# Objective
Fixes#9367.
Yet another follow-up to #16547.
These traits were initially based on `Borrow<Entity>` because that trait
was what they were replacing, and it felt close enough in meaning.
However, they ultimately don't quite match: `borrow` always returns
references, whereas `EntityBorrow` always returns a plain `Entity`.
Additionally, `EntityBorrow` can imply that we are borrowing an `Entity`
from the ECS, which is not what it does.
Due to its safety contract, `TrustedEntityBorrow` is important an
important and widely used trait for `EntitySet` functionality.
In contrast, the safe `EntityBorrow` does not see much use, because even
outside of `EntitySet`-related functionality, it is a better idea to
accept `TrustedEntityBorrow` over `EntityBorrow`.
Furthermore, as #9367 points out, abstracting over returning `Entity`
from pointers/structs that contain it can skip some ergonomic friction.
On top of that, there are aspects of #18319 and #18408 that are relevant
to naming:
We've run into the issue that relying on a type default can switch
generic order. This is livable in some contexts, but unacceptable in
others.
To remedy that, we'd need to switch to a type alias approach:
The "defaulted" `Entity` case becomes a
`UniqueEntity*`/`Entity*Map`/`Entity*Set` alias, and the base type
receives a more general name. `TrustedEntityBorrow` does not mesh
clearly with sensible base type names.
## Solution
Replace any `EntityBorrow` bounds with `TrustedEntityBorrow`.
+
Rename them as such:
`EntityBorrow` -> `ContainsEntity`
`TrustedEntityBorrow` -> `EntityEquivalent`
For `EntityBorrow` we produce a change in meaning; We designate it for
types that aren't necessarily strict wrappers around `Entity` or some
pointer to `Entity`, but rather any of the myriad of types that contain
a single associated `Entity`.
This pattern can already be seen in the common `entity`/`id` methods
across the engine.
We do not mean for `ContainsEntity` to be a trait that abstracts input
API (like how `AsRef<T>` is often used, f.e.), because eliding
`entity()` would be too implicit in the general case.
We prefix "Contains" to match the intuition of a struct with an `Entity`
field, like some contain a `length` or `capacity`.
It gives the impression of structure, which avoids the implication of a
relationship to the `ECS`.
`HasEntity` f.e. could be interpreted as "a currently live entity",
As an input trait for APIs like #9367 envisioned, `TrustedEntityBorrow`
is a better fit, because it *does* restrict itself to strict wrappers
and pointers. Which is why we replace any
`EntityBorrow`/`ContainsEntity` bounds with
`TrustedEntityBorrow`/`EntityEquivalent`.
Here, the name `EntityEquivalent` is a lot closer to its actual meaning,
which is "A type that is both equivalent to an `Entity`, and forms the
same total order when compared".
Prior art for this is the
[`Equivalent`](https://docs.rs/hashbrown/latest/hashbrown/trait.Equivalent.html)
trait in `hashbrown`, which utilizes both `Borrow` and `Eq` for its one
blanket impl!
Given that we lose the `Borrow` moniker, and `Equivalent` can carry
various meanings, we expand on the safety comment of `EntityEquivalent`
somewhat. That should help prevent the confusion we saw in
[#18408](https://github.com/bevyengine/bevy/pull/18408#issuecomment-2742094176).
The new name meshes a lot better with the type aliasing approach in
#18408, by aligning with the base name `EntityEquivalentHashMap`.
For a consistent scheme among all set types, we can use this scheme for
the `UniqueEntity*` wrapper types as well!
This allows us to undo the switched generic order that was introduced to
`UniqueEntityArray` by its `Entity` default.
Even without the type aliases, I think these renames are worth doing!
## Migration Guide
Any use of `EntityBorrow` becomes `ContainsEntity`.
Any use of `TrustedEntityBorrow` becomes `EntityEquivalent`.
# Objective
Unlike for their helper typers, the import paths for
`unique_array::UniqueEntityArray`, `unique_slice::UniqueEntitySlice`,
`unique_vec::UniqueEntityVec`, `hash_set::EntityHashSet`,
`hash_map::EntityHashMap`, `index_set::EntityIndexSet`,
`index_map::EntityIndexMap` are quite redundant.
When looking at the structure of `hashbrown`, we can also see that while
both `HashSet` and `HashMap` have their own modules, the main types
themselves are re-exported to the crate level.
## Solution
Re-export the types in their shared `entity` parent module, and simplify
the imports where they're used.
# Objective
Fixes#18515
After the recent changes to system param validation, the panic message
for a missing resource is currently:
```
Encountered an error in system `missing_resource_error::res_system`: SystemParamValidationError { skipped: false }
```
Add the parameter type name and a descriptive message, improving the
panic message to:
```
Encountered an error in system `missing_resource_error::res_system`: SystemParamValidationError { skipped: false, message: "Resource does not exist", param: "bevy_ecs::change_detection::Res<missing_resource_error::MissingResource>" }
```
## Solution
Add fields to `SystemParamValidationError` for error context. Include
the `type_name` of the param and a message.
Store them as `Cow<'static, str>` and only format them into a friendly
string in the `Display` impl. This lets us create errors using a
`&'static str` with no allocation or formatting, while still supporting
runtime `String` values if necessary.
Add a unit test that verifies the panic message.
## Future Work
If we change the default error handling to use `Display` instead of
`Debug`, and to use `ShortName` for the system name, the panic message
could be further improved to:
```
Encountered an error in system `res_system`: Parameter `Res<MissingResource>` failed validation: Resource does not exist
```
However, `BevyError` currently includes the backtrace in `Debug` but not
`Display`, and I didn't want to try to change that in this PR.
# Objective
This fixes `NonMesh` draw commands not receiving render-world entities
since
- https://github.com/bevyengine/bevy/pull/17698
This unbreaks item queries for queued non-mesh entities:
```rust
struct MyDrawCommand {
type ItemQuery = Read<DynamicUniformIndex<SomeUniform>>;
// ...
}
```
### Solution
Pass render entity to `NonMesh` draw commands instead of
`Entity::PLACEHOLDER`. This PR also introduces sorting of the `NonMesh`
bin keys like other types, which I assume is the intended behavior.
@pcwalton
## Testing
- Tested on a local project that extensively uses `NonMesh` items.
# Objective
- feature `shader_format_wesl` doesn't compile in Wasm
- once fixed, example `shader_material_wesl` doesn't work in WebGL2
## Solution
- remove special path handling when loading shaders. this seems like a
way to escape the asset folder which we don't want to allow, and can't
compile on android or wasm, and can't work on iOS (filesystem is rooted
there)
- pad material so that it's 16 bits. I couldn't get conditional
compilation to work in wesl for type declaration, it fails to parse
- the shader renders the color `(0.0, 0.0, 0.0, 0.0)` when it's not a
polka dot. this renders as black on WebGPU/metal/..., and white on
WebGL2. change it to `(0.0, 0.0, 0.0, 1.0)` so that it's black
everywhere
* `submit_graph_commands` was incorrectly timing the command buffer
generation tasks as well, and not only the queue submission. Moved the
span to fix that.
* Added a new `command_buffer_generation_tasks` span as a parent for all
the individual command buffer generation tasks that don't run as part of
the Core3d span.

# Objective
Fixes https://github.com/bevyengine/bevy/issues/16586.
## Solution
- Free meshes before allocating new ones (so hopefully the existing
allocation is used, but it's not guaranteed since it might end up
getting used by a smaller mesh first).
- Keep track of modified render assets, and have the mesh allocator free
their allocations.
- Cleaned up some render asset code to make it more understandable,
since it took me several minutes to reverse engineer/remember how it was
supposed to work.
Long term we'll probably want to explicitly reusing allocations for
modified meshes that haven't grown in size, or do delta uploads using a
compute shader or something, but this is an easy fix for the near term.
## Testing
Ran the example provided in the issue. No crash after a few minutes, and
memory usage remains steady.
# Objective
Make it easier to short-circuit system parameter validation.
Simplify the API surface by combining `ValidationOutcome` with
`SystemParamValidationError`.
## Solution
Replace `ValidationOutcome` with `Result<(),
SystemParamValidationError>`. Move the docs from `ValidationOutcome` to
`SystemParamValidationError`.
Add a `skipped` field to `SystemParamValidationError` to distinguish the
`Skipped` and `Invalid` variants.
Use the `?` operator to short-circuit validation in tuples of system
params.
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/17891
- Cherry-picked from https://github.com/bevyengine/bevy/pull/18411
## Solution
The `name` argument could either be made permanent (by removing the
`#[cfg(...)]` condition) or eliminated entirely. I opted to remove it,
as debugging a specific DDS texture edge case in GLTF files doesn't seem
necessary, and there isn't any other foreseeable need to have it.
## Migration Guide
- `Image::from_buffer()` no longer has a `name` argument that's only
present in debug builds when the `"dds"` feature is enabled. If you
happen to pass a name, remove it.
# Objective
When introduced, `Single` was intended to simply be silently skipped,
allowing for graceful and efficient handling of systems during invalid
game states (such as when the player is dead).
However, this also caused missing resources to *also* be silently
skipped, leading to confusing and very hard to debug failures. In
0.15.1, this behavior was reverted to a panic, making missing resources
easier to debug, but largely making `Single` (and `Populated`)
worthless, as they would panic during expected game states.
Ultimately, the consensus is that this behavior should differ on a
per-system-param basis. However, there was no sensible way to *do* that
before this PR.
## Solution
Swap `SystemParam::validate_param` from a `bool` to:
```rust
/// The outcome of system / system param validation,
/// used by system executors to determine what to do with a system.
pub enum ValidationOutcome {
/// All system parameters were validated successfully and the system can be run.
Valid,
/// At least one system parameter failed validation, and an error must be handled.
/// By default, this will result in1 a panic. See [crate::error] for more information.
///
/// This is the default behavior, and is suitable for system params that should *always* be valid,
/// either because sensible fallback behavior exists (like [`Query`] or because
/// failures in validation should be considered a bug in the user's logic that must be immediately addressed (like [`Res`]).
Invalid,
/// At least one system parameter failed validation, but the system should be skipped due to [`ValidationBehavior::Skip`].
/// This is suitable for system params that are intended to only operate in certain application states, such as [`Single`].
Skipped,
}
```
Then, inside of each `SystemParam` implementation, return either Valid,
Invalid or Skipped.
Currently, only `Single`, `Option<Single>` and `Populated` use the
`Skipped` behavior. Other params (like resources) retain their current
failing
## Testing
Messed around with the fallible_params example. Added a pair of tests:
one for panicking when resources are missing, and another for properly
skipping `Single` and `Populated` system params.
## To do
- [x] get https://github.com/bevyengine/bevy/pull/18454 merged
- [x] fix the todo!() in the macro-powered tuple implementation (please
help 🥺)
- [x] test
- [x] write a migration guide
- [x] update the example comments
## Migration Guide
Various system and system parameter validation methods
(`SystemParam::validate_param`, `System::validate_param` and
`System::validate_param_unsafe`) now return and accept a
`ValidationOutcome` enum, rather than a `bool`. The previous `true`
values map to `ValidationOutcome::Valid`, while `false` maps to
`ValidationOutcome::Invalid`.
However, if you wrote a custom schedule executor, you should now respect
the new `ValidationOutcome::Skipped` parameter, skipping any systems
whose validation was skipped. By contrast, `ValidationOutcome::Invalid`
systems should also be skipped, but you should call the
`default_error_handler` on them first, which by default will result in a
panic.
If you are implementing a custom `SystemParam`, you should consider
whether failing system param validation is an error or an expected
state, and choose between `Invalid` and `Skipped` accordingly. In Bevy
itself, `Single` and `Populated` now once again skip the system when
their conditions are not met. This is the 0.15.0 behavior, but stands in
contrast to the 0.15.1 behavior, where they would panic.
---------
Co-authored-by: MiniaczQ <xnetroidpl@gmail.com>
Co-authored-by: Dmytro Banin <banind@cs.washington.edu>
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
# Objective
- This variable is unused and never populated. I searched for the
literal text of the const and got no hits.
## Solution
- Delete it!
## Testing
- None.
# Objective
There are two related problems here:
1. Users should be able to change the fallback behavior of *all*
ECS-based errors in their application by setting the
`GLOBAL_ERROR_HANDLER`. See #18351 for earlier work in this vein.
2. The existing solution (#15500) for customizing this behavior is high
on boilerplate, not global and adds a great deal of complexity.
The consensus is that the default behavior when a parameter fails
validation should be set based on the kind of system parameter in
question: `Single` / `Populated` should silently skip the system, but
`Res` should panic. Setting this behavior at the system level is a
bandaid that makes getting to that ideal behavior more painful, and can
mask real failures (if a resource is missing but you've ignored a system
to make the Single stop panicking you're going to have a bad day).
## Solution
I've removed the existing `ParamWarnPolicy`-based configuration, and
wired up the `GLOBAL_ERROR_HANDLER`/`default_error_handler` to the
various schedule executors to properly plumb through errors .
Additionally, I've done a small cleanup pass on the corresponding
example.
## Testing
I've run the `fallible_params` example, with both the default and a
custom global error handler. The former panics (as expected), and the
latter spams the error console with warnings 🥲
## Questions for reviewers
1. Currently, failed system param validation will result in endless
console spam. Do you want me to implement a solution for warn_once-style
debouncing somehow?
2. Currently, the error reporting for failed system param validation is
very limited: all we get is that a system param failed validation and
the name of the system. Do you want me to implement improved error
reporting by bubbling up errors in this PR?
3. There is broad consensus that the default behavior for failed system
param validation should be set on a per-system param basis. Would you
like me to implement that in this PR?
My gut instinct is that we absolutely want to solve 2 and 3, but it will
be much easier to do that work (and review it) if we split the PRs
apart.
## Migration Guide
`ParamWarnPolicy` and the `WithParamWarnPolicy` have been removed
completely. Failures during system param validation are now handled via
the `GLOBAL_ERROR_HANDLER`: please see the `bevy_ecs::error` module docs
for more information.
---------
Co-authored-by: MiniaczQ <xnetroidpl@gmail.com>
# Objective
Create new `NonSendMarker` that does not depend on `NonSend`.
Required, in order to accomplish #17682. In that issue, we are trying to
replace `!Send` resources with `thread_local!` in order to unblock the
resources-as-components effort. However, when we remove all the `!Send`
resources from a system, that allows the system to run on a thread other
than the main thread, which is against the design of the system. So this
marker gives us the control to require a system to run on the main
thread without depending on `!Send` resources.
## Solution
Create a new `NonSendMarker` to replace the existing one that does not
depend on `NonSend`.
## Testing
Other than running tests, I ran a few examples:
- `window_resizing`
- `wireframe`
- `volumetric_fog` (looks so cool)
- `rotation`
- `button`
There is a Mac/iOS-specific change and I do not have a Mac or iOS device
to test it. I am doubtful that it would cause any problems for 2
reasons:
1. The change is the same as the non-wasm change which I did test
2. The Pixel Eagle tests run Mac tests
But it wouldn't hurt if someone wanted to spin up an example that
utilizes the `bevy_render` crate, which is where the Mac/iSO change was.
## Migration Guide
If `NonSendMarker` is being used from `bevy_app::prelude::*`, replace it
with `bevy_ecs::system::NonSendMarker` or use it from
`bevy_ecs::prelude::*`. In addition to that, `NonSendMarker` does not
need to be wrapped like so:
```rust
fn my_system(_non_send_marker: Option<NonSend<NonSendMarker>>) {
...
}
```
Instead, it can be used without any wrappers:
```rust
fn my_system(_non_send_marker: NonSendMarker) {
...
}
```
---------
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/18366 which seems to
have a similar underlying cause than the already closed (but not fixed)
https://github.com/bevyengine/bevy/issues/16185.
## Solution
For Windows with the AMD vulkan driver, there was already a hack to
force serial command encoding, which prevented these issues. The Linux
version of the AMD vulkan driver seems to have similar issues than its
Windows counterpart, so I extended the hack to also cover AMD on Linux.
I also removed the mention of `wgpu` since it was already outdated, and
doesn't seem to be relevant to the core issue (the AMD driver being
buggy).
## Testing
- Did you test these changes? If so, how?
- I ran the `3d_scene` example, which on `main` produced the flickering
shadows on Linux with the amdvlk driver, while it no longer does with
the workaround applied.
- Are there any parts that need more testing?
- Not sure.
- How can other people (reviewers) test your changes? Is there anything
specific they need to know?
- Requires a Linux system with an AMD card and the AMDVLK driver.
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
- My change should only affect Linux, where I did test it.
# Objective
WESL was broken on windows.
## Solution
- Upgrade to `wesl_rs` 1.2.
- Fix path handling on windows.
- Improve example for khronos demo this week.
# Objective
Now that #13432 has been merged, it's important we update our reflected
types to properly opt into this feature. If we do not, then this could
cause issues for users downstream who want to make use of
reflection-based cloning.
## Solution
This PR is broken into 4 commits:
1. Add `#[reflect(Clone)]` on all types marked `#[reflect(opaque)]` that
are also `Clone`. This is mandatory as these types would otherwise cause
the cloning operation to fail for any type that contains it at any
depth.
2. Update the reflection example to suggest adding `#[reflect(Clone)]`
on opaque types.
3. Add `#[reflect(clone)]` attributes on all fields marked
`#[reflect(ignore)]` that are also `Clone`. This prevents the ignored
field from causing the cloning operation to fail.
Note that some of the types that contain these fields are also `Clone`,
and thus can be marked `#[reflect(Clone)]`. This makes the
`#[reflect(clone)]` attribute redundant. However, I think it's safer to
keep it marked in the case that the `Clone` impl/derive is ever removed.
I'm open to removing them, though, if people disagree.
4. Finally, I added `#[reflect(Clone)]` on all types that are also
`Clone`. While not strictly necessary, it enables us to reduce the
generated output since we can just call `Clone::clone` directly instead
of calling `PartialReflect::reflect_clone` on each variant/field. It
also means we benefit from any optimizations or customizations made in
the `Clone` impl, including directly dereferencing `Copy` values and
increasing reference counters.
Along with that change I also took the liberty of adding any missing
registrations that I saw could be applied to the type as well, such as
`Default`, `PartialEq`, and `Hash`. There were hundreds of these to
edit, though, so it's possible I missed quite a few.
That last commit is **_massive_**. There were nearly 700 types to
update. So it's recommended to review the first three before moving onto
that last one.
Additionally, I can break the last commit off into its own PR or into
smaller PRs, but I figured this would be the easiest way of doing it
(and in a timely manner since I unfortunately don't have as much time as
I used to for code contributions).
## Testing
You can test locally with a `cargo check`:
```
cargo check --workspace --all-features
```
Extracted from my DLSS branch.
## Changelog
* Added `source_texture` and `destination_texture` to
`PostProcessWrite`, in addition to the existing texture views.
# Objective
In its existing form, the clamping that's done in `camera_system`
doesn't work well when the `physical_position` of the associated
viewport is nonzero. In such cases, it may produce invalid viewport
rectangles (i.e. not lying inside the render target), which may result
in crashes during the render pass.
The goal of this PR is to eliminate this possibility by making the
clamping behavior always result in a valid viewport rectangle when
possible.
## Solution
Incorporate the `physical_position` information into the clamping
behavior. In particular, always cut off enough so that it's contained in
the render target rather than clamping it to the same dimensions as the
target itself. In weirder situations, still try to produce a valid
viewport rectangle to avoid crashes.
## Testing
Tested these changes on my work branch where I encountered the crash.
# Objective
The `ViewportConversionError` error type does not implement `Error`,
making it incompatible with `BevyError`.
## Solution
Derive `Error` for `ViewportConversionError`.
I chose to use `thiserror` since it's already a dependency, but do let
me know if we should be preferring `derive_more`.
## Testing
You can test this by trying to compile the following:
```rust
let error: BevyError = ViewportConversionError::InvalidData.into();
```
# Objective
Prevents duplicate implementation between IntoSystemConfigs and
IntoSystemSetConfigs using a generic, adds a NodeType trait for more
config flexibility (opening the door to implement
https://github.com/bevyengine/bevy/issues/14195?).
## Solution
Followed writeup by @ItsDoot:
https://hackmd.io/@doot/rJeefFHc1x
Removes IntoSystemConfigs and IntoSystemSetConfigs, instead using
IntoNodeConfigs with generics.
## Testing
Pending
---
## Showcase
N/A
## Migration Guide
SystemSetConfigs -> NodeConfigs<InternedSystemSet>
SystemConfigs -> NodeConfigs<ScheduleSystem>
IntoSystemSetConfigs -> IntoNodeConfigs<InternedSystemSet, M>
IntoSystemConfigs -> IntoNodeConfigs<ScheduleSystem, M>
---------
Co-authored-by: Christian Hughes <9044780+ItsDoot@users.noreply.github.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
- #16883
- Improve the default behaviour of the exclusive fullscreen API.
## Solution
This PR changes the exclusive fullscreen window mode to require the type
`WindowMode::Fullscreen(MonitorSelection, VideoModeSelection)` and
removes `WindowMode::SizedFullscreen`. This API somewhat intentionally
more closely resembles Winit 0.31's upcoming fullscreen and video mode
API.
The new VideoModeSelection enum is specified as follows:
```rust
pub enum VideoModeSelection {
/// Uses the video mode that the monitor is already in.
Current,
/// Uses a given [`crate::monitor::VideoMode`]. A list of video modes supported by the monitor
/// is supplied by [`crate::monitor::Monitor::video_modes`].
Specific(VideoMode),
}
```
### Changing default behaviour
This might be contentious because it removes the previous behaviour of
`WindowMode::Fullscreen` which selected the highest resolution possible.
While the previous behaviour would be quite easy to re-implement as
additional options, or as an impl method on Monitor, I would argue that
this isn't an implementation that should be encouraged.
From the perspective of a Windows user, I prefer what the majority of
modern games do when entering fullscreen which is to preserve the OS's
current resolution settings, which allows exclusive fullscreen to be
entered faster, and to only have it change if I manually select it in
either the options of the game or the OS. The highest resolution
available is not necessarily what the user prefers.
I am open to changing this if I have just missed a good use case for it.
Likewise, the only functionality that `WindowMode::SizedFullscreen`
provided was that it selected the resolution closest to the current size
of the window so it was removed since this behaviour can be replicated
via the new `VideoModeSelection::Specific` if necessary.
## Out of scope
WindowResolution and scale factor act strangely in exclusive fullscreen,
this PR doesn't address it or regress it.
## Testing
- Tested on Windows 11 and macOS 12.7
- Linux untested
## Migration Guide
`WindowMode::SizedFullscreen(MonitorSelection)` and
`WindowMode::Fullscreen(MonitorSelection)` has become
`WindowMode::Fullscreen(MonitorSelection, VideoModeSelection)`.
Previously, the VideoMode was selected based on the closest resolution
to the current window size for SizedFullscreen and the largest
resolution for Fullscreen. It is possible to replicate that behaviour by
searching `Monitor::video_modes` and selecting it with
`VideoModeSelection::Specific(VideoMode)` but it is recommended to use
`VideoModeSelection::Current` as the default video mode when entering
fullscreen.
PR #17965 mistakenly made the `AsBindGroup` macro no longer emit a bind
group layout entry and a resource descriptor for buffers. This commit
adds that functionality back, fixing the `shader_material_bindless`
example.
Closes#18124.
# Objective
- In `Camera::viewport_to_world_2d`, `Camera::viewport_to_world`,
`Camera::world_to_viewport` and `Camera::world_to_viewport_with_depth`,
the results were incorrect when the `Camera::viewport` field was
configured with a viewport position that was non-zero. This PR attempts
to correct that.
- Fixes#16200
## Solution
- This PR now takes the viewport position into account in the functions
mentioned above.
- Extended `2d_viewport_to_world` example to test the functions with a
dynamic viewport position and size, camera positions and zoom levels. It
is probably worth discussing whether to change the example, add a new
one or just completely skip touching the examples.
## Testing
Used the modified example to test the functions with dynamic camera
transform as well as dynamic viewport size and position.
# Objective
Because `prepare_assets::<T>` had a mutable reference to the
`RenderAssetBytesPerFrame` resource, no render asset preparation could
happen in parallel. This PR fixes this by using an `AtomicUsize` to
count bytes written (if there's a limit in place), so that the system
doesn't need mutable access.
- Related: https://github.com/bevyengine/bevy/pull/12622
**Before**
<img width="1049" alt="Screenshot 2025-02-17 at 11 40 53 AM"
src="https://github.com/user-attachments/assets/040e6184-1192-4368-9597-5ceda4b8251b"
/>
**After**
<img width="836" alt="Screenshot 2025-02-17 at 1 38 37 PM"
src="https://github.com/user-attachments/assets/95488796-3323-425c-b0a6-4cf17753512e"
/>
## Testing
- Tested on a local project (with and without limiting enabled)
- Someone with more knowledge of wgpu/underlying driver guts should
confirm that this doesn't actually bite us by introducing contention
(i.e. if buffer writing really *should be* serial).
# Objective
- Allow bevy and wgpu developers to test newer versions of wgpu without
having to update naga_oil.
## Solution
- Currently bevy feeds wgsl through naga_oil to get a naga::Module that
it passes to wgpu.
- Added a way to pass wgsl through naga_oil, and then serialize the
naga::Module back into a wgsl string to feed to wgpu, allowing wgpu to
parse it using it's internal version of naga (and not the version of
naga bevy_render/naga_oil is using).
## Testing
1. Run 3d_scene (it works)
2. Run 3d_scene with `--features bevy_render/decoupled_naga` (it still
works)
3. Add the following patch to bevy/Cargo.toml, run cargo update, and
compile again (it will fail)
```toml
[patch.crates-io]
wgpu = { git = "https://github.com/gfx-rs/wgpu", rev = "2764e7a39920e23928d300e8856a672f1952da63" }
wgpu-core = { git = "https://github.com/gfx-rs/wgpu", rev = "2764e7a39920e23928d300e8856a672f1952da63" }
wgpu-hal = { git = "https://github.com/gfx-rs/wgpu", rev = "2764e7a39920e23928d300e8856a672f1952da63" }
wgpu-types = { git = "https://github.com/gfx-rs/wgpu", rev = "2764e7a39920e23928d300e8856a672f1952da63" }
```
4. Fix errors and compile again (it will work, and you didn't have to
touch naga_oil)
# Objective
WESL's pre-MVP `0.1.0` has been
[released](https://docs.rs/wesl/latest/wesl/)!
Add support for WESL shader source so that we can begin playing and
testing WESL, as well as aiding in their development.
## Solution
Adds a `ShaderSource::WESL` that can be used to load `.wesl` shaders.
Right now, we don't support mixing `naga-oil`. Additionally, WESL
shaders currently need to pass through the naga frontend, which the WESL
team is aware isn't great for performance (they're working on compiling
into naga modules). Also, since our shaders are managed using the asset
system, we don't currently support using file based imports like `super`
or package scoped imports. Further work will be needed to asses how we
want to support this.
---
## Showcase
See the `shader_material_wesl` example. Be sure to press space to
activate party mode (trigger conditional compilation)!
https://github.com/user-attachments/assets/ec6ad19f-b6e4-4e9d-a00f-6f09336b08a4
# Objective
- Contributes to #15460
- Supersedes #8520
- Fixes#4906
## Solution
- Added a new `web` feature to `bevy`, and several of its crates.
- Enabled new `web` feature automatically within crates without `no_std`
support.
## Testing
- `cargo build --no-default-features --target wasm32v1-none`
---
## Migration Guide
When using Bevy crates which _don't_ automatically enable the `web`
feature, please enable it when building for the browser.
## Notes
- I added [`cfg_if`](https://crates.io/crates/cfg-if) to help manage
some of the feature gate gore that this extra feature introduces. It's
still pretty ugly, but I think much easier to read.
- Certain `wasm` targets (e.g.,
[wasm32-wasip1](https://doc.rust-lang.org/nightly/rustc/platform-support/wasm32-wasip1.html#wasm32-wasip1))
provide an incomplete implementation for `std`. I have not tested these
platforms, but I suspect Bevy's liberal use of usually unsupported
features (e.g., threading) will cause these targets to fail. As such,
consider `wasm32-unknown-unknown` as the only `wasm` platform with
support from Bevy for `std`. All others likely will need to be treated
as `no_std` platforms.
# Objective
- Fixes#15460 (will open new issues for further `no_std` efforts)
- Supersedes #17715
## Solution
- Threaded in new features as required
- Made certain crates optional but default enabled
- Removed `compile-check-no-std` from internal `ci` tool since GitHub CI
can now simply check `bevy` itself now
- Added CI task to check `bevy` on `thumbv6m-none-eabi` to ensure
`portable-atomic` support is still valid [^1]
[^1]: This may be controversial, since it could be interpreted as
implying Bevy will maintain support for `thumbv6m-none-eabi` going
forward. In reality, just like `x86_64-unknown-none`, this is a
[canary](https://en.wiktionary.org/wiki/canary_in_a_coal_mine) target to
make it clear when `portable-atomic` no longer works as intended (fixing
atomic support on atomically challenged platforms). If a PR comes
through and makes supporting this class of platforms impossible, then
this CI task can be removed. I however wager this won't be a problem.
## Testing
- CI
---
## Release Notes
Bevy now has support for `no_std` directly from the `bevy` crate.
Users can disable default features and enable a new `default_no_std`
feature instead, allowing `bevy` to be used in `no_std` applications and
libraries.
```toml
# Bevy for `no_std` platforms
bevy = { version = "0.16", default-features = false, features = ["default_no_std"] }
```
`default_no_std` enables certain required features, such as `libm` and
`critical-section`, and as many optional crates as possible (currently
just `bevy_state`). For atomically-challenged platforms such as the
Raspberry Pi Pico, `portable-atomic` will be used automatically.
For library authors, we recommend depending on `bevy` with
`default-features = false` to allow `std` and `no_std` users to both
depend on your crate. Here are some recommended features a library crate
may want to expose:
```toml
[features]
# Most users will be on a platform which has `std` and can use the more-powerful `async_executor`.
default = ["std", "async_executor"]
# Features for typical platforms.
std = ["bevy/std"]
async_executor = ["bevy/async_executor"]
# Features for `no_std` platforms.
libm = ["bevy/libm"]
critical-section = ["bevy/critical-section"]
[dependencies]
# We disable default features to ensure we don't accidentally enable `std` on `no_std` targets, for example.
bevy = { version = "0.16", default-features = false }
```
While this is verbose, it gives the maximum control to end-users to
decide how they wish to use Bevy on their platform.
We encourage library authors to experiment with `no_std` support. For
libraries relying exclusively on `bevy` and no other dependencies, it
may be as simple as adding `#![no_std]` to your `lib.rs` and exposing
features as above! Bevy can also provide many `std` types, such as
`HashMap`, `Mutex`, and `Instant` on all platforms. See
`bevy::platform_support` for details on what's available out of the box!
## Migration Guide
- If you were previously relying on `bevy` with default features
disabled, you may need to enable the `std` and `async_executor`
features.
- `bevy_reflect` has had its `bevy` feature removed. If you were relying
on this feature, simply enable `smallvec` and `smol_str` instead.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
`insert_or_spawn_batch` is due to be deprecated eventually (#15704), and
removing uses internally will make that easier.
## Solution
Replaced internal uses of `insert_or_spawn_batch` with
`try_insert_batch` (non-panicking variant because
`insert_or_spawn_batch` didn't panic).
All of the internal uses are in rendering code. Since retained rendering
was meant to get rid non-opaque entity IDs, I assume the code was just
using `insert_or_spawn_batch` because `insert_batch` didn't exist and
not because it actually wanted to spawn something. However, I am *not*
confident in my ability to judge rendering code.
# Objective
Component `require()` IDE integration is fully broken, as of #16575.
## Solution
This reverts us back to the previous "put the docs on Component trait"
impl. This _does_ reduce the accessibility of the required components in
rust docs, but the complete erasure of "required component IDE
experience" is not worth the price of slightly increased prominence of
requires in docs.
Additionally, Rust Analyzer has recently started including derive
attributes in suggestions, so we aren't losing that benefit of the
proc_macro attribute impl.
# Objective
Fix unsound query transmutes on queries obtained from
`Query::as_readonly()`.
The following compiles, and the call to `transmute_lens()` should panic,
but does not:
```rust
fn bad_system(query: Query<&mut A>) {
let mut readonly = query.as_readonly();
let mut lens: QueryLens<&mut A> = readonly.transmute_lens();
let other_readonly: Query<&A> = query.as_readonly();
// `lens` and `other_readonly` alias, and are both alive here!
}
```
To make `Query::as_readonly()` zero-cost, we pointer-cast
`&QueryState<D, F>` to `&QueryState<D::ReadOnly, F>`. This means that
the `component_access` for a read-only query's state may include
accesses for the original mutable version, but the `Query` does not have
exclusive access to those components! `transmute` and `join` use that
access to ensure that a join is valid, and will incorrectly allow a
transmute that includes mutable access.
As a bonus, allow `Query::join`s that output `FilteredEntityRef` or
`FilteredEntityMut` to receive access from the `other` query. Currently
they only receive access from `self`.
## Solution
When transmuting or joining from a read-only query, remove any writes
before performing checking that the transmute is valid. For joins, be
sure to handle the case where one input query was the result of
`as_readonly()` but the other has valid mutable access.
This requires identifying read-only queries, so add a
`QueryData::IS_READ_ONLY` associated constant. Note that we only call
`QueryState::as_transmuted_state()` with `NewD: ReadOnlyQueryData`, so
checking for read-only queries is sufficient to check for
`as_transmuted_state()`.
Removing writes requires allocating a new `FilteredAccess`, so only do
so if the query is read-only and the state has writes. Otherwise, the
existing access is correct and we can continue using a reference to it.
Use the new read-only state to call `NewD::set_access`, so that
transmuting to a `FilteredAccessMut` results in a read-only
`FilteredAccessMut`. Otherwise, it would take the original write access,
and then the transmute would panic because it had too much access.
Note that `join` was previously passing `self.component_access` to
`NewD::set_access`. Switching it to `joined_component_access` also
allows a join that outputs `FilteredEntity(Ref|Mut)` to receive access
from `other`. The fact that it didn't do that before seems like an
oversight, so I didn't try to prevent that change.
## Testing
Added unit tests with the unsound transmute and join.
# Objective
As discussed in #14275, Bevy is currently too prone to panic, and makes
the easy / beginner-friendly way to do a large number of operations just
to panic on failure.
This is seriously frustrating in library code, but also slows down
development, as many of the `Query::single` panics can actually safely
be an early return (these panics are often due to a small ordering issue
or a change in game state.
More critically, in most "finished" products, panics are unacceptable:
any unexpected failures should be handled elsewhere. That's where the
new
With the advent of good system error handling, we can now remove this.
Note: I was instrumental in a) introducing this idea in the first place
and b) pushing to make the panicking variant the default. The
introduction of both `let else` statements in Rust and the fancy system
error handling work in 0.16 have changed my mind on the right balance
here.
## Solution
1. Make `Query::single` and `Query::single_mut` (and other random
related methods) return a `Result`.
2. Handle all of Bevy's internal usage of these APIs.
3. Deprecate `Query::get_single` and friends, since we've moved their
functionality to the nice names.
4. Add detailed advice on how to best handle these errors.
Generally I like the diff here, although `get_single().unwrap()` in
tests is a bit of a downgrade.
## Testing
I've done a global search for `.single` to track down any missed
deprecated usages.
As to whether or not all the migrations were successful, that's what CI
is for :)
## Future work
~~Rename `Query::get_single` and friends to `Query::single`!~~
~~I've opted not to do this in this PR, and smear it across two releases
in order to ease the migration. Successive deprecations are much easier
to manage than the semantics and types shifting under your feet.~~
Cart has convinced me to change my mind on this; see
https://github.com/bevyengine/bevy/pull/18082#discussion_r1974536085.
## Migration guide
`Query::single`, `Query::single_mut` and their `QueryState` equivalents
now return a `Result`. Generally, you'll want to:
1. Use Bevy 0.16's system error handling to return a `Result` using the
`?` operator.
2. Use a `let else Ok(data)` block to early return if it's an expected
failure.
3. Use `unwrap()` or `Ok` destructuring inside of tests.
The old `Query::get_single` (etc) methods which did this have been
deprecated.
# Objective
There are currently three ways to access the parent stored on a ChildOf
relationship:
1. `child_of.parent` (field accessor)
2. `child_of.get()` (get function)
3. `**child_of` (Deref impl)
I will assert that we should only have one (the field accessor), and
that the existence of the other implementations causes confusion and
legibility issues. The deref approach is heinous, and `child_of.get()`
is significantly less clear than `child_of.parent`.
## Solution
Remove `impl Deref for ChildOf` and `ChildOf::get`.
The one "downside" I'm seeing is that:
```rust
entity.get::<ChildOf>().map(ChildOf::get)
```
Becomes this:
```rust
entity.get::<ChildOf>().map(|c| c.parent)
```
I strongly believe that this is worth the increased clarity and
consistency. I'm also not really a huge fan of the "pass function
pointer to map" syntax. I think most people don't think this way about
maps. They think in terms of a function that takes the item in the
Option and returns the result of some action on it.
## Migration Guide
```rust
// Before
**child_of
// After
child_of.parent
// Before
child_of.get()
// After
child_of.parent
// Before
entity.get::<ChildOf>().map(ChildOf::get)
// After
entity.get::<ChildOf>().map(|c| c.parent)
```
# Objective
fixes#17896
## Solution
Change ChildOf ( Entity ) to ChildOf { parent: Entity }
by doing this we also allow users to use named structs for relationship
derives, When you have more than 1 field in a struct with named fields
the macro will look for a field with the attribute #[relationship] and
all of the other fields should implement the Default trait. Unnamed
fields are still supported.
When u have a unnamed struct with more than one field the macro will
fail.
Do we want to support something like this ?
```rust
#[derive(Component)]
#[relationship_target(relationship = ChildOf)]
pub struct Children (#[relationship] Entity, u8);
```
I could add this, it but doesn't seem nice.
## Testing
crates/bevy_ecs - cargo test
## Showcase
```rust
use bevy_ecs::component::Component;
use bevy_ecs::entity::Entity;
#[derive(Component)]
#[relationship(relationship_target = Children)]
pub struct ChildOf {
#[relationship]
pub parent: Entity,
internal: u8,
};
#[derive(Component)]
#[relationship_target(relationship = ChildOf)]
pub struct Children {
children: Vec<Entity>
};
```
---------
Co-authored-by: Tim Overbeek <oorbecktim@Tims-MacBook-Pro.local>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-042.client.nl.eduvpn.org>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-059.client.nl.eduvpn.org>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-054.client.nl.eduvpn.org>
Co-authored-by: Tim Overbeek <oorbecktim@c-001-001-027.client.nl.eduvpn.org>
Even though opaque deferred entities aren't placed into the `Opaque3d`
bin, we still want to cache them as though they were, so that we don't
have to re-queue them every frame. This commit implements that logic,
reducing the time of `queue_material_meshes` to near-zero on Caldera.
Currently, the structure-level `#[uniform]` attribute of `AsBindGroup`
creates a binding array of individual buffers, each of which contains
data for a single material. A more efficient approach would be to
provide a single buffer with an array containing all of the data for all
materials in the bind group. Because `StandardMaterial` uses
`#[uniform]`, this can be notably inefficient with large numbers of
materials.
This patch introduces a new attribute on `AsBindGroup`, `#[data]`, which
works identically to `#[uniform]` except that it concatenates all the
data into a single buffer that the material bind group allocator itself
manages. It also converts `StandardMaterial` to use this new
functionality. This effectively provides the "material data in arrays"
feature.
# Objective
- Fixes#17960
## Solution
- Followed the [edition upgrade
guide](https://doc.rust-lang.org/edition-guide/editions/transitioning-an-existing-project-to-a-new-edition.html)
## Testing
- CI
---
## Summary of Changes
### Documentation Indentation
When using lists in documentation, proper indentation is now linted for.
This means subsequent lines within the same list item must start at the
same indentation level as the item.
```rust
/* Valid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
/* Invalid */
/// - Item 1
/// Run-on sentence.
/// - Item 2
struct Foo;
```
### Implicit `!` to `()` Conversion
`!` (the never return type, returned by `panic!`, etc.) no longer
implicitly converts to `()`. This is particularly painful for systems
with `todo!` or `panic!` statements, as they will no longer be functions
returning `()` (or `Result<()>`), making them invalid systems for
functions like `add_systems`. The ideal fix would be to accept functions
returning `!` (or rather, _not_ returning), but this is blocked on the
[stabilisation of the `!` type
itself](https://doc.rust-lang.org/std/primitive.never.html), which is
not done.
The "simple" fix would be to add an explicit `-> ()` to system
signatures (e.g., `|| { todo!() }` becomes `|| -> () { todo!() }`).
However, this is _also_ banned, as there is an existing lint which (IMO,
incorrectly) marks this as an unnecessary annotation.
So, the "fix" (read: workaround) is to put these kinds of `|| -> ! { ...
}` closuers into variables and give the variable an explicit type (e.g.,
`fn()`).
```rust
// Valid
let system: fn() = || todo!("Not implemented yet!");
app.add_systems(..., system);
// Invalid
app.add_systems(..., || todo!("Not implemented yet!"));
```
### Temporary Variable Lifetimes
The order in which temporary variables are dropped has changed. The
simple fix here is _usually_ to just assign temporaries to a named
variable before use.
### `gen` is a keyword
We can no longer use the name `gen` as it is reserved for a future
generator syntax. This involved replacing uses of the name `gen` with
`r#gen` (the raw-identifier syntax).
### Formatting has changed
Use statements have had the order of imports changed, causing a
substantial +/-3,000 diff when applied. For now, I have opted-out of
this change by amending `rustfmt.toml`
```toml
style_edition = "2021"
```
This preserves the original formatting for now, reducing the size of
this PR. It would be a simple followup to update this to 2024 and run
`cargo fmt`.
### New `use<>` Opt-Out Syntax
Lifetimes are now implicitly included in RPIT types. There was a handful
of instances where it needed to be added to satisfy the borrow checker,
but there may be more cases where it _should_ be added to avoid
breakages in user code.
### `MyUnitStruct { .. }` is an invalid pattern
Previously, you could match against unit structs (and unit enum
variants) with a `{ .. }` destructuring. This is no longer valid.
### Pretty much every use of `ref` and `mut` are gone
Pattern binding has changed to the point where these terms are largely
unused now. They still serve a purpose, but it is far more niche now.
### `iter::repeat(...).take(...)` is bad
New lint recommends using the more explicit `iter::repeat_n(..., ...)`
instead.
## Migration Guide
The lifetimes of functions using return-position impl-trait (RPIT) are
likely _more_ conservative than they had been previously. If you
encounter lifetime issues with such a function, please create an issue
to investigate the addition of `+ use<...>`.
## Notes
- Check the individual commits for a clearer breakdown for what
_actually_ changed.
---------
Co-authored-by: François Mockers <francois.mockers@vleue.com>
Two-phase occlusion culling can be helpful for shadow maps just as it
can for a prepass, in order to reduce vertex and alpha mask fragment
shading overhead. This patch implements occlusion culling for shadow
maps from directional lights, when the `OcclusionCulling` component is
present on the entities containing the lights. Shadow maps from point
lights are deferred to a follow-up patch. Much of this patch involves
expanding the hierarchical Z-buffer to cover shadow maps in addition to
standard view depth buffers.
The `scene_viewer` example has been updated to add `OcclusionCulling` to
the directional light that it creates.
This improved the performance of the rend3 sci-fi test scene when
enabling shadows.
Currently, Bevy's implementation of bindless resources is rather
unusual: every binding in an object that implements `AsBindGroup` (most
commonly, a material) becomes its own separate binding array in the
shader. This is inefficient for two reasons:
1. If multiple materials reference the same texture or other resource,
the reference to that resource will be duplicated many times. This
increases `wgpu` validation overhead.
2. It creates many unused binding array slots. This increases `wgpu` and
driver overhead and makes it easier to hit limits on APIs that `wgpu`
currently imposes tight resource limits on, like Metal.
This PR fixes these issues by switching Bevy to use the standard
approach in GPU-driven renderers, in which resources are de-duplicated
and passed as global arrays, one for each type of resource.
Along the way, this patch introduces per-platform resource limits and
bumps them from 16 resources per binding array to 64 resources per bind
group on Metal and 2048 resources per bind group on other platforms.
(Note that the number of resources per *binding array* isn't the same as
the number of resources per *bind group*; as it currently stands, if all
the PBR features are turned on, Bevy could pack as many as 496 resources
into a single slab.) The limits have been increased because `wgpu` now
has universal support for partially-bound binding arrays, which mean
that we no longer need to fill the binding arrays with fallback
resources on Direct3D 12. The `#[bindless(LIMIT)]` declaration when
deriving `AsBindGroup` can now simply be written `#[bindless]` in order
to have Bevy choose a default limit size for the current platform.
Custom limits are still available with the new
`#[bindless(limit(LIMIT))]` syntax: e.g. `#[bindless(limit(8))]`.
The material bind group allocator has been completely rewritten. Now
there are two allocators: one for bindless materials and one for
non-bindless materials. The new non-bindless material allocator simply
maintains a 1:1 mapping from material to bind group. The new bindless
material allocator maintains a list of slabs and allocates materials
into slabs on a first-fit basis. This unfortunately makes its
performance O(number of resources per object * number of slabs), but the
number of slabs is likely to be low, and it's planned to become even
lower in the future with `wgpu` improvements. Resources are
de-duplicated with in a slab and reference counted. So, for instance, if
multiple materials refer to the same texture, that texture will exist
only once in the appropriate binding array.
To support these new features, this patch adds the concept of a
*bindless descriptor* to the `AsBindGroup` trait. The bindless
descriptor allows the material bind group allocator to probe the layout
of the material, now that an array of `BindGroupLayoutEntry` records is
insufficient to describe the group. The `#[derive(AsBindGroup)]` has
been heavily modified to support the new features. The most important
user-facing change to that macro is that the struct-level `uniform`
attribute, `#[uniform(BINDING_NUMBER, StandardMaterial)]`, now reads
`#[uniform(BINDLESS_INDEX, MATERIAL_UNIFORM_TYPE,
binding_array(BINDING_NUMBER)]`, allowing the material to specify the
binding number for the binding array that holds the uniform data.
To make this patch simpler, I removed support for bindless
`ExtendedMaterial`s, as well as field-level bindless uniform and storage
buffers. I intend to add back support for these as a follow-up. Because
they aren't in any released Bevy version yet, I figured this was OK.
Finally, this patch updates `StandardMaterial` for the new bindless
changes. Generally, code throughout the PBR shaders that looked like
`base_color_texture[slot]` now looks like
`bindless_2d_textures[material_indices[slot].base_color_texture]`.
This patch fixes a system hang that I experienced on the [Caldera test]
when running with `caldera --random-materials --texture-count 100`. The
time per frame is around 19.75 ms, down from 154.2 ms in Bevy 0.14: a
7.8× speedup.
[Caldera test]: https://github.com/DGriffin91/bevy_caldera_scene
This commit restructures the multidrawable batch set builder for better
performance in various ways:
* The bin traversal is optimized to make the best use of the CPU cache.
* The inner loop that iterates over the bins, which is the hottest part
of `batch_and_prepare_binned_render_phase`, has been shrunk as small as
possible.
* Where possible, multiple elements are added to or reserved from GPU
buffers as a batch instead of one at a time.
* Methods that LLVM wasn't inlining have been marked `#[inline]` where
doing so would unlock optimizations.
This code has also been refactored to avoid duplication between the
logic for indexed and non-indexed meshes via the introduction of a
`MultidrawableBatchSetPreparer` object.
Together, this improved the `batch_and_prepare_binned_render_phase` time
on Caldera by approximately 2×.
Eventually, we should optimize the batchable-but-not-multidrawable and
unbatchable logic as well, but these meshes are much rarer, so in the
interests of keeping this patch relatively small I opted to leave those
to a follow-up.
# Objective
Make checked vs unchecked shaders configurable
Fixes#17786
## Solution
Added `ValidateShaders` enum to `Shader` and added
`create_and_validate_shader_module` to `RenderDevice`
## Testing
I tested the shader examples locally and they all worked. I'd like to
write a few tests to verify but am unsure how to start.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
The `check_visibility` system currently follows this algorithm:
1. Store all meshes that were visible last frame in the
`PreviousVisibleMeshes` set.
2. Determine which meshes are visible. For each such visible mesh,
remove it from `PreviousVisibleMeshes`.
3. Mark all meshes that remain in `PreviousVisibleMeshes` as invisible.
This algorithm would be correct if the `check_visibility` were the only
system that marked meshes visible. However, it's not: the shadow-related
systems `check_dir_light_mesh_visibility` and
`check_point_light_mesh_visibility` can as well. This results in the
following sequence of events for meshes that are in a shadow map but
*not* visible from a camera:
A. `check_visibility` runs, finds that no camera contains these meshes,
and marks them hidden, which sets the changed flag.
B. `check_dir_light_mesh_visibility` and/or
`check_point_light_mesh_visibility` run, discover that these meshes
are visible in the shadow map, and marks them as visible, again
setting the `ViewVisibility` changed flag.
C. During the extraction phase, the mesh extraction system sees that
`ViewVisibility` is changed and re-extracts the mesh.
This is inefficient and results in needless work during rendering.
This patch fixes the issue in two ways:
* The `check_dir_light_mesh_visibility` and
`check_point_light_mesh_visibility` systems now remove meshes that they
discover from `PreviousVisibleMeshes`.
* Step (3) above has been moved from `check_visibility` to a separate
system, `mark_newly_hidden_entities_invisible`. This system runs after
all visibility-determining systems, ensuring that
`PreviousVisibleMeshes` contains only those meshes that truly became
invisible on this frame.
This fix dramatically improves the performance of [the Caldera
benchmark], when combined with several other patches I've submitted.
[the Caldera benchmark]:
https://github.com/DGriffin91/bevy_caldera_scene
PR #17688 broke motion vector computation, and therefore motion blur,
because it enabled retention of `MeshInputUniform`s, and
`MeshInputUniform`s contain the indices of the previous frame's
transform and the previous frame's skinned mesh joint matrices. On frame
N, if a `MeshInputUniform` is retained on GPU from the previous frame,
the `previous_input_index` and `previous_skin_index` would refer to the
indices for frame N - 2, not the index for frame N - 1.
This patch fixes the problems. It solves these issues in two different
ways, one for transforms and one for skins:
1. To fix transforms, this patch supplies the *frame index* to the
shader as part of the view uniforms, and specifies which frame index
each mesh's previous transform refers to. So, in the situation described
above, the frame index would be N, the previous frame index would be N -
1, and the `previous_input_frame_number` would be N - 2. The shader can
now detect this situation and infer that the mesh has been retained, and
can therefore conclude that the mesh's transform hasn't changed.
2. To fix skins, this patch replaces the explicit `previous_skin_index`
with an invariant that the index of the joints for the current frame and
the index of the joints for the previous frame are the same. This means
that the `MeshInputUniform` never has to be updated even if the skin is
animated. The downside is that we have to copy joint matrices from the
previous frame's buffer to the current frame's buffer in
`extract_skins`.
The rationale behind (2) is that we currently have no mechanism to
detect when joints that affect a skin have been updated, short of
comparing all the transforms and setting a flag for
`extract_meshes_for_gpu_building` to consume, which would regress
performance as we want `extract_skins` and
`extract_meshes_for_gpu_building` to be able to run in parallel.
To test this change, use `cargo run --example motion_blur`.
Currently, Bevy rebuilds the buffer containing all the transforms for
joints every frame, during the extraction phase. This is inefficient in
cases in which many skins are present in the scene and their joints
don't move, such as the Caldera test scene.
To address this problem, this commit switches skin extraction to use a
set of retained GPU buffers with allocations managed by the offset
allocator. I use fine-grained change detection in order to determine
which skins need updating. Note that the granularity is on the level of
an entire skin, not individual joints. Using the change detection at
that level would yield poor performance in common cases in which an
entire skin is animated at once. Also, this patch yields additional
performance from the fact that changing joint transforms no longer
requires the skinned mesh to be re-extracted.
Note that this optimization can be a double-edged sword. In
`many_foxes`, fine-grained change detection regressed the performance of
`extract_skins` by 3.4x. This is because every joint is updated every
frame in that example, so change detection is pointless and is pure
overhead. Because the `many_foxes` workload is actually representative
of animated scenes, this patch includes a heuristic that disables
fine-grained change detection if the number of transformed entities in
the frame exceeds a certain fraction of the total number of joints.
Currently, this threshold is set to 25%. Note that this is a crude
heuristic, because it doesn't distinguish between the number of
transformed *joints* and the number of transformed *entities*; however,
it should be good enough to yield the optimum code path most of the
time.
Finally, this patch fixes a bug whereby skinned meshes are actually
being incorrectly retained if the buffer offsets of the joints of those
skinned meshes changes from frame to frame. To fix this without
retaining skins, we would have to re-extract every skinned mesh every
frame. Doing this was a significant regression on Caldera. With this PR,
by contrast, mesh joints stay at the same buffer offset, so we don't
have to update the `MeshInputUniform` containing the buffer offset every
frame. This also makes PR #17717 easier to implement, because that PR
uses the buffer offset from the previous frame, and the logic for
calculating that is simplified if the previous frame's buffer offset is
guaranteed to be identical to that of the current frame.
On Caldera, this patch reduces the time spent in `extract_skins` from
1.79 ms to near zero. On `many_foxes`, this patch regresses the
performance of `extract_skins` by approximately 10%-25%, depending on
the number of foxes. This has only a small impact on frame rate.
The GPU can fill out many of the fields in `IndirectParametersMetadata`
using information it already has:
* `early_instance_count` and `late_instance_count` are always
initialized to zero.
* `mesh_index` is already present in the work item buffer as the
`input_index` of the first work item in each batch.
This patch moves these fields to a separate buffer, the *GPU indirect
parameters metadata* buffer. That way, it avoids having to write them on
CPU during `batch_and_prepare_binned_render_phase`. This effectively
reduces the number of bits that that function must write per mesh from
160 to 64 (in addition to the 64 bits per mesh *instance*).
Additionally, this PR refactors `UntypedPhaseIndirectParametersBuffers`
to add another layer, `MeshClassIndirectParametersBuffers`, which allows
abstracting over the buffers corresponding indexed and non-indexed
meshes. This patch doesn't make much use of this abstraction, but
forthcoming patches will, and it's overall a cleaner approach.
This didn't seem to have much of an effect by itself on
`batch_and_prepare_binned_render_phase` time, but subsequent PRs
dependent on this PR yield roughly a 2× speedup.
## Objective
There's no general error for when an entity doesn't exist, and some
methods are going to need one when they get Resultified. The closest
thing is `EntityFetchError`, but that error has a slightly more specific
purpose.
## Solution
- Added `EntityDoesNotExistError`.
- Contains `Entity` and `EntityDoesNotExistDetails`.
- Changed `EntityFetchError` and `QueryEntityError`:
- Changed `NoSuchEntity` variant to wrap `EntityDoesNotExistError` and
renamed the variant to `EntityDoesNotExist`.
- Renamed `EntityFetchError` to `EntityMutableFetchError` to make its
purpose clearer.
- Renamed `TryDespawnError` to `EntityDespawnError` to make it more
general.
- Changed `World::inspect_entity` to return `Result<[ok],
EntityDoesNotExistError>` instead of panicking.
- Changed `World::get_entity` and `WorldEntityFetch::fetch_ref` to
return `Result<[ok], EntityDoesNotExistError>` instead of `Result<[ok],
Entity>`.
- Changed `UnsafeWorldCell::get_entity` to return
`Result<UnsafeEntityCell, EntityDoesNotExistError>` instead of
`Option<UnsafeEntityCell>`.
## Migration Guide
- `World::inspect_entity` now returns `Result<impl Iterator<Item =
&ComponentInfo>, EntityDoesNotExistError>` instead of `impl
Iterator<Item = &ComponentInfo>`.
- `World::get_entity` now returns `EntityDoesNotExistError` as an error
instead of `Entity`. You can still access the entity's ID through the
error's `entity` field.
- `UnsafeWorldCell::get_entity` now returns `Result<UnsafeEntityCell,
EntityDoesNotExistError>` instead of `Option<UnsafeEntityCell>`.
Appending to these vectors is performance-critical in
`batch_and_prepare_binned_render_phase`, so `RawBufferVec`, which
doesn't have the overhead of `encase`, is more appropriate.
The `collect_buffers_for_phase` system tries to reuse these buffers, but
its efforts are stymied by the fact that
`clear_batched_gpu_instance_buffers` clears the containing hash table
and therefore frees the buffers. This patch makes
`clear_batched_gpu_instance_buffers` stop doing that so that the
allocations can be reused.
There was nonsense code in `batch_and_prepare_sorted_render_phase` that
created temporary buffers to add objects to instead of using the correct
ones. I think this was debug code. This commit removes that code in
favor of writing to the actual buffers.
Closes#17846.
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
The `output_index` field is only used in direct mode, and the
`indirect_parameters_index` field is only used in indirect mode.
Consequently, we can combine them into a single field, reducing the size
of `PreprocessWorkItem`, which
`batch_and_prepare_{binned,sorted}_render_phase` must construct every
frame for every mesh instance, from 96 bits to 64 bits.
Currently, invocations of `batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` can't run in parallel because
they write to scene-global GPU buffers. After PR #17698,
`batch_and_prepare_binned_render_phase` started accounting for the
lion's share of the CPU time, causing us to be strongly CPU bound on
scenes like Caldera when occlusion culling was on (because of the
overhead of batching for the Z-prepass). Although I eventually plan to
optimize `batch_and_prepare_binned_render_phase`, we can obtain
significant wins now by parallelizing that system across phases.
This commit splits all GPU buffers that
`batch_and_prepare_binned_render_phase` and
`batch_and_prepare_sorted_render_phase` touches into separate buffers
for each phase so that the scheduler will run those phases in parallel.
At the end of batch preparation, we gather the render phases up into a
single resource with a new *collection* phase. Because we already run
mesh preprocessing separately for each phase in order to make occlusion
culling work, this is actually a cleaner separation. For example, mesh
output indices (the unique ID that identifies each mesh instance on GPU)
are now guaranteed to be sequential starting from 0, which will simplify
the forthcoming work to remove them in favor of the compute dispatch ID.
On Caldera, this brings the frame time down to approximately 9.1 ms with
occlusion culling on.

Conceptually, bins are ordered hash maps. We currently implement these
as a list of keys with an associated hash map. But we already have a
data type that implements ordered hash maps directly: `IndexMap`. This
patch switches Bevy to use `IndexMap`s for bins. Because we're memory
bound, this doesn't affect performance much, but it is cleaner.
# Objective
- Wgpu has some expensive code it injects into shaders to avoid the
possibility of things like infinite loops. Generally our shaders are
written by users who won't do this, so it just makes our shaders perform
worse.
## Solution
- Turn off the checks.
- We could try to conditionally keep them, but that complicates the code
and 99.9% of users won't want this.
## Migration Guide
- Bevy no longer turns on wgpu's runtime safety checks
https://docs.rs/wgpu/latest/wgpu/struct.ShaderRuntimeChecks.html. If you
were using Bevy with untrusted shaders, please file an issue.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
## Objective
Get rid of a redundant Cargo feature flag.
## Solution
Use the built-in `target_abi = "sim"` instead of a custom Cargo feature
flag, which is set for the iOS (and visionOS and tvOS) simulator. This
has been stable since Rust 1.78.
In the future, some of this may become redundant if Wgpu implements
proper supper for the iOS Simulator:
https://github.com/gfx-rs/wgpu/issues/7057
CC @mockersf who implemented [the original
fix](https://github.com/bevyengine/bevy/pull/10178).
## Testing
- Open mobile example in Xcode.
- Launch the simulator.
- See that no errors are emitted.
- Remove the code cfg-guarded behind `target_abi = "sim"`.
- See that an error now happens.
(I haven't actually performed these steps on the latest `main`, because
I'm hitting an unrelated error (EDIT: It was
https://github.com/bevyengine/bevy/pull/17637). But tested it on
0.15.0).
---
## Migration Guide
> If you're using a project that builds upon the mobile example, remove
the `ios_simulator` feature from your `Cargo.toml` (Bevy now handles
this internally).
Currently, we look up each `MeshInputUniform` index in a hash table that
maps the main entity ID to the index every frame. This is inefficient,
cache unfriendly, and unnecessary, as the `MeshInputUniform` index for
an entity remains the same from frame to frame (even if the input
uniform changes). This commit changes the `IndexSet` in the `RenderBin`
to an `IndexMap` that maps the `MainEntity` to `MeshInputUniformIndex`
(a new type that this patch adds for more type safety).
On Caldera with parallel `batch_and_prepare_binned_render_phase`, this
patch improves that function from 3.18 ms to 2.42 ms, a 31% speedup.
Currently, when a mesh slab overflows, we recreate the allocator and
reinsert all the meshes that were in it in an arbitrary order. This can
result in the meshes moving around. Before `MeshInputUniform`s were
retained, this was slow but harmless, because the `MeshInputUniform`
that contained the positions of the vertex and index data in the slab
would be recreated every frame. However, with mesh retention, there's no
guarantee that the `MeshInputUniform`, which could be cached from the
previous frame, will reflect the new position of the mesh data within
the buffer if that buffer happened to grow. This manifested itself as
seeming mesh data corruption when adding many meshes dynamically to the
scene.
There are three possible ways that I could have fixed this that I can
see:
1. Invalidate and rebuild all the `MeshInputUniform`s belonging to all
meshes in a slab when that mesh grows.
2. Introduce a second layer of indirection so that the
`MeshInputUniform` points to a *mesh allocation table* that contains the
current locations of the data of each mesh.
3. Avoid moving meshes when reallocating the buffer.
To be efficient, option (1) would require scanning meshes to see if
their positions changed, a la
`mark_meshes_as_changed_if_their_materials_changed`. Option (2) would
add more runtime indirection and would require additional bookkeeping on
the part of the allocator.
Therefore, this PR chooses option (3), which was remarkably simple to
implement. The key is that the offset allocator happens to allocate
addresses from low addresses to high addresses. So all we have to do is
to *conceptually* allocate the full 512 MiB mesh slab as far as the
offset allocator is concerned, and grow the underlying backing store
from 1 MiB to 512 MiB as needed. In other words, the allocator now
allocates *virtual* GPU memory, and the actual backing slab resizes to
fit the virtual memory. This ensures that the location of mesh data
remains constant for the lifetime of the mesh asset, and we can remove
the code that reinserts meshes one by one when the slab grows in favor
of a single buffer copy.
Closes#17766.
Currently, we *sweep*, or remove entities from bins when those entities
became invisible or changed phases, during `queue_material_meshes` and
similar phases. This, however, is wrong, because `queue_material_meshes`
executes once per material type, not once per phase. This could result
in sweeping bins multiple times per phase, which can corrupt the bins.
This commit fixes the issue by moving sweeping to a separate system that
runs after queuing.
This manifested itself as entities appearing and disappearing seemingly
at random.
Closes#17759.
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
# Objective
Because of mesh preprocessing, users cannot rely on
`@builtin(instance_index)` in order to reference external data, as the
instance index is not stable, either from frame to frame or relative to
the total spawn order of mesh instances.
## Solution
Add a user supplied mesh index that can be used for referencing external
data when drawing instanced meshes.
Closes#13373
## Testing
Benchmarked `many_cubes` showing no difference in total frame time.
## Showcase
https://github.com/user-attachments/assets/80620147-aafc-4d9d-a8ee-e2149f7c8f3b
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
https://github.com/bevyengine/bevy/issues/17746
## Solution
- Change `Image.data` from being a `Vec<u8>` to a `Option<Vec<u8>>`
- Added functions to help with creating images
## Testing
- Did you test these changes? If so, how?
All current tests pass
Tested a variety of existing examples to make sure they don't crash
(they don't)
- If relevant, what platforms did you test these changes on, and are
there any important ones you can't test?
Linux x86 64-bit NixOS
---
## Migration Guide
Code that directly access `Image` data will now need to use unwrap or
handle the case where no data is provided.
Behaviour of new_fill slightly changed, but not in a way that is likely
to affect anything. It no longer panics and will fill the whole texture
instead of leaving black pixels if the data provided is not a nice
factor of the size of the image.
---------
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
## Objective
A major critique of Bevy at the moment is how boilerplatey it is to
compose (and read) entity hierarchies:
```rust
commands
.spawn(Foo)
.with_children(|p| {
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
p.spawn(Bar).with_children(|p| {
p.spawn(Baz);
});
});
```
There is also currently no good way to statically define and return an
entity hierarchy from a function. Instead, people often do this
"internally" with a Commands function that returns nothing, making it
impossible to spawn the hierarchy in other cases (direct World spawns,
ChildSpawner, etc).
Additionally, because this style of API results in creating the
hierarchy bits _after_ the initial spawn of a bundle, it causes ECS
archetype changes (and often expensive table moves).
Because children are initialized after the fact, we also can't count
them to pre-allocate space. This means each time a child inserts itself,
it has a high chance of overflowing the currently allocated capacity in
the `RelationshipTarget` collection, causing literal worst-case
reallocations.
We can do better!
## Solution
The Bundle trait has been extended to support an optional
`BundleEffect`. This is applied directly to World immediately _after_
the Bundle has fully inserted. Note that this is
[intentionally](https://github.com/bevyengine/bevy/discussions/16920)
_not done via a deferred Command_, which would require repeatedly
copying each remaining subtree of the hierarchy to a new command as we
walk down the tree (_not_ good performance).
This allows us to implement the new `SpawnRelated` trait for all
`RelationshipTarget` impls, which looks like this in practice:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
Spawn((
Bar,
Children::spawn(Spawn(Baz)),
)),
))
))
```
`Children::spawn` returns `SpawnRelatedBundle<Children, L:
SpawnableList>`, which is a `Bundle` that inserts `Children`
(preallocated to the size of the `SpawnableList::size_hint()`).
`Spawn<B: Bundle>(pub B)` implements `SpawnableList` with a size of 1.
`SpawnableList` is also implemented for tuples of `SpawnableList` (same
general pattern as the Bundle impl).
There are currently three built-in `SpawnableList` implementations:
```rust
world.spawn((
Foo,
Children::spawn((
Spawn(Name::new("Child1")),
SpawnIter(["Child2", "Child3"].into_iter().map(Name::new),
SpawnWith(|parent: &mut ChildSpawner| {
parent.spawn(Name::new("Child4"));
parent.spawn(Name::new("Child5"));
})
)),
))
```
We get the benefits of "structured init", but we have nice flexibility
where it is required!
Some readers' first instinct might be to try to remove the need for the
`Spawn` wrapper. This is impossible in the Rust type system, as a tuple
of "child Bundles to be spawned" and a "tuple of Components to be added
via a single Bundle" is ambiguous in the Rust type system. There are two
ways to resolve that ambiguity:
1. By adding support for variadics to the Rust type system (removing the
need for nested bundles). This is out of scope for this PR :)
2. Using wrapper types to resolve the ambiguity (this is what I did in
this PR).
For the single-entity spawn cases, `Children::spawn_one` does also
exist, which removes the need for the wrapper:
```rust
world.spawn((
Foo,
Children::spawn_one(Bar),
))
```
## This works for all Relationships
This API isn't just for `Children` / `ChildOf` relationships. It works
for any relationship type, and they can be mixed and matched!
```rust
world.spawn((
Foo,
Observers::spawn((
Spawn(Observer::new(|trigger: Trigger<FuseLit>| {})),
Spawn(Observer::new(|trigger: Trigger<Exploded>| {})),
)),
OwnerOf::spawn(Spawn(Bar))
Children::spawn(Spawn(Baz))
))
```
## Macros
While `Spawn` is necessary to satisfy the type system, we _can_ remove
the need to express it via macros. The example above can be expressed
more succinctly using the new `children![X]` macro, which internally
produces `Children::spawn(Spawn(X))`:
```rust
world.spawn((
Foo,
children![
(
Bar,
children![Baz],
),
(
Bar,
children![Baz],
),
]
))
```
There is also a `related!` macro, which is a generic version of the
`children!` macro that supports any relationship type:
```rust
world.spawn((
Foo,
related!(Children[
(
Bar,
related!(Children[Baz]),
),
(
Bar,
related!(Children[Baz]),
),
])
))
```
## Returning Hierarchies from Functions
Thanks to these changes, the following pattern is now possible:
```rust
fn button(text: &str, color: Color) -> impl Bundle {
(
Node {
width: Val::Px(300.),
height: Val::Px(100.),
..default()
},
BackgroundColor(color),
children![
Text::new(text),
]
)
}
fn ui() -> impl Bundle {
(
Node {
width: Val::Percent(100.0),
height: Val::Percent(100.0),
..default(),
},
children![
button("hello", BLUE),
button("world", RED),
]
)
}
// spawn from a system
fn system(mut commands: Commands) {
commands.spawn(ui());
}
// spawn directly on World
world.spawn(ui());
```
## Additional Changes and Notes
* `Bundle::from_components` has been split out into
`BundleFromComponents::from_components`, enabling us to implement
`Bundle` for types that cannot be "taken" from the ECS (such as the new
`SpawnRelatedBundle`).
* The `NoBundleEffect` trait (which implements `BundleEffect`) is
implemented for empty tuples (and tuples of empty tuples), which allows
us to constrain APIs to only accept bundles that do not have effects.
This is critical because the current batch spawn APIs cannot efficiently
apply BundleEffects in their current form (as doing so in-place could
invalidate the cached raw pointers). We could consider allocating a
buffer of the effects to be applied later, but that does have
performance implications that could offset the balance and value of the
batched APIs (and would likely require some refactors to the underlying
code). I've decided to be conservative here. We can consider relaxing
that requirement on those APIs later, but that should be done in a
followup imo.
* I've ported a few examples to illustrate real-world usage. I think in
a followup we should port all examples to the `children!` form whenever
possible (and for cases that require things like SpawnIter, use the raw
APIs).
* Some may ask "why not use the `Relationship` to spawn (ex:
`ChildOf::spawn(Foo)`) instead of the `RelationshipTarget` (ex:
`Children::spawn(Spawn(Foo))`)?". That _would_ allow us to remove the
`Spawn` wrapper. I've explicitly chosen to disallow this pattern.
`Bundle::Effect` has the ability to create _significant_ weirdness.
Things in `Bundle` position look like components. For example
`world.spawn((Foo, ChildOf::spawn(Bar)))` _looks and reads_ like Foo is
a child of Bar. `ChildOf` is in Foo's "component position" but it is not
a component on Foo. This is a huge problem. Now that `Bundle::Effect`
exists, we should be _very_ principled about keeping the "weird and
unintuitive behavior" to a minimum. Things that read like components
_should be the components they appear to be".
## Remaining Work
* The macros are currently trivially implemented using macro_rules and
are currently limited to the max tuple length. They will require a
proc_macro implementation to work around the tuple length limit.
## Next Steps
* Port the remaining examples to use `children!` where possible and raw
`Spawn` / `SpawnIter` / `SpawnWith` where the flexibility of the raw API
is required.
## Migration Guide
Existing spawn patterns will continue to work as expected.
Manual Bundle implementations now require a `BundleEffect` associated
type. Exisiting bundles would have no bundle effect, so use `()`.
Additionally `Bundle::from_components` has been moved to the new
`BundleFromComponents` trait.
```rust
// Before
unsafe impl Bundle for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
/* remaining bundle impl here */
}
// After
unsafe impl Bundle for X {
type Effect = ();
/* remaining bundle impl here */
}
unsafe impl BundleFromComponents for X {
unsafe fn from_components<T, F>(ctx: &mut T, func: &mut F) -> Self {
}
}
```
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: Gino Valente <49806985+MrGVSV@users.noreply.github.com>
Co-authored-by: Emerson Coskey <emerson@coskey.dev>
This pr uses the `extern crate self as` trick to make proc macros behave
the same way inside and outside bevy.
# Objective
- Removes noise introduced by `crate as` in the whole bevy repo.
- Fixes#17004.
- Hardens proc macro path resolution.
## TODO
- [x] `BevyManifest` needs cleanup.
- [x] Cleanup remaining `crate as`.
- [x] Add proper integration tests to the ci.
## Notes
- `cargo-manifest-proc-macros` is written by me and based/inspired by
the old `BevyManifest` implementation and
[`bkchr/proc-macro-crate`](https://github.com/bkchr/proc-macro-crate).
- What do you think about the new integration test machinery I added to
the `ci`?
More and better integration tests can be added at a later stage.
The goal of these integration tests is to simulate an actual separate
crate that uses bevy. Ideally they would lightly touch all bevy crates.
## Testing
- Needs RA test
- Needs testing from other users
- Others need to run at least `cargo run -p ci integration-test` and
verify that they work.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Didn't remove WgpuWrapper. Not sure if it's needed or not still.
## Testing
- Did you test these changes? If so, how? Example runner
- Are there any parts that need more testing? Web (portable atomics
thingy?), DXC.
## Migration Guide
- Bevy has upgraded to [wgpu
v24](https://github.com/gfx-rs/wgpu/blob/trunk/CHANGELOG.md#v2400-2025-01-15).
- When using the DirectX 12 rendering backend, the new priority system
for choosing a shader compiler is as follows:
- If the `WGPU_DX12_COMPILER` environment variable is set at runtime, it
is used
- Else if the new `statically-linked-dxc` feature is enabled, a custom
version of DXC will be statically linked into your app at compile time.
- Else Bevy will look in the app's working directory for
`dxcompiler.dll` and `dxil.dll` at runtime.
- Else if they are missing, Bevy will fall back to FXC (not recommended)
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
# Objective
- publish script copy the license files to all subcrates, meaning that
all publish are dirty. this breaks git verification of crates
- the order and list of crates to publish is manually maintained,
leading to error. cargo 1.84 is more strict and the list is currently
wrong
## Solution
- duplicate all the licenses to all crates and remove the
`--allow-dirty` flag
- instead of a manual list of crates, get it from `cargo package
--workspace`
- remove the `--no-verify` flag to... verify more things?
PR #17684 broke occlusion culling because it neglected to set the
indirect parameter offsets for the late mesh preprocessing stage if the
work item buffers were already set. This PR moves the update of those
values to a new function, `init_work_item_buffers`, which is
unconditionally called for every phase every frame.
Note that there's some complexity in order to handle the case in which
occlusion culling was enabled on one frame and disabled on the next, or
vice versa. This was necessary in order to make the occlusion culling
toggle in the `occlusion_culling` example work again.
This PR makes Bevy keep entities in bins from frame to frame if they
haven't changed. This reduces the time spent in `queue_material_meshes`
and related functions to near zero for static geometry. This patch uses
the same change tick technique that #17567 uses to detect when meshes
have changed in such a way as to require re-binning.
In order to quickly find the relevant bin for an entity when that entity
has changed, we introduce a new type of cache, the *bin key cache*. This
cache stores a mapping from main world entity ID to cached bin key, as
well as the tick of the most recent change to the entity. As we iterate
through the visible entities in `queue_material_meshes`, we check the
cache to see whether the entity needs to be re-binned. If it doesn't,
then we mark it as clean in the `valid_cached_entity_bin_keys` bit set.
If it does, then we insert it into the correct bin, and then mark the
entity as clean. At the end, all entities not marked as clean are
removed from the bins.
This patch has a dramatic effect on the rendering performance of most
benchmarks, as it effectively eliminates `queue_material_meshes` from
the profile. Note, however, that it generally simultaneously regresses
`batch_and_prepare_binned_render_phase` by a bit (not by enough to
outweigh the win, however). I believe that's because, before this patch,
`queue_material_meshes` put the bins in the CPU cache for
`batch_and_prepare_binned_render_phase` to use, while with this patch,
`batch_and_prepare_binned_render_phase` must load the bins into the CPU
cache itself.
On Caldera, this reduces the time spent in `queue_material_meshes` from
5+ ms to 0.2ms-0.3ms. Note that benchmarking on that scene is very noisy
right now because of https://github.com/bevyengine/bevy/issues/17535.
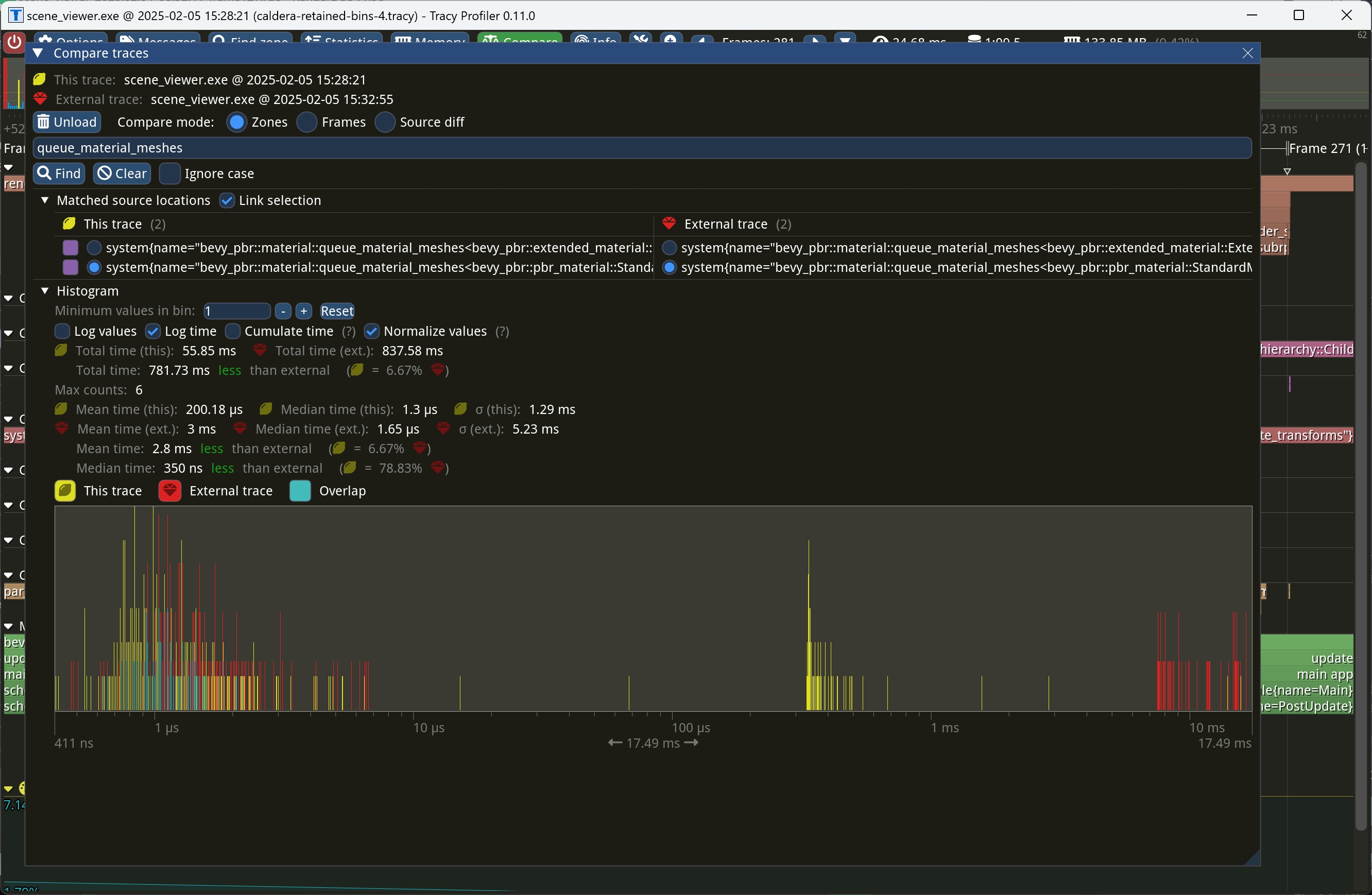
# Objective
- Make use of the new `weak_handle!` macro added in
https://github.com/bevyengine/bevy/pull/17384
## Solution
- Migrate bevy from `Handle::weak_from_u128` to the new `weak_handle!`
macro that takes a random UUID
- Deprecate `Handle::weak_from_u128`, since there are no remaining use
cases that can't also be addressed by constructing the type manually
## Testing
- `cargo run -p ci -- test`
---
## Migration Guide
Replace `Handle::weak_from_u128` with `weak_handle!` and a random UUID.
# Objective
Fixes#17662
## Solution
Moved `Item` and `fetch` from `WorldQuery` to `QueryData`, and adjusted
their implementations accordingly.
Currently, documentation related to `fetch` is written under
`WorldQuery`. It would be more appropriate to move it to the `QueryData`
documentation for clarity.
I am not very experienced with making contributions. If there are any
mistakes or areas for improvement, I would appreciate any suggestions
you may have.
## Migration Guide
The `WorldQuery::Item` type and `WorldQuery::fetch` method have been
moved to `QueryData`, as they were not useful for `QueryFilter` types.
---------
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
# Objective
Simplify and expand the API for `QueryState`.
`QueryState` has a lot of methods that mirror those on `Query`. These
are then multiplied by variants that take `&World`, `&mut World`, and
`UnsafeWorldCell`. In addition, many of them have `_manual` variants
that take `&QueryState` and avoid calling `update_archetypes()`. Not all
of the combinations exist, however, so some operations are not possible.
## Solution
Introduce methods to get a `Query` from a `QueryState`. That will reduce
duplication between the types, and ensure that the full `Query` API is
always available for `QueryState`.
Introduce methods on `Query` that consume the query to return types with
the full `'w` lifetime. This avoids issues with borrowing where things
like `query_state.query(&world).get(entity)` don't work because they
borrow from the temporary `Query`.
Finally, implement `Copy` for read-only `Query`s. `get_inner` and
`iter_inner` currently take `&self`, so changing them to consume `self`
would be a breaking change. By making `Query: Copy`, they can consume a
copy of `self` and continue to work.
The consuming methods also let us simplify the implementation of methods
on `Query`, by doing `fn foo(&self) { self.as_readonly().foo_inner() }`
and `fn foo_mut(&mut self) { self.reborrow().foo_inner() }`. That
structure makes it more difficult to accidentally extend lifetimes,
since the safe `as_readonly()` and `reborrow()` methods shrink them
appropriately. The optimizer is able to see that they are both identity
functions and inline them, so there should be no performance cost.
Note that this change would conflict with #15848. If `QueryState` is
stored as a `Cow`, then the consuming methods cannot be implemented, and
`Copy` cannot be implemented.
## Future Work
The next step is to mark the methods on `QueryState` as `#[deprecated]`,
and move the implementations into `Query`.
## Migration Guide
`Query::to_readonly` has been renamed to `Query::as_readonly`.
# Cold Specialization
## Objective
An ongoing part of our quest to retain everything in the render world,
cold-specialization aims to cache pipeline specialization so that
pipeline IDs can be recomputed only when necessary, rather than every
frame. This approach reduces redundant work in stable scenes, while
still accommodating scenarios in which materials, views, or visibility
might change, as well as unlocking future optimization work like
retaining render bins.
## Solution
Queue systems are split into a specialization system and queue system,
the former of which only runs when necessary to compute a new pipeline
id. Pipelines are invalidated using a combination of change detection
and ECS ticks.
### The difficulty with change detection
Detecting “what changed” can be tricky because pipeline specialization
depends not only on the entity’s components (e.g., mesh, material, etc.)
but also on which view (camera) it is rendering in. In other words, the
cache key for a given pipeline id is a view entity/render entity pair.
As such, it's not sufficient simply to react to change detection in
order to specialize -- an entity could currently be out of view or could
be rendered in the future in camera that is currently disabled or hasn't
spawned yet.
### Why ticks?
Ticks allow us to ensure correctness by allowing us to compare the last
time a view or entity was updated compared to the cached pipeline id.
This ensures that even if an entity was out of view or has never been
seen in a given camera before we can still correctly determine whether
it needs to be re-specialized or not.
## Testing
TODO: Tested a bunch of different examples, need to test more.
## Migration Guide
TODO
- `AssetEvents` has been moved into the `PostUpdate` schedule.
---------
Co-authored-by: Patrick Walton <pcwalton@mimiga.net>
We were calling `clear()` on the work item buffer table, which caused us
to deallocate all the CPU side buffers. This patch changes the logic to
instead just clear the buffers individually, but leave their backing
stores. This has two consequences:
1. To effectively retain work item buffers from frame to frame, we need
to key them off `RetainedViewEntity` values and not the render world
`Entity`, which is transient. This PR changes those buffers accordingly.
2. We need to clean up work item buffers that belong to views that went
away. Amusingly enough, we actually have a system,
`delete_old_work_item_buffers`, that tries to do this already, but it
wasn't doing anything because the `clear_batched_gpu_instance_buffers`
system already handled that. This patch actually makes the
`delete_old_work_item_buffers` system useful, by removing the clearing
behavior from `clear_batched_gpu_instance_buffers` and instead making
`delete_old_work_item_buffers` delete buffers corresponding to
nonexistent views.
On Bistro, this PR improves the performance of
`batch_and_prepare_binned_render_phase` from 61.2 us to 47.8 us, a 28%
speedup.

Data for the other batches is only accessed by the GPU, not the CPU, so
it's a waste of time and memory to store information relating to those
other batches.
On Bistro, this reduces time spent in
`batch_and_prepare_binned_render_phase` from 85.9 us to 61.2 us, a 40%
speedup.

# Objective
- Most of the `*MeshBuilder` classes are not implementing `Reflect`
## Solution
- Implementing `Reflect` for all `*MeshBuilder` were is possible.
- Make sure all `*MeshBuilder` implements `Default`.
- Adding new `MeshBuildersPlugin` that registers all `*MeshBuilder`
types.
## Testing
- `cargo run -p ci`
- Tested some examples like `3d_scene` just in case something was
broken.
# Objective
- Fix the atmosphere LUT parameterization in the aerial -view and
sky-view LUTs
- Correct the light accumulation according to a ray-marched reference
- Avoid negative values of the sun disk illuminance when the sun disk is
below the horizon
## Solution
- Adding a Newton's method iteration to `fast_sqrt` function
- Switched to using `fast_acos_4` for better precision of the sun angle
towards the horizon (view mu angle = 0)
- Simplified the function for mapping to and from the Sky View UV
coordinates by removing an if statement and correctly apply the method
proposed by the [Hillarie
paper](https://sebh.github.io/publications/egsr2020.pdf) detailed in
section 5.3 and 5.4.
- Replaced the `ray_dir_ws.y` term with a shadow factor in the
`sample_sun_illuminance` function that correctly approximates the sun
disk occluded by the earth from any view point
## Testing
- Ran the atmosphere and SSAO examples to make sure the shaders still
compile and run as expected.
---
## Showcase
<img width="1151" alt="showcase-img"
src="https://github.com/user-attachments/assets/de875533-42bd-41f9-9fd0-d7cc57d6e51c"
/>
---------
Co-authored-by: Emerson Coskey <emerson@coskey.dev>
# Objective
- Linking to a specific AsBindGroup attribute is hard because it doesn't
use any headers and all the docs is in a giant block
## Solution
- Make each attribute it's own sub-header so they can be easily linked
---
## Showcase
Here's what the rustdoc output looks like with this change

## Notes
I kept the bullet point so the text is still indented like before. Not
sure if we should keep that or not
Minor improvement to the render_resource doc comments; specifically, the
gpu buffer types
- makes them consistently reference each other
- reorders them to be alphabetical
- removes duplicated entries
*Occlusion culling* allows the GPU to skip the vertex and fragment
shading overhead for objects that can be quickly proved to be invisible
because they're behind other geometry. A depth prepass already
eliminates most fragment shading overhead for occluded objects, but the
vertex shading overhead, as well as the cost of testing and rejecting
fragments against the Z-buffer, is presently unavoidable for standard
meshes. We currently perform occlusion culling only for meshlets. But
other meshes, such as skinned meshes, can benefit from occlusion culling
too in order to avoid the transform and skinning overhead for unseen
meshes.
This commit adapts the same [*two-phase occlusion culling*] technique
that meshlets use to Bevy's standard 3D mesh pipeline when the new
`OcclusionCulling` component, as well as the `DepthPrepass` component,
are present on the camera. It has these steps:
1. *Early depth prepass*: We use the hierarchical Z-buffer from the
previous frame to cull meshes for the initial depth prepass, effectively
rendering only the meshes that were visible in the last frame.
2. *Early depth downsample*: We downsample the depth buffer to create
another hierarchical Z-buffer, this time with the current view
transform.
3. *Late depth prepass*: We use the new hierarchical Z-buffer to test
all meshes that weren't rendered in the early depth prepass. Any meshes
that pass this check are rendered.
4. *Late depth downsample*: Again, we downsample the depth buffer to
create a hierarchical Z-buffer in preparation for the early depth
prepass of the next frame. This step is done after all the rendering, in
order to account for custom phase items that might write to the depth
buffer.
Note that this patch has no effect on the per-mesh CPU overhead for
occluded objects, which remains high for a GPU-driven renderer due to
the lack of `cold-specialization` and retained bins. If
`cold-specialization` and retained bins weren't on the horizon, then a
more traditional approach like potentially visible sets (PVS) or low-res
CPU rendering would probably be more efficient than the GPU-driven
approach that this patch implements for most scenes. However, at this
point the amount of effort required to implement a PVS baking tool or a
low-res CPU renderer would probably be greater than landing
`cold-specialization` and retained bins, and the GPU driven approach is
the more modern one anyway. It does mean that the performance
improvements from occlusion culling as implemented in this patch *today*
are likely to be limited, because of the high CPU overhead for occluded
meshes.
Note also that this patch currently doesn't implement occlusion culling
for 2D objects or shadow maps. Those can be addressed in a follow-up.
Additionally, note that the techniques in this patch require compute
shaders, which excludes support for WebGL 2.
This PR is marked experimental because of known precision issues with
the downsampling approach when applied to non-power-of-two framebuffer
sizes (i.e. most of them). These precision issues can, in rare cases,
cause objects to be judged occluded that in fact are not. (I've never
seen this in practice, but I know it's possible; it tends to be likelier
to happen with small meshes.) As a follow-up to this patch, we desire to
switch to the [SPD-based hi-Z buffer shader from the Granite engine],
which doesn't suffer from these problems, at which point we should be
able to graduate this feature from experimental status. I opted not to
include that rewrite in this patch for two reasons: (1) @JMS55 is
planning on doing the rewrite to coincide with the new availability of
image atomic operations in Naga; (2) to reduce the scope of this patch.
A new example, `occlusion_culling`, has been added. It demonstrates
objects becoming quickly occluded and disoccluded by dynamic geometry
and shows the number of objects that are actually being rendered. Also,
a new `--occlusion-culling` switch has been added to `scene_viewer`, in
order to make it easy to test this patch with large scenes like Bistro.
[*two-phase occlusion culling*]:
https://medium.com/@mil_kru/two-pass-occlusion-culling-4100edcad501
[Aaltonen SIGGRAPH 2015]:
https://www.advances.realtimerendering.com/s2015/aaltonenhaar_siggraph2015_combined_final_footer_220dpi.pdf
[Some literature]:
https://gist.github.com/reduz/c5769d0e705d8ab7ac187d63be0099b5?permalink_comment_id=5040452#gistcomment-5040452
[SPD-based hi-Z buffer shader from the Granite engine]:
https://github.com/Themaister/Granite/blob/master/assets/shaders/post/hiz.comp
## Migration guide
* When enqueuing a custom mesh pipeline, work item buffers are now
created with
`bevy::render::batching::gpu_preprocessing::get_or_create_work_item_buffer`,
not `PreprocessWorkItemBuffers::new`. See the
`specialized_mesh_pipeline` example.
## Showcase
Occlusion culling example:

Bistro zoomed out, before occlusion culling:

Bistro zoomed out, after occlusion culling:

In this scene, occlusion culling reduces the number of meshes Bevy has
to render from 1591 to 585.
# Objective
Implement `Eq` and `Hash` for the `BindGroup` and `BindGroupLayout`
wrappers.
## Solution
Implement based on the same assumption that the ID is unique, for
consistency with `PartialEq`.
## Testing
None; this should be straightforward. If there's an issue that would be
a design one.
Implement procedural atmospheric scattering from [Sebastien Hillaire's
2020 paper](https://sebh.github.io/publications/egsr2020.pdf). This
approach should scale well even down to mobile hardware, and is
physically accurate.
## Co-author: @mate-h
He helped massively with getting this over the finish line, ensuring
everything was physically correct, correcting several places where I had
misunderstood or misapplied the paper, and improving the performance in
several places as well. Thanks!
## Credits
@aevyrie: helped find numerous bugs and improve the example to best show
off this feature :)
Built off of @mtsr's original branch, which handled the transmittance
lut (arguably the most important part)
## Showcase:


## For followup
- Integrate with pcwalton's volumetrics code
- refactor/reorganize for better integration with other effects
- have atmosphere transmittance affect directional lights
- add support for generating skybox/environment map
---------
Co-authored-by: Emerson Coskey <56370779+EmersonCoskey@users.noreply.github.com>
Co-authored-by: atlv <email@atlasdostal.com>
Co-authored-by: JMS55 <47158642+JMS55@users.noreply.github.com>
Co-authored-by: Emerson Coskey <coskey@emerlabs.net>
Co-authored-by: Máté Homolya <mate.homolya@gmail.com>
# Objective
- Contributes to #16877
## Solution
- Moved `hashbrown`, `foldhash`, and related types out of `bevy_utils`
and into `bevy_platform_support`
- Refactored the above to match the layout of these types in `std`.
- Updated crates as required.
## Testing
- CI
---
## Migration Guide
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::hash`:
- `FixedState`
- `DefaultHasher`
- `RandomState`
- `FixedHasher`
- `Hashed`
- `PassHash`
- `PassHasher`
- `NoOpHash`
- The following items were moved out of `bevy_utils` and into
`bevy_platform_support::collections`:
- `HashMap`
- `HashSet`
- `bevy_utils::hashbrown` has been removed. Instead, import from
`bevy_platform_support::collections` _or_ take a dependency on
`hashbrown` directly.
- `bevy_utils::Entry` has been removed. Instead, import from
`bevy_platform_support::collections::hash_map` or
`bevy_platform_support::collections::hash_set` as appropriate.
- All of the above equally apply to `bevy::utils` and
`bevy::platform_support`.
## Notes
- I left `PreHashMap`, `PreHashMapExt`, and `TypeIdMap` in `bevy_utils`
as they might be candidates for micro-crating. They can always be moved
into `bevy_platform_support` at a later date if desired.
# Objective
- Make the function signature for `ComponentHook` less verbose
## Solution
- Refactored `Entity`, `ComponentId`, and `Option<&Location>` into a new
`HookContext` struct.
## Testing
- CI
---
## Migration Guide
Update the function signatures for your component hooks to only take 2
arguments, `world` and `context`. Note that because `HookContext` is
plain data with all members public, you can use de-structuring to
simplify migration.
```rust
// Before
fn my_hook(
mut world: DeferredWorld,
entity: Entity,
component_id: ComponentId,
) { ... }
// After
fn my_hook(
mut world: DeferredWorld,
HookContext { entity, component_id, caller }: HookContext,
) { ... }
```
Likewise, if you were discarding certain parameters, you can use `..` in
the de-structuring:
```rust
// Before
fn my_hook(
mut world: DeferredWorld,
entity: Entity,
_: ComponentId,
) { ... }
// After
fn my_hook(
mut world: DeferredWorld,
HookContext { entity, .. }: HookContext,
) { ... }
```
# Objective
Fixes#14708
Also fixes some commands not updating tracked location.
## Solution
`ObserverTrigger` has a new `caller` field with the
`track_change_detection` feature;
hooks take an additional caller parameter (which is `Some(…)` or `None`
depending on the feature).
## Testing
See the new tests in `src/observer/mod.rs`
---
## Showcase
Observers now know from where they were triggered (if
`track_change_detection` is enabled):
```rust
world.observe(move |trigger: Trigger<OnAdd, Foo>| {
println!("Added Foo from {}", trigger.caller());
});
```
## Migration
- hooks now take an additional `Option<&'static Location>` argument
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
This commit makes Bevy use change detection to only update
`RenderMaterialInstances` and `RenderMeshMaterialIds` when meshes have
been added, changed, or removed. `extract_mesh_materials`, the system
that extracts these, now follows the pattern that
`extract_meshes_for_gpu_building` established.
This improves frame time of `many_cubes` from 3.9ms to approximately
3.1ms, which slightly surpasses the performance of Bevy 0.14.
(Resubmitted from #16878 to clean up history.)

---------
Co-authored-by: Charlotte McElwain <charlotte.c.mcelwain@gmail.com>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
`bevy_ecs`'s `system` module is something of a grab bag, and *very*
large. This is particularly true for the `system_param` module, which is
more than 2k lines long!
While it could be defensible to put `Res` and `ResMut` there (lol no
they're in change_detection.rs, obviously), it doesn't make any sense to
put the `Resource` trait there. This is confusing to navigate (and
painful to work on and review).
## Solution
- Create a root level `bevy_ecs/resource.rs` module to mirror
`bevy_ecs/component.rs`
- move the `Resource` trait to that module
- move the `Resource` derive macro to that module as well (Rust really
likes when you pun on the names of the derive macro and trait and put
them in the same path)
- fix all of the imports
## Notes to reviewers
- We could probably move more stuff into here, but I wanted to keep this
PR as small as possible given the absurd level of import changes.
- This PR is ground work for my upcoming attempts to store resource data
on components (resources-as-entities). Splitting this code out will make
the work and review a bit easier, and is the sort of overdue refactor
that's good to do as part of more meaningful work.
## Testing
cargo build works!
## Migration Guide
`bevy_ecs::system::Resource` has been moved to
`bevy_ecs::resource::Resource`.
Fixes#17412
## Objective
`Parent` uses the "has a X" naming convention. There is increasing
sentiment that we should use the "is a X" naming convention for
relationships (following #17398). This leaves `Children` as-is because
there is prevailing sentiment that `Children` is clearer than `ParentOf`
in many cases (especially when treating it like a collection).
This renames `Parent` to `ChildOf`.
This is just the implementation PR. To discuss the path forward, do so
in #17412.
## Migration Guide
- The `Parent` component has been renamed to `ChildOf`.
# Objective
Diagnostics for labels don't suggest how to best implement them.
```
error[E0277]: the trait bound `Label: ScheduleLabel` is not satisfied
--> src/main.rs:15:35
|
15 | let mut sched = Schedule::new(Label);
| ------------- ^^^^^ the trait `ScheduleLabel` is not implemented for `Label`
| |
| required by a bound introduced by this call
|
= help: the trait `ScheduleLabel` is implemented for `Interned<(dyn ScheduleLabel + 'static)>`
note: required by a bound in `bevy_ecs::schedule::Schedule::new`
--> /home/vj/workspace/rust/bevy/crates/bevy_ecs/src/schedule/schedule.rs:297:28
|
297 | pub fn new(label: impl ScheduleLabel) -> Self {
| ^^^^^^^^^^^^^ required by this bound in `Schedule::new`
```
## Solution
`diagnostics::on_unimplemented` and `diagnostics::do_not_recommend`
## Showcase
New error message:
```
error[E0277]: the trait bound `Label: ScheduleLabel` is not satisfied
--> src/main.rs:15:35
|
15 | let mut sched = Schedule::new(Label);
| ------------- ^^^^^ the trait `ScheduleLabel` is not implemented for `Label`
| |
| required by a bound introduced by this call
|
= note: consider annotating `Label` with `#[derive(ScheduleLabel)]`
note: required by a bound in `bevy_ecs::schedule::Schedule::new`
--> /home/vj/workspace/rust/bevy/crates/bevy_ecs/src/schedule/schedule.rs:297:28
|
297 | pub fn new(label: impl ScheduleLabel) -> Self {
| ^^^^^^^^^^^^^ required by this bound in `Schedule::new`
```
# Objective
The existing `RelationshipSourceCollection` uses `Vec` as the only
possible backing for our relationships. While a reasonable choice,
benchmarking use cases might reveal that a different data type is better
or faster.
For example:
- Not all relationships require a stable ordering between the
relationship sources (i.e. children). In cases where we a) have many
such relations and b) don't care about the ordering between them, a hash
set is likely a better datastructure than a `Vec`.
- The number of children-like entities may be small on average, and a
`smallvec` may be faster
## Solution
- Implement `RelationshipSourceCollection` for `EntityHashSet`, our
custom entity-optimized `HashSet`.
-~~Implement `DoubleEndedIterator` for `EntityHashSet` to make things
compile.~~
- This implementation was cursed and very surprising.
- Instead, by moving the iterator type on `RelationshipSourceCollection`
from an erased RPTIT to an explicit associated type we can add a trait
bound on the offending methods!
- Implement `RelationshipSourceCollection` for `SmallVec`
## Testing
I've added a pair of new tests to make sure this pattern compiles
successfully in practice!
## Migration Guide
`EntityHashSet` and `EntityHashMap` are no longer re-exported in
`bevy_ecs::entity` directly. If you were not using `bevy_ecs` / `bevy`'s
`prelude`, you can access them through their now-public modules,
`hash_set` and `hash_map` instead.
## Notes to reviewers
The `EntityHashSet::Iter` type needs to be public for this impl to be
allowed. I initially renamed it to something that wasn't ambiguous and
re-exported it, but as @Victoronz pointed out, that was somewhat
unidiomatic.
In
1a8564898f,
I instead made the `entity_hash_set` public (and its `entity_hash_set`)
sister public, and removed the re-export. I prefer this design (give me
module docs please), but it leads to a lot of churn in this PR.
Let me know which you'd prefer, and if you'd like me to split that
change out into its own micro PR.
# Objective
- Contributes to #16877
## Solution
- Initial creation of `bevy_platform_support` crate.
- Moved `bevy_utils::Instant` into new `bevy_platform_support` crate.
- Moved `portable-atomic`, `portable-atomic-util`, and
`critical-section` into new `bevy_platform_support` crate.
## Testing
- CI
---
## Showcase
Instead of needing code like this to import an `Arc`:
```rust
#[cfg(feature = "portable-atomic")]
use portable_atomic_util::Arc;
#[cfg(not(feature = "portable-atomic"))]
use alloc::sync::Arc;
```
We can now use:
```rust
use bevy_platform_support::sync::Arc;
```
This applies to many other types, but the goal is overall the same:
allowing crates to use `std`-like types without the boilerplate of
conditional compilation and platform-dependencies.
## Migration Guide
- Replace imports of `bevy_utils::Instant` with
`bevy_platform_support::time::Instant`
- Replace imports of `bevy::utils::Instant` with
`bevy::platform_support::time::Instant`
## Notes
- `bevy_platform_support` hasn't been reserved on `crates.io`
- ~~`bevy_platform_support` is not re-exported from `bevy` at this time.
It may be worthwhile exporting this crate, but I am unsure of a
reasonable name to export it under (`platform_support` may be a bit
wordy for user-facing).~~
- I've included an implementation of `Instant` which is suitable for
`no_std` platforms that are not Wasm for the sake of eliminating feature
gates around its use. It may be a controversial inclusion, so I'm happy
to remove it if required.
- There are many other items (`spin`, `bevy_utils::Sync(Unsafe)Cell`,
etc.) which should be added to this crate. I have kept the initial scope
small to demonstrate utility without making this too unwieldy.
---------
Co-authored-by: TimJentzsch <TimJentzsch@users.noreply.github.com>
Co-authored-by: Chris Russell <8494645+chescock@users.noreply.github.com>
Co-authored-by: François Mockers <francois.mockers@vleue.com>
This adds support for one-to-many non-fragmenting relationships (with
planned paths for fragmenting and non-fragmenting many-to-many
relationships). "Non-fragmenting" means that entities with the same
relationship type, but different relationship targets, are not forced
into separate tables (which would cause "table fragmentation").
Functionally, this fills a similar niche as the current Parent/Children
system. The biggest differences are:
1. Relationships have simpler internals and significantly improved
performance and UX. Commands and specialized APIs are no longer
necessary to keep everything in sync. Just spawn entities with the
relationship components you want and everything "just works".
2. Relationships are generalized. Bevy can provide additional built in
relationships, and users can define their own.
**REQUEST TO REVIEWERS**: _please don't leave top level comments and
instead comment on specific lines of code. That way we can take
advantage of threaded discussions. Also dont leave comments simply
pointing out CI failures as I can read those just fine._
## Built on top of what we have
Relationships are implemented on top of the Bevy ECS features we already
have: components, immutability, and hooks. This makes them immediately
compatible with all of our existing (and future) APIs for querying,
spawning, removing, scenes, reflection, etc. The fewer specialized APIs
we need to build, maintain, and teach, the better.
## Why focus on one-to-many non-fragmenting first?
1. This allows us to improve Parent/Children relationships immediately,
in a way that is reasonably uncontroversial. Switching our hierarchy to
fragmenting relationships would have significant performance
implications. ~~Flecs is heavily considering a switch to non-fragmenting
relations after careful considerations of the performance tradeoffs.~~
_(Correction from @SanderMertens: Flecs is implementing non-fragmenting
storage specialized for asset hierarchies, where asset hierarchies are
many instances of small trees that have a well defined structure)_
2. Adding generalized one-to-many relationships is currently a priority
for the [Next Generation Scene / UI
effort](https://github.com/bevyengine/bevy/discussions/14437).
Specifically, we're interested in building reactions and observers on
top.
## The changes
This PR does the following:
1. Adds a generic one-to-many Relationship system
3. Ports the existing Parent/Children system to Relationships, which now
lives in `bevy_ecs::hierarchy`. The old `bevy_hierarchy` crate has been
removed.
4. Adds on_despawn component hooks
5. Relationships can opt-in to "despawn descendants" behavior, meaning
that the entire relationship hierarchy is despawned when
`entity.despawn()` is called. The built in Parent/Children hierarchies
enable this behavior, and `entity.despawn_recursive()` has been removed.
6. `world.spawn` now applies commands after spawning. This ensures that
relationship bookkeeping happens immediately and removes the need to
manually flush. This is in line with the equivalent behaviors recently
added to the other APIs (ex: insert).
7. Removes the ValidParentCheckPlugin (system-driven / poll based) in
favor of a `validate_parent_has_component` hook.
## Using Relationships
The `Relationship` trait looks like this:
```rust
pub trait Relationship: Component + Sized {
type RelationshipSources: RelationshipSources<Relationship = Self>;
fn get(&self) -> Entity;
fn from(entity: Entity) -> Self;
}
```
A relationship is a component that:
1. Is a simple wrapper over a "target" Entity.
2. Has a corresponding `RelationshipSources` component, which is a
simple wrapper over a collection of entities. Every "target entity"
targeted by a "source entity" with a `Relationship` has a
`RelationshipSources` component, which contains every "source entity"
that targets it.
For example, the `Parent` component (as it currently exists in Bevy) is
the `Relationship` component and the entity containing the Parent is the
"source entity". The entity _inside_ the `Parent(Entity)` component is
the "target entity". And that target entity has a `Children` component
(which implements `RelationshipSources`).
In practice, the Parent/Children relationship looks like this:
```rust
#[derive(Relationship)]
#[relationship(relationship_sources = Children)]
pub struct Parent(pub Entity);
#[derive(RelationshipSources)]
#[relationship_sources(relationship = Parent)]
pub struct Children(Vec<Entity>);
```
The Relationship and RelationshipSources derives automatically implement
Component with the relevant configuration (namely, the hooks necessary
to keep everything in sync).
The most direct way to add relationships is to spawn entities with
relationship components:
```rust
let a = world.spawn_empty().id();
let b = world.spawn(Parent(a)).id();
assert_eq!(world.entity(a).get::<Children>().unwrap(), &[b]);
```
There are also convenience APIs for spawning more than one entity with
the same relationship:
```rust
world.spawn_empty().with_related::<Children>(|s| {
s.spawn_empty();
s.spawn_empty();
})
```
The existing `with_children` API is now a simpler wrapper over
`with_related`. This makes this change largely non-breaking for existing
spawn patterns.
```rust
world.spawn_empty().with_children(|s| {
s.spawn_empty();
s.spawn_empty();
})
```
There are also other relationship APIs, such as `add_related` and
`despawn_related`.
## Automatic recursive despawn via the new on_despawn hook
`RelationshipSources` can opt-in to "despawn descendants" behavior,
which will despawn all related entities in the relationship hierarchy:
```rust
#[derive(RelationshipSources)]
#[relationship_sources(relationship = Parent, despawn_descendants)]
pub struct Children(Vec<Entity>);
```
This means that `entity.despawn_recursive()` is no longer required.
Instead, just use `entity.despawn()` and the relevant related entities
will also be despawned.
To despawn an entity _without_ despawning its parent/child descendants,
you should remove the `Children` component first, which will also remove
the related `Parent` components:
```rust
entity
.remove::<Children>()
.despawn()
```
This builds on the on_despawn hook introduced in this PR, which is fired
when an entity is despawned (before other hooks).
## Relationships are the source of truth
`Relationship` is the _single_ source of truth component.
`RelationshipSources` is merely a reflection of what all the
`Relationship` components say. By embracing this, we are able to
significantly improve the performance of the system as a whole. We can
rely on component lifecycles to protect us against duplicates, rather
than needing to scan at runtime to ensure entities don't already exist
(which results in quadratic runtime). A single source of truth gives us
constant-time inserts. This does mean that we cannot directly spawn
populated `Children` components (or directly add or remove entities from
those components). I personally think this is a worthwhile tradeoff,
both because it makes the performance much better _and_ because it means
theres exactly one way to do things (which is a philosophy we try to
employ for Bevy APIs).
As an aside: treating both sides of the relationship as "equivalent
source of truth relations" does enable building simple and flexible
many-to-many relationships. But this introduces an _inherent_ need to
scan (or hash) to protect against duplicates.
[`evergreen_relations`](https://github.com/EvergreenNest/evergreen_relations)
has a very nice implementation of the "symmetrical many-to-many"
approach. Unfortunately I think the performance issues inherent to that
approach make it a poor choice for Bevy's default relationship system.
## Followup Work
* Discuss renaming `Parent` to `ChildOf`. I refrained from doing that in
this PR to keep the diff reasonable, but I'm personally biased toward
this change (and using that naming pattern generally for relationships).
* [Improved spawning
ergonomics](https://github.com/bevyengine/bevy/discussions/16920)
* Consider adding relationship observers/triggers for "relationship
targets" whenever a source is added or removed. This would replace the
current "hierarchy events" system, which is unused upstream but may have
existing users downstream. I think triggers are the better fit for this
than a buffered event queue, and would prefer not to add that back.
* Fragmenting relations: My current idea hinges on the introduction of
"value components" (aka: components whose type _and_ value determines
their ComponentId, via something like Hashing / PartialEq). By labeling
a Relationship component such as `ChildOf(Entity)` as a "value
component", `ChildOf(e1)` and `ChildOf(e2)` would be considered
"different components". This makes the transition between fragmenting
and non-fragmenting a single flag, and everything else continues to work
as expected.
* Many-to-many support
* Non-fragmenting: We can expand Relationship to be a list of entities
instead of a single entity. I have largely already written the code for
this.
* Fragmenting: With the "value component" impl mentioned above, we get
many-to-many support "for free", as it would allow inserting multiple
copies of a Relationship component with different target entities.
Fixes#3742 (If this PR is merged, I think we should open more targeted
followup issues for the work above, with a fresh tracking issue free of
the large amount of less-directed historical context)
Fixes#17301Fixes#12235Fixes#15299Fixes#15308
## Migration Guide
* Replace `ChildBuilder` with `ChildSpawnerCommands`.
* Replace calls to `.set_parent(parent_id)` with
`.insert(Parent(parent_id))`.
* Replace calls to `.replace_children()` with `.remove::<Children>()`
followed by `.add_children()`. Note that you'll need to manually despawn
any children that are not carried over.
* Replace calls to `.despawn_recursive()` with `.despawn()`.
* Replace calls to `.despawn_descendants()` with
`.despawn_related::<Children>()`.
* If you have any calls to `.despawn()` which depend on the children
being preserved, you'll need to remove the `Children` component first.
---------
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
Fixes https://github.com/bevyengine/bevy/issues/17111
## Solution
Move `#![warn(clippy::allow_attributes,
clippy::allow_attributes_without_reason)]` to the workspace `Cargo.toml`
## Testing
Lots of CI testing, and local testing too.
---------
Co-authored-by: Benjamin Brienen <benjamin.brienen@outlook.com>
This commit allows Bevy to use `multi_draw_indirect_count` for drawing
meshes. The `multi_draw_indirect_count` feature works just like
`multi_draw_indirect`, but it takes the number of indirect parameters
from a GPU buffer rather than specifying it on the CPU.
Currently, the CPU constructs the list of indirect draw parameters with
the instance count for each batch set to zero, uploads the resulting
buffer to the GPU, and dispatches a compute shader that bumps the
instance count for each mesh that survives culling. Unfortunately, this
is inefficient when we support `multi_draw_indirect_count`. Draw
commands corresponding to meshes for which all instances were culled
will remain present in the list when calling
`multi_draw_indirect_count`, causing overhead. Proper use of
`multi_draw_indirect_count` requires eliminating these empty draw
commands.
To address this inefficiency, this PR makes Bevy fully construct the
indirect draw commands on the GPU instead of on the CPU. Instead of
writing instance counts to the draw command buffer, the mesh
preprocessing shader now writes them to a separate *indirect metadata
buffer*. A second compute dispatch known as the *build indirect
parameters* shader runs after mesh preprocessing and converts the
indirect draw metadata into actual indirect draw commands for the GPU.
The build indirect parameters shader operates on a batch at a time,
rather than an instance at a time, and as such each thread writes only 0
or 1 indirect draw parameters, simplifying the current logic in
`mesh_preprocessing`, which currently has to have special cases for the
first mesh in each batch. The build indirect parameters shader emits
draw commands in a tightly packed manner, enabling maximally efficient
use of `multi_draw_indirect_count`.
Along the way, this patch switches mesh preprocessing to dispatch one
compute invocation per render phase per view, instead of dispatching one
compute invocation per view. This is preparation for two-phase occlusion
culling, in which we will have two mesh preprocessing stages. In that
scenario, the first mesh preprocessing stage must only process opaque
and alpha tested objects, so the work items must be separated into those
that are opaque or alpha tested and those that aren't. Thus this PR
splits out the work items into a separate buffer for each phase. As this
patch rewrites so much of the mesh preprocessing infrastructure, it was
simpler to just fold the change into this patch instead of deferring it
to the forthcoming occlusion culling PR.
Finally, this patch changes mesh preprocessing so that it runs
separately for indexed and non-indexed meshes. This is because draw
commands for indexed and non-indexed meshes have different sizes and
layouts. *The existing code is actually broken for non-indexed meshes*,
as it attempts to overlay the indirect parameters for non-indexed meshes
on top of those for indexed meshes. Consequently, right now the
parameters will be read incorrectly when multiple non-indexed meshes are
multi-drawn together. *This is a bug fix* and, as with the change to
dispatch phases separately noted above, was easiest to include in this
patch as opposed to separately.
## Migration Guide
* Systems that add custom phase items now need to populate the indirect
drawing-related buffers. See the `specialized_mesh_pipeline` example for
an example of how this is done.