Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Implements cascaded shadow maps for directional lights, which produces better quality shadows without needing excessively large shadow maps.
Fixes#3629
Before

After
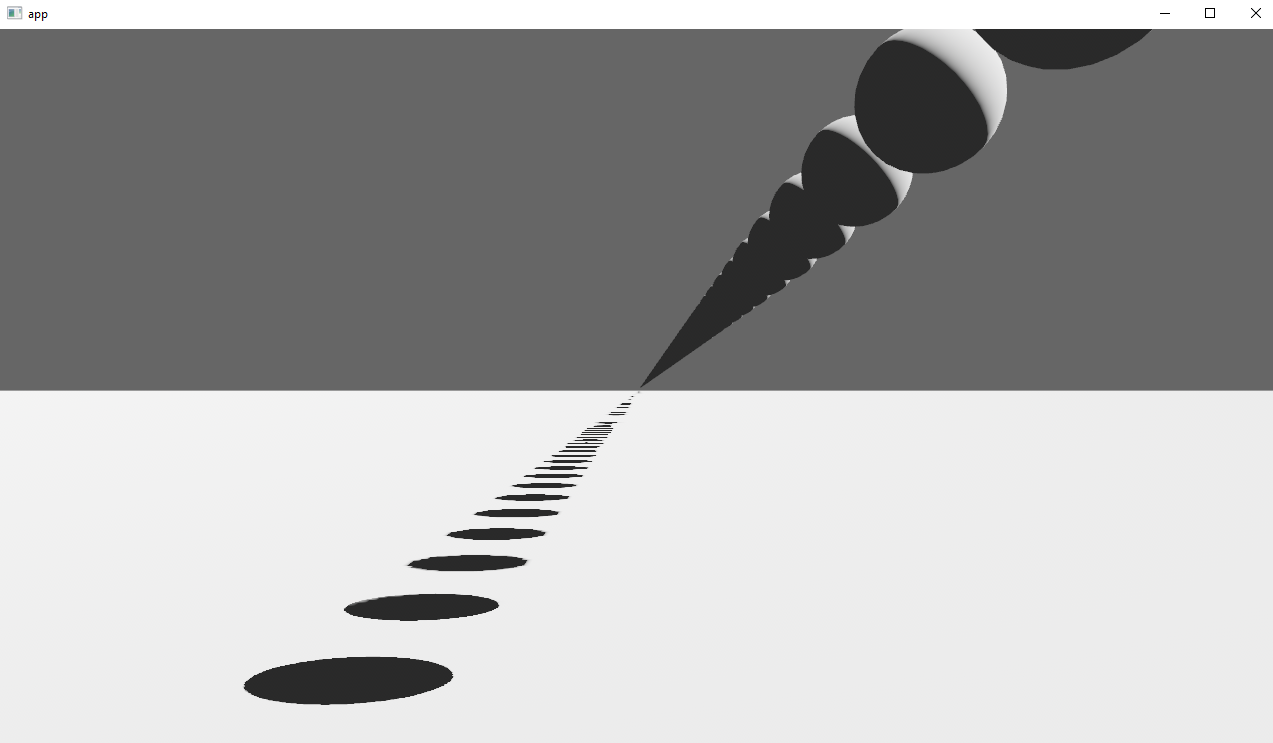
## Solution
Rather than rendering a single shadow map for directional light, the view frustum is divided into a series of cascades, each of which gets its own shadow map. The correct cascade is then sampled for shadow determination.
---
## Changelog
Directional lights now use cascaded shadow maps for improved shadow quality.
## Migration Guide
You no longer have to manually specify a `shadow_projection` for a directional light, and these settings should be removed. If customization of how cascaded shadow maps work is desired, modify the `CascadeShadowConfig` component instead.
# Objective
- This PR adds support for blend modes to the PBR `StandardMaterial`.
<img width="1392" alt="Screenshot 2022-11-18 at 20 00 56" src="https://user-images.githubusercontent.com/418473/202820627-0636219a-a1e5-437a-b08b-b08c6856bf9c.png">
<img width="1392" alt="Screenshot 2022-11-18 at 20 01 01" src="https://user-images.githubusercontent.com/418473/202820615-c8d43301-9a57-49c4-bd21-4ae343c3e9ec.png">
## Solution
- The existing `AlphaMode` enum is extended, adding three more modes: `AlphaMode::Premultiplied`, `AlphaMode::Add` and `AlphaMode::Multiply`;
- All new modes are rendered in the existing `Transparent3d` phase;
- The existing mesh flags for alpha mode are reorganized for a more compact/efficient representation, and new values are added;
- `MeshPipelineKey::TRANSPARENT_MAIN_PASS` is refactored into `MeshPipelineKey::BLEND_BITS`.
- `AlphaMode::Opaque` and `AlphaMode::Mask(f32)` share a single opaque pipeline key: `MeshPipelineKey::BLEND_OPAQUE`;
- `Blend`, `Premultiplied` and `Add` share a single premultiplied alpha pipeline key, `MeshPipelineKey::BLEND_PREMULTIPLIED_ALPHA`. In the shader, color values are premultiplied accordingly (or not) depending on the blend mode to produce the three different results after PBR/tone mapping/dithering;
- `Multiply` uses its own independent pipeline key, `MeshPipelineKey::BLEND_MULTIPLY`;
- Example and documentation are provided.
---
## Changelog
### Added
- Added support for additive and multiplicative blend modes in the PBR `StandardMaterial`, via `AlphaMode::Add` and `AlphaMode::Multiply`;
- Added support for premultiplied alpha in the PBR `StandardMaterial`, via `AlphaMode::Premultiplied`;
# Objective
- Add a configurable prepass
- A depth prepass is useful for various shader effects and to reduce overdraw. It can be expansive depending on the scene so it's important to be able to disable it if you don't need any effects that uses it or don't suffer from excessive overdraw.
- The goal is to eventually use it for things like TAA, Ambient Occlusion, SSR and various other techniques that can benefit from having a prepass.
## Solution
The prepass node is inserted before the main pass. It runs for each `Camera3d` with a prepass component (`DepthPrepass`, `NormalPrepass`). The presence of one of those components is used to determine which textures are generated in the prepass. When any prepass is enabled, the depth buffer generated will be used by the main pass to reduce overdraw.
The prepass runs for each `Material` created with the `MaterialPlugin::prepass_enabled` option set to `true`. You can overload the shader used by the prepass by using `Material::prepass_vertex_shader()` and/or `Material::prepass_fragment_shader()`. It will also use the `Material::specialize()` for more advanced use cases. It is enabled by default on all materials.
The prepass works on opaque materials and materials using an alpha mask. Transparent materials are ignored.
The `StandardMaterial` overloads the prepass fragment shader to support alpha mask and normal maps.
---
## Changelog
- Add a new `PrepassNode` that runs before the main pass
- Add a `PrepassPlugin` to extract/prepare/queue the necessary data
- Add a `DepthPrepass` and `NormalPrepass` component to control which textures will be created by the prepass and available in later passes.
- Add a new `prepass_enabled` flag to the `MaterialPlugin` that will control if a material uses the prepass or not.
- Add a new `prepass_enabled` flag to the `PbrPlugin` to control if the StandardMaterial uses the prepass. Currently defaults to false.
- Add `Material::prepass_vertex_shader()` and `Material::prepass_fragment_shader()` to control the prepass from the `Material`
## Notes
In bevy's sample 3d scene, the performance is actually worse when enabling the prepass, but on more complex scenes the performance is generally better. I would like more testing on this, but @DGriffin91 has reported a very noticeable improvements in some scenes.
The prepass is also used by @JMS55 for TAA and GTAO
discord thread: <https://discord.com/channels/691052431525675048/1011624228627419187>
This PR was built on top of the work of multiple people
Co-Authored-By: @superdump
Co-Authored-By: @robtfm
Co-Authored-By: @JMS55
Co-authored-by: Charles <IceSentry@users.noreply.github.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
# Objective
- The #7064 PR had poor performance on an M1 Max in MacOS due to significant overuse of registers resulting in 'register spilling' where data that would normally be stored in registers on the GPU is instead stored in VRAM. The latency to read from/write to VRAM instead of registers incurs a significant performance penalty.
- Use of registers is a limiting factor in shader performance. Assignment of a struct from memory to a local variable can incur copies. Passing a variable that has struct type as an argument to a function can also incur copies. As such, these two cases can incur increased register usage and decreased performance.
## Solution
- Remove/avoid a number of assignments of light struct type data to local variables.
- Remove/avoid a number of passing light struct type variables/data as value arguments to shader functions.
# Objective
- Closes#5262
- Fix color banding caused by quantization.
## Solution
- Adds dithering to the tonemapping node from #3425.
- This is inspired by Godot's default "debanding" shader: https://gist.github.com/belzecue/
- Unlike Godot:
- debanding happens after tonemapping. My understanding is that this is preferred, because we are running the debanding at the last moment before quantization (`[f32, f32, f32, f32]` -> `f32`). This ensures we aren't biasing the dithering strength by applying it in a different (linear) color space.
- This code instead uses and reference the origin source, Valve at GDC 2015


## Additional Notes
Real time rendering to standard dynamic range outputs is limited to 8 bits of depth per color channel. Internally we keep everything in full 32-bit precision (`vec4<f32>`) inside passes and 16-bit between passes until the image is ready to be displayed, at which point the GPU implicitly converts our `vec4<f32>` into a single 32bit value per pixel, with each channel (rgba) getting 8 of those 32 bits.
### The Problem
8 bits of color depth is simply not enough precision to make each step invisible - we only have 256 values per channel! Human vision can perceive steps in luma to about 14 bits of precision. When drawing a very slight gradient, the transition between steps become visible because with a gradient, neighboring pixels will all jump to the next "step" of precision at the same time.
### The Solution
One solution is to simply output in HDR - more bits of color data means the transition between bands will become smaller. However, not everyone has hardware that supports 10+ bit color depth. Additionally, 10 bit color doesn't even fully solve the issue, banding will result in coherent bands on shallow gradients, but the steps will be harder to perceive.
The solution in this PR adds noise to the signal before it is "quantized" or resampled from 32 to 8 bits. Done naively, it's easy to add unneeded noise to the image. To ensure dithering is correct and absolutely minimal, noise is adding *within* one step of the output color depth. When converting from the 32bit to 8bit signal, the value is rounded to the nearest 8 bit value (0 - 255). Banding occurs around the transition from one value to the next, let's say from 50-51. Dithering will never add more than +/-0.5 bits of noise, so the pixels near this transition might round to 50 instead of 51 but will never round more than one step. This means that the output image won't have excess variance:
- in a gradient from 49 to 51, there will be a step between each band at 49, 50, and 51.
- Done correctly, the modified image of this gradient will never have a adjacent pixels more than one step (0-255) from each other.
- I.e. when scanning across the gradient you should expect to see:
```
|-band-| |-band-| |-band-|
Baseline: 49 49 49 50 50 50 51 51 51
Dithered: 49 50 49 50 50 51 50 51 51
Dithered (wrong): 49 50 51 49 50 51 49 51 50
```


You can see from above how correct dithering "fuzzes" the transition between bands to reduce distinct steps in color, without adding excess noise.
### HDR
The previous section (and this PR) assumes the final output is to an 8-bit texture, however this is not always the case. When Bevy adds HDR support, the dithering code will need to take the per-channel depth into account instead of assuming it to be 0-255. Edit: I talked with Rob about this and it seems like the current solution is okay. We may need to revisit once we have actual HDR final image output.
---
## Changelog
### Added
- All pipelines now support deband dithering. This is enabled by default in 3D, and can be toggled in the `Tonemapping` component in camera bundles. Banding is a graphical artifact created when the rendered image is crunched from high precision (f32 per color channel) down to the final output (u8 per channel in SDR). This results in subtle gradients becoming blocky due to the reduced color precision. Deband dithering applies a small amount of noise to the signal before it is "crunched", which breaks up the hard edges of blocks (bands) of color. Note that this does not add excess noise to the image, as the amount of noise is less than a single step of a color channel - just enough to break up the transition between color blocks in a gradient.
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Make the many foxes not unnecessarily bright. Broken since #5666.
- Fixes#6528
## Solution
- In #5666 normalisation of normals was moved from the fragment stage to the vertex stage. However, it was not added to the vertex stage for skinned normals. The many foxes are skinned and their skinned normals were not unit normals. which made them brighter. Normalising the skinned normals fixes this.
---
## Changelog
- Fixed: Non-unit length skinned normals are now normalized.
# Objective
- Fixes#4019
- Fix lighting of double-sided materials when using a negative scale
- The FlightHelmet.gltf model's hose uses a double-sided material. Loading the model with a uniform scale of -1.0, and comparing against Blender, it was identified that negating the world-space tangent, bitangent, and interpolated normal produces incorrect lighting. Discussion with Morten Mikkelsen clarified that this is both incorrect and unnecessary.
## Solution
- Remove the code that negates the T, B, and N vectors (the interpolated world-space tangent, calculated world-space bitangent, and interpolated world-space normal) when seeing the back face of a double-sided material with negative scale.
- Negate the world normal for a double-sided back face only when not using normal mapping
### Before, on `main`, flipping T, B, and N
<img width="932" alt="Screenshot 2022-08-22 at 15 11 53" src="https://user-images.githubusercontent.com/302146/185965366-f776ff2c-cfa1-46d1-9c84-fdcb399c273c.png">
### After, on this PR
<img width="932" alt="Screenshot 2022-08-22 at 15 12 11" src="https://user-images.githubusercontent.com/302146/185965420-8be493e2-3b1a-4188-bd13-fd6b17a76fe7.png">
### Double-sided material without normal maps
https://user-images.githubusercontent.com/302146/185988113-44a384e7-0b55-4946-9b99-20f8c803ab7e.mp4
---
## Changelog
- Fixed: Lighting of normal-mapped, double-sided materials applied to models with negative scale
- Fixed: Lighting and shadowing of back faces with no normal-mapping and a double-sided material
## Migration Guide
`prepare_normal` from the `bevy_pbr::pbr_functions` shader import has been reworked.
Before:
```rust
pbr_input.world_normal = in.world_normal;
pbr_input.N = prepare_normal(
pbr_input.material.flags,
in.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
in.is_front,
);
```
After:
```rust
pbr_input.world_normal = prepare_world_normal(
in.world_normal,
(material.flags & STANDARD_MATERIAL_FLAGS_DOUBLE_SIDED_BIT) != 0u,
in.is_front,
);
pbr_input.N = apply_normal_mapping(
pbr_input.material.flags,
pbr_input.world_normal,
#ifdef VERTEX_TANGENTS
#ifdef STANDARDMATERIAL_NORMAL_MAP
in.world_tangent,
#endif
#endif
in.uv,
);
```
Attempt to make features like bloom https://github.com/bevyengine/bevy/pull/2876 easier to implement.
**This PR:**
- Moves the tonemapping from `pbr.wgsl` into a separate pass
- also add a separate upscaling pass after the tonemapping which writes to the swap chain (enables resolution-independant rendering and post-processing after tonemapping)
- adds a `hdr` bool to the camera which controls whether the pbr and sprite shaders render into a `Rgba16Float` texture
**Open questions:**
- ~should the 2d graph work the same as the 3d one?~ it is the same now
- ~The current solution is a bit inflexible because while you can add a post processing pass that writes to e.g. the `hdr_texture`, you can't write to a separate `user_postprocess_texture` while reading the `hdr_texture` and tell the tone mapping pass to read from the `user_postprocess_texture` instead. If the tonemapping and upscaling render graph nodes were to take in a `TextureView` instead of the view entity this would almost work, but the bind groups for their respective input textures are already created in the `Queue` render stage in the hardcoded order.~ solved by creating bind groups in render node
**New render graph:**

<details>
<summary>Before</summary>

</details>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Alpha mask was previously ignored when using an unlit material.
- Fixes https://github.com/bevyengine/bevy/issues/4479
## Solution
- Extract the alpha discard to a separate function and use it when unlit is true
## Notes
I tried calling `alpha_discard()` before the `if` in pbr.wgsl, but I had errors related to having a `discard` at the beginning before doing the texture sampling. I'm not sure if there's a way to fix that instead of having the function being called in 2 places.
# Objective
- Morten Mikkelsen clarified that the world normal and tangent must be normalized in the vertex stage and the interpolated values must not be normalized in the fragment stage. This is in order to match the mikktspace approach exactly.
- Fixes#5514 by ensuring the tangent basis matrix (TBN) is orthonormal
## Solution
- Normalize the world normal in the vertex stage and not the fragment stage
- Normalize the world tangent xyz in the vertex stage
- Take into account the sign of the determinant of the local to world matrix when calculating the bitangent
---
## Changelog
- Fixed - scaling a model that uses normal mapping now has correct lighting again
# Objective
Bevy requires meshes to include UV coordinates, even if the material does not use any textures, and will fail with an error `ERROR bevy_pbr::material: Mesh is missing requested attribute: Vertex_Uv (MeshVertexAttributeId(2), pipeline type: Some("bevy_pbr::material::MaterialPipeline<bevy_pbr::pbr_material::StandardMaterial>"))` otherwise. The objective of this PR is to permit this.
## Solution
This PR follows the design of #4528, which added support for per-vertex colours. It adds a shader define called VERTEX_UVS which indicates the presence of UV coordinates to the shader.
# Objective
add spotlight support
## Solution / Changelog
- add spotlight angles (inner, outer) to ``PointLight`` struct. emitted light is linearly attenuated from 100% to 0% as angle tends from inner to outer. Direction is taken from the existing transform rotation.
- add spotlight direction (vec3) and angles (f32,f32) to ``GpuPointLight`` struct (60 bytes -> 80 bytes) in ``pbr/render/lights.rs`` and ``mesh_view_bind_group.wgsl``
- reduce no-buffer-support max point light count to 204 due to above
- use spotlight data to attenuate light in ``pbr.wgsl``
- do additional cluster culling on spotlights to minimise cost in ``assign_lights_to_clusters``
- changed one of the lights in the lighting demo to a spotlight
- also added a ``spotlight`` demo - probably not justified but so reviewers can see it more easily
## notes
increasing the size of the GpuPointLight struct on my machine reduces the FPS of ``many_lights -- sphere`` from ~150fps to 140fps.
i thought this was a reasonable tradeoff, and felt better than handling spotlights separately which is possible but would mean introducing a new bind group, refactoring light-assignment code and adding new spotlight-specific code in pbr.wgsl. the FPS impact for smaller numbers of lights should be very small.
the cluster culling strategy reintroduces the cluster aabb code which was recently removed... sorry. the aabb is used to get a cluster bounding sphere, which can then be tested fairly efficiently using the strategy described at the end of https://bartwronski.com/2017/04/13/cull-that-cone/. this works well with roughly cubic clusters (where the cluster z size is close to the same as x/y size), less well for other cases like single Z slice / tiled forward rendering. In the worst case we will end up just keeping the culling of the equivalent point light.
Co-authored-by: François <mockersf@gmail.com>
# Objective
This fixes https://github.com/bevyengine/bevy/issues/5127
## Solution
- Moved texture sample out of branch in `prepare_normal()`.
Co-authored-by: DGriffin91 <github@dgdigital.net>
# Objective
- Make the reusable PBR shading functionality a little more reusable
- Add constructor functions for `StandardMaterial` and `PbrInput` structs to populate them with default values
- Document unclear `PbrInput` members
- Demonstrate how to reuse the bevy PBR shading functionality
- The final important piece from #3969 as the initial shot at making the PBR shader code reusable in custom materials
## Solution
- Add back and rework the 'old' `array_texture` example from pre-0.6.
- Create a custom shader material
- Use a single array texture binding and sampler for the material bind group
- Use a shader that calls `pbr()` from the `bevy_pbr::pbr_functions` import
- Spawn a row of cubes using the custom material
- In the shader, select the array texture layer to sample by using the world position x coordinate modulo the number of array texture layers
<img width="1392" alt="Screenshot 2022-06-23 at 12 28 05" src="https://user-images.githubusercontent.com/302146/175278593-2296f519-f577-4ece-81c0-d842283784a1.png">
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Allow custom shaders to reuse the HDR results of PBR.
## Solution
- Separate `pbr()` and `tone_mapping()` into 2 functions in `pbr_functions.wgsl`.
# Objective
- Builds on top of #4938
- Make clustered-forward PBR lighting/shadows functionality callable
- See #3969 for details
## Solution
- Add `PbrInput` struct type containing a `StandardMaterial`, occlusion, world_position, world_normal, and frag_coord
- Split functionality to calculate the unit view vector, and normal-mapped normal into `bevy_pbr::pbr_functions`
- Split high-level shading flow into `pbr(in: PbrInput, N: vec3<f32>, V: vec3<f32>, is_orthographic: bool)` function in `bevy_pbr::pbr_functions`
- Rework `pbr.wgsl` fragment stage entry point to make use of the new functions
- This has been benchmarked on an M1 Max using `many_cubes -- sphere`. `main` had a median frame time of 15.88ms, this PR 15.99ms, which is a 0.69% frame time increase, which is within noise in my opinion.
---
## Changelog
- Added: PBR shading code is now callable. Import `bevy_pbr::pbr_functions` and its dependencies, create a `PbrInput`, calculate the unit view and normal-mapped normal vectors and whether the projection is orthographic, and call `pbr()`!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}