Co-authored-by: Robert Swain <robert.swain@gmail.com> # Objective Implements cascaded shadow maps for directional lights, which produces better quality shadows without needing excessively large shadow maps. Fixes #3629 Before  After 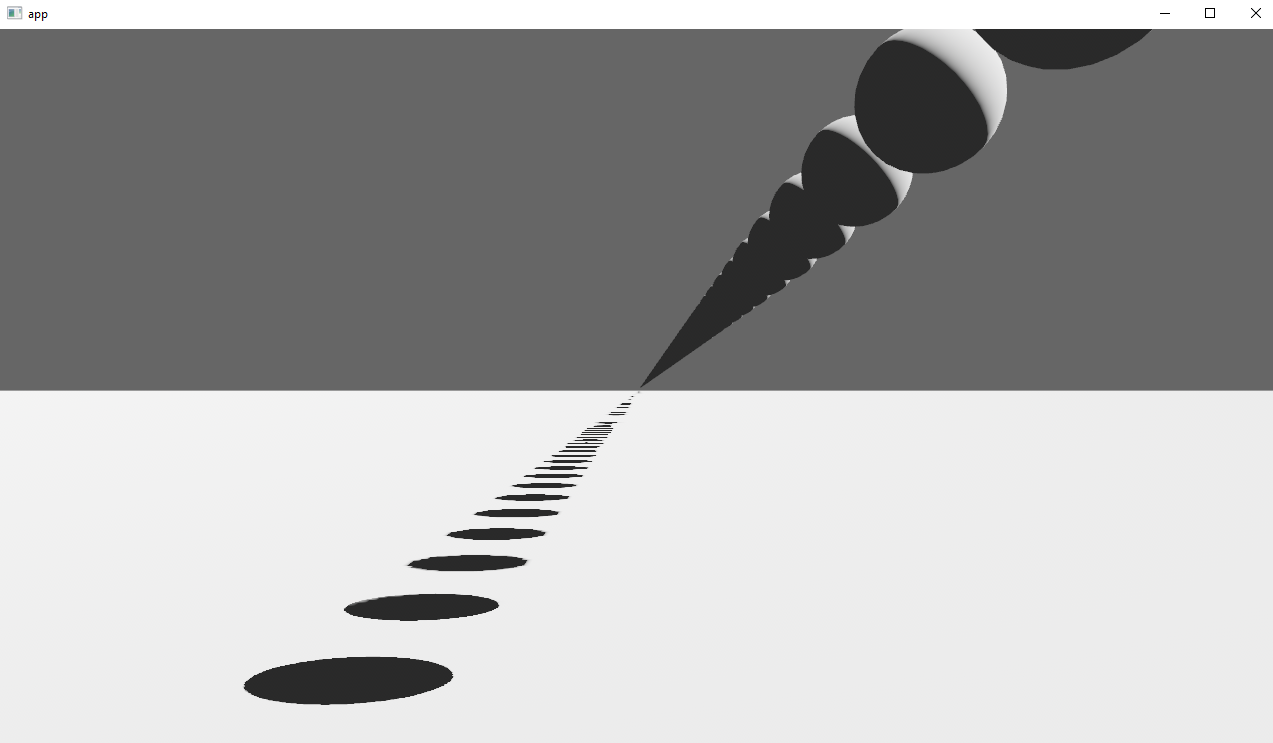 ## Solution Rather than rendering a single shadow map for directional light, the view frustum is divided into a series of cascades, each of which gets its own shadow map. The correct cascade is then sampled for shadow determination. --- ## Changelog Directional lights now use cascaded shadow maps for improved shadow quality. ## Migration Guide You no longer have to manually specify a `shadow_projection` for a directional light, and these settings should be removed. If customization of how cascaded shadow maps work is desired, modify the `CascadeShadowConfig` component instead.
{kind=link}
{kind=link}
335 lines
12 KiB
WebGPU Shading Language
335 lines
12 KiB
WebGPU Shading Language
#define_import_path bevy_pbr::pbr_functions
|
|
|
|
#ifdef TONEMAP_IN_SHADER
|
|
#import bevy_core_pipeline::tonemapping
|
|
#endif
|
|
|
|
|
|
fn alpha_discard(material: StandardMaterial, output_color: vec4<f32>) -> vec4<f32> {
|
|
var color = output_color;
|
|
let alpha_mode = material.flags & STANDARD_MATERIAL_FLAGS_ALPHA_MODE_RESERVED_BITS;
|
|
if alpha_mode == STANDARD_MATERIAL_FLAGS_ALPHA_MODE_OPAQUE {
|
|
// NOTE: If rendering as opaque, alpha should be ignored so set to 1.0
|
|
color.a = 1.0;
|
|
} else if alpha_mode == STANDARD_MATERIAL_FLAGS_ALPHA_MODE_MASK {
|
|
if color.a >= material.alpha_cutoff {
|
|
// NOTE: If rendering as masked alpha and >= the cutoff, render as fully opaque
|
|
color.a = 1.0;
|
|
} else {
|
|
// NOTE: output_color.a < in.material.alpha_cutoff should not is not rendered
|
|
// NOTE: This and any other discards mean that early-z testing cannot be done!
|
|
discard;
|
|
}
|
|
}
|
|
return color;
|
|
}
|
|
|
|
fn prepare_world_normal(
|
|
world_normal: vec3<f32>,
|
|
double_sided: bool,
|
|
is_front: bool,
|
|
) -> vec3<f32> {
|
|
var output: vec3<f32> = world_normal;
|
|
#ifndef VERTEX_TANGENTS
|
|
#ifndef STANDARDMATERIAL_NORMAL_MAP
|
|
// NOTE: When NOT using normal-mapping, if looking at the back face of a double-sided
|
|
// material, the normal needs to be inverted. This is a branchless version of that.
|
|
output = (f32(!double_sided || is_front) * 2.0 - 1.0) * output;
|
|
#endif
|
|
#endif
|
|
return output;
|
|
}
|
|
|
|
fn apply_normal_mapping(
|
|
standard_material_flags: u32,
|
|
world_normal: vec3<f32>,
|
|
#ifdef VERTEX_TANGENTS
|
|
#ifdef STANDARDMATERIAL_NORMAL_MAP
|
|
world_tangent: vec4<f32>,
|
|
#endif
|
|
#endif
|
|
#ifdef VERTEX_UVS
|
|
uv: vec2<f32>,
|
|
#endif
|
|
) -> vec3<f32> {
|
|
// NOTE: The mikktspace method of normal mapping explicitly requires that the world normal NOT
|
|
// be re-normalized in the fragment shader. This is primarily to match the way mikktspace
|
|
// bakes vertex tangents and normal maps so that this is the exact inverse. Blender, Unity,
|
|
// Unreal Engine, Godot, and more all use the mikktspace method. Do not change this code
|
|
// unless you really know what you are doing.
|
|
// http://www.mikktspace.com/
|
|
var N: vec3<f32> = world_normal;
|
|
|
|
#ifdef VERTEX_TANGENTS
|
|
#ifdef STANDARDMATERIAL_NORMAL_MAP
|
|
// NOTE: The mikktspace method of normal mapping explicitly requires that these NOT be
|
|
// normalized nor any Gram-Schmidt applied to ensure the vertex normal is orthogonal to the
|
|
// vertex tangent! Do not change this code unless you really know what you are doing.
|
|
// http://www.mikktspace.com/
|
|
var T: vec3<f32> = world_tangent.xyz;
|
|
var B: vec3<f32> = world_tangent.w * cross(N, T);
|
|
#endif
|
|
#endif
|
|
|
|
#ifdef VERTEX_TANGENTS
|
|
#ifdef VERTEX_UVS
|
|
#ifdef STANDARDMATERIAL_NORMAL_MAP
|
|
// Nt is the tangent-space normal.
|
|
var Nt = textureSample(normal_map_texture, normal_map_sampler, uv).rgb;
|
|
if (standard_material_flags & STANDARD_MATERIAL_FLAGS_TWO_COMPONENT_NORMAL_MAP) != 0u {
|
|
// Only use the xy components and derive z for 2-component normal maps.
|
|
Nt = vec3<f32>(Nt.rg * 2.0 - 1.0, 0.0);
|
|
Nt.z = sqrt(1.0 - Nt.x * Nt.x - Nt.y * Nt.y);
|
|
} else {
|
|
Nt = Nt * 2.0 - 1.0;
|
|
}
|
|
// Normal maps authored for DirectX require flipping the y component
|
|
if (standard_material_flags & STANDARD_MATERIAL_FLAGS_FLIP_NORMAL_MAP_Y) != 0u {
|
|
Nt.y = -Nt.y;
|
|
}
|
|
// NOTE: The mikktspace method of normal mapping applies maps the tangent-space normal from
|
|
// the normal map texture in this way to be an EXACT inverse of how the normal map baker
|
|
// calculates the normal maps so there is no error introduced. Do not change this code
|
|
// unless you really know what you are doing.
|
|
// http://www.mikktspace.com/
|
|
N = Nt.x * T + Nt.y * B + Nt.z * N;
|
|
#endif
|
|
#endif
|
|
#endif
|
|
|
|
return normalize(N);
|
|
}
|
|
|
|
// NOTE: Correctly calculates the view vector depending on whether
|
|
// the projection is orthographic or perspective.
|
|
fn calculate_view(
|
|
world_position: vec4<f32>,
|
|
is_orthographic: bool,
|
|
) -> vec3<f32> {
|
|
var V: vec3<f32>;
|
|
if is_orthographic {
|
|
// Orthographic view vector
|
|
V = normalize(vec3<f32>(view.view_proj[0].z, view.view_proj[1].z, view.view_proj[2].z));
|
|
} else {
|
|
// Only valid for a perpective projection
|
|
V = normalize(view.world_position.xyz - world_position.xyz);
|
|
}
|
|
return V;
|
|
}
|
|
|
|
struct PbrInput {
|
|
material: StandardMaterial,
|
|
occlusion: f32,
|
|
frag_coord: vec4<f32>,
|
|
world_position: vec4<f32>,
|
|
// Normalized world normal used for shadow mapping as normal-mapping is not used for shadow
|
|
// mapping
|
|
world_normal: vec3<f32>,
|
|
// Normalized normal-mapped world normal used for lighting
|
|
N: vec3<f32>,
|
|
// Normalized view vector in world space, pointing from the fragment world position toward the
|
|
// view world position
|
|
V: vec3<f32>,
|
|
is_orthographic: bool,
|
|
};
|
|
|
|
// Creates a PbrInput with default values
|
|
fn pbr_input_new() -> PbrInput {
|
|
var pbr_input: PbrInput;
|
|
|
|
pbr_input.material = standard_material_new();
|
|
pbr_input.occlusion = 1.0;
|
|
|
|
pbr_input.frag_coord = vec4<f32>(0.0, 0.0, 0.0, 1.0);
|
|
pbr_input.world_position = vec4<f32>(0.0, 0.0, 0.0, 1.0);
|
|
pbr_input.world_normal = vec3<f32>(0.0, 0.0, 1.0);
|
|
|
|
pbr_input.is_orthographic = false;
|
|
|
|
pbr_input.N = vec3<f32>(0.0, 0.0, 1.0);
|
|
pbr_input.V = vec3<f32>(1.0, 0.0, 0.0);
|
|
|
|
return pbr_input;
|
|
}
|
|
|
|
#ifndef NORMAL_PREPASS
|
|
fn pbr(
|
|
in: PbrInput,
|
|
) -> vec4<f32> {
|
|
var output_color: vec4<f32> = in.material.base_color;
|
|
|
|
// TODO use .a for exposure compensation in HDR
|
|
let emissive = in.material.emissive;
|
|
|
|
// calculate non-linear roughness from linear perceptualRoughness
|
|
let metallic = in.material.metallic;
|
|
let perceptual_roughness = in.material.perceptual_roughness;
|
|
let roughness = perceptualRoughnessToRoughness(perceptual_roughness);
|
|
|
|
let occlusion = in.occlusion;
|
|
|
|
output_color = alpha_discard(in.material, output_color);
|
|
|
|
// Neubelt and Pettineo 2013, "Crafting a Next-gen Material Pipeline for The Order: 1886"
|
|
let NdotV = max(dot(in.N, in.V), 0.0001);
|
|
|
|
// Remapping [0,1] reflectance to F0
|
|
// See https://google.github.io/filament/Filament.html#materialsystem/parameterization/remapping
|
|
let reflectance = in.material.reflectance;
|
|
let F0 = 0.16 * reflectance * reflectance * (1.0 - metallic) + output_color.rgb * metallic;
|
|
|
|
// Diffuse strength inversely related to metallicity
|
|
let diffuse_color = output_color.rgb * (1.0 - metallic);
|
|
|
|
let R = reflect(-in.V, in.N);
|
|
|
|
// accumulate color
|
|
var light_accum: vec3<f32> = vec3<f32>(0.0);
|
|
|
|
let view_z = dot(vec4<f32>(
|
|
view.inverse_view[0].z,
|
|
view.inverse_view[1].z,
|
|
view.inverse_view[2].z,
|
|
view.inverse_view[3].z
|
|
), in.world_position);
|
|
let cluster_index = fragment_cluster_index(in.frag_coord.xy, view_z, in.is_orthographic);
|
|
let offset_and_counts = unpack_offset_and_counts(cluster_index);
|
|
|
|
// point lights
|
|
for (var i: u32 = offset_and_counts[0]; i < offset_and_counts[0] + offset_and_counts[1]; i = i + 1u) {
|
|
let light_id = get_light_id(i);
|
|
var shadow: f32 = 1.0;
|
|
if ((mesh.flags & MESH_FLAGS_SHADOW_RECEIVER_BIT) != 0u
|
|
&& (point_lights.data[light_id].flags & POINT_LIGHT_FLAGS_SHADOWS_ENABLED_BIT) != 0u) {
|
|
shadow = fetch_point_shadow(light_id, in.world_position, in.world_normal);
|
|
}
|
|
let light_contrib = point_light(in.world_position.xyz, light_id, roughness, NdotV, in.N, in.V, R, F0, diffuse_color);
|
|
light_accum = light_accum + light_contrib * shadow;
|
|
}
|
|
|
|
// spot lights
|
|
for (var i: u32 = offset_and_counts[0] + offset_and_counts[1]; i < offset_and_counts[0] + offset_and_counts[1] + offset_and_counts[2]; i = i + 1u) {
|
|
let light_id = get_light_id(i);
|
|
var shadow: f32 = 1.0;
|
|
if ((mesh.flags & MESH_FLAGS_SHADOW_RECEIVER_BIT) != 0u
|
|
&& (point_lights.data[light_id].flags & POINT_LIGHT_FLAGS_SHADOWS_ENABLED_BIT) != 0u) {
|
|
shadow = fetch_spot_shadow(light_id, in.world_position, in.world_normal);
|
|
}
|
|
let light_contrib = spot_light(in.world_position.xyz, light_id, roughness, NdotV, in.N, in.V, R, F0, diffuse_color);
|
|
light_accum = light_accum + light_contrib * shadow;
|
|
}
|
|
|
|
let n_directional_lights = lights.n_directional_lights;
|
|
for (var i: u32 = 0u; i < n_directional_lights; i = i + 1u) {
|
|
var shadow: f32 = 1.0;
|
|
if ((mesh.flags & MESH_FLAGS_SHADOW_RECEIVER_BIT) != 0u
|
|
&& (lights.directional_lights[i].flags & DIRECTIONAL_LIGHT_FLAGS_SHADOWS_ENABLED_BIT) != 0u) {
|
|
shadow = fetch_directional_shadow(i, in.world_position, in.world_normal, view_z);
|
|
}
|
|
let light_contrib = directional_light(i, roughness, NdotV, in.N, in.V, R, F0, diffuse_color);
|
|
light_accum = light_accum + light_contrib * shadow;
|
|
}
|
|
|
|
let diffuse_ambient = EnvBRDFApprox(diffuse_color, 1.0, NdotV);
|
|
let specular_ambient = EnvBRDFApprox(F0, perceptual_roughness, NdotV);
|
|
|
|
output_color = vec4<f32>(
|
|
light_accum
|
|
+ (diffuse_ambient + specular_ambient) * lights.ambient_color.rgb * occlusion
|
|
+ emissive.rgb * output_color.a,
|
|
output_color.a
|
|
);
|
|
|
|
output_color = cluster_debug_visualization(
|
|
output_color,
|
|
view_z,
|
|
in.is_orthographic,
|
|
offset_and_counts,
|
|
cluster_index,
|
|
);
|
|
|
|
return output_color;
|
|
}
|
|
#endif // NORMAL_PREPASS
|
|
|
|
#ifdef TONEMAP_IN_SHADER
|
|
fn tone_mapping(in: vec4<f32>) -> vec4<f32> {
|
|
// tone_mapping
|
|
return vec4<f32>(reinhard_luminance(in.rgb), in.a);
|
|
|
|
// Gamma correction.
|
|
// Not needed with sRGB buffer
|
|
// output_color.rgb = pow(output_color.rgb, vec3(1.0 / 2.2));
|
|
}
|
|
#endif // TONEMAP_IN_SHADER
|
|
|
|
#ifdef DEBAND_DITHER
|
|
fn dither(color: vec4<f32>, pos: vec2<f32>) -> vec4<f32> {
|
|
return vec4<f32>(color.rgb + screen_space_dither(pos.xy), color.a);
|
|
}
|
|
#endif // DEBAND_DITHER
|
|
|
|
#ifdef PREMULTIPLY_ALPHA
|
|
fn premultiply_alpha(standard_material_flags: u32, color: vec4<f32>) -> vec4<f32> {
|
|
// `Blend`, `Premultiplied` and `Alpha` all share the same `BlendState`. Depending
|
|
// on the alpha mode, we premultiply the color channels by the alpha channel value,
|
|
// (and also optionally replace the alpha value with 0.0) so that the result produces
|
|
// the desired blend mode when sent to the blending operation.
|
|
#ifdef BLEND_PREMULTIPLIED_ALPHA
|
|
// For `BlendState::PREMULTIPLIED_ALPHA_BLENDING` the blend function is:
|
|
//
|
|
// result = 1 * src_color + (1 - src_alpha) * dst_color
|
|
let alpha_mode = standard_material_flags & STANDARD_MATERIAL_FLAGS_ALPHA_MODE_RESERVED_BITS;
|
|
if (alpha_mode == STANDARD_MATERIAL_FLAGS_ALPHA_MODE_BLEND) {
|
|
// Here, we premultiply `src_color` by `src_alpha` (ahead of time, here in the shader)
|
|
//
|
|
// src_color *= src_alpha
|
|
//
|
|
// We end up with:
|
|
//
|
|
// result = 1 * (src_alpha * src_color) + (1 - src_alpha) * dst_color
|
|
// result = src_alpha * src_color + (1 - src_alpha) * dst_color
|
|
//
|
|
// Which is the blend operation for regular alpha blending `BlendState::ALPHA_BLENDING`
|
|
return vec4<f32>(color.rgb * color.a, color.a);
|
|
} else if (alpha_mode == STANDARD_MATERIAL_FLAGS_ALPHA_MODE_ADD) {
|
|
// Here, we premultiply `src_color` by `src_alpha`, and replace `src_alpha` with 0.0:
|
|
//
|
|
// src_color *= src_alpha
|
|
// src_alpha = 0.0
|
|
//
|
|
// We end up with:
|
|
//
|
|
// result = 1 * (src_alpha * src_color) + (1 - 0) * dst_color
|
|
// result = src_alpha * src_color + 1 * dst_color
|
|
//
|
|
// Which is the blend operation for additive blending
|
|
return vec4<f32>(color.rgb * color.a, 0.0);
|
|
} else {
|
|
// Here, we don't do anything, so that we get premultiplied alpha blending. (As expected)
|
|
return color.rgba;
|
|
}
|
|
#endif
|
|
// `Multiply` uses its own `BlendState`, but we still need to premultiply here in the
|
|
// shader so that we get correct results as we tweak the alpha channel
|
|
#ifdef BLEND_MULTIPLY
|
|
// The blend function is:
|
|
//
|
|
// result = dst_color * src_color + (1 - src_alpha) * dst_color
|
|
//
|
|
// We premultiply `src_color` by `src_alpha`:
|
|
//
|
|
// src_color *= src_alpha
|
|
//
|
|
// We end up with:
|
|
//
|
|
// result = dst_color * (src_color * src_alpha) + (1 - src_alpha) * dst_color
|
|
// result = src_alpha * (src_color * dst_color) + (1 - src_alpha) * dst_color
|
|
//
|
|
// Which is the blend operation for multiplicative blending with arbitrary mixing
|
|
// controlled by the source alpha channel
|
|
return vec4<f32>(color.rgb * color.a, color.a);
|
|
#endif
|
|
}
|
|
#endif
|