# Objective
- Fixes#15460 (will open new issues for further `no_std` efforts)
- Supersedes #17715
## Solution
- Threaded in new features as required
- Made certain crates optional but default enabled
- Removed `compile-check-no-std` from internal `ci` tool since GitHub CI
can now simply check `bevy` itself now
- Added CI task to check `bevy` on `thumbv6m-none-eabi` to ensure
`portable-atomic` support is still valid [^1]
[^1]: This may be controversial, since it could be interpreted as
implying Bevy will maintain support for `thumbv6m-none-eabi` going
forward. In reality, just like `x86_64-unknown-none`, this is a
[canary](https://en.wiktionary.org/wiki/canary_in_a_coal_mine) target to
make it clear when `portable-atomic` no longer works as intended (fixing
atomic support on atomically challenged platforms). If a PR comes
through and makes supporting this class of platforms impossible, then
this CI task can be removed. I however wager this won't be a problem.
## Testing
- CI
---
## Release Notes
Bevy now has support for `no_std` directly from the `bevy` crate.
Users can disable default features and enable a new `default_no_std`
feature instead, allowing `bevy` to be used in `no_std` applications and
libraries.
```toml
# Bevy for `no_std` platforms
bevy = { version = "0.16", default-features = false, features = ["default_no_std"] }
```
`default_no_std` enables certain required features, such as `libm` and
`critical-section`, and as many optional crates as possible (currently
just `bevy_state`). For atomically-challenged platforms such as the
Raspberry Pi Pico, `portable-atomic` will be used automatically.
For library authors, we recommend depending on `bevy` with
`default-features = false` to allow `std` and `no_std` users to both
depend on your crate. Here are some recommended features a library crate
may want to expose:
```toml
[features]
# Most users will be on a platform which has `std` and can use the more-powerful `async_executor`.
default = ["std", "async_executor"]
# Features for typical platforms.
std = ["bevy/std"]
async_executor = ["bevy/async_executor"]
# Features for `no_std` platforms.
libm = ["bevy/libm"]
critical-section = ["bevy/critical-section"]
[dependencies]
# We disable default features to ensure we don't accidentally enable `std` on `no_std` targets, for example.
bevy = { version = "0.16", default-features = false }
```
While this is verbose, it gives the maximum control to end-users to
decide how they wish to use Bevy on their platform.
We encourage library authors to experiment with `no_std` support. For
libraries relying exclusively on `bevy` and no other dependencies, it
may be as simple as adding `#![no_std]` to your `lib.rs` and exposing
features as above! Bevy can also provide many `std` types, such as
`HashMap`, `Mutex`, and `Instant` on all platforms. See
`bevy::platform_support` for details on what's available out of the box!
## Migration Guide
- If you were previously relying on `bevy` with default features
disabled, you may need to enable the `std` and `async_executor`
features.
- `bevy_reflect` has had its `bevy` feature removed. If you were relying
on this feature, simply enable `smallvec` and `smol_str` instead.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fixes#17960
## Solution
- Followed the [edition upgrade
guide](https://doc.rust-lang.org/edition-guide/editions/transitioning-an-existing-project-to-a-new-edition.html)
## Testing
- CI
---
## Summary of Changes
### Documentation Indentation
When using lists in documentation, proper indentation is now linted for.
This means subsequent lines within the same list item must start at the
same indentation level as the item.
```rust
/* Valid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
/* Invalid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
```
### Implicit `!` to `()` Conversion
`!` (the never return type, returned by `panic!`, etc.) no longer
implicitly converts to `()`. This is particularly painful for systems
with `todo!` or `panic!` statements, as they will no longer be functions
returning `()` (or `Result<()>`), making them invalid systems for
functions like `add_systems`. The ideal fix would be to accept functions
returning `!` (or rather, _not_ returning), but this is blocked on the
[stabilisation of the `!` type
itself](https://doc.rust-lang.org/std/primitive.never.html), which is
not done.
The "simple" fix would be to add an explicit `-> ()` to system
signatures (e.g., `|| { todo!() }` becomes `|| -> () { todo!() }`).
However, this is _also_ banned, as there is an existing lint which (IMO,
incorrectly) marks this as an unnecessary annotation.
So, the "fix" (read: workaround) is to put these kinds of `|| -> ! { ...
}` closuers into variables and give the variable an explicit type (e.g.,
`fn()`).
```rust
// Valid
let system: fn() = || todo!("Not implemented yet!");
app.add_systems(..., system);
// Invalid
app.add_systems(..., || todo!("Not implemented yet!"));
```
### Temporary Variable Lifetimes
The order in which temporary variables are dropped has changed. The
simple fix here is _usually_ to just assign temporaries to a named
variable before use.
### `gen` is a keyword
We can no longer use the name `gen` as it is reserved for a future
generator syntax. This involved replacing uses of the name `gen` with
`r#gen` (the raw-identifier syntax).
### Formatting has changed
Use statements have had the order of imports changed, causing a
substantial +/-3,000 diff when applied. For now, I have opted-out of
this change by amending `rustfmt.toml`
```toml
style_edition = "2021"
```
This preserves the original formatting for now, reducing the size of
this PR. It would be a simple followup to update this to 2024 and run
`cargo fmt`.
### New `use<>` Opt-Out Syntax
Lifetimes are now implicitly included in RPIT types. There was a handful
of instances where it needed to be added to satisfy the borrow checker,
but there may be more cases where it _should_ be added to avoid
breakages in user code.
### `MyUnitStruct { .. }` is an invalid pattern
Previously, you could match against unit structs (and unit enum
variants) with a `{ .. }` destructuring. This is no longer valid.
### Pretty much every use of `ref` and `mut` are gone
Pattern binding has changed to the point where these terms are largely
unused now. They still serve a purpose, but it is far more niche now.
### `iter::repeat(...).take(...)` is bad
New lint recommends using the more explicit `iter::repeat_n(..., ...)`
instead.
## Migration Guide
The lifetimes of functions using return-position impl-trait (RPIT) are
likely _more_ conservative than they had been previously. If you
encounter lifetime issues with such a function, please create an issue
to investigate the addition of `+ use<...>`.
## Notes
- Check the individual commits for a clearer breakdown for what
_actually_ changed.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
Currently, invocations of `batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` can't run in parallel because
they write to scene-global GPU buffers. After PR #17698,
`batch_and_prepare_binned_render_phase` started accounting for the
lion's share of the CPU time, causing us to be strongly CPU bound on
scenes like Caldera when occlusion culling was on (because of the
overhead of batching for the Z-prepass). Although I eventually plan to
optimize `batch_and_prepare_binned_render_phase`, we can obtain
significant wins now by parallelizing that system across phases.
This commit splits all GPU buffers that
`batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` touches into separate buffers
for each phase so that the scheduler will run those phases in parallel.
At the end of batch preparation, we gather the render phases up into a
single resource with a new *collection* phase. Because we already run
mesh preprocessing separately for each phase in order to make occlusion
culling work, this is actually a cleaner separation. For example, mesh
output indices (the unique ID that identifies each mesh instance on GPU)
are now guaranteed to be sequential starting from 0, which will simplify
the forthcoming work to remove them in favor of the compute dispatch ID.
On Caldera, this brings the frame time down to approximately 9.1 ms with
occlusion culling on.

## Objective
Get rid of a redundant Cargo feature flag.
## Solution
Use the built-in `target_abi = "sim"` instead of a custom Cargo feature
flag, which is set for the iOS (and visionOS and tvOS) simulator. This
has been stable since Rust 1.78.
In the future, some of this may become redundant if Wgpu implements
proper supper for the iOS Simulator:
https://github.com/gfx-rs/wgpu/issues/7057
CC @mockersf who implemented [the original
fix](https://github.com/bevyengine/bevy/pull/10178).
## Testing
- Open mobile example in Xcode.
- Launch the simulator.
- See that no errors are emitted.
- Remove the code cfg-guarded behind `target_abi = "sim"`.
- See that an error now happens.
(I haven't actually performed these steps on the latest `main`, because
I'm hitting an unrelated error (EDIT: It was
https://github.com/bevyengine/bevy/pull/17637). But tested it on
0.15.0).
---
## Migration Guide
> If you're using a project that builds upon the mobile example, remove
the `ios_simulator` feature from your `Cargo.toml` (Bevy now handles
this internally).
Didn't remove WgpuWrapper. Not sure if it's needed or not still.
## Testing
- Did you test these changes? If so, how? Example runner
- Are there any parts that need more testing? Web (portable atomics
thingy?), DXC.
## Migration Guide
- Bevy has upgraded to [wgpu
v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15).
- When using the DirectX 12 rendering backend, the new priority system
for choosing a shader compiler is as follows:
- If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it
is used
- Else if the new `statically-linked-dxc` feature is enabled, a custom
version of DXC will be statically linked into your app at compile time.
- Else Bevy will look in the app's working directory for
`dxcompiler.dll` and `dxil.dll` at runtime.
- Else if they are missing, Bevy will fall back to FXC (not recommended)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
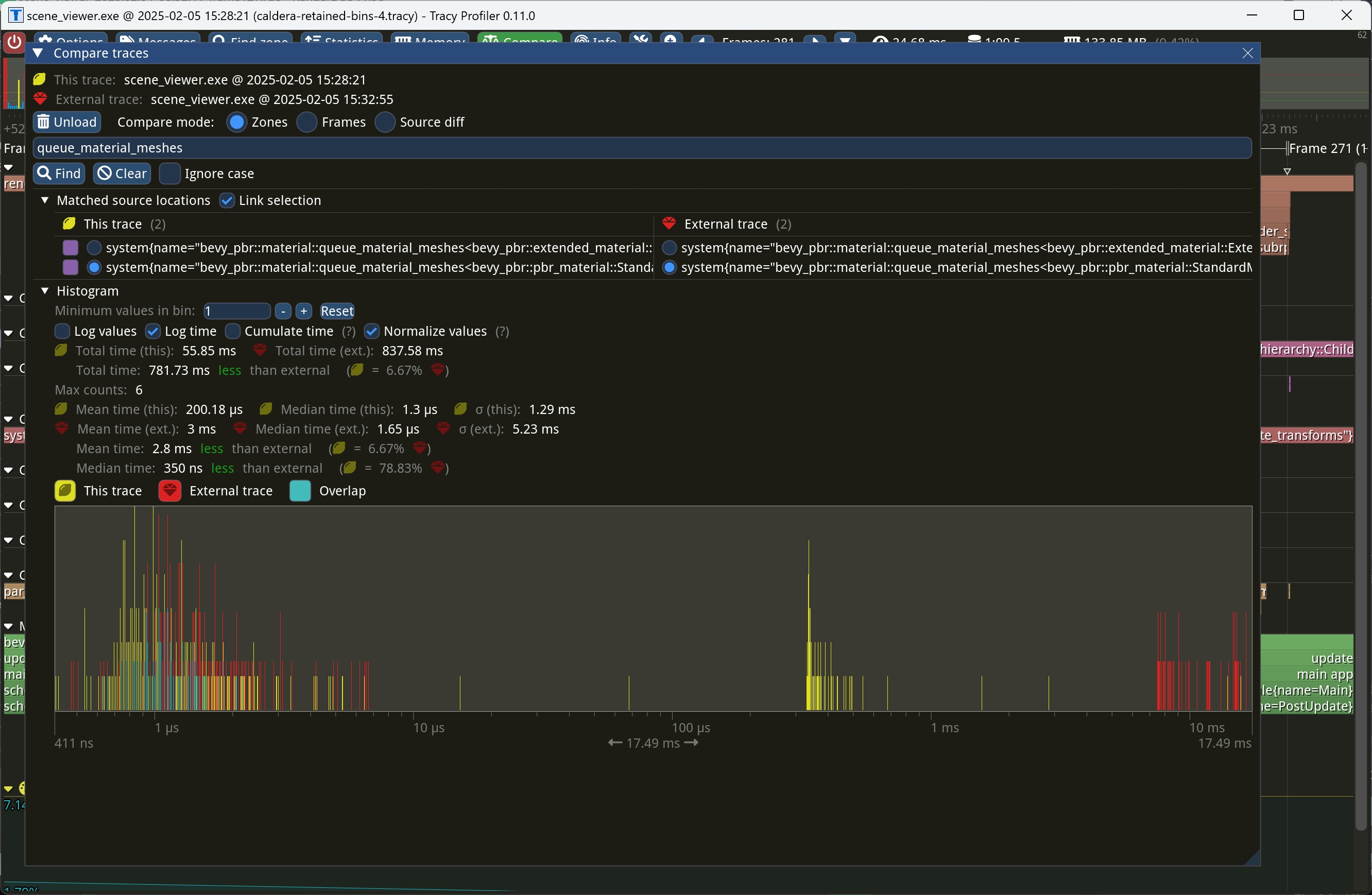
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
# Objective
- Contributes to #16877
## Solution
- Moved `hashbrown`, `foldhash`, and related types out of `bevy_utils`
and into `bevy_platform_support`
- Refactored the above to match the layout of these types in `std`.
- Updated crates as required.
## Testing
- CI
---
## Migration Guide
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::hash`:
- `FixedState`
- `DefaultHasher`
- `RandomState`
- `FixedHasher`
- `Hashed`
- `PassHash`
- `PassHasher`
- `NoOpHash`
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::collections`:
- `HashMap`
- `HashSet`
- `bevy_utils::hashbrown` has been removed. Instead, import from
`bevy_platform_support::collections` _or_ take a dependency on
`hashbrown` directly.
- `bevy_utils::Entry` has been removed. Instead, import from
`bevy_platform_support::collections::hash_map` or
`bevy_platform_support::collections::hash_set` as appropriate.
- All of the above equally apply to `bevy::utils` and
`bevy::platform_support`.
## Notes
- I left `PreHashMap`, `PreHashMapExt`, and `TypeIdMap` in `bevy_utils`
as they might be candidates for micro-crating. They can always be moved
into `bevy_platform_support` at a later date if desired.
# Objective
- Contributes to #16877
## Solution
- Initial creation of `bevy_platform_support` crate.
- Moved `bevy_utils::Instant` into new `bevy_platform_support` crate.
- Moved `portable-atomic`, `portable-atomic-util`, and
`critical-section` into new `bevy_platform_support` crate.
## Testing
- CI
---
## Showcase
Instead of needing code like this to import an `Arc`:
```rust
#[cfg(feature = "portable-atomic")]
use portable_atomic_util::Arc;
#[cfg(not(feature = "portable-atomic"))]
use alloc::sync::Arc;
```
We can now use:
```rust
use bevy_platform_support::sync::Arc;
```
This applies to many other types, but the goal is overall the same:
allowing crates to use `std`-like types without the boilerplate of
conditional compilation and platform-dependencies.
## Migration Guide
- Replace imports of `bevy_utils::Instant` with
`bevy_platform_support::time::Instant`
- Replace imports of `bevy::utils::Instant` with
`bevy::platform_support::time::Instant`
## Notes
- `bevy_platform_support` hasn't been reserved on `crates.io`
- ~~`bevy_platform_support` is not re-exported from `bevy` at this time.
It may be worthwhile exporting this crate, but I am unsure of a
reasonable name to export it under (`platform_support` may be a bit
wordy for user-facing).~~
- I've included an implementation of `Instant` which is suitable for
`no_std` platforms that are not Wasm for the sake of eliminating feature
gates around its use. It may be a controversial inclusion, so I'm happy
to remove it if required.
- There are many other items (`spin`, `bevy_utils::Sync(Unsafe)Cell`,
etc.) which should be added to this crate. I have kept the initial scope
small to demonstrate utility without making this too unwieldy.
---------
Co-authored-by: TimJentzsch <TimJentzsch@users.noreply.github.com>
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
This adds support for one-to-many non-fragmenting relationships (with
planned paths for fragmenting and non-fragmenting many-to-many
relationships). "Non-fragmenting" means that entities with the same
relationship type, but different relationship targets, are not forced
into separate tables (which would cause "table fragmentation").
Functionally, this fills a similar niche as the current Parent/Children
system. The biggest differences are:
1. Relationships have simpler internals and significantly improved
performance and UX. Commands and specialized APIs are no longer
necessary to keep everything in sync. Just spawn entities with the
relationship components you want and everything "just works".
2. Relationships are generalized. Bevy can provide additional built in
relationships, and users can define their own.
**REQUEST TO REVIEWERS**: _please don't leave top level comments and
instead comment on specific lines of code. That way we can take
advantage of threaded discussions. Also dont leave comments simply
pointing out CI failures as I can read those just fine._
## Built on top of what we have
Relationships are implemented on top of the Bevy ECS features we already
have: components, immutability, and hooks. This makes them immediately
compatible with all of our existing (and future) APIs for querying,
spawning, removing, scenes, reflection, etc. The fewer specialized APIs
we need to build, maintain, and teach, the better.
## Why focus on one-to-many non-fragmenting first?
1. This allows us to improve Parent/Children relationships immediately,
in a way that is reasonably uncontroversial. Switching our hierarchy to
fragmenting relationships would have significant performance
implications. ~~Flecs is heavily considering a switch to non-fragmenting
relations after careful considerations of the performance tradeoffs.~~
_(Correction from @SanderMertens: Flecs is implementing non-fragmenting
storage specialized for asset hierarchies, where asset hierarchies are
many instances of small trees that have a well defined structure)_
2. Adding generalized one-to-many relationships is currently a priority
for the [Next Generation Scene / UI
effort](https://github.com/bevyengine/bevy/discussions/14437).
Specifically, we're interested in building reactions and observers on
top.
## The changes
This PR does the following:
1. Adds a generic one-to-many Relationship system
3. Ports the existing Parent/Children system to Relationships, which now
lives in `bevy_ecs::hierarchy`. The old `bevy_hierarchy` crate has been
removed.
4. Adds on_despawn component hooks
5. Relationships can opt-in to "despawn descendants" behavior, meaning
that the entire relationship hierarchy is despawned when
`entity.despawn()` is called. The built in Parent/Children hierarchies
enable this behavior, and `entity.despawn_recursive()` has been removed.
6. `world.spawn` now applies commands after spawning. This ensures that
relationship bookkeeping happens immediately and removes the need to
manually flush. This is in line with the equivalent behaviors recently
added to the other APIs (ex: insert).
7. Removes the ValidParentCheckPlugin (system-driven / poll based) in
favor of a `validate_parent_has_component` hook.
## Using Relationships
The `Relationship` trait looks like this:
```rust
pub trait Relationship: Component + Sized {
type RelationshipSources: RelationshipSources<Relationship = Self>;
fn get(&self) -> Entity;
fn from(entity: Entity) -> Self;
}
```
A relationship is a component that:
1. Is a simple wrapper over a "target" Entity.
2. Has a corresponding `RelationshipSources` component, which is a
simple wrapper over a collection of entities. Every "target entity"
targeted by a "source entity" with a `Relationship` has a
`RelationshipSources` component, which contains every "source entity"
that targets it.
For example, the `Parent` component (as it currently exists in Bevy) is
the `Relationship` component and the entity containing the Parent is the
"source entity". The entity _inside_ the `Parent(Entity)` component is
the "target entity". And that target entity has a `Children` component
(which implements `RelationshipSources`).
In practice, the Parent/Children relationship looks like this:
```rust
#[derive(Relationship)]
#[relationship(relationship_sources = Children)]
pub struct Parent(pub Entity);
#[derive(RelationshipSources)]
#[relationship_sources(relationship = Parent)]
pub struct Children(Vec<Entity>);
```
The Relationship and RelationshipSources derives automatically implement
Component with the relevant configuration (namely, the hooks necessary
to keep everything in sync).
The most direct way to add relationships is to spawn entities with
relationship components:
```rust
let a = world.spawn_empty().id();
let b = world.spawn(Parent(a)).id();
assert_eq!(world.entity(a).get::<Children>().unwrap(), &[b]);
```
There are also convenience APIs for spawning more than one entity with
the same relationship:
```rust
world.spawn_empty().with_related::<Children>(|s| {
s.spawn_empty();
s.spawn_empty();
})
```
The existing `with_children` API is now a simpler wrapper over
`with_related`. This makes this change largely non-breaking for existing
spawn patterns.
```rust
world.spawn_empty().with_children(|s| {
s.spawn_empty();
s.spawn_empty();
})
```
There are also other relationship APIs, such as `add_related` and
`despawn_related`.
## Automatic recursive despawn via the new on_despawn hook
`RelationshipSources` can opt-in to "despawn descendants" behavior,
which will despawn all related entities in the relationship hierarchy:
```rust
#[derive(RelationshipSources)]
#[relationship_sources(relationship = Parent, despawn_descendants)]
pub struct Children(Vec<Entity>);
```
This means that `entity.despawn_recursive()` is no longer required.
Instead, just use `entity.despawn()` and the relevant related entities
will also be despawned.
To despawn an entity _without_ despawning its parent/child descendants,
you should remove the `Children` component first, which will also remove
the related `Parent` components:
```rust
entity
.remove::<Children>()
.despawn()
```
This builds on the on_despawn hook introduced in this PR, which is fired
when an entity is despawned (before other hooks).
## Relationships are the source of truth
`Relationship` is the _single_ source of truth component.
`RelationshipSources` is merely a reflection of what all the
`Relationship` components say. By embracing this, we are able to
significantly improve the performance of the system as a whole. We can
rely on component lifecycles to protect us against duplicates, rather
than needing to scan at runtime to ensure entities don't already exist
(which results in quadratic runtime). A single source of truth gives us
constant-time inserts. This does mean that we cannot directly spawn
populated `Children` components (or directly add or remove entities from
those components). I personally think this is a worthwhile tradeoff,
both because it makes the performance much better _and_ because it means
theres exactly one way to do things (which is a philosophy we try to
employ for Bevy APIs).
As an aside: treating both sides of the relationship as "equivalent
source of truth relations" does enable building simple and flexible
many-to-many relationships. But this introduces an _inherent_ need to
scan (or hash) to protect against duplicates.
[`evergreen_relations`](https://github.com/EvergreenNest/evergreen_relations)
has a very nice implementation of the "symmetrical many-to-many"
approach. Unfortunately I think the performance issues inherent to that
approach make it a poor choice for Bevy's default relationship system.
## Followup Work
* Discuss renaming `Parent` to `ChildOf`. I refrained from doing that in
this PR to keep the diff reasonable, but I'm personally biased toward
this change (and using that naming pattern generally for relationships).
* [Improved spawning
ergonomics](https://github.com/bevyengine/bevy/discussions/16920)
* Consider adding relationship observers/triggers for "relationship
targets" whenever a source is added or removed. This would replace the
current "hierarchy events" system, which is unused upstream but may have
existing users downstream. I think triggers are the better fit for this
than a buffered event queue, and would prefer not to add that back.
* Fragmenting relations: My current idea hinges on the introduction of
"value components" (aka: components whose type _and_ value determines
their ComponentId, via something like Hashing / PartialEq). By labeling
a Relationship component such as `ChildOf(Entity)` as a "value
component", `ChildOf(e1)` and `ChildOf(e2)` would be considered
"different components". This makes the transition between fragmenting
and non-fragmenting a single flag, and everything else continues to work
as expected.
* Many-to-many support
* Non-fragmenting: We can expand Relationship to be a list of entities
instead of a single entity. I have largely already written the code for
this.
* Fragmenting: With the "value component" impl mentioned above, we get
many-to-many support "for free", as it would allow inserting multiple
copies of a Relationship component with different target entities.
Fixes#3742 (If this PR is merged, I think we should open more targeted
followup issues for the work above, with a fresh tracking issue free of
the large amount of less-directed historical context)
Fixes#17301Fixes#12235Fixes#15299Fixes#15308
## Migration Guide
* Replace `ChildBuilder` with `ChildSpawnerCommands`.
* Replace calls to `.set_parent(parent_id)` with
`.insert(Parent(parent_id))`.
* Replace calls to `.replace_children()` with `.remove::<Children>()`
followed by `.add_children()`. Note that you'll need to manually despawn
any children that are not carried over.
* Replace calls to `.despawn_recursive()` with `.despawn()`.
* Replace calls to `.despawn_descendants()` with
`.despawn_related::<Children>()`.
* If you have any calls to `.despawn()` which depend on the children
being preserved, you'll need to remove the `Children` component first.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective & Solution
- Update `downcast-rs` to the latest version, 2.
- Disable (new) `sync` feature to improve compatibility with atomically
challenged platforms.
- Remove stub `downcast-rs` alternative code from `bevy_app`
## Testing
- CI
## Notes
The only change from version 1 to version 2 is the addition of a new
`sync` feature, which allows disabling the `DowncastSync` parts of
`downcast-rs`, which require access to `alloc::sync::Arc`, which is not
available on atomically challenged platforms. Since Bevy makes no use of
the functionality provided by the `sync` feature, I've disabled it in
all crates. Further details can be found
[here](https://github.com/marcianx/downcast-rs/pull/22).
Bump version after release
This PR has been auto-generated
---------
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François Mockers <mockersf@gmail.com>
# Objective
- Contributes to #11478
## Solution
- Made `bevy_utils::tracing` `doc(hidden)`
- Re-exported `tracing` from `bevy_log` for end-users
- Added `tracing` directly to crates that need it.
## Testing
- CI
---
## Migration Guide
If you were importing `tracing` via `bevy::utils::tracing`, instead use
`bevy::log::tracing`. Note that many items within `tracing` are also
directly re-exported from `bevy::log` as well, so you may only need
`bevy::log` for the most common items (e.g., `warn!`, `trace!`, etc.).
This also applies to the `log_once!` family of macros.
## Notes
- While this doesn't reduce the line-count in `bevy_utils`, it further
decouples the internal crates from `bevy_utils`, making its eventual
removal more feasible in the future.
- I have just imported `tracing` as we do for all dependencies. However,
a workspace dependency may be more appropriate for version management.
# Objective
- Fixes#16892
## Solution
- Removed `TypeRegistryPlugin` (`Name` is now automatically registered
with a default `App`)
- Moved `TaskPoolPlugin` to `bevy_app`
- Moved `FrameCountPlugin` to `bevy_diagnostic`
- Deleted now-empty `bevy_core`
## Testing
- CI
## Migration Guide
- `TypeRegistryPlugin` no longer exists. If you can't use a default
`App` but still need `Name` registered, do so manually with
`app.register_type::<Name>()`.
- References to `TaskPoolPlugin` and associated types will need to
import it from `bevy_app` instead of `bevy_core`
- References to `FrameCountPlugin` and associated types will need to
import it from `bevy_diagnostic` instead of `bevy_core`
## Notes
This strategy was agreed upon by Cart and several other members in
[Discord](https://discord.com/channels/691052431525675048/692572690833473578/1319137218312278077).
# Objective
Simplify the code by using `macro_rules` instead of a proc macro where
possible.
## Solution
Replace `impl_param_set` proc macro with a `macro_rules` macro.
# Objective
- Remove `derive_more`'s error derivation and replace it with
`thiserror`
## Solution
- Added `derive_more`'s `error` feature to `deny.toml` to prevent it
sneaking back in.
- Reverted to `thiserror` error derivation
## Notes
Merge conflicts were too numerous to revert the individual changes, so
this reversion was done manually. Please scrutinise carefully during
review.
# Objective
Fixes#15941
## Solution
Created https://crates.io/crates/variadics_please and moved the code
there; updating references
`bevy_utils/macros` is deleted.
## Testing
cargo check
## Migration Guide
Use `variadics_please::{all_tuples, all_tuples_with_size}` instead of
`bevy::utils::{all_tuples, all_tuples_with_size}`.
# Objective
- Fixes#16363
- Ensure that someone using minimum version doesn't get the bugs that
were fixed in the 23.0.1 patch
## Solution
- Use wgpu 23.0.1
Alternative to #16450
# Objective
detailed_trace! in its current form does not work (and breaks CI)
## Solution
Fix detailed_trace by checking for the feature properly, adding it to
the correct crates, and removing it from the incorrect crates
# Objective
This is a follow-up to #15650. While the core `Image` stuff moved from
`bevy_render` to `bevy_image`, the `ImageLoader` and the
`CompressedImageSaver` remained in `bevy_render`.
## Solution
I moved `ImageLoader` and `CompressedImageSaver` to `bevy_image` and
re-exported everything out from `bevy_render`. The second step isn't
strictly necessary, but `bevy_render` is already doing this for all the
other `bevy_image` types, so I kept it the same for consistency.
Unfortunately I had to give `ImageLoader` a constructor so I can keep
the `RenderDevice` stuff in `bevy_render`.
## Testing
It compiles!
## Migration Guide
- `ImageLoader` can no longer be initialized directly through
`init_asset_loader`. Now you must use
`app.register_asset_loader(ImageLoader::new(supported_compressed_formats))`
(check out the implementation of `bevy_render::ImagePlugin`). This only
affects you if you are initializing the loader manually and does not
affect users of `bevy_render::ImagePlugin`.
## Followup work
- We should be able to move most of the `ImagePlugin` to `bevy_image`.
This would likely require an `ImagePlugin` and a `RenderImagePlugin` or
something though.
# Objective
Fixes#15515
## Solution
I went for the simplest solution because "format" in
`shader_format_spirv` didn't sound directly related.
## Testing
The command `cargo b -p bevy --no-default-features -F
spirv_shader_passthrough,x11` failed before, but works now.
# Objective
Bevy supports feature gates for each format it supports, but several
formats that it loads via the `image` crate do not have feature gates.
Additionally, the QOI format is supported by the `image` crate and
wasn't available at all. This fixes that.
## Solution
The following feature gates are added:
* `avif`
* `ff` (Farbfeld)
* `gif`
* `ico`
* `qoi`
* `tiff`
None of these formats are enabled by default, despite the fact that all
these formats appeared to be enabled by default before. Since
`default-features` was disabled for the `image` crate, it's likely that
using any of these formats would have errored by default before this
change, although this probably needs additional testing.
## Testing
The changes seemed minimal enough that a compile test would be
sufficient.
## Migration guide
Image formats that previously weren't feature-gated are now
feature-gated, meaning they will have to be enabled if you use them:
* `avif`
* `ff` (Farbfeld)
* `gif`
* `ico`
* `tiff`
Additionally, the `qoi` feature has been added to support loading QOI
format images.
Previously, these formats appeared in the enum by default, but weren't
actually enabled via the `image` crate, potentially resulting in weird
bugs. Now, you should be able to add these features to your projects to
support them properly.
# Objective
- `bevy_render` should not depend on `bevy_winit`
- Fixes#15565
## Solution
- `bevy_render` no longer depends on `bevy_winit`
- The following is behind the `custom_cursor` feature
- Move custom cursor code from `bevy_render` to `bevy_winit` behind the
`custom_cursor` feature
- `bevy_winit` now depends on `bevy_render` (for `Image` and
`TextureFormat`)
- `bevy_winit` now depends on `bevy_asset` (for `Assets`, `Handle` and
`AssetId`)
- `bevy_winit` now depends on `bytemuck` (already in tree)
- Custom cursor code in `bevy_winit` reworked to use `AssetId` (other
than that it is taken over 1:1)
- Rework `bevy_winit` custom cursor interface visibility now that the
logic is all contained in `bevy_winit`
## Testing
- I ran the screenshot and window_settings examples
- Tested on linux wayland so far
---
## Migration Guide
`CursorIcon` and `CustomCursor` previously provided by
`bevy::render::view::cursor` is now available from `bevy::winit`.
A new feature `custom_cursor` enables this functionality (default
feature).
# Objective
- bevy_render is gargantuan
## Solution
- Split out bevy_mesh
## Testing
- Ran some examples, everything looks fine
## Migration Guide
`bevy_render::mesh::morph::inherit_weights` is now
`bevy_render::mesh::inherit_weights`
if you were using `Mesh::compute_aabb`, you will need to `use
bevy_render::mesh::MeshAabb;` now
---------
Co-authored-by: Joona Aalto <jondolf.dev@gmail.com>
# Objective
- We use a feature introduced in async-channel 2.3.0, `force_send`
- Existing project fail to compile as they have a lock file on the 2.2.X
## Solution
- Bump async-channel
# Objective
Updating ``glam`` to 0.29, ``encase`` to 0.10.
## Solution
Update the necessary ``Cargo.toml`` files.
## Testing
Ran ``cargo run -p ci`` on Windows; no issues came up.
---------
Co-authored-by: aecsocket <aecsocket@tutanota.com>
**Note:** This is an adoption of @Shfty 's adoption (#8131) of #3996!
All I've done is updated the branch and run the docs CI.
> **Note:** This is an adoption of #3996, originally authored by
@molikto
>
> # Objective
> Allow use of `wgpu::Features::SPIRV_SHADER_PASSTHROUGH` and the
corresponding `wgpu::Device::create_shader_module_spirv` for SPIR-V
shader assets.
>
> This enables use-cases where naga is not sufficient to load a given
(valid) SPIR-V module, i.e. cases where naga lacks support for a given
SPIR-V feature employed by a third-party codegen backend like
`rust-gpu`.
>
> ## Solution
> * Reimplemented the changes from [Spirv shader
bypass #3996](https://github.com/bevyengine/bevy/pull/3996), on account
of the original branch having been deleted.
> * Documented the new `spirv_shader_passthrough` feature flag with the
appropriate platform support context from [wgpu's
documentation](https://docs.rs/wgpu/latest/wgpu/struct.Features.html#associatedconstant.SPIRV_SHADER_PASSTHROUGH).
>
> ## Changelog
> * Adds a `spirv_shader_passthrough` feature flag to the following
crates:
>
> * `bevy`
> * `bevy_internal`
> * `bevy_render`
> * Extends `RenderDevice::create_shader_module` with a conditional call
to `wgpu::Device::create_shader_module_spirv` if
`spirv_shader_passthrough` is enabled and
`wgpu::Features::SPIRV_SHADER_PASSTHROUGH` is present for the current
platform.
> * Documents the relevant `wgpu` platform support in
`docs/cargo_features.md`
---------
Co-authored-by: Josh Palmer <1253239+Shfty@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Remove the `wgpu_trace` feature while still making it easy/possible to
record wgpu traces for debugging.
- Close#14725.
- Get a taste of the bevy codebase. :P
## Solution
This PR performs the above objective by removing the `wgpu_trace`
feature from all `Cargo.toml` files.
However, wgpu traces are still useful for debugging - but to record
them, you need to pass in a directory path to store the traces in. To
avoid forcing users into manually creating the renderer,
`bevy_render::settings::WgpuSettings` now has a `trace_path` field, so
that all of Bevy's automatic initialization can happen while still
allowing for tracing.
## Testing
- Did you test these changes? If so, how?
- I have tested these changes, but only via running `cargo run -p ci`. I
am hoping the Github Actions workflows will catch anything I missed.
- Are there any parts that need more testing?
- I do not believe so.
- How can other people (reviewers) test your changes? Is there anything
specific they need to know?
- If you want to test these changes, I have updated the debugging guide
(`docs/debugging.md`) section on WGPU Tracing.
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
- I ran the above command on a Windows 10 64-bit (x64) machine, using
the `stable-x86_64-pc-windows-msvc` toolchain. I do not have anything
set up for other platforms or targets (though I can't imagine this needs
testing on other platforms).
---
## Migration Guide
1. The `bevy/wgpu_trace`, `bevy_render/wgpu_trace`, and
`bevy_internal/wgpu_trace` features no longer exist. Remove them from
your `Cargo.toml`, CI, tooling, and what-not.
2. Follow the instructions in the updated `docs/debugging.md` file in
the repository, under the WGPU Tracing section.
Because of the changes made, you can now generate traces to any path,
rather than the hardcoded `%WorkspaceRoot%/wgpu_trace` (where
`%WorkspaceRoot%` is... the root of your crate's workspace) folder.
(If WGPU hasn't restored tracing functionality...) Do note that WGPU has
not yet restored tracing functionality. However, once it does, the above
should be sufficient to generate new traces.
---------
Co-authored-by: TrialDragon <31419708+TrialDragon@users.noreply.github.com>
Upgrading to WGPU 22.
Needs `naga_oil` to upgrade first, I've got a fork that compiles but
fails tests, so until that's fixed and the crate is officially
updated/released this will be blocked.
---------
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
# Objective
- Add custom images as cursors
- Fixes#9557
## Solution
- Change cursor type to accommodate both native and image cursors
- I don't really like this solution because I couldn't use
`Handle<Image>` directly. I would need to import `bevy_assets` and that
causes a circular dependency. Alternatively we could use winit's
`CustomCursor` smart pointers, but that seems hard because the event
loop is needed to create those and is not easily accessable for users.
So now I need to copy around rgba buffers which is sad.
- I use a cache because especially on the web creating cursor images is
really slow
- Sorry to #14196 for yoinking, I just wanted to make a quick solution
for myself and thought that I should probably share it too.
Update:
- Now uses `Handle<Image>`, reads rgba data in `bevy_render` and uses
resources to send the data to `bevy_winit`, where the final cursors are
created.
## Testing
- Added example which works fine at least on Linux Wayland (winit side
has been tested with all platforms).
- I haven't tested if the url cursor works.
## Migration Guide
- `CursorIcon` is no longer a field in `Window`, but a separate
component can be inserted to a window entity. It has been changed to an
enum that can hold custom images in addition to system icons.
- `Cursor` is renamed to `CursorOptions` and `cursor` field of `Window`
is renamed to `cursor_options`
- `CursorIcon` is renamed to `SystemCursorIcon`
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Jan Hohenheim <jan@hohenheim.ch>
Basically it's https://github.com/bevyengine/bevy/pull/13792 with the
bumped versions of `encase` and `hexasphere`.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- Fix issue #2611
## Solution
- Add `--generate-link-to-definition` to all the `rustdoc-args` arrays
in the `Cargo.toml`s (for docs.rs)
- Add `--generate-link-to-definition` to the `RUSTDOCFLAGS` environment
variable in the docs workflow (for dev-docs.bevyengine.org)
- Document all the workspace crates in the docs workflow (needed because
otherwise only the source code of the `bevy` package will be included,
making the argument useless)
- I think this also fixes#3662, since it fixes the bug on
dev-docs.bevyengine.org, while on docs.rs it has been fixed for a while
on their side.
---
## Changelog
- The source code viewer on docs.rs now includes links to the
definitions.
# Objective
- `bevy_render` depends on `image 0.25` but uses `image::ImageReader`
which was added only in `image 0.25.2`
- users that have `image 0.25` in their `Cargo.lock` and update to the
latest `bevy_render` may thus get a compilation due to this (at least I
did)
## Solution
- Properly set the correct minimum version of `image` that `bevy_render`
depends on.
This commit uses the [`offset-allocator`] crate to combine vertex and
index arrays from different meshes into single buffers. Since the
primary source of `wgpu` overhead is from validation and synchronization
when switching buffers, this significantly improves Bevy's rendering
performance on many scenes.
This patch is a more flexible version of #13218, which also used slabs.
Unlike #13218, which used slabs of a fixed size, this commit implements
slabs that start small and can grow. In addition to reducing memory
usage, supporting slab growth reduces the number of vertex and index
buffer switches that need to happen during rendering, leading to
improved performance. To prevent pathological fragmentation behavior,
slabs are capped to a maximum size, and mesh arrays that are too large
get their own dedicated slabs.
As an additional improvement over #13218, this commit allows the
application to customize all allocator heuristics. The
`MeshAllocatorSettings` resource contains values that adjust the minimum
and maximum slab sizes, the cutoff point at which meshes get their own
dedicated slabs, and the rate at which slabs grow. Hopefully-sensible
defaults have been chosen for each value.
Unfortunately, WebGL 2 doesn't support the *base vertex* feature, which
is necessary to pack vertex arrays from different meshes into the same
buffer. `wgpu` represents this restriction as the downlevel flag
`BASE_VERTEX`. This patch detects that bit and ensures that all vertex
buffers get dedicated slabs on that platform. Even on WebGL 2, though,
we can combine all *index* arrays into single buffers to reduce buffer
changes, and we do so.
The following measurements are on Bistro:
Overall frame time improves from 8.74 ms to 5.53 ms (1.58x speedup):

Render system time improves from 6.57 ms to 3.54 ms (1.86x speedup):

Opaque pass time improves from 4.64 ms to 2.33 ms (1.99x speedup):

## Migration Guide
### Changed
* Vertex and index buffers for meshes may now be packed alongside other
buffers, for performance.
* `GpuMesh` has been renamed to `RenderMesh`, to reflect the fact that
it no longer directly stores handles to GPU objects.
* Because meshes no longer have their own vertex and index buffers, the
responsibility for the buffers has moved from `GpuMesh` (now called
`RenderMesh`) to the `MeshAllocator` resource. To access the vertex data
for a mesh, use `MeshAllocator::mesh_vertex_slice`. To access the index
data for a mesh, use `MeshAllocator::mesh_index_slice`.
[`offset-allocator`]: https://github.com/pcwalton/offset-allocator
Bump version after release
This PR has been auto-generated
Co-authored-by: Bevy Auto Releaser <41898282+github-actions[bot]@users.noreply.github.com>
Co-authored-by: François Mockers <mockersf@gmail.com>
Currently blocked on https://github.com/gfx-rs/wgpu/issues/5774
# Objective
Update to wgpu 0.20
## Solution
Update to wgpu 0.20 and naga_oil 0.14.
## Testing
Tested a few different examples on linux (vulkan, webgl2, webgpu) and
windows (dx12 + vulkan) and they worked.
---
## Changelog
- Updated to wgpu 0.20. Note that we don't currently support wgpu's new
pipeline overridable constants, as they don't work on web currently and
need some more changes to naga_oil (and are somewhat redundant with
naga_oil's shader defs). See wgpu's changelog for more
https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v0200-2024-04-28
## Migration Guide
TODO
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: François Mockers <mockersf@gmail.com>
Updates the requirements on
[ruzstd](https://github.com/KillingSpark/zstd-rs) to permit the latest
version.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/releases">ruzstd's
releases</a>.</em></p>
<blockquote>
<h2>Optimizations, Documentation and slight API changes</h2>
<ul>
<li>Few slight performance optimizations</li>
<li>Big documentation contribution</li>
<li><code>StreamingDecoder</code> now has API to get to the contained
<code>impl Read</code></li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/KillingSpark/zstd-rs/blob/master/Changelog.md">ruzstd's
changelog</a>.</em></p>
<blockquote>
<h1>After 0.7.0</h1>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="101df3eac0"><code>101df3e</code></a>
bump version to 0.7.0</li>
<li><a
href="c7ad34bc1c"><code>c7ad34b</code></a>
fix doc on reverse bitreader</li>
<li><a
href="cd73dffe15"><code>cd73dff</code></a>
changelog</li>
<li><a
href="944b391c30"><code>944b391</code></a>
don't return errors on too large requests on a reversed bitreader (<a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/58">#58</a>)</li>
<li><a
href="53e7b1a600"><code>53e7b1a</code></a>
fix doc comments for clippy</li>
<li><a
href="16fee8cd45"><code>16fee8c</code></a>
Implement accessors for inner reader on StreamDecoder (<a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/62">#62</a>)</li>
<li><a
href="0b9607324e"><code>0b96073</code></a>
Add documentation throughout the codebase. (<a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/61">#61</a>)</li>
<li><a
href="5265c12c8c"><code>5265c12</code></a>
remove derive_more (<a
href="https://redirect.github.com/KillingSpark/zstd-rs/issues/60">#60</a>)</li>
<li><a
href="88f7a41677"><code>88f7a41</code></a>
use core instead of std</li>
<li><a
href="2ee37fdf5b"><code>2ee37fd</code></a>
optimize the copying done in the ringbuffer</li>
<li>Additional commits viewable in <a
href="https://github.com/KillingSpark/zstd-rs/compare/v0.6.0...v0.7.0">compare
view</a></li>
</ul>
</details>
<br />
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
# Objective
Remove the limit of `RenderLayer` by using a growable mask using
`SmallVec`.
Changes adopted from @UkoeHB's initial PR here
https://github.com/bevyengine/bevy/pull/12502 that contained additional
changes related to propagating render layers.
Changes
## Solution
The main thing needed to unblock this is removing `RenderLayers` from
our shader code. This primarily affects `DirectionalLight`. We are now
computing a `skip` field on the CPU that is then used to skip the light
in the shader.
## Testing
Checked a variety of examples and did a quick benchmark on `many_cubes`.
There were some existing problems identified during the development of
the original pr (see:
https://discord.com/channels/691052431525675048/1220477928605749340/1221190112939872347).
This PR shouldn't change any existing behavior besides removing the
layer limit (sans the comment in migration about `all` layers no longer
being possible).
---
## Changelog
Removed the limit on `RenderLayers` by using a growable bitset that only
allocates when layers greater than 64 are used.
## Migration Guide
- `RenderLayers::all()` no longer exists. Entities expecting to be
visible on all layers, e.g. lights, should compute the active layers
that are in use.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
Fixes#12966
## Solution
Renaming multi_threaded feature to match snake case
## Migration Guide
Bevy feature multi-threaded should be refered to multi_threaded from now
on.
# Objective
- Update glam version requirement to latest version.
## Solution
- Updated `glam` version requirement from 0.25 to 0.27.
- Updated `encase` and `encase_derive_impl` version requirement from 0.7
to 0.8.
- Updated `hexasphere` version requirement from 10.0 to 12.0.
- Breaking changes from glam changelog:
- [0.26.0] Minimum Supported Rust Version bumped to 1.68.2 for impl
From<bool> for {f32,f64} support.
- [0.27.0] Changed implementation of vector fract method to match the
Rust implementation instead of the GLSL implementation, that is self -
self.trunc() instead of self - self.floor().
---
## Migration Guide
- When using `glam` exports, keep in mind that `vector` `fract()` method
now matches Rust implementation (that is `self - self.trunc()` instead
of `self - self.floor()`). If you want to use the GLSL implementation
you should now use `fract_gl()`.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Minimize the number of dependencies low in the tree.
## Solution
* Remove the dependency on rustc-hash in bevy_ecs (not used) and
bevy_macro_utils (only used in one spot).
* Deduplicate the dependency on `sha1_smol` with the existing blake3
dependency already being used for bevy_asset.
* Remove the unused `ron` dependency on `bevy_app`
* Make the `serde` dependency for `bevy_ecs` optional. It's only used
for serializing Entity.
* Change the `wgpu` dependency to `wgpu-types`, and make it optional for
`bevy_color`.
* Remove the unused `thread-local` dependency on `bevy_render`.
* Make multiple dependencies for `bevy_tasks` optional and enabled only
when running with the `multi-threaded` feature. Preferably they'd be
disabled all the time on wasm, but I couldn't find a clean way to do
this.
---
## Changelog
TODO
## Migration Guide
TODO
Fixed a bug where skybox ddsfile would crash from wgpu while trying to
read past the file buffer.
Added a unit-test to prevent regression.
Bumped ddsfile dependency version to 0.5.2
# Objective
Prevents a crash when loading dds skybox.
## Solution
ddsfile already automatically sets array layers to be 6 for skyboxes.
Removed bevy's extra *= 6 multiplication.
---
This is a copy of
[#12598](https://github.com/bevyengine/bevy/pull/12598) ... I made that
one off of main and wasn't able to make more pull requests without
making a new branch.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
Since BufferVec was first introduced, `bytemuck` has added additional
traits with fewer restrictions than `Pod`. Within BufferVec, we only
rely on the constraints of `bytemuck::cast_slice` to a `u8` slice, which
now only requires `T: NoUninit` which is a strict superset of `Pod`
types.
## Solution
Change out the `Pod` generic type constraint with `NoUninit`. Also
taking the opportunity to substitute `cast_slice` with
`must_cast_slice`, which avoids a runtime panic in place of a compile
time failure if `T` cannot be used.
---
## Changelog
Changed: `BufferVec` now supports working with types containing
`NoUninit` but not `Pod` members.
Changed: `BufferVec` will now fail to compile if used with a type that
cannot be safely read from. Most notably, this includes ZSTs, which
would previously always panic at runtime.
# Objective
- Closes https://github.com/bevyengine/bevy/pull/12415
## Solution
- Refactored code that was changed/deprecated in `image` 0.25.
- Please review this PR carefully since I'm just making the changes
without any context or deep knowledge of the module.
---------
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Co-authored-by: James Liu <contact@jamessliu.com>
# Objective
This gets Bevy building on Wasm when the `atomics` flag is enabled. This
does not yet multithread Bevy itself, but it allows Bevy users to use a
crate like `wasm_thread` to spawn their own threads and manually
parallelize work. This is a first step towards resolving #4078 . Also
fixes#9304.
This provides a foothold so that Bevy contributors can begin to think
about multithreaded Wasm's constraints and Bevy can work towards changes
to get the engine itself multithreaded.
Some flags need to be set on the Rust compiler when compiling for Wasm
multithreading. Here's what my build script looks like, with the correct
flags set, to test out Bevy examples on web:
```bash
set -e
RUSTFLAGS='-C target-feature=+atomics,+bulk-memory,+mutable-globals' \
cargo build --example breakout --target wasm32-unknown-unknown -Z build-std=std,panic_abort --release
wasm-bindgen --out-name wasm_example \
--out-dir examples/wasm/target \
--target web target/wasm32-unknown-unknown/release/examples/breakout.wasm
devserver --header Cross-Origin-Opener-Policy='same-origin' --header Cross-Origin-Embedder-Policy='require-corp' --path examples/wasm
```
A few notes:
1. `cpal` crashes immediately when the `atomics` flag is set. That is
patched in https://github.com/RustAudio/cpal/pull/837, but not yet in
the latest crates.io release.
That can be temporarily worked around by patching Cpal like so:
```toml
[patch.crates-io]
cpal = { git = "https://github.com/RustAudio/cpal" }
```
2. When testing out `wasm_thread` you need to enable the `es_modules`
feature.
## Solution
The largest obstacle to compiling Bevy with `atomics` on web is that
`wgpu` types are _not_ Send and Sync. Longer term Bevy will need an
approach to handle that, but in the near term Bevy is already configured
to be single-threaded on web.
Therefor it is enough to wrap `wgpu` types in a
`send_wrapper::SendWrapper` that _is_ Send / Sync, but panics if
accessed off the `wgpu` thread.
---
## Changelog
- `wgpu` types that are not `Send` are wrapped in
`send_wrapper::SendWrapper` on Wasm + 'atomics'
- CommandBuffers are not generated in parallel on Wasm + 'atomics'
## Questions
- Bevy should probably add CI checks to make sure this doesn't regress.
Should that go in this PR or a separate PR? **Edit:** Added checks to
build Wasm with atomics
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: daxpedda <daxpedda@gmail.com>
Co-authored-by: François <francois.mockers@vleue.com>
# Objective
- Add serialize feature to bevy_color
- "Fixes #12527".
## Solution
- Added feature for serialization
---
## Changelog
- Serde serialization is now optional, with flag 'serialize'
## Migration Guide
- If user wants color data structures to be serializable, then
application needs to be build with flag 'serialize'