# Objective
- In #17743, attention was raised to the fact that we supported an
unusual kind of step easing function. The author of the fix kindly
provided some links to standards used in CSS. It would be desirable to
support generally agreed upon standards so this PR here tries to
implement an extra configuration option of the step easing function
- Resolve#17744
## Solution
- Introduce `StepConfig`
- `StepConfig` can configure both the number of steps and the jumping
behavior of the function
- `StepConfig` replaces the raw `usize` parameter of the
`EasingFunction::Steps(usize)` construct.
- `StepConfig`s default jumping behavior is `end`, so in that way it
follows #17743
## Testing
- I added a new test per `JumpAt` jumping behavior. These tests
replicate the visuals that can be found at
https://developer.mozilla.org/en-US/docs/Web/CSS/easing-function/steps#description
## Migration Guide
- `EasingFunction::Steps` now uses a `StepConfig` instead of a raw
`usize`. You can replicate the previous behavior by replaceing
`EasingFunction::Steps(10)` with
`EasingFunction::Steps(StepConfig::new(10))`.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
There's no need for the `span_index` and `color` variables in
`extract_text_shadows` and `extract_text_sections` and we can remove one
of the span index comparisons since text colors are only set per
section.
## Testing
<img width="454" alt="trace"
src="https://github.com/user-attachments/assets/3109d1df-0817-46c2-9889-0459ac93a42c"
/>
This commit builds on top of the work done in #16589 and #17051, by
adding support for fallible observer systems.
As with the previous work, the actual results of the observer system are
suppressed for now, but the intention is to provide a way to handle
errors in a global way.
Until then, you can use a `PipeSystem` to manually handle results.
---------
Signed-off-by: Jean Mertz <git@jeanmertz.com>
# Objective
Bevy's ECS provides several core traits such as `Component`,
`SystemParam`, etc that determine where a type can be used. When reading
the docs, this currently requires scrolling down to and scanning the
"Trait Implementations" section. Make these core traits more visible.
## Solution
Add a color-coded labels below the type heading denoting the following
types:
- `Component`
- immutable components are labeled as such
- `Resource`
- `Asset`
- `Event`
- `Plugin` & `PluginGroup`
- `ScheduleLabel` & `SystemSet`
- `SystemParam`
As docs.rs does not provide an option for post-processing the html,
these are added via JS with traits implementations being detected by
scanning the DOM. Rustdoc's html output is unstable, which could
potentially lead to this detection (or the adding of the labels) to
break, however it only needs to work when a new release is deployed and
falls back to the status quo of not displaying these labels.
Idea by JMS55, implementation by Jondolf (see
https://github.com/Jondolf/bevy_docs_extension_demo/).
## Testing
Run this in Bevy's root folder:
```bash
RUSTDOCFLAGS="--html-after-content docs-rs/trait-tags.html --cfg docsrs_dep" RUSTFLAGS="--cfg docsrs_dep" cargo doc --no-deps -p <some_bevy_package>
```
---
## Showcase
Check it out on
[docs.rs](https://docs.rs/bevy_docs_extension_demo/0.1.1/bevy_docs_extension_demo/struct.TestAllTraits.html)

## Release Notes
On docs.rs, Bevy now displays labels indicating which core traits a type
implements:

If you want to add these to your own crate, check out [these
instructions](https://github.com/bevyengine/bevy/blob/main/docs-rs#3rd-party-crates).
---------
Co-authored-by: Joona Aalto <jondolf.dev@gmail.com>
Co-authored-by: Carter Weinberg <weinbergcarter@gmail.com>
## What problem does this solve or what need does it fill?
There are some situations
(https://github.com/bevyengine/bevy/issues/13735) where the ticks that
are present inside `Ref` are incorrect, for example if `Ref` is created
outside of a `SystemParam`.
I still want to use `Ref` because it has convenient `is_added` and
`is_changed` methods.
My current solution is to build my own `Ref` by copy-pasting most the
bevy code to do that via something like
```rust
/// This method is necessary because there is no easy way to
pub(crate) fn get_ref<C: Component>(
world: &World,
entity: Entity,
last_run: Tick,
this_run: Tick,
) -> Ref<C> {
unsafe {
let component_id = world
.components()
.get_id(TypeId::of::<C>())
.unwrap_unchecked();
let world = world.as_unsafe_world_cell_readonly();
let entity_cell = world.get_entity(entity).unwrap_unchecked();
get_component_and_ticks(
world,
component_id,
C::STORAGE_TYPE,
entity,
entity_cell.location(),
)
.map(|(value, cells, _caller)| {
Ref::new(
value.deref::<C>(),
cells.added.deref(),
cells.changed.deref(),
last_run,
this_run,
#[cfg(feature = "track_location")]
_caller.deref(),
)
})
.unwrap_unchecked()
}
}
// Utility function to return
#[inline]
unsafe fn get_component_and_ticks(
world: UnsafeWorldCell<'_>,
component_id: ComponentId,
storage_type: StorageType,
entity: Entity,
location: EntityLocation,
) -> Option<(Ptr<'_>, TickCells<'_>, MaybeUnsafeCellLocation<'_>)> {
match storage_type {
StorageType::Table => {
let table = unsafe { world.storages().tables.get(location.table_id) }?;
// SAFETY: archetypes only store valid table_rows and caller ensure aliasing rules
Some((
table.get_component(component_id, location.table_row)?,
TickCells {
added: table
.get_added_tick(component_id, location.table_row)
.unwrap_unchecked(),
changed: table
.get_changed_tick(component_id, location.table_row)
.unwrap_unchecked(),
},
#[cfg(feature = "track_location")]
table
.get_changed_by(component_id, location.table_row)
.unwrap_unchecked(),
#[cfg(not(feature = "track_location"))]
(),
))
}
StorageType::SparseSet => {
let storage = unsafe { world.storages() }.sparse_sets.get(component_id)?;
storage.get_with_ticks(entity)
}
}
}
```
It would be very convenient if instead bevy exposed a way to create a
`Ref` object with custom `last_run` and `this_run` ticks.
This PR does this by exposing a function to overwrite the `last_run` and
`this_run` ticks.
(Same with `Mut`)
I am ok with marking the method unsafe or risky if it's deemed to risky
for end-users.
# Objective
Add position reporting to `HitData` sent from the UI picking backend.
## Solution
Add the computed normalized relative cursor position to `hit_data`
alongside the `Entity`.
The position reported in `HitData` is normalized relative to the node,
with `(0.,0.,0.)` at the top left and `(1., 1., 0.)` in the bottom
right. Coordinates are relative to the entire node, not just the visible
region.
`HitData` needs a `Vec3` so I just extended with 0.0. I considered
inserting the `depth` here but thought it would be redundant.
I also considered putting the screen space position in the `normal`
field of `HitData`, but that would require renaming of the field or a
separate data structure.
## Testing
Tested with mouse on X11 with entities that have `Node` components.
---
## Showcase
```rs
// Get click position relative to node
fn hit_position(trigger: Trigger<Pointer<Click>>) {
let hit_pos = trigger.event.hit.position.expect("no position");
info!("{}", hit_pos);
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
You can now configure error handlers for fallible systems. These can be
configured on several levels:
- Globally via `App::set_systems_error_handler`
- Per-schedule via `Schedule::set_error_handler`
- Per-system via a piped system (this is existing functionality)
The default handler of panicking on error keeps the same behavior as
before this commit.
The "fallible_systems" example demonstrates the new functionality.
This builds on top of #17731, #16589, #17051.
---------
Signed-off-by: Jean Mertz <git@jeanmertz.com>
# Objective
Add some multi-span text to the `many_buttons` benchmark by splitting up
each button label text into two different coloured text spans.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
This is a follow up fix for #17330 and fixes#17780.
There was a logic error in the ambiguity detection of
`cargo-manifest-proc-macros`.
`cargo-manifest-proc-macros` now has a test for this case to prevent the
issue in the future.
I also opted to hard fail if the `cargo-manifest-proc-macros` crate
fails. That way the error is more obvious and easier to fix and
diagnose.
## Testing
- The reproducer:
https://github.com/bevyengine/bevy_editor_prototypes/pull/178 works for
me using these fixes.
# Objective
Currently, default query filters, as added in #13120 / #17514 are
hardcoded to only use a single query filter.
This is limiting, as multiple distinct disabling components can serve
important distinct roles. I ran into this limitation when experimenting
with a workflow for prefabs, which don't represent the same state as "an
entity which is temporarily nonfunctional".
## Solution
1. Change `DefaultQueryFilters` to store a SmallVec of ComponentId,
rather than an Option.
2. Expose methods on `DefaultQueryFilters`, `World` and `App` to
actually configure this.
3. While we're here, improve the docs, write some tests, make use of
FromWorld and make some method names more descriptive.
## Follow-up
I'm not convinced that supporting sparse set disabling components is
useful, given the hit to iteration performance and runtime checks
incurred. That's disjoint from this PR though, so I'm not doing it here.
The existing warnings are fine for now.
## Testing
I've added both a doc test and an mid-level unit test to verify that
this works!
# Objective
Allow quick jump to definition of types of GlTFs labeled assets.
## Solution
Add links to the types refered on the docs of `GltfAssetLabel`
## Testing
Ran `cargo run -p ci`
# Objective
Since previously we only had the alpha channel available, we stored the
mean of the transmittance in the aerial view lut, resulting in a grayer
fog than should be expected.
## Solution
- Calculate transmittance to scene in `render_sky` with two samples from
the transmittance lut
- use dual-source blending to effectively have per-component alpha
blending
Currently, we *sweep*, or remove entities from bins when those entities
became invisible or changed phases, during `queue_material_meshes` and
similar phases. This, however, is wrong, because `queue_material_meshes`
executes once per material type, not once per phase. This could result
in sweeping bins multiple times per phase, which can corrupt the bins.
This commit fixes the issue by moving sweeping to a separate system that
runs after queuing.
This manifested itself as entities appearing and disappearing seemingly
at random.
Closes#17759.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Because of mesh preprocessing, users cannot rely on
`@builtin(instance_index)` in order to reference external data, as the
instance index is not stable, either from frame to frame or relative to
the total spawn order of mesh instances.
## Solution
Add a user supplied mesh index that can be used for referencing external
data when drawing instanced meshes.
Closes#13373
## Testing
Benchmarked `many_cubes` showing no difference in total frame time.
## Showcase
https://github.com/user-attachments/assets/80620147-aafc-4d9d-a8ee-e2149f7c8f3b
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
- Expand the documentation for `EasingCurve`.
- I suspect this might have avoided the confusion in
https://github.com/bevyengine/bevy/pull/17711.
- Also add a shortcut for simple cases.
## Solution
- Added various examples and extra context.
- Implemented `Curve<T>` for `EaseFunction`.
- This means `EasingCurve::new(0.0, 1.0, EaseFunction::X)` can be
shortened to `EaseFunction::X`.
- In some cases this will be a minor performance improvement.
- Added test to confirm they're the same.
- ~~Added some benchmarks for bonus points.~~
## Side Notes
- I would have liked to rename `EaseFunction` to `EaseFn` for brevity,
but that would be a breaking change and maybe controversial.
- Also suspect `EasingCurve` should be `EaseCurve`, but say la vee.
- Benchmarks show that calling `EaseFunction::Smoothstep` is still
slower than calling `smoothstep` directly.
- I think this is because the compiler refuses to inline
`EaseFunction::eval`.
- I don't see any good solution - might need a whole different
interface.
## Testing
```sh
cargo test --package bevy_math
cargo doc --package bevy_math
./target/doc/bevy_math/curve/easing/struct.EasingCurve.html
cargo bench --package benches --bench math -- easing
```
# Objective
https://github.com/bevyengine/bevy/issues/17746
## Solution
- Change `Image.data` from being a `Vec<u8>` to a `Option<Vec<u8>>`
- Added functions to help with creating images
## Testing
- Did you test these changes? If so, how?
All current tests pass
Tested a variety of existing examples to make sure they don't crash
(they don't)
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
Linux x86 64-bit NixOS
---
## Migration Guide
Code that directly access `Image` data will now need to use unwrap or
handle the case where no data is provided.
Behaviour of new_fill slightly changed, but not in a way that is likely
to affect anything. It no longer panics and will fill the whole texture
instead of leaving black pixels if the data provided is not a nice
factor of the size of the image.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
Currently
[CosmicBuffer](https://docs.rs/bevy/latest/bevy/text/struct.CosmicBuffer.html)
is a public type with a public field that is not used or accessible in
any public API. Since it is prominently shown in the docs it is the
obvious place to start when trying to access `cosmic_string` features
such as for mapping between screen coordinates and positions in the
displayed text.
The only place `CosmicBuffer` is currently used is as a field of
`ComputedTextBlock`, where a comment explains why the field is private:
/// Buffer for managing text layout and creating [`TextLayoutInfo`].
///
/// This is private because buffer contents are always refreshed from
ECS state when writing glyphs to
/// `TextLayoutInfo`. If you want to control the buffer contents
manually or use the `cosmic-text`
/// editor, then you need to not use `TextLayout` and instead manually
implement the conversion to
/// `TextLayoutInfo`.
#[reflect(ignore)]
pub(crate) buffer: CosmicBuffer,
Unfortunately this comment does not appear in the docs, so a user
looking for a way to access `CosmicBuffer` will not find it unless they
check the source code.
Also there does not seem to be any alternative way to map between screen
coordinates and positions in the displayed text, which would be highly
useful for things like text edit widgets or tool tips. The reasons given
for making the field private only apply for mutable access, so
non-mutable access would presumably be fine.
## Solution
I added a getter to `ComputedTextBlock`, and added the explanation for
why there is no mutable access in the comment:
/// Accesses the underling buffer which can be used for `cosmic-text`
APIs such as accessing layout information
/// or calculating a cursor position.
///
/// Mutable access not offered because changes would be overwritten
during the automated layout calculation.
/// If you want to control the buffer contents manually or use the
`cosmic-text`
/// editor, then you need to not use `TextLayout` and instead manually
implement the conversion to
/// `TextLayoutInfo`.
pub fn get_buffer(&self) -> &CosmicBuffer {
&self.buffer
}
## Testing
I tested that the getter could be used to map from screen coordinates to
string positions by creating a rudimentary text edit widget and trying
it out.
## Alternatives
An alternative to making `CosmicBuffer` accessible would be to make the
type private so that no one wastes time looking for a way of accessing
it, and adding additional methods to `ComputedTextBlock` that make use
of the buffer as implementation detail and offer access to currently
inaccessible functionality.
---------
Co-authored-by: Rob Parrett <robparrett@gmail.com>
# Objective
- bevy_math fails to publish because of the self dev-dependency
- it's used to enable the `approx` feature in tests
## Solution
- Don't specify a version in the dev-dependency. dependencies without a
version are ignored by cargo when publishing
- Gate all the tests that depend on the `approx` feature so that it
doesn't fail to compile when not enabled
- Also gate an import that wasn't used without `bevy_reflect`
## Testing
- with at least cargo 1.84: `cargo package -p bevy_math`
- `cd target/package/bevy_math_* && cargo test`
# Objective
Restore the behavior of `Query::get_many` prior to #15858.
When passed duplicate `Entity`s, `get_many` is supposed to return
results for all of them, since read-only queries don't alias. However,
#15858 merged the implementation with `get_many_mut` and caused it to
return `QueryEntityError::AliasedMutability`.
## Solution
Introduce a new `Query::get_many_readonly` method that consumes the
`Query` like `get_many_inner`, but that is constrained to `D:
ReadOnlyQueryData` so that it can skip the aliasing check. Implement
`Query::get_many` in terms of that new method. Add a test, and a comment
explaining why it doesn't match the pattern of the other `&self`
methods.
This method returns `None` if `meta.location.archetype_id` is
`ArchetypeId::INVALID`.
`EntityLocation::INVALID.archetype_id` is `ArchetypeId::INVALID`.
Therefore this method cannot return `Some(EntityLocation::INVALID)`.
Linking to it in the docs is futile anyway as that constant is not
public.
# Objective
`bevy_picking` currently does not support scroll events.
## Solution
This pr adds a new event type for scroll, and updates the default input
system for mouse pointers to read and emit this event.
## Testing
- Did you test these changes? If so, how?
- Are there any parts that need more testing?
- How can other people (reviewers) test your changes? Is there anything
specific they need to know?
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
I haven't tested these changes, if the reviewers can advise me how to do
so I'd appreciate it!
# Objective
- Allow users to configure volume using decibels by changing the
`Volume` type from newtyping an `f32` to an enum with `Linear` and
`Decibels` variants.
- Fixes#9507.
- Alternative reworked version of closed#9582.
## Solution
Compared to https://github.com/bevyengine/bevy/pull/9582, this PR has
the following main differences:
1. It uses the term "linear scale" instead of "amplitude" per
https://github.com/bevyengine/bevy/pull/9582/files#r1513529491.
2. Supports `ops` for doing `Volume` arithmetic. Can add two volumes,
e.g. to increase/decrease the current volume. Can multiply two volumes,
e.g. to get the “effective” volume of an audio source considering global
volume.
[requested and blessed on Discord]:
https://discord.com/channels/691052431525675048/749430447326625812/1318272597003341867
## Testing
- Ran `cargo run --example soundtrack`.
- Ran `cargo run --example audio_control`.
- Ran `cargo run --example spatial_audio_2d`.
- Ran `cargo run --example spatial_audio_3d`.
- Ran `cargo run --example pitch`.
- Ran `cargo run --example decodable`.
- Ran `cargo run --example audio`.
---
## Migration Guide
Audio volume can now be configured using decibel values, as well as
using linear scale values. To enable this, some types and functions in
`bevy_audio` have changed.
- `Volume` is now an enum with `Linear` and `Decibels` variants.
Before:
```rust
let v = Volume(1.0);
```
After:
```rust
let volume = Volume::Linear(1.0);
let volume = Volume::Decibels(0.0); // or now you can deal with decibels if you prefer
```
- `Volume::ZERO` has been renamed to the more semantically correct
`Volume::SILENT` because `Volume` now supports decibels and "zero
volume" in decibels actually means "normal volume".
- The `AudioSinkPlayback` trait's volume-related methods now deal with
`Volume` types rather than `f32`s. `AudioSinkPlayback::volume()` now
returns a `Volume` rather than an `f32`. `AudioSinkPlayback::set_volume`
now receives a `Volume` rather than an `f32`. This affects the
`AudioSink` and `SpatialAudioSink` implementations of the trait. The
previous `f32` values are equivalent to the volume converted to linear
scale so the `Volume:: Linear` variant should be used to migrate between
`f32`s and `Volume`.
- The `GlobalVolume::new` function now receives a `Volume` instead of an
`f32`.
---------
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
# Objective
Eliminate the need to write `cfg(feature = "track_location")` every time
one uses an API that may use location tracking. It's verbose, and a
little intimidating. And it requires code outside of `bevy_ecs` that
wants to use location tracking needs to either unconditionally enable
the feature, or include conditional compilation of its own. It would be
good for users to be able to log locations when they are available
without needing to add feature flags to their own crates.
Reduce the number of cases where code compiles with the `track_location`
feature enabled, but not with it disabled, or vice versa. It can be hard
to remember to test it both ways!
Remove the need to store a `None` in `HookContext` when the
`track_location` feature is disabled.
## Solution
Create an `MaybeLocation<T>` type that contains a `T` if the
`track_location` feature is enabled, and is a ZST if it is not. The
overall API is similar to `Option`, but whether the value is `Some` or
`None` is set at compile time and is the same for all values.
Default `T` to `&'static Location<'static>`, since that is the most
common case.
Remove all `cfg(feature = "track_location")` blocks outside of the
implementation of that type, and instead call methods on it.
When `track_location` is disabled, `MaybeLocation` is a ZST and all
methods are `#[inline]` and empty, so they should be entirely removed by
the compiler. But the code will still be visible to the compiler and
checked, so if it compiles with the feature disabled then it should also
compile with it enabled, and vice versa.
## Open Questions
Where should these types live? I put them in `change_detection` because
that's where the existing `MaybeLocation` types were, but we now use
these outside of change detection.
While I believe that the compiler should be able to remove all of these
calls, I have not actually tested anything. If we want to take this
approach, what testing is required to ensure it doesn't impact
performance?
## Migration Guide
Methods like `Ref::changed_by()` that return a `&'static
Location<'static>` will now be available even when the `track_location`
feature is disabled, but they will return a new `MaybeLocation` type.
`MaybeLocation` wraps a `&'static Location<'static>` when the feature is
enabled, and is a ZST when the feature is disabled.
Existing code that needs a `&Location` can call `into_option().unwrap()`
to recover it. Many trait impls are forwarded, so if you only need
`Display` then no changes will be necessary.
If that code was conditionally compiled, you may instead want to use the
methods on `MaybeLocation` to remove the need for conditional
compilation.
Code that constructs a `Ref`, `Mut`, `Res`, or `ResMut` will now need to
provide location information unconditionally. If you are creating them
from existing Bevy types, you can obtain a `MaybeLocation` from methods
like `Table::get_changed_by_slice_for()` or
`ComponentSparseSet::get_with_ticks`. Otherwise, you will need to store
a `MaybeLocation` next to your data and use methods like `as_ref()` or
`as_mut()` to obtain wrapped references.
# Objective
- It's currently very hard for beginners and advanced users to get a
full understanding of a complete render phase.
## Solution
- Implement a full custom render phase
- The render phase in the example is intended to show a custom stencil
phase that renders the stencil in red directly on the screen
---
## Showcase
<img width="1277" alt="image"
src="https://github.com/user-attachments/assets/e9dc0105-4fb6-463f-ad53-0529b575fd28"
/>
## Notes
More docs to explain what is going on is still needed but the example
works and can already help some people.
We might want to consider using a batched phase and cold specialization
in the future, but the example is already complex enough as it is.
---------
Co-authored-by: Christopher Biscardi <chris@christopherbiscardi.com>
# Objective
- I was getting familiar with the many_components example to test some
recent pr's for executor changes and saw some things to improve.
## Solution
- Use `insert_by_ids` instead of `insert_by_id`. This reduces the number
of archetype moves and improves startup times substantially.
- Add a tracing span to `base_system`. I'm not sure why, but tracing
spans weren't showing for this system. I think it's something to do with
how pipe system works, but need to investigate more. The approach in
this pr is a little better than the default span too, since it allows
adding the number of entities queried to the span which is not possible
with the default system span.
- println the number of archetype component id's that are created. This
is useful since part of the purpose of this stress test is to test how
well the use of FixedBitSet scales in the executor.
## Testing
- Ran the example with `cargo run --example many_components -F
trace_tracy 1000000` and connected with tracy
- Timed the time it took to spawn 1 million entities on main (240 s) vs
this pr (15 s)
---
## Showcase

## Future Work
- Currently systems are created with a random set of components and
entities are created with a random set of components without any
correlation between the randomness. This means that some systems won't
match any entities and some entities could not match any systems. It
might be better to spawn the entities from the pool of components that
match the queries that the systems are using.
# Objective
Fixes#15417.
## Solution
- Remove the `labeled_assets` fields from `LoadedAsset` and
`ErasedLoadedAsset`.
- Created new structs `CompleteLoadedAsset` and
`CompleteErasedLoadedAsset` to hold the `labeled_subassets`.
- When a subasset is `LoadContext::finish`ed, it produces a
`CompleteLoadedAsset`.
- When a `CompleteLoadedAsset` is added to a `LoadContext` (as a
subasset), their `labeled_assets` are merged, reporting any overlaps.
One important detail to note: nested subassets with overlapping names
could in theory have been used in the past for the purposes of asset
preprocessing. Even though there was no way to access these "shadowed"
nested subassets, asset preprocessing does get access to these nested
subassets. This does not seem like a case we should support though. It
is confusing at best.
## Testing
- This is just a refactor.
---
## Migration Guide
- Most uses of `LoadedAsset` and `ErasedLoadedAsset` should be replaced
with `CompleteLoadedAsset` and `CompleteErasedLoadedAsset` respectively.
# Objective
https://github.com/bevyengine/bevy/pull/16966 tried to fix a bug where
`slot` wasn't passed to `parallaxed_uv` when not running under bindless,
but failed to account for meshlets. This surfaces on macOS where
bindless is disabled.
## Solution
Lift the slot variable out of the bindless condition so it's always
available.
# Objective
It's difficult to understand or make changes to the UI systems because
of how each system needs to individually track changes to scale factor,
windows and camera targets in local hashmaps, particularly for new
contributors. Any major change inevitably introduces new scale factor
bugs.
Instead of per-system resolution we can resolve the camera target info
for all UI nodes in a system at the start of `PostUpdate` and then store
it per-node in components that can be queried with change detection.
Fixes#17578Fixes#15143
## Solution
Store the UI render target's data locally per node in a component that
is updated in `PostUpdate` before any other UI systems run.
This component can be then be queried with change detection so that UI
systems no longer need to have knowledge of cameras and windows and
don't require fragile custom change detection solutions using local
hashmaps.
## Showcase
Compare `measure_text_system` from main (which has a bug the causes it
to use the wrong scale factor when a node's camera target changes):
```
pub fn measure_text_system(
mut scale_factors_buffer: Local<EntityHashMap<f32>>,
mut last_scale_factors: Local<EntityHashMap<f32>>,
fonts: Res<Assets<Font>>,
camera_query: Query<(Entity, &Camera)>,
default_ui_camera: DefaultUiCamera,
ui_scale: Res<UiScale>,
mut text_query: Query<
(
Entity,
Ref<TextLayout>,
&mut ContentSize,
&mut TextNodeFlags,
&mut ComputedTextBlock,
Option<&UiTargetCamera>,
),
With<Node>,
>,
mut text_reader: TextUiReader,
mut text_pipeline: ResMut<TextPipeline>,
mut font_system: ResMut<CosmicFontSystem>,
) {
scale_factors_buffer.clear();
let default_camera_entity = default_ui_camera.get();
for (entity, block, content_size, text_flags, computed, maybe_camera) in &mut text_query {
let Some(camera_entity) = maybe_camera
.map(UiTargetCamera::entity)
.or(default_camera_entity)
else {
continue;
};
let scale_factor = match scale_factors_buffer.entry(camera_entity) {
Entry::Occupied(entry) => *entry.get(),
Entry::Vacant(entry) => *entry.insert(
camera_query
.get(camera_entity)
.ok()
.and_then(|(_, c)| c.target_scaling_factor())
.unwrap_or(1.0)
* ui_scale.0,
),
};
if last_scale_factors.get(&camera_entity) != Some(&scale_factor)
|| computed.needs_rerender()
|| text_flags.needs_measure_fn
|| content_size.is_added()
{
create_text_measure(
entity,
&fonts,
scale_factor.into(),
text_reader.iter(entity),
block,
&mut text_pipeline,
content_size,
text_flags,
computed,
&mut font_system,
);
}
}
core::mem::swap(&mut *last_scale_factors, &mut *scale_factors_buffer);
}
```
with `measure_text_system` from this PR (which always uses the correct
scale factor):
```
pub fn measure_text_system(
fonts: Res<Assets<Font>>,
mut text_query: Query<
(
Entity,
Ref<TextLayout>,
&mut ContentSize,
&mut TextNodeFlags,
&mut ComputedTextBlock,
Ref<ComputedNodeTarget>,
),
With<Node>,
>,
mut text_reader: TextUiReader,
mut text_pipeline: ResMut<TextPipeline>,
mut font_system: ResMut<CosmicFontSystem>,
) {
for (entity, block, content_size, text_flags, computed, computed_target) in &mut text_query {
// Note: the ComputedTextBlock::needs_rerender bool is cleared in create_text_measure().
if computed_target.is_changed()
|| computed.needs_rerender()
|| text_flags.needs_measure_fn
|| content_size.is_added()
{
create_text_measure(
entity,
&fonts,
computed_target.scale_factor.into(),
text_reader.iter(entity),
block,
&mut text_pipeline,
content_size,
text_flags,
computed,
&mut font_system,
);
}
}
}
```
## Testing
I removed an alarming number of tests from the `layout` module but they
were mostly to do with the deleted camera synchronisation logic. The
remaining tests should all pass now.
The most relevant examples are `multiple_windows` and `split_screen`,
the behaviour of both should be unchanged from main.
---------
Co-authored-by: UkoeHB <37489173+UkoeHB@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
A major critique of Bevy at the moment is how boilerplatey it is to
compose (and read) entity hierarchies:
```rust
commands
.spawn(Foo)
.with_children(|p| {
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
});
```
There is also currently no good way to statically define and return an
entity hierarchy from a function. Instead, people often do this
"internally" with a Commands function that returns nothing, making it
impossible to spawn the hierarchy in other cases (direct World spawns,
ChildSpawner, etc).
Additionally, because this style of API results in creating the
hierarchy bits _after_ the initial spawn of a bundle, it causes ECS
archetype changes (and often expensive table moves).
Because children are initialized after the fact, we also can't count
them to pre-allocate space. This means each time a child inserts itself,
it has a high chance of overflowing the currently allocated capacity in
the `RelationshipTarget` collection, causing literal worst-case
reallocations.
We can do better!
## Solution
The Bundle trait has been extended to support an optional
`BundleEffect`. This is applied directly to World immediately _after_
the Bundle has fully inserted. Note that this is
[intentionally](https://github.com/bevyengine/bevy/discussions/16920)
_not done via a deferred Command_, which would require repeatedly
copying each remaining subtree of the hierarchy to a new command as we
walk down the tree (_not_ good performance).
This allows us to implement the new `SpawnRelated` trait for all
`RelationshipTarget` impls, which looks like this in practice:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
))
))
```
`Children::spawn` returns `SpawnRelatedBundle<Children, L:
SpawnableList>`, which is a `Bundle` that inserts `Children`
(preallocated to the size of the `SpawnableList::size_hint()`).
`Spawn<B: Bundle>(pub B)` implements `SpawnableList` with a size of 1.
`SpawnableList` is also implemented for tuples of `SpawnableList` (same
general pattern as the Bundle impl).
There are currently three built-in `SpawnableList` implementations:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn(Name::new("Child1")),
SpawnIter(["Child2", "Child3"].into_iter().map(Name::new),
SpawnWith(|parent: &mut ChildSpawner| {
parent.spawn(Name::new("Child4"));
parent.spawn(Name::new("Child5"));
})
)),
))
```
We get the benefits of "structured init", but we have nice flexibility
where it is required!
Some readers' first instinct might be to try to remove the need for the
`Spawn` wrapper. This is impossible in the Rust type system, as a tuple
of "child Bundles to be spawned" and a "tuple of Components to be added
via a single Bundle" is ambiguous in the Rust type system. There are two
ways to resolve that ambiguity:
1. By adding support for variadics to the Rust type system (removing the
need for nested bundles). This is out of scope for this PR :)
2. Using wrapper types to resolve the ambiguity (this is what I did in
this PR).
For the single-entity spawn cases, `Children::spawn_one` does also
exist, which removes the need for the wrapper:
```rust
world.spawn((
Foo,
Children::spawn_one(Bar),
))
```
## This works for all Relationships
This API isn't just for `Children` / `ChildOf` relationships. It works
for any relationship type, and they can be mixed and matched!
```rust
world.spawn((
Foo,
Observers::spawn((
Spawn(Observer::new(|trigger: Trigger<FuseLit>| {})),
Spawn(Observer::new(|trigger: Trigger<Exploded>| {})),
)),
OwnerOf::spawn(Spawn(Bar))
Children::spawn(Spawn(Baz))
))
```
## Macros
While `Spawn` is necessary to satisfy the type system, we _can_ remove
the need to express it via macros. The example above can be expressed
more succinctly using the new `children![X]` macro, which internally
produces `Children::spawn(Spawn(X))`:
```rust
world.spawn((
Foo,
children![
(
Bar,
children![Baz],
),
(
Bar,
children![Baz],
),
]
))
```
There is also a `related!` macro, which is a generic version of the
`children!` macro that supports any relationship type:
```rust
world.spawn((
Foo,
related!(Children[
(
Bar,
related!(Children[Baz]),
),
(
Bar,
related!(Children[Baz]),
),
])
))
```
## Returning Hierarchies from Functions
Thanks to these changes, the following pattern is now possible:
```rust
fn button(text: &str, color: Color) -> impl Bundle {
(
Node {
width: Val::Px(300.),
height: Val::Px(100.),
..default()
},
BackgroundColor(color),
children![
Text::new(text),
]
)
}
fn ui() -> impl Bundle {
(
Node {
width: Val::Percent(100.0),
height: Val::Percent(100.0),
..default(),
},
children![
button("hello", BLUE),
button("world", RED),
]
)
}
// spawn from a system
fn system(mut commands: Commands) {
commands.spawn(ui());
}
// spawn directly on World
world.spawn(ui());
```
## Additional Changes and Notes
* `Bundle::from_components` has been split out into
`BundleFromComponents::from_components`, enabling us to implement
`Bundle` for types that cannot be "taken" from the ECS (such as the new
`SpawnRelatedBundle`).
* The `NoBundleEffect` trait (which implements `BundleEffect`) is
implemented for empty tuples (and tuples of empty tuples), which allows
us to constrain APIs to only accept bundles that do not have effects.
This is critical because the current batch spawn APIs cannot efficiently
apply BundleEffects in their current form (as doing so in-place could
invalidate the cached raw pointers). We could consider allocating a
buffer of the effects to be applied later, but that does have
performance implications that could offset the balance and value of the
batched APIs (and would likely require some refactors to the underlying
code). I've decided to be conservative here. We can consider relaxing
that requirement on those APIs later, but that should be done in a
followup imo.
* I've ported a few examples to illustrate real-world usage. I think in
a followup we should port all examples to the `children!` form whenever
possible (and for cases that require things like SpawnIter, use the raw
APIs).
* Some may ask "why not use the `Relationship` to spawn (ex:
`ChildOf::spawn(Foo)`) instead of the `RelationshipTarget` (ex:
`Children::spawn(Spawn(Foo))`)?". That _would_ allow us to remove the
`Spawn` wrapper. I've explicitly chosen to disallow this pattern.
`Bundle::Effect` has the ability to create _significant_ weirdness.
Things in `Bundle` position look like components. For example
`world.spawn((Foo, ChildOf::spawn(Bar)))` _looks and reads_ like Foo is
a child of Bar. `ChildOf` is in Foo's "component position" but it is not
a component on Foo. This is a huge problem. Now that `Bundle::Effect`
exists, we should be _very_ principled about keeping the "weird and
unintuitive behavior" to a minimum. Things that read like components
_should be the components they appear to be".
## Remaining Work
* The macros are currently trivially implemented using macro_rules and
are currently limited to the max tuple length. They will require a
proc_macro implementation to work around the tuple length limit.
## Next Steps
* Port the remaining examples to use `children!` where possible and raw
`Spawn` / `SpawnIter` / `SpawnWith` where the flexibility of the raw API
is required.
## Migration Guide
Existing spawn patterns will continue to work as expected.
Manual Bundle implementations now require a `BundleEffect` associated
type. Exisiting bundles would have no bundle effect, so use `()`.
Additionally `Bundle::from_components` has been moved to the new
`BundleFromComponents` trait.
```rust
// Before
unsafe impl Bundle for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
/* remaining bundle impl here */
}
// After
unsafe impl Bundle for X {
type Effect = ();
/* remaining bundle impl here */
}
unsafe impl BundleFromComponents for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
Co-authored-by: Emerson Coskey <emerson@coskey.dev>
# Objective
Solves https://github.com/bevyengine/bevy/issues/17747.
## Solution
- Adds an example for creating a default value for Local.
## Testing
- Example code compiles and passes assertions.
This pr uses the `extern crate self as` trick to make proc macros behave
the same way inside and outside bevy.
# Objective
- Removes noise introduced by `crate as` in the whole bevy repo.
- Fixes#17004.
- Hardens proc macro path resolution.
## TODO
- [x] `BevyManifest` needs cleanup.
- [x] Cleanup remaining `crate as`.
- [x] Add proper integration tests to the ci.
## Notes
- `cargo-manifest-proc-macros` is written by me and based/inspired by
the old `BevyManifest` implementation and
[`bkchr/proc-macro-crate`](https://github.com/bkchr/proc-macro-crate).
- What do you think about the new integration test machinery I added to
the `ci`?
More and better integration tests can be added at a later stage.
The goal of these integration tests is to simulate an actual separate
crate that uses bevy. Ideally they would lightly touch all bevy crates.
## Testing
- Needs RA test
- Needs testing from other users
- Others need to run at least `cargo run -p ci integration-test` and
verify that they work.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Didn't remove WgpuWrapper. Not sure if it's needed or not still.
## Testing
- Did you test these changes? If so, how? Example runner
- Are there any parts that need more testing? Web (portable atomics
thingy?), DXC.
## Migration Guide
- Bevy has upgraded to [wgpu
v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15).
- When using the DirectX 12 rendering backend, the new priority system
for choosing a shader compiler is as follows:
- If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it
is used
- Else if the new `statically-linked-dxc` feature is enabled, a custom
version of DXC will be statically linked into your app at compile time.
- Else Bevy will look in the app's working directory for
`dxcompiler.dll` and `dxil.dll` at runtime.
- Else if they are missing, Bevy will fall back to FXC (not recommended)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
The entity disabling / default query filter work added in #17514 and
#13120 is neat, but we don't teach users how it works!
We should fix that before 0.16.
## Solution
Write a simple example to teach the basics of entity disabling!
## Testing
`cargo run --example entity_disabling`
## Showcase

---------
Co-authored-by: Zachary Harrold <zac@harrold.com.au>
# Objective
Fix#16477.
## Solution
- Remove temporary silence introduced in #16763
- bump version of `notify-debouncer-full` to remove transitive
dependency on `instant` crate.
# Objective
- publish script copy the license files to all subcrates, meaning that
all publish are dirty. this breaks git verification of crates
- the order and list of crates to publish is manually maintained,
leading to error. cargo 1.84 is more strict and the list is currently
wrong
## Solution
- duplicate all the licenses to all crates and remove the
`--allow-dirty` flag
- instead of a manual list of crates, get it from `cargo package
--workspace`
- remove the `--no-verify` flag to... verify more things?
# Objective
Things were breaking post-cs.
## Solution
`specialize_mesh_materials` must run after
`collect_meshes_for_gpu_building`. Therefore, its placement in the
`PrepareAssets` set didn't make sense (also more generally). To fix, we
put this class of system in ~`PrepareResources`~ `QueueMeshes`, although
it potentially could use a more descriptive location. We may want to
review the placement of `check_views_need_specialization` which is also
currently in `PrepareAssets`.
PR #17684 broke occlusion culling because it neglected to set the
indirect parameter offsets for the late mesh preprocessing stage if the
work item buffers were already set. This PR moves the update of those
values to a new function, `init_work_item_buffers`, which is
unconditionally called for every phase every frame.
Note that there's some complexity in order to handle the case in which
occlusion culling was enabled on one frame and disabled on the next, or
vice versa. This was necessary in order to make the occlusion culling
toggle in the `occlusion_culling` example work again.
Right now, we key the cached light change ticks off the `LightEntity`.
This uses the render world entity, which isn't stable between frames.
Thus in practice few shadows are retained from frame to frame. This PR
fixes the issue by keying off the `RetainedViewEntity` instead, which is
designed to be stable from frame to frame.
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
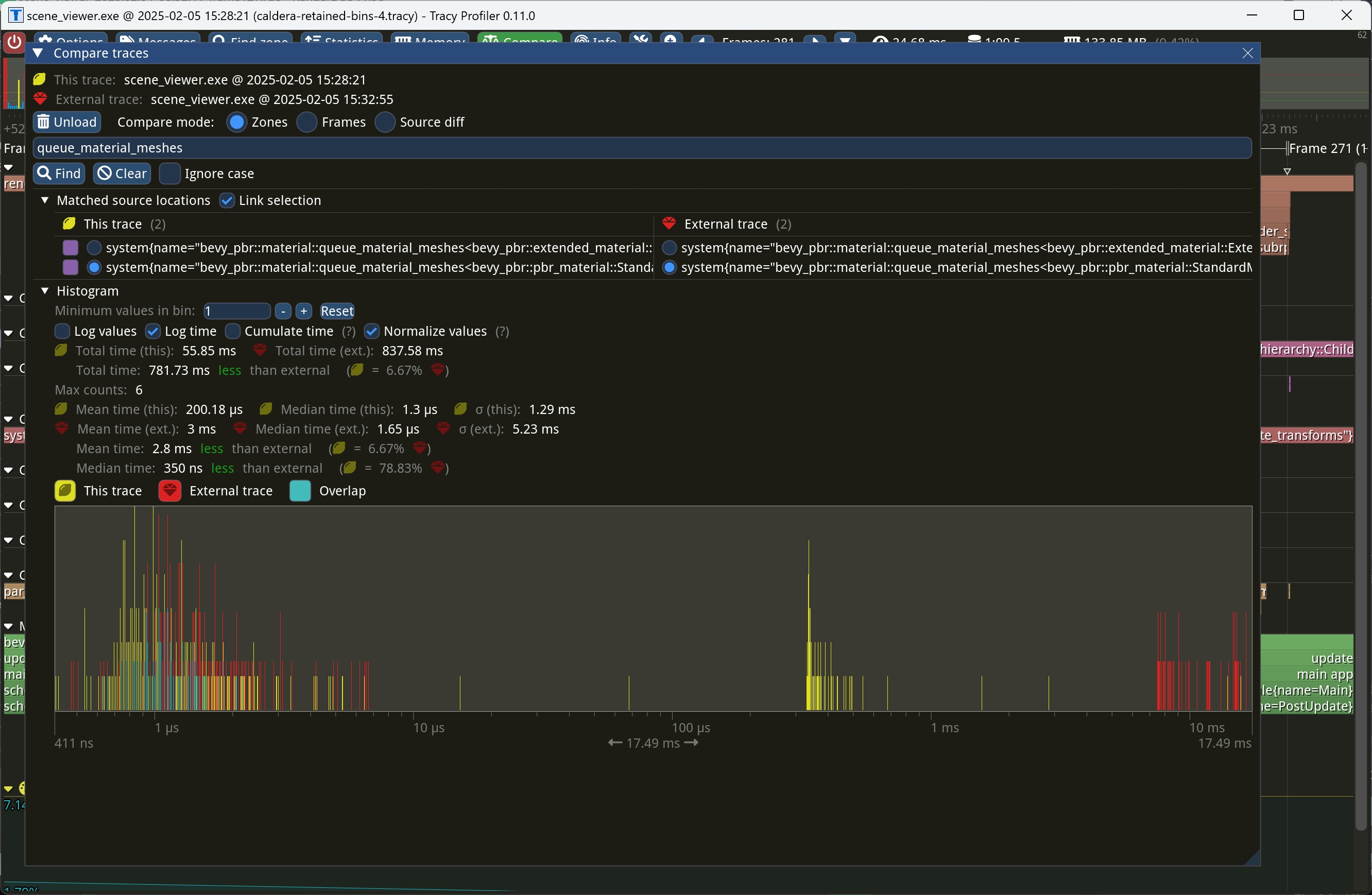
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
# Objective
After #17461, the ease function labels in this example are a bit
cramped, especially in the bottom row.
This adjusts the spacing slightly and centers the labels.
## Solution
- The label is now a child of the plot and they are drawn around the
center of the transform
- Plot size and extents are now constants, and this thing has been
banished:
```rust
i as f32 * 95.0 - 1280.0 / 2.0 + 25.0,
-100.0 - ((j as f32 * 250.0) - 300.0),
0.0,
```
- There's room for expansion in another row, so make that easier by
doing the chunking by row
- Other misc tidying of variable names, sprinkled in a few comments,
etc.
## Before
<img width="1280" alt="Screenshot 2025-02-08 at 7 33 14 AM"
src="https://github.com/user-attachments/assets/0b79c619-d295-4ab1-8cd1-d23c862d06c5"
/>
## After
<img width="1280" alt="Screenshot 2025-02-08 at 7 32 45 AM"
src="https://github.com/user-attachments/assets/656ef695-9aa8-42e9-b867-1718294316bd"
/>
# Objective
The docs of `EaseFunction` don't visualize the different functions,
requiring you to check out the Bevy repo and running the
`easing_function` example.
## Solution
- Add tool to generate suitable svg graphs. This only needs to be re-run
when adding new ease functions.
- works with all themes
- also add missing easing functions to example.
---
## Showcase

---------
Co-authored-by: François Mockers <mockersf@gmail.com>
Right now, meshes aren't grouped together based on the bindless texture
slab when drawing shadows. This manifests itself as flickering in
Bistro. I believe that there are two causes of this:
1. Alpha masked shadows may try to sample from the wrong texture,
causing the alpha mask to appear and disappear.
2. Objects may try to sample from the blank textures that we pad out the
bindless slabs with, causing them to vanish intermittently.
This commit fixes the issue by including the material bind group ID as
part of the shadow batch set key, just as we do for the prepass and main
pass.
# Objective
Fixes#17718
## Solution
Schedule `text_system` before `AssetEvents`.
I guess what was happening here is that glyphs weren't shown because
`text_system` was running before `AssetEevents` and so `prepare_uinodes`
never recieves the the asset modified event about the glyph texture
atlas image.
Fixes#17535
Bevy's approach to handling "entity mapping" during spawning and cloning
needs some work. The addition of
[Relations](https://github.com/bevyengine/bevy/pull/17398) both
[introduced a new "duplicate entities" bug when spawning scenes in the
scene system](#17535) and made the weaknesses of the current mapping
system exceedingly clear:
1. Entity mapping requires _a ton_ of boilerplate (implement or derive
VisitEntities and VisitEntitesMut, then register / reflect MapEntities).
Knowing the incantation is challenging and if you forget to do it in
part or in whole, spawning subtly breaks.
2. Entity mapping a spawned component in scenes incurs unnecessary
overhead: look up ReflectMapEntities, create a _brand new temporary
instance_ of the component using FromReflect, map the entities in that
instance, and then apply that on top of the actual component using
reflection. We can do much better.
Additionally, while our new [Entity cloning
system](https://github.com/bevyengine/bevy/pull/16132) is already pretty
great, it has some areas we can make better:
* It doesn't expose semantic info about the clone (ex: ignore or "clone
empty"), meaning we can't key off of that in places where it would be
useful, such as scene spawning. Rather than duplicating this info across
contexts, I think it makes more sense to add that info to the clone
system, especially given that we'd like to use cloning code in some of
our spawning scenarios.
* EntityCloner is currently built in a way that prioritizes a single
entity clone
* EntityCloner's recursive cloning is built to be done "inside out" in a
parallel context (queue commands that each have a clone of
EntityCloner). By making EntityCloner the orchestrator of the clone we
can remove internal arcs, improve the clarity of the code, make
EntityCloner mutable again, and simplify the builder code.
* EntityCloner does not currently take into account entity mapping. This
is necessary to do true "bullet proof" cloning, would allow us to unify
the per-component scene spawning and cloning UX, and ultimately would
allow us to use EntityCloner in place of raw reflection for scenes like
`Scene(World)` (which would give us a nice performance boost: fewer
archetype moves, less reflection overhead).
## Solution
### Improved Entity Mapping
First, components now have first-class "entity visiting and mapping"
behavior:
```rust
#[derive(Component, Reflect)]
#[reflect(Component)]
struct Inventory {
size: usize,
#[entities]
items: Vec<Entity>,
}
```
Any field with the `#[entities]` annotation will be viewable and
mappable when cloning and spawning scenes.
Compare that to what was required before!
```rust
#[derive(Component, Reflect, VisitEntities, VisitEntitiesMut)]
#[reflect(Component, MapEntities)]
struct Inventory {
#[visit_entities(ignore)]
size: usize,
items: Vec<Entity>,
}
```
Additionally, for relationships `#[entities]` is implied, meaning this
"just works" in scenes and cloning:
```rust
#[derive(Component, Reflect)]
#[relationship(relationship_target = Children)]
#[reflect(Component)]
struct ChildOf(pub Entity);
```
Note that Component _does not_ implement `VisitEntities` directly.
Instead, it has `Component::visit_entities` and
`Component::visit_entities_mut` methods. This is for a few reasons:
1. We cannot implement `VisitEntities for C: Component` because that
would conflict with our impl of VisitEntities for anything that
implements `IntoIterator<Item=Entity>`. Preserving that impl is more
important from a UX perspective.
2. We should not implement `Component: VisitEntities` VisitEntities in
the Component derive, as that would increase the burden of manual
Component trait implementors.
3. Making VisitEntitiesMut directly callable for components would make
it easy to invalidate invariants defined by a component author. By
putting it in the `Component` impl, we can make it harder to call
naturally / unavailable to autocomplete using `fn
visit_entities_mut(this: &mut Self, ...)`.
`ReflectComponent::apply_or_insert` is now
`ReflectComponent::apply_or_insert_mapped`. By moving mapping inside
this impl, we remove the need to go through the reflection system to do
entity mapping, meaning we no longer need to create a clone of the
target component, map the entities in that component, and patch those
values on top. This will make spawning mapped entities _much_ faster
(The default `Component::visit_entities_mut` impl is an inlined empty
function, so it will incur no overhead for unmapped entities).
### The Bug Fix
To solve #17535, spawning code now skips entities with the new
`ComponentCloneBehavior::Ignore` and
`ComponentCloneBehavior::RelationshipTarget` variants (note
RelationshipTarget is a temporary "workaround" variant that allows
scenes to skip these components. This is a temporary workaround that can
be removed as these cases should _really_ be using EntityCloner logic,
which should be done in a followup PR. When that is done,
`ComponentCloneBehavior::RelationshipTarget` can be merged into the
normal `ComponentCloneBehavior::Custom`).
### Improved Cloning
* `Option<ComponentCloneHandler>` has been replaced by
`ComponentCloneBehavior`, which encodes additional intent and context
(ex: `Default`, `Ignore`, `Custom`, `RelationshipTarget` (this last one
is temporary)).
* Global per-world entity cloning configuration has been removed. This
felt overly complicated, increased our API surface, and felt too
generic. Each clone context can have different requirements (ex: what a
user wants in a specific system, what a scene spawner wants, etc). I'd
prefer to see how far context-specific EntityCloners get us first.
* EntityCloner's internals have been reworked to remove Arcs and make it
mutable.
* EntityCloner is now directly stored on EntityClonerBuilder,
simplifying the code somewhat
* EntityCloner's "bundle scratch" pattern has been moved into the new
BundleScratch type, improving its usability and making it usable in
other contexts (such as future cross-world cloning code). Currently this
is still private, but with some higher level safe APIs it could be used
externally for making dynamic bundles
* EntityCloner's recursive cloning behavior has been "externalized". It
is now responsible for orchestrating recursive clones, meaning it no
longer needs to be sharable/clone-able across threads / read-only.
* EntityCloner now does entity mapping during clones, like scenes do.
This gives behavior parity and also makes it more generically useful.
* `RelatonshipTarget::RECURSIVE_SPAWN` is now
`RelationshipTarget::LINKED_SPAWN`, and this field is used when cloning
relationship targets to determine if cloning should happen recursively.
The new `LINKED_SPAWN` term was picked to make it more generically
applicable across spawning and cloning scenarios.
## Next Steps
* I think we should adapt EntityCloner to support cross world cloning. I
think this PR helps set the stage for that by making the internals
slightly more generalized. We could have a CrossWorldEntityCloner that
reuses a lot of this infrastructure.
* Once we support cross world cloning, we should use EntityCloner to
spawn `Scene(World)` scenes. This would yield significant performance
benefits (no archetype moves, less reflection overhead).
---------
Co-authored-by: eugineerd <70062110+eugineerd@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
{kind=link}