# Objective
fix#9605
spotlight culling uses an incorrect cluster aabb for orthographic
projections: it does not take into account the near and far cluster
bounds at all.
## Solution
use z_near and z_far to determine cluster aabb in orthographic mode.
i'm not 100% sure this is the only change that's needed, but i am sure
this change is needed, and the example seems to work well now
(CLUSTERED_FORWARD_DEBUG_CLUSTER_LIGHT_COMPLEXITY shows good bounds
around the cone for a variety of orthographic setups).
# Objective
Webgl2 broke when pcf was merged.
Fixes#10048
## Solution
Change the `textureSampleCompareLevel` in shadow_sampling.wgsl to
`textureSampleCompare` to make it work again.
# Objective
Currently, the only way for custom components that participate in
rendering to opt into the higher-performance extraction method in #9903
is to implement the `RenderInstances` data structure and the extraction
logic manually. This is inconvenient compared to the `ExtractComponent`
API.
## Solution
This commit creates a new `RenderInstance` trait that mirrors the
existing `ExtractComponent` method but uses the higher-performance
approach that #9903 uses. Additionally, `RenderInstance` is more
flexible than `ExtractComponent`, because it can extract multiple
components at once. This makes high-performance rendering components
essentially as easy to write as the existing ones based on component
extraction.
---
## Changelog
### Added
A new `RenderInstance` trait is available mirroring `ExtractComponent`,
but using a higher-performance method to extract one or more components
to the render world. If you have custom components that rendering takes
into account, you may consider migration from `ExtractComponent` to
`RenderInstance` for higher performance.
# Objective
- Improve antialiasing for non-point light shadow edges.
- Very partially addresses
https://github.com/bevyengine/bevy/issues/3628.
## Solution
- Implements "The Witness"'s shadow map sampling technique.
- Ported from @superdump's old branch, all credit to them :)
- Implements "Call of Duty: Advanced Warfare"'s stochastic shadow map
sampling technique when the velocity prepass is enabled, for use with
TAA.
- Uses interleaved gradient noise to generate a random angle, and then
averages 8 samples in a spiral pattern, rotated by the random angle.
- I also tried spatiotemporal blue noise, but it was far too noisy to be
filtered by TAA alone. In the future, we should try spatiotemporal blue
noise + a specialized shadow denoiser such as
https://gpuopen.com/fidelityfx-denoiser/#shadow. This approach would
also be useful for hybrid rasterized applications with raytraced
shadows.
- The COD presentation has an interesting temporal dithering of the
noise for use with temporal supersampling that we should revisit when we
get DLSS/FSR/other TSR.
---
## Changelog
* Added `ShadowFilteringMethod`. Improved directional light and
spotlight shadow edges to be less aliased.
## Migration Guide
* Shadows cast by directional lights or spotlights now have smoother
edges. To revert to the old behavior, add
`ShadowFilteringMethod::Hardware2x2` to your cameras.
---------
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Daniel Chia <danstryder@gmail.com>
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Brandon Dyer <brandondyer64@gmail.com>
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: Elabajaba <Elabajaba@users.noreply.github.com>
Co-authored-by: IceSentry <IceSentry@users.noreply.github.com>
# Objective
https://github.com/bevyengine/bevy/pull/7328 introduced an API to
override the global wireframe config. I believe it is flawed for a few
reasons.
This PR uses a non-breaking API. Instead of making the `Wireframe` an
enum I introduced the `NeverRenderWireframe` component. Here's the
reason why I think this is better:
- Easier to migrate since it doesn't change the old behaviour.
Essentially nothing to migrate. Right now this PR is a breaking change
but I don't think it has to be.
- It's similar to other "per mesh" rendering features like
NotShadowCaster/NotShadowReceiver
- It doesn't force new users to also think about global vs not global if
all they want is to render a wireframe
- This would also let you filter at the query definition level instead
of filtering when running the query
## Solution
- Introduce a `NeverRenderWireframe` component that ignores the global
config
---
## Changelog
- Added a `NeverRenderWireframe` component that ignores the global
`WireframeConfig`
# Objective
Allow the user to choose between "Add wireframes to these specific
entities" or "Add wireframes to everything _except_ these specific
entities".
Fixes#7309
# Solution
Make the `Wireframe` component act like an override to the global
configuration.
Having `global` set to `false`, and adding a `Wireframe` with `enable:
true` acts exactly as before.
But now the opposite is also possible: Set `global` to `true` and add a
`Wireframe` with `enable: false` will draw wireframes for everything
_except_ that entity.
Updated the example to show how overriding the global config works.
Conventionally, the second UV map (`TEXCOORD1`, `UV1`) is used for
lightmap UVs. This commit allows Bevy to import them, so that a custom
shader that applies lightmaps can use those UVs if desired.
Note that this doesn't actually apply lightmaps to Bevy meshes; that
will be a followup. It does, however, open the door to future Bevy
plugins that implement baked global illumination.
## Changelog
### Added
The Bevy glTF loader now imports a second UV channel (`TEXCOORD1`,
`UV1`) from meshes if present. This can be used by custom shaders to
implement lightmapping.
# Objective
`Has<T>` was added to bevy_ecs, but we're still using the
`Option<With<T>>` pattern in multiple locations.
## Solution
Replace them with `Has<T>`.
# Objective
`extract_meshes` can easily be one of the most expensive operations in
the blocking extract schedule for 3D apps. It also has no fundamentally
serialized parts and can easily be run across multiple threads. Let's
speed it up by parallelizing it!
## Solution
Use the `ThreadLocal<Cell<Vec<T>>>` approach utilized by #7348 in
conjunction with `Query::par_iter` to build a set of thread-local
queues, and collect them after going wide.
## Performance
Using `cargo run --profile stress-test --features trace_tracy --example
many_cubes`. Yellow is this PR. Red is main.
`extract_meshes`:
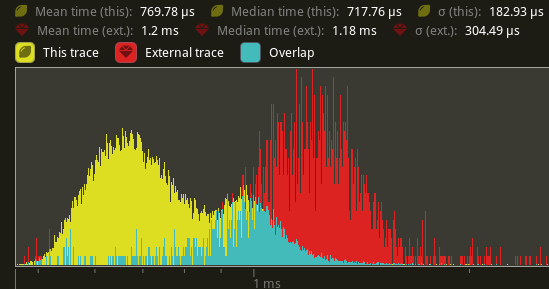
An average reduction from 1.2ms to 770us is seen, a 41.6% improvement.
Note: this is still not including #9950's changes, so this may actually
result in even faster speedups once that's merged in.
# Objective
- Improve rendering performance, particularly by avoiding the large
system commands costs of using the ECS in the way that the render world
does.
## Solution
- Define `EntityHasher` that calculates a hash from the
`Entity.to_bits()` by `i | (i.wrapping_mul(0x517cc1b727220a95) << 32)`.
`0x517cc1b727220a95` is something like `u64::MAX / N` for N that gives a
value close to π and that works well for hashing. Thanks for @SkiFire13
for the suggestion and to @nicopap for alternative suggestions and
discussion. This approach comes from `rustc-hash` (a.k.a. `FxHasher`)
with some tweaks for the case of hashing an `Entity`. `FxHasher` and
`SeaHasher` were also tested but were significantly slower.
- Define `EntityHashMap` type that uses the `EntityHashser`
- Use `EntityHashMap<Entity, T>` for render world entity storage,
including:
- `RenderMaterialInstances` - contains the `AssetId<M>` of the material
associated with the entity. Also for 2D.
- `RenderMeshInstances` - contains mesh transforms, flags and properties
about mesh entities. Also for 2D.
- `SkinIndices` and `MorphIndices` - contains the skin and morph index
for an entity, respectively
- `ExtractedSprites`
- `ExtractedUiNodes`
## Benchmarks
All benchmarks have been conducted on an M1 Max connected to AC power.
The tests are run for 1500 frames. The 1000th frame is captured for
comparison to check for visual regressions. There were none.
### 2D Meshes
`bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d`
#### `--ordered-z`
This test spawns the 2D meshes with z incrementing back to front, which
is the ideal arrangement allocation order as it matches the sorted
render order which means lookups have a high cache hit rate.
<img width="1112" alt="Screenshot 2023-09-27 at 07 50 45"
src="https://github.com/bevyengine/bevy/assets/302146/e140bc98-7091-4a3b-8ae1-ab75d16d2ccb">
-39.1% median frame time.
#### Random
This test spawns the 2D meshes with random z. This not only makes the
batching and transparent 2D pass lookups get a lot of cache misses, it
also currently means that the meshes are almost certain to not be
batchable.
<img width="1108" alt="Screenshot 2023-09-27 at 07 51 28"
src="https://github.com/bevyengine/bevy/assets/302146/29c2e813-645a-43ce-982a-55df4bf7d8c4">
-7.2% median frame time.
### 3D Meshes
`many_cubes --benchmark`
<img width="1112" alt="Screenshot 2023-09-27 at 07 51 57"
src="https://github.com/bevyengine/bevy/assets/302146/1a729673-3254-4e2a-9072-55e27c69f0fc">
-7.7% median frame time.
### Sprites
**NOTE: On `main` sprites are using `SparseSet<Entity, T>`!**
`bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite`
#### `--ordered-z`
This test spawns the sprites with z incrementing back to front, which is
the ideal arrangement allocation order as it matches the sorted render
order which means lookups have a high cache hit rate.
<img width="1116" alt="Screenshot 2023-09-27 at 07 52 31"
src="https://github.com/bevyengine/bevy/assets/302146/bc8eab90-e375-4d31-b5cd-f55f6f59ab67">
+13.0% median frame time.
#### Random
This test spawns the sprites with random z. This makes the batching and
transparent 2D pass lookups get a lot of cache misses.
<img width="1109" alt="Screenshot 2023-09-27 at 07 53 01"
src="https://github.com/bevyengine/bevy/assets/302146/22073f5d-99a7-49b0-9584-d3ac3eac3033">
+0.6% median frame time.
### UI
**NOTE: On `main` UI is using `SparseSet<Entity, T>`!**
`many_buttons`
<img width="1111" alt="Screenshot 2023-09-27 at 07 53 26"
src="https://github.com/bevyengine/bevy/assets/302146/66afd56d-cbe4-49e7-8b64-2f28f6043d85">
+15.1% median frame time.
## Alternatives
- Cart originally suggested trying out `SparseSet<Entity, T>` and indeed
that is slightly faster under ideal conditions. However,
`PassHashMap<Entity, T>` has better worst case performance when data is
randomly distributed, rather than in sorted render order, and does not
have the worst case memory usage that `SparseSet`'s dense `Vec<usize>`
that maps from the `Entity` index to sparse index into `Vec<T>`. This
dense `Vec` has to be as large as the largest Entity index used with the
`SparseSet`.
- I also tested `PassHashMap<u32, T>`, intending to use `Entity.index()`
as the key, but this proved to sometimes be slower and mostly no
different.
- The only outstanding approach that has not been implemented and tested
is to _not_ clear the render world of its entities each frame. That has
its own problems, though they could perhaps be solved.
- Performance-wise, if the entities and their component data were not
cleared, then they would incur table moves on spawn, and should not
thereafter, rather just their component data would be overwritten.
Ideally we would have a neat way of either updating data in-place via
`&mut T` queries, or inserting components if not present. This would
likely be quite cumbersome to have to remember to do everywhere, but
perhaps it only needs to be done in the more performance-sensitive
systems.
- The main problem to solve however is that we want to both maintain a
mapping between main world entities and render world entities, be able
to run the render app and world in parallel with the main app and world
for pipelined rendering, and at the same time be able to spawn entities
in the render world in such a way that those Entity ids do not collide
with those spawned in the main world. This is potentially quite
solvable, but could well be a lot of ECS work to do it in a way that
makes sense.
---
## Changelog
- Changed: Component data for entities to be drawn are no longer stored
on entities in the render world. Instead, data is stored in a
`EntityHashMap<Entity, T>` in various resources. This brings significant
performance benefits due to the way the render app clears entities every
frame. Resources of most interest are `RenderMeshInstances` and
`RenderMaterialInstances`, and their 2D counterparts.
## Migration Guide
Previously the render app extracted mesh entities and their component
data from the main world and stored them as entities and components in
the render world. Now they are extracted into essentially
`EntityHashMap<Entity, T>` where `T` are structs containing an
appropriate group of data. This means that while extract set systems
will continue to run extract queries against the main world they will
store their data in hash maps. Also, systems in later sets will either
need to look up entities in the available resources such as
`RenderMeshInstances`, or maintain their own `EntityHashMap<Entity, T>`
for their own data.
Before:
```rust
fn queue_custom(
material_meshes: Query<(Entity, &MeshTransforms, &Handle<Mesh>), With<InstanceMaterialData>>,
) {
...
for (entity, mesh_transforms, mesh_handle) in &material_meshes {
...
}
}
```
After:
```rust
fn queue_custom(
render_mesh_instances: Res<RenderMeshInstances>,
instance_entities: Query<Entity, With<InstanceMaterialData>>,
) {
...
for entity in &instance_entities {
let Some(mesh_instance) = render_mesh_instances.get(&entity) else { continue; };
// The mesh handle in `AssetId<Mesh>` form, and the `MeshTransforms` can now
// be found in `mesh_instance` which is a `RenderMeshInstance`
...
}
}
```
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
# Objective
This is a minimally disruptive version of #8340. I attempted to update
it, but failed due to the scope of the changes added in #8204.
Fixes#8307. Partially addresses #4642. As seen in
https://github.com/bevyengine/bevy/issues/8284, we're actually copying
data twice in Prepare stage systems. Once into a CPU-side intermediate
scratch buffer, and once again into a mapped buffer. This is inefficient
and effectively doubles the time spent and memory allocated to run these
systems.
## Solution
Skip the scratch buffer entirely and use
`wgpu::Queue::write_buffer_with` to directly write data into mapped
buffers.
Separately, this also directly uses
`wgpu::Limits::min_uniform_buffer_offset_alignment` to set up the
alignment when writing to the buffers. Partially addressing the issue
raised in #4642.
Storage buffers and the abstractions built on top of
`DynamicUniformBuffer` will need to come in followup PRs.
This may not have a noticeable performance difference in this PR, as the
only first-party systems affected by this are view related, and likely
are not going to be particularly heavy.
---
## Changelog
Added: `DynamicUniformBuffer::get_writer`.
Added: `DynamicUniformBufferWriter`.
# Objective
mesh.rs is infamously large. We could split off unrelated code.
## Solution
Morph targets are very similar to skinning and have their own module. We
move skinned meshes to an independent module like morph targets and give
the systems similar names.
### Open questions
Should the skinning systems and structs stay public?
---
## Migration Guide
Renamed skinning systems, resources and components:
- extract_skinned_meshes -> extract_skins
- prepare_skinned_meshes -> prepare_skins
- SkinnedMeshUniform -> SkinUniform
- SkinnedMeshJoints -> SkinIndex
---------
Co-authored-by: François <mockersf@gmail.com>
Co-authored-by: vero <email@atlasdostal.com>
# Objective
- Implement the foundations of automatic batching/instancing of draw
commands as the next step from #89
- NOTE: More performance improvements will come when more data is
managed and bound in ways that do not require rebinding such as mesh,
material, and texture data.
## Solution
- The core idea for batching of draw commands is to check whether any of
the information that has to be passed when encoding a draw command
changes between two things that are being drawn according to the sorted
render phase order. These should be things like the pipeline, bind
groups and their dynamic offsets, index/vertex buffers, and so on.
- The following assumptions have been made:
- Only entities with prepared assets (pipelines, materials, meshes) are
queued to phases
- View bindings are constant across a phase for a given draw function as
phases are per-view
- `batch_and_prepare_render_phase` is the only system that performs this
batching and has sole responsibility for preparing the per-object data.
As such the mesh binding and dynamic offsets are assumed to only vary as
a result of the `batch_and_prepare_render_phase` system, e.g. due to
having to split data across separate uniform bindings within the same
buffer due to the maximum uniform buffer binding size.
- Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform
in arrays in GPU buffers rather than each one being at a dynamic offset
in a uniform buffer. This is the same optimisation that was made for 3D
not long ago.
- Change batch size for a range in `PhaseItem`, adding API for getting
or mutating the range. This is more flexible than a size as the length
of the range can be used in place of the size, but the start and end can
be otherwise whatever is needed.
- Add an optional mesh bind group dynamic offset to `PhaseItem`. This
avoids having to do a massive table move just to insert
`GpuArrayBufferIndex` components.
## Benchmarks
All tests have been run on an M1 Max on AC power. `bevymark` and
`many_cubes` were modified to use 1920x1080 with a scale factor of 1. I
run a script that runs a separate Tracy capture process, and then runs
the bevy example with `--features bevy_ci_testing,trace_tracy` and
`CI_TESTING_CONFIG=../benchmark.ron` with the contents of
`../benchmark.ron`:
```rust
(
exit_after: Some(1500)
)
```
...in order to run each test for 1500 frames.
The recent changes to `many_cubes` and `bevymark` added reproducible
random number generation so that with the same settings, the same rng
will occur. They also added benchmark modes that use a fixed delta time
for animations. Combined this means that the same frames should be
rendered both on main and on the branch.
The graphs compare main (yellow) to this PR (red).
### 3D Mesh `many_cubes --benchmark`
<img width="1411" alt="Screenshot 2023-09-03 at 23 42 10"
src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4">
The mesh and material are the same for all instances. This is basically
the best case for the initial batching implementation as it results in 1
draw for the ~11.7k visible meshes. It gives a ~30% reduction in median
frame time.
The 1000th frame is identical using the flip tool:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4615 seconds
```
### 3D Mesh `many_cubes --benchmark --material-texture-count 10`
<img width="1404" alt="Screenshot 2023-09-03 at 23 45 18"
src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf">
This run uses 10 different materials by varying their textures. The
materials are randomly selected, and there is no sorting by material
bind group for opaque 3D so any batching is 'random'. The PR produces a
~5% reduction in median frame time. If we were to sort the opaque phase
by the material bind group, then this should be a lot faster. This
produces about 10.5k draws for the 11.7k visible entities. This makes
sense as randomly selecting from 10 materials gives a chance that two
adjacent entities randomly select the same material and can be batched.
The 1000th frame is identical in flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4537 seconds
```
### 3D Mesh `many_cubes --benchmark --vary-per-instance`
<img width="1394" alt="Screenshot 2023-09-03 at 23 48 44"
src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f">
This run varies the material data per instance by randomly-generating
its colour. This is the worst case for batching and that it performs
about the same as `main` is a good thing as it demonstrates that the
batching has minimal overhead when dealing with ~11k visible mesh
entities.
The 1000th frame is identical according to flip:

```
Mean: 0.000000
Weighted median: 0.000000
1st weighted quartile: 0.000000
3rd weighted quartile: 0.000000
Min: 0.000000
Max: 0.000000
Evaluation time: 0.4568 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d`
<img width="1412" alt="Screenshot 2023-09-03 at 23 59 56"
src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4">
This spawns 160 waves of 1000 quad meshes that are shaded with
ColorMaterial. Each wave has a different material so 160 waves currently
should result in 160 batches. This results in a 50% reduction in median
frame time.
Capturing a screenshot of the 1000th frame main vs PR gives:

```
Mean: 0.001222
Weighted median: 0.750432
1st weighted quartile: 0.453494
3rd weighted quartile: 0.969758
Min: 0.000000
Max: 0.990296
Evaluation time: 0.4255 seconds
```
So they seem to produce the same results. I also double-checked the
number of draws. `main` does 160000 draws, and the PR does 160, as
expected.
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --material-texture-count 10`
<img width="1392" alt="Screenshot 2023-09-04 at 00 09 22"
src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c">
This generates 10 textures and generates materials for each of those and
then selects one material per wave. The median frame time is reduced by
50%. Similar to the plain run above, this produces 160 draws on the PR
and 160000 on `main` and the 1000th frame is identical (ignoring the fps
counter text overlay).

```
Mean: 0.002877
Weighted median: 0.964980
1st weighted quartile: 0.668871
3rd weighted quartile: 0.982749
Min: 0.000000
Max: 0.992377
Evaluation time: 0.4301 seconds
```
### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode
mesh2d --vary-per-instance`
<img width="1396" alt="Screenshot 2023-09-04 at 00 13 53"
src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb">
This creates unique materials per instance by randomly-generating the
material's colour. This is the worst case for 2D batching. Somehow, this
PR manages a 7% reduction in median frame time. Both main and this PR
issue 160000 draws.
The 1000th frame is the same:

```
Mean: 0.001214
Weighted median: 0.937499
1st weighted quartile: 0.635467
3rd weighted quartile: 0.979085
Min: 0.000000
Max: 0.988971
Evaluation time: 0.4462 seconds
```
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite`
<img width="1396" alt="Screenshot 2023-09-04 at 12 21 12"
src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43">
This just spawns 160 waves of 1000 sprites. There should be and is no
notable difference between main and the PR.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --material-texture-count 10`
<img width="1389" alt="Screenshot 2023-09-04 at 12 36 08"
src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413">
This spawns the sprites selecting a texture at random per instance from
the 10 generated textures. This has no significant change vs main and
shouldn't.
### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode
sprite --vary-per-instance`
<img width="1401" alt="Screenshot 2023-09-04 at 12 29 52"
src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6">
This sets the sprite colour as being unique per instance. This can still
all be drawn using one batch. There should be no difference but the PR
produces median frame times that are 4% higher. Investigation showed no
clear sources of cost, rather a mix of give and take that should not
happen. It seems like noise in the results.
### Summary
| Benchmark | % change in median frame time |
| ------------- | ------------- |
| many_cubes | 🟩 -30% |
| many_cubes 10 materials | 🟩 -5% |
| many_cubes unique materials | 🟩 ~0% |
| bevymark mesh2d | 🟩 -50% |
| bevymark mesh2d 10 materials | 🟩 -50% |
| bevymark mesh2d unique materials | 🟩 -7% |
| bevymark sprite | 🟥 2% |
| bevymark sprite 10 materials | 🟥 0.6% |
| bevymark sprite unique materials | 🟥 4.1% |
---
## Changelog
- Added: 2D and 3D mesh entities that share the same mesh and material
(same textures, same data) are now batched into the same draw command
for better performance.
---------
Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com>
Co-authored-by: Nicola Papale <nico@nicopap.ch>
# Objective
Some rendering system did heavy use of `if let`, and could be improved
by using `let else`.
## Solution
- Reduce rightward drift by using let-else over if-let
- Extract value-to-key mappings to their own functions so that the
system is less bloated, easier to understand
- Use a `let` binding instead of untupling in closure argument to reduce
indentation
## Note to reviewers
Enable the "no white space diff" for easier viewing.
In the "Files changed" view, click on the little cog right of the "Jump
to" text, on the row where the "Review changes" button is. then enable
the "Hide whitespace" checkbox and click reload.
# Objective
Fix a typo introduced by #9497. While drafting the PR, the type was
originally called `VisibleInHierarchy` before I renamed it to
`InheritedVisibility`, but this field got left behind due to a typo.
# Objective
- When adding/removing bindings in large binding lists, git would
generate very difficult-to-read diffs
## Solution
- Move the `@group(X) @binding(Y)` into the same line as the binding
type declaration
# Objective
Replace instances of
```rust
for x in collection.iter{_mut}() {
```
with
```rust
for x in &{mut} collection {
```
This also changes CI to no longer suppress this lint. Note that since
this lint only shows up when using clippy in pedantic mode, it was
probably unnecessary to suppress this lint in the first place.
# Objective
- Fixes#6662
- Wireframe crash for skinned meshes:
```
wgpu error: Validation Error
Caused by:
In Device::create_render_pipeline
note: label = `opaque_mesh_pipeline`
Error matching ShaderStages(VERTEX) shader requirements against the pipeline
Location[4] Uint32x4 interpolated as Some(Flat) with sampling None is not provided by the previous stage outputs
Input is not provided by the earlier stage in the pipeline
```
- Wireframe crash for morphed meshes:
```
wgpu error: Validation Error
Caused by:
In a RenderPass
note: encoder = `<CommandBuffer-(0, 14, Metal)>`
In a draw command, indexed:true indirect:false
note: render pipeline = `opaque_mesh_pipeline`
The pipeline layout, associated with the current render pipeline, contains a bind group layout at index 1 which is incompatible with the bind group layout associated with the bind group at 1
```
## Solution
- Fix the locations for skinned meshes in the wireframe shader
- Add the morph key to the wireframe specialisation key
- Morph the vertex in the wireframe shader
https://github.com/bevyengine/bevy/assets/8672791/ce0a9584-bd28-4d74-9c3f-256602e6fac5