input
uniform changes). This commit changes the `IndexSet` in the `RenderBin`
to an `IndexMap` that maps the `MainEntity` to `MeshInputUniformIndex`
(a new type that this patch adds for more type safety).
On Caldera with parallel `batch_and_prepare_binned_render_phase`, this
patch improves that function from 3.18 ms to 2.42 ms, a 31% speedup.
# Objective
Allow switching through available Tonemapping algorithms on `bloom_2d`
example to compare between them
## Solution
Add a resource to `bloom_2d` that holds current tonemapping algorithm, a
method to get the next one, and a check of key press to make the switch
## Testing
Ran `bloom_2d` example with modified code
## Showcase
https://github.com/user-attachments/assets/920b2d6a-b237-4b19-be9d-9b651b4dc913
Note: Sprite flashing is already described in #17763
# Objective
Fix gltf validation errors in `Fox.glb`.
Inspired by #8099, but that issue doesn't appear to describe a real bug
to fix, as far as I can tell.
## Solution
Use the latest version of the Fox from
[glTF-Sample-Assets](https://github.com/KhronosGroup/glTF-Sample-Assets/blob/main/Models/Fox/glTF-Binary/Fox.glb).
## Testing
Dropped both versions in https://github.khronos.org/glTF-Validator/
`cargo run --example animated_mesh` seems to still look fine.
Before:
```
The asset contains errors.
"numErrors": 126,
"numWarnings": 4184,
```
After:
```
The asset is valid.
"numErrors": 0,
"numWarnings": 0,
```
## Discussion
The 3d testbed was panicking with
```
thread 'main' panicked at examples/testbed/3d.rs:288:60:
called `Result::unwrap()` on an `Err` value: QueryDoesNotMatch(35v1 with components Transform, GlobalTransform, Visibility, InheritedVisibility, ViewVisibility, ChildOf, Children, Name)
```
Which is bizarre. I think this might be related to #17720, or maybe the
structure of the gltf changed.
I fixed it by using updating the testbed to use a more robust method of
finding the correct entity as is done in `animated_mesh`.
# Objective
- In #17743, attention was raised to the fact that we supported an
unusual kind of step easing function. The author of the fix kindly
provided some links to standards used in CSS. It would be desirable to
support generally agreed upon standards so this PR here tries to
implement an extra configuration option of the step easing function
- Resolve#17744
## Solution
- Introduce `StepConfig`
- `StepConfig` can configure both the number of steps and the jumping
behavior of the function
- `StepConfig` replaces the raw `usize` parameter of the
`EasingFunction::Steps(usize)` construct.
- `StepConfig`s default jumping behavior is `end`, so in that way it
follows #17743
## Testing
- I added a new test per `JumpAt` jumping behavior. These tests
replicate the visuals that can be found at
https://developer.mozilla.org/en-US/docs/Web/CSS/easing-function/steps#description
## Migration Guide
- `EasingFunction::Steps` now uses a `StepConfig` instead of a raw
`usize`. You can replicate the previous behavior by replaceing
`EasingFunction::Steps(10)` with
`EasingFunction::Steps(StepConfig::new(10))`.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
This commit builds on top of the work done in #16589 and #17051, by
adding support for fallible observer systems.
As with the previous work, the actual results of the observer system are
suppressed for now, but the intention is to provide a way to handle
errors in a global way.
Until then, you can use a `PipeSystem` to manually handle results.
---------
Signed-off-by: Jean Mertz <git@jeanmertz.com>
You can now configure error handlers for fallible systems. These can be
configured on several levels:
- Globally via `App::set_systems_error_handler`
- Per-schedule via `Schedule::set_error_handler`
- Per-system via a piped system (this is existing functionality)
The default handler of panicking on error keeps the same behavior as
before this commit.
The "fallible_systems" example demonstrates the new functionality.
This builds on top of #17731, #16589, #17051.
---------
Signed-off-by: Jean Mertz <git@jeanmertz.com>
# Objective
Add some multi-span text to the `many_buttons` benchmark by splitting up
each button label text into two different coloured text spans.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Because of mesh preprocessing, users cannot rely on
`@builtin(instance_index)` in order to reference external data, as the
instance index is not stable, either from frame to frame or relative to
the total spawn order of mesh instances.
## Solution
Add a user supplied mesh index that can be used for referencing external
data when drawing instanced meshes.
Closes#13373
## Testing
Benchmarked `many_cubes` showing no difference in total frame time.
## Showcase
https://github.com/user-attachments/assets/80620147-aafc-4d9d-a8ee-e2149f7c8f3b
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
https://github.com/bevyengine/bevy/issues/17746
## Solution
- Change `Image.data` from being a `Vec<u8>` to a `Option<Vec<u8>>`
- Added functions to help with creating images
## Testing
- Did you test these changes? If so, how?
All current tests pass
Tested a variety of existing examples to make sure they don't crash
(they don't)
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
Linux x86 64-bit NixOS
---
## Migration Guide
Code that directly access `Image` data will now need to use unwrap or
handle the case where no data is provided.
Behaviour of new_fill slightly changed, but not in a way that is likely
to affect anything. It no longer panics and will fill the whole texture
instead of leaving black pixels if the data provided is not a nice
factor of the size of the image.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Allow users to configure volume using decibels by changing the
`Volume` type from newtyping an `f32` to an enum with `Linear` and
`Decibels` variants.
- Fixes#9507.
- Alternative reworked version of closed#9582.
## Solution
Compared to https://github.com/bevyengine/bevy/pull/9582, this PR has
the following main differences:
1. It uses the term "linear scale" instead of "amplitude" per
https://github.com/bevyengine/bevy/pull/9582/files#r1513529491.
2. Supports `ops` for doing `Volume` arithmetic. Can add two volumes,
e.g. to increase/decrease the current volume. Can multiply two volumes,
e.g. to get the “effective” volume of an audio source considering global
volume.
[requested and blessed on Discord]:
https://discord.com/channels/691052431525675048/749430447326625812/1318272597003341867
## Testing
- Ran `cargo run --example soundtrack`.
- Ran `cargo run --example audio_control`.
- Ran `cargo run --example spatial_audio_2d`.
- Ran `cargo run --example spatial_audio_3d`.
- Ran `cargo run --example pitch`.
- Ran `cargo run --example decodable`.
- Ran `cargo run --example audio`.
---
## Migration Guide
Audio volume can now be configured using decibel values, as well as
using linear scale values. To enable this, some types and functions in
`bevy_audio` have changed.
- `Volume` is now an enum with `Linear` and `Decibels` variants.
Before:
```rust
let v = Volume(1.0);
```
After:
```rust
let volume = Volume::Linear(1.0);
let volume = Volume::Decibels(0.0); // or now you can deal with decibels if you prefer
```
- `Volume::ZERO` has been renamed to the more semantically correct
`Volume::SILENT` because `Volume` now supports decibels and "zero
volume" in decibels actually means "normal volume".
- The `AudioSinkPlayback` trait's volume-related methods now deal with
`Volume` types rather than `f32`s. `AudioSinkPlayback::volume()` now
returns a `Volume` rather than an `f32`. `AudioSinkPlayback::set_volume`
now receives a `Volume` rather than an `f32`. This affects the
`AudioSink` and `SpatialAudioSink` implementations of the trait. The
previous `f32` values are equivalent to the volume converted to linear
scale so the `Volume:: Linear` variant should be used to migrate between
`f32`s and `Volume`.
- The `GlobalVolume::new` function now receives a `Volume` instead of an
`f32`.
---------
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
# Objective
- It's currently very hard for beginners and advanced users to get a
full understanding of a complete render phase.
## Solution
- Implement a full custom render phase
- The render phase in the example is intended to show a custom stencil
phase that renders the stencil in red directly on the screen
---
## Showcase
<img width="1277" alt="image"
src="https://github.com/user-attachments/assets/e9dc0105-4fb6-463f-ad53-0529b575fd28"
/>
## Notes
More docs to explain what is going on is still needed but the example
works and can already help some people.
We might want to consider using a batched phase and cold specialization
in the future, but the example is already complex enough as it is.
---------
Co-authored-by: Christopher Biscardi <chris@christopherbiscardi.com>
# Objective
- I was getting familiar with the many_components example to test some
recent pr's for executor changes and saw some things to improve.
## Solution
- Use `insert_by_ids` instead of `insert_by_id`. This reduces the number
of archetype moves and improves startup times substantially.
- Add a tracing span to `base_system`. I'm not sure why, but tracing
spans weren't showing for this system. I think it's something to do with
how pipe system works, but need to investigate more. The approach in
this pr is a little better than the default span too, since it allows
adding the number of entities queried to the span which is not possible
with the default system span.
- println the number of archetype component id's that are created. This
is useful since part of the purpose of this stress test is to test how
well the use of FixedBitSet scales in the executor.
## Testing
- Ran the example with `cargo run --example many_components -F
trace_tracy 1000000` and connected with tracy
- Timed the time it took to spawn 1 million entities on main (240 s) vs
this pr (15 s)
---
## Showcase

## Future Work
- Currently systems are created with a random set of components and
entities are created with a random set of components without any
correlation between the randomness. This means that some systems won't
match any entities and some entities could not match any systems. It
might be better to spawn the entities from the pool of components that
match the queries that the systems are using.
# Objective
Fixes#15417.
## Solution
- Remove the `labeled_assets` fields from `LoadedAsset` and
`ErasedLoadedAsset`.
- Created new structs `CompleteLoadedAsset` and
`CompleteErasedLoadedAsset` to hold the `labeled_subassets`.
- When a subasset is `LoadContext::finish`ed, it produces a
`CompleteLoadedAsset`.
- When a `CompleteLoadedAsset` is added to a `LoadContext` (as a
subasset), their `labeled_assets` are merged, reporting any overlaps.
One important detail to note: nested subassets with overlapping names
could in theory have been used in the past for the purposes of asset
preprocessing. Even though there was no way to access these "shadowed"
nested subassets, asset preprocessing does get access to these nested
subassets. This does not seem like a case we should support though. It
is confusing at best.
## Testing
- This is just a refactor.
---
## Migration Guide
- Most uses of `LoadedAsset` and `ErasedLoadedAsset` should be replaced
with `CompleteLoadedAsset` and `CompleteErasedLoadedAsset` respectively.
# Objective
It's difficult to understand or make changes to the UI systems because
of how each system needs to individually track changes to scale factor,
windows and camera targets in local hashmaps, particularly for new
contributors. Any major change inevitably introduces new scale factor
bugs.
Instead of per-system resolution we can resolve the camera target info
for all UI nodes in a system at the start of `PostUpdate` and then store
it per-node in components that can be queried with change detection.
Fixes#17578Fixes#15143
## Solution
Store the UI render target's data locally per node in a component that
is updated in `PostUpdate` before any other UI systems run.
This component can be then be queried with change detection so that UI
systems no longer need to have knowledge of cameras and windows and
don't require fragile custom change detection solutions using local
hashmaps.
## Showcase
Compare `measure_text_system` from main (which has a bug the causes it
to use the wrong scale factor when a node's camera target changes):
```
pub fn measure_text_system(
mut scale_factors_buffer: Local<EntityHashMap<f32>>,
mut last_scale_factors: Local<EntityHashMap<f32>>,
fonts: Res<Assets<Font>>,
camera_query: Query<(Entity, &Camera)>,
default_ui_camera: DefaultUiCamera,
ui_scale: Res<UiScale>,
mut text_query: Query<
(
Entity,
Ref<TextLayout>,
&mut ContentSize,
&mut TextNodeFlags,
&mut ComputedTextBlock,
Option<&UiTargetCamera>,
),
With<Node>,
>,
mut text_reader: TextUiReader,
mut text_pipeline: ResMut<TextPipeline>,
mut font_system: ResMut<CosmicFontSystem>,
) {
scale_factors_buffer.clear();
let default_camera_entity = default_ui_camera.get();
for (entity, block, content_size, text_flags, computed, maybe_camera) in &mut text_query {
let Some(camera_entity) = maybe_camera
.map(UiTargetCamera::entity)
.or(default_camera_entity)
else {
continue;
};
let scale_factor = match scale_factors_buffer.entry(camera_entity) {
Entry::Occupied(entry) => *entry.get(),
Entry::Vacant(entry) => *entry.insert(
camera_query
.get(camera_entity)
.ok()
.and_then(|(_, c)| c.target_scaling_factor())
.unwrap_or(1.0)
* ui_scale.0,
),
};
if last_scale_factors.get(&camera_entity) != Some(&scale_factor)
|| computed.needs_rerender()
|| text_flags.needs_measure_fn
|| content_size.is_added()
{
create_text_measure(
entity,
&fonts,
scale_factor.into(),
text_reader.iter(entity),
block,
&mut text_pipeline,
content_size,
text_flags,
computed,
&mut font_system,
);
}
}
core::mem::swap(&mut *last_scale_factors, &mut *scale_factors_buffer);
}
```
with `measure_text_system` from this PR (which always uses the correct
scale factor):
```
pub fn measure_text_system(
fonts: Res<Assets<Font>>,
mut text_query: Query<
(
Entity,
Ref<TextLayout>,
&mut ContentSize,
&mut TextNodeFlags,
&mut ComputedTextBlock,
Ref<ComputedNodeTarget>,
),
With<Node>,
>,
mut text_reader: TextUiReader,
mut text_pipeline: ResMut<TextPipeline>,
mut font_system: ResMut<CosmicFontSystem>,
) {
for (entity, block, content_size, text_flags, computed, computed_target) in &mut text_query {
// Note: the ComputedTextBlock::needs_rerender bool is cleared in create_text_measure().
if computed_target.is_changed()
|| computed.needs_rerender()
|| text_flags.needs_measure_fn
|| content_size.is_added()
{
create_text_measure(
entity,
&fonts,
computed_target.scale_factor.into(),
text_reader.iter(entity),
block,
&mut text_pipeline,
content_size,
text_flags,
computed,
&mut font_system,
);
}
}
}
```
## Testing
I removed an alarming number of tests from the `layout` module but they
were mostly to do with the deleted camera synchronisation logic. The
remaining tests should all pass now.
The most relevant examples are `multiple_windows` and `split_screen`,
the behaviour of both should be unchanged from main.
---------
Co-authored-by: UkoeHB <37489173+UkoeHB@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
A major critique of Bevy at the moment is how boilerplatey it is to
compose (and read) entity hierarchies:
```rust
commands
.spawn(Foo)
.with_children(|p| {
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
});
```
There is also currently no good way to statically define and return an
entity hierarchy from a function. Instead, people often do this
"internally" with a Commands function that returns nothing, making it
impossible to spawn the hierarchy in other cases (direct World spawns,
ChildSpawner, etc).
Additionally, because this style of API results in creating the
hierarchy bits _after_ the initial spawn of a bundle, it causes ECS
archetype changes (and often expensive table moves).
Because children are initialized after the fact, we also can't count
them to pre-allocate space. This means each time a child inserts itself,
it has a high chance of overflowing the currently allocated capacity in
the `RelationshipTarget` collection, causing literal worst-case
reallocations.
We can do better!
## Solution
The Bundle trait has been extended to support an optional
`BundleEffect`. This is applied directly to World immediately _after_
the Bundle has fully inserted. Note that this is
[intentionally](https://github.com/bevyengine/bevy/discussions/16920)
_not done via a deferred Command_, which would require repeatedly
copying each remaining subtree of the hierarchy to a new command as we
walk down the tree (_not_ good performance).
This allows us to implement the new `SpawnRelated` trait for all
`RelationshipTarget` impls, which looks like this in practice:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
))
))
```
`Children::spawn` returns `SpawnRelatedBundle<Children, L:
SpawnableList>`, which is a `Bundle` that inserts `Children`
(preallocated to the size of the `SpawnableList::size_hint()`).
`Spawn<B: Bundle>(pub B)` implements `SpawnableList` with a size of 1.
`SpawnableList` is also implemented for tuples of `SpawnableList` (same
general pattern as the Bundle impl).
There are currently three built-in `SpawnableList` implementations:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn(Name::new("Child1")),
SpawnIter(["Child2", "Child3"].into_iter().map(Name::new),
SpawnWith(|parent: &mut ChildSpawner| {
parent.spawn(Name::new("Child4"));
parent.spawn(Name::new("Child5"));
})
)),
))
```
We get the benefits of "structured init", but we have nice flexibility
where it is required!
Some readers' first instinct might be to try to remove the need for the
`Spawn` wrapper. This is impossible in the Rust type system, as a tuple
of "child Bundles to be spawned" and a "tuple of Components to be added
via a single Bundle" is ambiguous in the Rust type system. There are two
ways to resolve that ambiguity:
1. By adding support for variadics to the Rust type system (removing the
need for nested bundles). This is out of scope for this PR :)
2. Using wrapper types to resolve the ambiguity (this is what I did in
this PR).
For the single-entity spawn cases, `Children::spawn_one` does also
exist, which removes the need for the wrapper:
```rust
world.spawn((
Foo,
Children::spawn_one(Bar),
))
```
## This works for all Relationships
This API isn't just for `Children` / `ChildOf` relationships. It works
for any relationship type, and they can be mixed and matched!
```rust
world.spawn((
Foo,
Observers::spawn((
Spawn(Observer::new(|trigger: Trigger<FuseLit>| {})),
Spawn(Observer::new(|trigger: Trigger<Exploded>| {})),
)),
OwnerOf::spawn(Spawn(Bar))
Children::spawn(Spawn(Baz))
))
```
## Macros
While `Spawn` is necessary to satisfy the type system, we _can_ remove
the need to express it via macros. The example above can be expressed
more succinctly using the new `children![X]` macro, which internally
produces `Children::spawn(Spawn(X))`:
```rust
world.spawn((
Foo,
children![
(
Bar,
children![Baz],
),
(
Bar,
children![Baz],
),
]
))
```
There is also a `related!` macro, which is a generic version of the
`children!` macro that supports any relationship type:
```rust
world.spawn((
Foo,
related!(Children[
(
Bar,
related!(Children[Baz]),
),
(
Bar,
related!(Children[Baz]),
),
])
))
```
## Returning Hierarchies from Functions
Thanks to these changes, the following pattern is now possible:
```rust
fn button(text: &str, color: Color) -> impl Bundle {
(
Node {
width: Val::Px(300.),
height: Val::Px(100.),
..default()
},
BackgroundColor(color),
children![
Text::new(text),
]
)
}
fn ui() -> impl Bundle {
(
Node {
width: Val::Percent(100.0),
height: Val::Percent(100.0),
..default(),
},
children![
button("hello", BLUE),
button("world", RED),
]
)
}
// spawn from a system
fn system(mut commands: Commands) {
commands.spawn(ui());
}
// spawn directly on World
world.spawn(ui());
```
## Additional Changes and Notes
* `Bundle::from_components` has been split out into
`BundleFromComponents::from_components`, enabling us to implement
`Bundle` for types that cannot be "taken" from the ECS (such as the new
`SpawnRelatedBundle`).
* The `NoBundleEffect` trait (which implements `BundleEffect`) is
implemented for empty tuples (and tuples of empty tuples), which allows
us to constrain APIs to only accept bundles that do not have effects.
This is critical because the current batch spawn APIs cannot efficiently
apply BundleEffects in their current form (as doing so in-place could
invalidate the cached raw pointers). We could consider allocating a
buffer of the effects to be applied later, but that does have
performance implications that could offset the balance and value of the
batched APIs (and would likely require some refactors to the underlying
code). I've decided to be conservative here. We can consider relaxing
that requirement on those APIs later, but that should be done in a
followup imo.
* I've ported a few examples to illustrate real-world usage. I think in
a followup we should port all examples to the `children!` form whenever
possible (and for cases that require things like SpawnIter, use the raw
APIs).
* Some may ask "why not use the `Relationship` to spawn (ex:
`ChildOf::spawn(Foo)`) instead of the `RelationshipTarget` (ex:
`Children::spawn(Spawn(Foo))`)?". That _would_ allow us to remove the
`Spawn` wrapper. I've explicitly chosen to disallow this pattern.
`Bundle::Effect` has the ability to create _significant_ weirdness.
Things in `Bundle` position look like components. For example
`world.spawn((Foo, ChildOf::spawn(Bar)))` _looks and reads_ like Foo is
a child of Bar. `ChildOf` is in Foo's "component position" but it is not
a component on Foo. This is a huge problem. Now that `Bundle::Effect`
exists, we should be _very_ principled about keeping the "weird and
unintuitive behavior" to a minimum. Things that read like components
_should be the components they appear to be".
## Remaining Work
* The macros are currently trivially implemented using macro_rules and
are currently limited to the max tuple length. They will require a
proc_macro implementation to work around the tuple length limit.
## Next Steps
* Port the remaining examples to use `children!` where possible and raw
`Spawn` / `SpawnIter` / `SpawnWith` where the flexibility of the raw API
is required.
## Migration Guide
Existing spawn patterns will continue to work as expected.
Manual Bundle implementations now require a `BundleEffect` associated
type. Exisiting bundles would have no bundle effect, so use `()`.
Additionally `Bundle::from_components` has been moved to the new
`BundleFromComponents` trait.
```rust
// Before
unsafe impl Bundle for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
/* remaining bundle impl here */
}
// After
unsafe impl Bundle for X {
type Effect = ();
/* remaining bundle impl here */
}
unsafe impl BundleFromComponents for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
Co-authored-by: Emerson Coskey <emerson@coskey.dev>
Didn't remove WgpuWrapper. Not sure if it's needed or not still.
## Testing
- Did you test these changes? If so, how? Example runner
- Are there any parts that need more testing? Web (portable atomics
thingy?), DXC.
## Migration Guide
- Bevy has upgraded to [wgpu
v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15).
- When using the DirectX 12 rendering backend, the new priority system
for choosing a shader compiler is as follows:
- If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it
is used
- Else if the new `statically-linked-dxc` feature is enabled, a custom
version of DXC will be statically linked into your app at compile time.
- Else Bevy will look in the app's working directory for
`dxcompiler.dll` and `dxil.dll` at runtime.
- Else if they are missing, Bevy will fall back to FXC (not recommended)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
The entity disabling / default query filter work added in #17514 and
#13120 is neat, but we don't teach users how it works!
We should fix that before 0.16.
## Solution
Write a simple example to teach the basics of entity disabling!
## Testing
`cargo run --example entity_disabling`
## Showcase

---------
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
PR #17684 broke occlusion culling because it neglected to set the
indirect parameter offsets for the late mesh preprocessing stage if the
work item buffers were already set. This PR moves the update of those
values to a new function, `init_work_item_buffers`, which is
unconditionally called for every phase every frame.
Note that there's some complexity in order to handle the case in which
occlusion culling was enabled on one frame and disabled on the next, or
vice versa. This was necessary in order to make the occlusion culling
toggle in the `occlusion_culling` example work again.
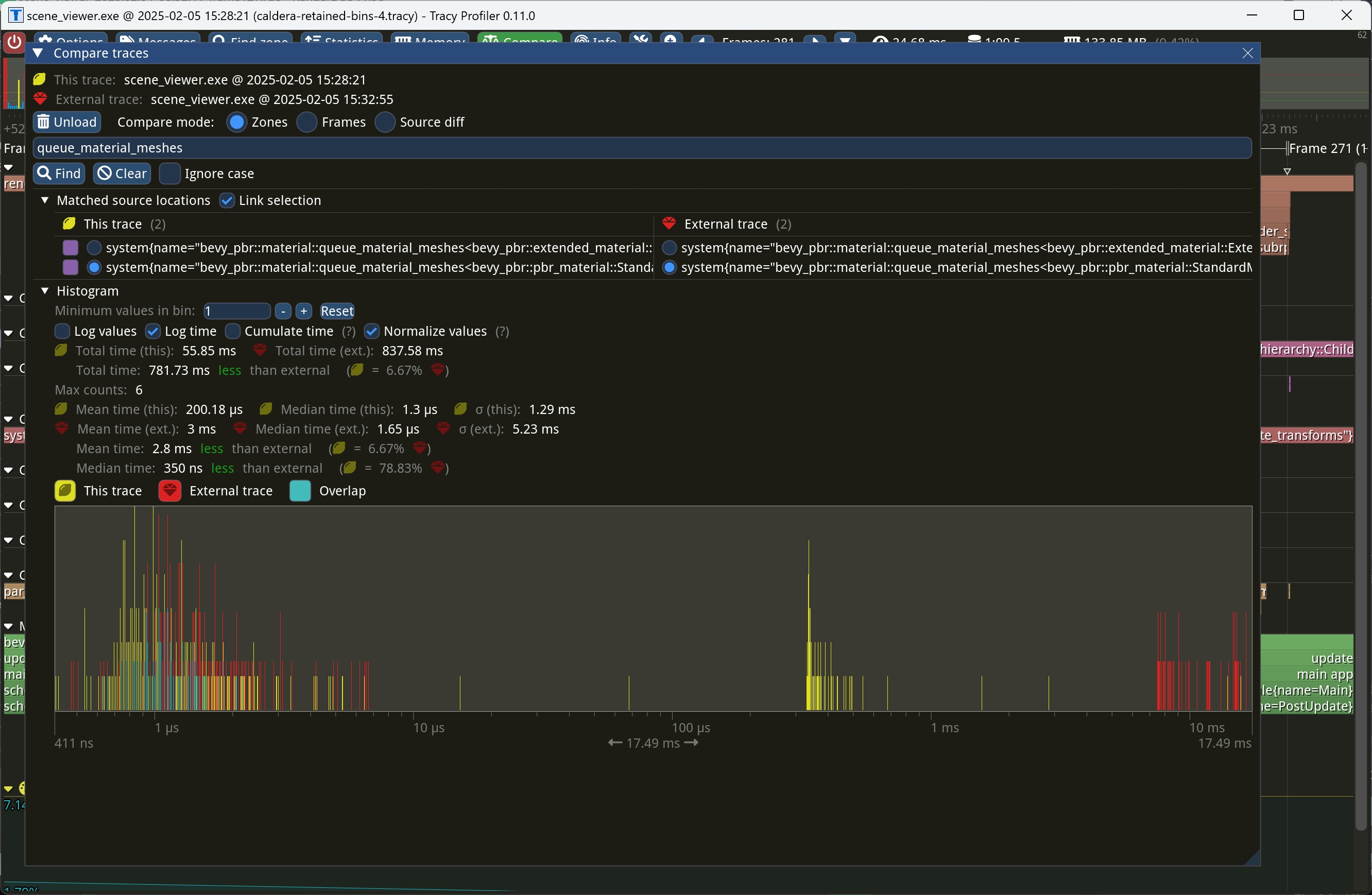
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
# Objective
After #17461, the ease function labels in this example are a bit
cramped, especially in the bottom row.
This adjusts the spacing slightly and centers the labels.
## Solution
- The label is now a child of the plot and they are drawn around the
center of the transform
- Plot size and extents are now constants, and this thing has been
banished:
```rust
i as f32 * 95.0 - 1280.0 / 2.0 + 25.0,
-100.0 - ((j as f32 * 250.0) - 300.0),
0.0,
```
- There's room for expansion in another row, so make that easier by
doing the chunking by row
- Other misc tidying of variable names, sprinkled in a few comments,
etc.
## Before
<img width="1280" alt="Screenshot 2025-02-08 at 7 33 14 AM"
src="https://github.com/user-attachments/assets/0b79c619-d295-4ab1-8cd1-d23c862d06c5"
/>
## After
<img width="1280" alt="Screenshot 2025-02-08 at 7 32 45 AM"
src="https://github.com/user-attachments/assets/656ef695-9aa8-42e9-b867-1718294316bd"
/>