# Objective
Documentation should no longer be using pre-stageless terminology to
avoid confusion.
## Solution
- update all docs referring to stages to instead refer to sets/schedules
where appropriate
- also mention `apply_system_buffers` for anything system-buffer-related
that previously referred to buffers being applied "at the end of a
stage"
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/7990.
## Solution
- Register needed types, verified pasted code in issue works.
Do I need to register more `Option<T>` types?
# Objective
Fixes#7989
Based on #7991 by @CoffeeVampir3
## Solution
There were three parts to this issue:
1. `extend_where_clause` did not account for the optionality of a where
clause's trailing comma
```rust
// OKAY
struct Foo<T> where T: Asset, {/* ... */}
// ERROR
struct Foo<T> where T: Asset {/* ... */}
```
2. `FromReflect` derive logic was not actively using
`extend_where_clause` which led to some inconsistencies (enums weren't
adding _any_ additional bounds even)
3. Using `extend_where_clause` in the `FromReflect` derive logic meant
we had to optionally add `Default` bounds to ignored fields iff the
entire item itself was not already `Default` (otherwise the definition
for `Handle<T>` wouldn't compile since `HandleType` doesn't impl
`Default` but `Handle<T>` itself does)
---
## Changelog
- Fixed issue where a missing trailing comma could break the reflection
derives
- Fixes#7965
- Code quality improvements.
- Removes the unreferenced function `dither` in pbr_functions.wgsl
introduced in 72fbcc7, but made obsolete in c069c54.
- Makes the reference to `screen_space_dither` in pbr.wgsl conditional
on `#ifdef TONEMAP_IN_SHADER`, as the required import is conditional on
the same, as deband dithering can only occur if tonemapping is also
occurring.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- `Sprite` components are not included in scene (de)serialization.
- Fixes#8206
## Solution
- Add `#[reflect(Component, Default)]` to `Sprite`
- Add `#[derive(FromReflect)]` to `Sprite` and `Anchor`
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Bevy with
```
default-features = false
features = [
"trace_tracy"
]
```
will fail due to `error: The platform you're compiling for is not
supported by winit`
## Solution
- Make bevy_winit/trace optional in trace feature
# Objective
`Or<T>` should be a new type of `PhantomData<T>` instead of `T`.
## Solution
Make `Or<T>` a new type of `PhantomData<T>`.
## Migration Guide
`Or<T>` is just used as a type annotation and shouldn't be constructed.
A `RegularPolygon` is described by the circumscribed radius, not the
inscribed radius.
## Objective
- Correct documentation for `RegularPolygon`
## Solution
- Use the correct term
---------
Co-authored-by: Paul Hüber <phueber@kernsp.in>
Co-authored-by: Alice Cecile <alice.i.cecile@gmail.com>
# Objective
When using the `#[derive(WorldQuery)]` macro, the `ReadOnly` struct
generated has default (private) visibility for each field, regardless of
the visibility of the original field.
## Solution
For each field of a read-only `WorldQuery` variant, use the visibility
of the associated field defined on the original struct.
# Objective
Fix#1727Fix#8010
Meta types generated by the `SystemParam` and `WorldQuery` derive macros
can conflict with user-defined types if they happen to have the same
name.
## Solution
In order to check if an identifier would conflict with user-defined
types, we can just search the original `TokenStream` passed to the macro
to see if it contains the identifier (since the meta types are defined
in an anonymous scope, it's only possible for them to conflict with the
struct definition itself). When generating an identifier for meta types,
we can simply check if it would conflict, and then add additional
characters to the name until it no longer conflicts with anything.
The `WorldQuery` "Item" and read-only structs are a part of a module's
public API, and thus it is intended for them to conflict with
user-defined types.
# Objective
The function `assert_is_system` is used in documentation tests to ensure
that example code actually produces valid systems. Currently,
`assert_is_system` just checks that each function parameter implements
`SystemParam`. To further check the validity of the system, we should
initialize the passed system so that it will be checked for conflicting
accesses. Not only does this enforce the validity of our examples, but
it provides a convenient way to demonstrate conflicting accesses via a
`should_panic` example, which is nicely rendered by rustdoc:
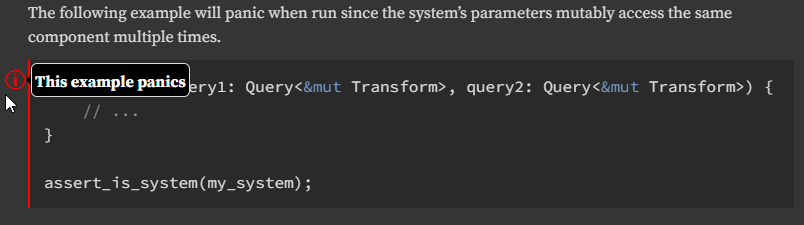
## Solution
Initialize the system with an empty world to trigger its internal access
conflict checks.
---
## Changelog
The function `bevy::ecs::system::assert_is_system` now panics when
passed a system with conflicting world accesses, as does
`assert_is_read_only_system`.
## Migration Guide
The functions `assert_is_system` and `assert_is_read_only_system` (in
`bevy_ecs::system`) now panic if the passed system has invalid world
accesses. Any tests that called this function on a system with invalid
accesses will now fail. Either fix the system's conflicting accesses, or
specify that the test is meant to fail:
1. For regular tests (that is, functions annotated with `#[test]`), add
the `#[should_panic]` attribute to the function.
2. For documentation tests, add `should_panic` to the start of the code
block: ` ```should_panic`
# Objective
We're currently using an unconditional `unwrap` in multiple locations
when inserting bundles into an entity when we know it will never fail.
This adds a large amount of extra branching that could be avoided on in
release builds.
## Solution
Use `DebugCheckedUnwrap` in bundle insertion code where relevant. Add
and update the safety comments to match.
This should remove the panicking branches from release builds, which has
a significant impact on the generated code:
https://github.com/james7132/bevy_asm_tests/compare/less-panicking-bundles#diff-e55a27cfb1615846ed3b6472f15a1aed66ed394d3d0739b3117f95cf90f46951R2086
shows about a 10% reduction in the number of generated instructions for
`EntityMut::insert`, `EntityMut::remove`, `EntityMut::take`, and related
functions.
---------
Co-authored-by: JoJoJet <21144246+JoJoJet@users.noreply.github.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Currently, the render graph slots are only used to pass the
view_entity around. This introduces significant boilerplate for very
little value. Instead of using slots for this, make the view_entity part
of the `RenderGraphContext`. This also means we won't need to have
`IN_VIEW` on every node and and we'll be able to use the default impl of
`Node::input()`.
## Solution
- Add `view_entity: Option<Entity>` to the `RenderGraphContext`
- Update all nodes to use this instead of entity slot input
---
## Changelog
- Add optional `view_entity` to `RenderGraphContext`
## Migration Guide
You can now get the view_entity directly from the `RenderGraphContext`.
When implementing the Node:
```rust
// 0.10
struct FooNode;
impl FooNode {
const IN_VIEW: &'static str = "view";
}
impl Node for FooNode {
fn input(&self) -> Vec<SlotInfo> {
vec![SlotInfo::new(Self::IN_VIEW, SlotType::Entity)]
}
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.get_input_entity(Self::IN_VIEW)?;
// ...
Ok(())
}
}
// 0.11
struct FooNode;
impl Node for FooNode {
fn run(
&self,
graph: &mut RenderGraphContext,
// ...
) -> Result<(), NodeRunError> {
let view_entity = graph.view_entity();
// ...
Ok(())
}
}
```
When adding the node to the graph, you don't need to specify a slot_edge
for the view_entity.
```rust
// 0.10
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
let input_node_id = draw_2d_graph.set_input(vec![SlotInfo::new(
graph::input::VIEW_ENTITY,
SlotType::Entity,
)]);
graph.add_slot_edge(
input_node_id,
graph::input::VIEW_ENTITY,
FooNode::NAME,
FooNode::IN_VIEW,
);
// add_node_edge ...
// 0.11
let mut graph = RenderGraph::default();
graph.add_node(FooNode::NAME, node);
// add_node_edge ...
```
## Notes
This PR paired with #8007 will help reduce a lot of annoying boilerplate
with the render nodes. Depending on which one gets merged first. It will
require a bit of clean up work to make both compatible.
I tagged this as a breaking change, because using the old system to get
the view_entity will break things because it's not a node input slot
anymore.
## Notes for reviewers
A lot of the diffs are just removing the slots in every nodes and graph
creation. The important part is mostly in the
graph_runner/CameraDriverNode.
# Objective
Add viewport variants to `Val` that specify a percentage length based on
the size of the window.
## Solution
Add the variants `Vw`, `Vh`, `VMin` and `VMax` to `Val`.
Add a physical window size parameter to the `from_style` function and
use it to convert the viewport variants to Taffy Points values.
One issue: It isn't responsive to window resizes. So `flex_node_system`
has to do a full update every time the window size changes. Perhaps this
can be fixed with support from Taffy.
---
## Changelog
* Added `Val` viewport unit variants `Vw`, `Vh`, `VMin` and `VMax`.
* Modified `convert` module to support the new `Val` variants.
* Changed `flex_node_system` to support the new `Val` variants.
* Perform full layout update on screen resizing, to propagate the new
viewport size to all nodes.
This MR is a rebased and alternative proposal to
https://github.com/bevyengine/bevy/pull/5602
# Objective
- https://github.com/bevyengine/bevy/pull/4447 implemented untyped
(using component ids instead of generics and TypeId) APIs for
inserting/accessing resources and accessing components, but left
inserting components for another PR (this one)
## Solution
- add `EntityMut::insert_by_id`
- split `Bundle` into `DynamicBundle` with `get_components` and `Bundle:
DynamicBundle`. This allows the `BundleInserter` machinery to be reused
for bundles that can only be written, not read, and have no statically
available `ComponentIds`
- Compared to the original MR this approach exposes unsafe endpoints and
requires the user to manage instantiated `BundleIds`. This is quite easy
for the end user to do and does not incur the performance penalty of
checking whether component input is correctly provided for the
`BundleId`.
- This MR does ensure that constructing `BundleId` itself is safe
---
## Changelog
- add methods for inserting bundles and components to:
`world.entity_mut(entity).insert_by_id`
# Objective
Add comments explaining:
* That `Val::Px` is a value in logical pixels
* That `Val::Percent` is based on the length of its parent along a
specific axis.
* How the layout algorithm determines which axis the percentage should
be based on.
# Objective
Co-Authored-By: davier
[bricedavier@gmail.com](mailto:bricedavier@gmail.com)
Fixes#3576.
Adds a `resources` field in scene serialization data to allow
de/serializing resources that have reflection enabled.
## Solution
Most of this code is taken from a previous closed PR:
https://github.com/bevyengine/bevy/pull/3580. Most of the credit goes to
@Davier , what I did was mostly getting it to work on the latest main
branch of Bevy, along with adding a few asserts in the currently
existing tests to be sure everything is working properly.
This PR changes the scene format to include resources in this way:
```
(
resources: {
// List of resources here, keyed by resource type name.
},
entities: [
// Previous scene format here
],
)
```
An example taken from the tests:
```
(
resources: {
"bevy_scene::serde::tests::MyResource": (
foo: 123,
),
},
entities: {
// Previous scene format here
},
)
```
For this, a `resources` fields has been added on the `DynamicScene` and
the `DynamicSceneBuilder` structs. The latter now also has a method
named `extract_resources` to properly extract the existing resources
registered in the local type registry, in a similar way to
`extract_entities`.
---
## Changelog
Added: Reflect resources registered in the type registry used by dynamic
scenes will now be properly de/serialized in scene data.
## Migration Guide
Since the scene format has been changed, the user may not be able to use
scenes saved prior to this PR due to the `resources` scene field being
missing. ~~To preserve backwards compatibility, I will try to make the
`resources` fully optional so that old scenes can be loaded without
issue.~~
## TODOs
- [x] I may have to update a few doc blocks still referring to dynamic
scenes as mere container of entities, since they now include resources
as well.
- [x] ~~I want to make the `resources` key optional, as specified in the
Migration Guide, so that old scenes will be compatible with this
change.~~ Since this would only be trivial for ron format, I think it
might be better to consider it in a separate PR/discussion to figure out
if it could be done for binary serialization too.
- [x] I suppose it might be a good idea to add a resources in the scene
example so that users will quickly notice they can serialize resources
just like entities.
---------
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
Add a convenient immediate mode drawing API for visual debugging.
Fixes#5619
Alternative to #1625
Partial alternative to #5734
Based off https://github.com/Toqozz/bevy_debug_lines with some changes:
* Simultaneous support for 2D and 3D.
* Methods for basic shapes; circles, spheres, rectangles, boxes, etc.
* 2D methods.
* Removed durations. Seemed niche, and can be handled by users.
<details>
<summary>Performance</summary>
Stress tested using Bevy's recommended optimization settings for the dev
profile with the
following command.
```bash
cargo run --example many_debug_lines \
--config "profile.dev.package.\"*\".opt-level=3" \
--config "profile.dev.opt-level=1"
```
I dipped to 65-70 FPS at 300,000 lines
CPU: 3700x
RAM Speed: 3200 Mhz
GPU: 2070 super - probably not very relevant, mostly cpu/memory bound
</details>
<details>
<summary>Fancy bloom screenshot</summary>
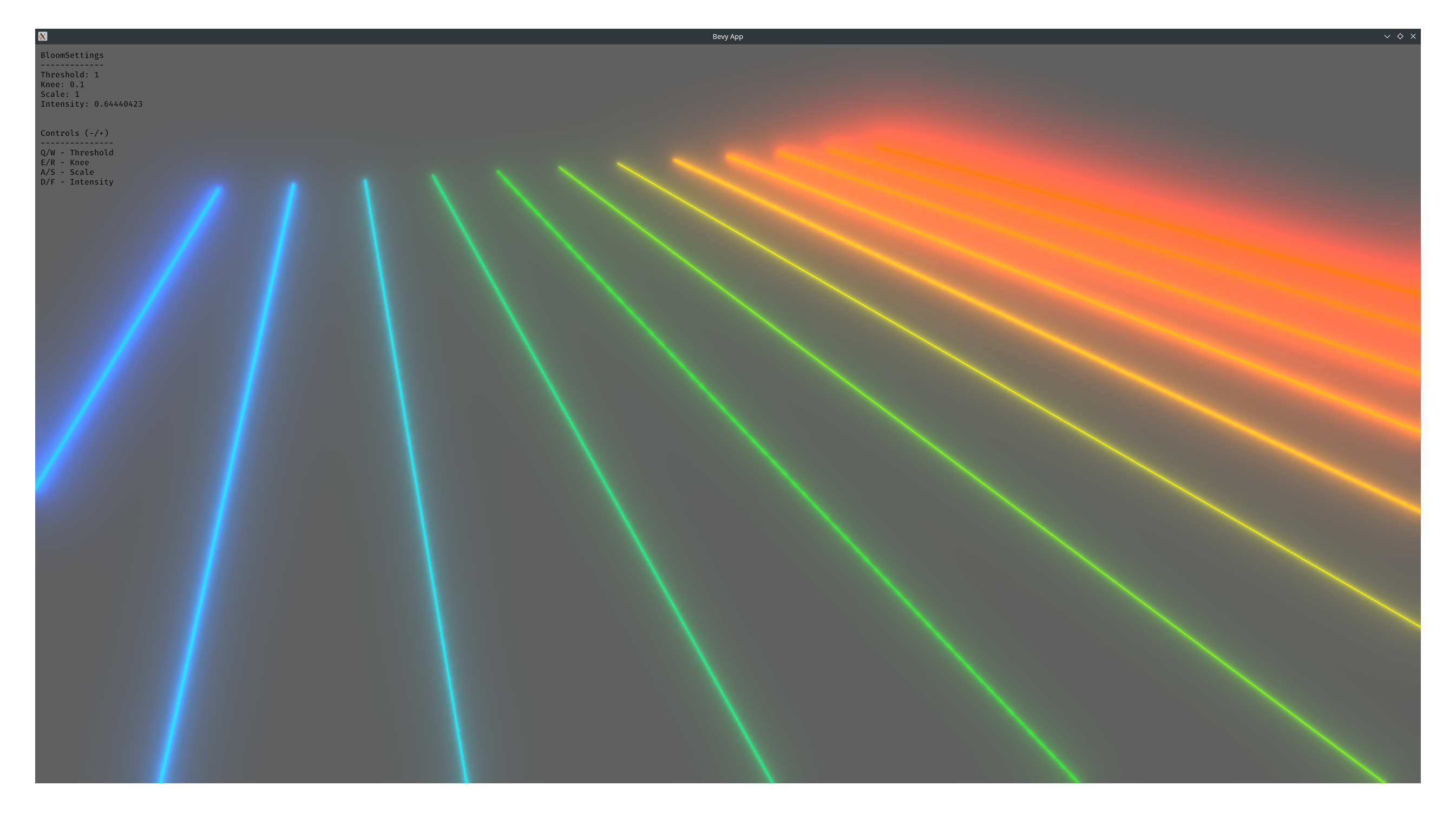
</details>
## Changelog
* Added `GizmoPlugin`
* Added `Gizmos` system parameter for drawing lines and wireshapes.
### TODO
- [ ] Update changelog
- [x] Update performance numbers
- [x] Add credit to PR description
### Future work
- Cache rendering primitives instead of constructing them out of line
segments each frame.
- Support for drawing solid meshes
- Interactions. (See
[bevy_mod_gizmos](https://github.com/LiamGallagher737/bevy_mod_gizmos))
- Fancier line drawing. (See
[bevy_polyline](https://github.com/ForesightMiningSoftwareCorporation/bevy_polyline))
- Support for `RenderLayers`
- Display gizmos for a certain duration. Currently everything displays
for one frame (ie. immediate mode)
- Changing settings per drawn item like drawing on top or drawing to
different `RenderLayers`
Co-Authored By: @lassade <felipe.jorge.pereira@gmail.com>
Co-Authored By: @The5-1 <agaku@hotmail.de>
Co-Authored By: @Toqozz <toqoz@hotmail.com>
Co-Authored By: @nicopap <nico@nicopap.ch>
---------
Co-authored-by: Robert Swain <robert.swain@gmail.com>
Co-authored-by: IceSentry <c.giguere42@gmail.com>
Co-authored-by: Carter Anderson <mcanders1@gmail.com>
# Objective
- Fixes https://github.com/bevyengine/bevy/issues/6760
- adds line and position on line info to scene errors
```text
Before:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)`
After:
2023-03-12T22:38:59.103220Z WARN bevy_asset::asset_server: encountered an error while loading an asset: Expected closing `)` at scenes/test/scene.scn.ron:10:4
```
## Solution
- use span_error to get position info. This is what the ron crate does
internally to get the position info.
562963f887/src/options.rs (L158)
## Changelog
- added line numbers to scene errors
---------
Co-authored-by: Paul Hansen <mail@paul.rs>
# Objective
- @mockersf identified a performance regression of about 25% longer frame times introduced by #7784 in a complex scene with the Amazon Lumberyard bistro scene with both exterior and interior variants and a number of point lights with shadow mapping enabled
- The additional time seemed to be spent in the `ShadowPassNode`
- `ShadowPassNode` encodes the draw commands for the shadow phase. Roughly the same numbers of entities were having draw commands encoded, so something about the way they were being encoded had changed.
- One thing that definitely changed was that the pipeline used will be different depending on the alpha mode, and the scene has lots entities with opaque and blend materials. This suggested that maybe the pipeline was changing a lot so I tried a quick hack to see if it was the problem.
## Solution
- Sort the shadow phase items by their pipeline id
- This groups phase items by their pipeline id, which significantly reduces pipeline rebinding required to the point that the performance regression was gone.
# Objective
- Currently, https://github.com/vleue/bevy_bistro_playground crashes when enabling shadows, because this allocates a new buffer for the view uniforms, but the `TonemappingNode` uses a cached bind group that doesn't reference the new uniform buffer.
## Solution
- Check if the buffer id of the view uniforms buffer has changed and create a new bind group if it did.
# Objective
Fixes#7757
New function `Color::as_lcha` was added and `Color::as_lch_f32` changed name to `Color::as_lcha_f32`.
----
As a side note I did it as in every other Color function, that is I created very simillar code in `as_lcha` as was in `as_lcha_f32`. However it is totally possible to avoid this code duplication in LCHA and other color variants by doing something like :
```
pub fn as_lcha(self: &Color) -> Color {
let (lightness, chroma, hue, alpha) = self.as_lcha_f32();
return Color::Lcha { lightness, chroma, hue, alpha };
}
```
This is maybe slightly less efficient but it avoids copy-pasting this huge match expression which is error prone. Anyways since it is my first commit here I wanted to be consistent with the rest of code but can refactor all variants in separate PR if somebody thinks it is good idea.
# Objective
revert combining pipelines for AlphaMode::Blend and AlphaMode::Premultiplied & Add
the recent blend state pr changed `AlphaMode::Blend` to use a blend state of `Blend::PREMULTIPLIED_ALPHA_BLENDING`, and recovered the original behaviour by multiplying colour by alpha in the standard material's fragment shader.
this had some advantages (specifically it means more material instances can be batched together in future), but this also means that custom materials that specify `AlphaMode::Blend` now get a premultiplied blend state, so they must also multiply colour by alpha.
## Solution
revert that combination to preserve 0.9 behaviour for custom materials with AlphaMode::Blend.
This produces more accurate results for the `EmissiveStrengthTest` glTF test case.
(Requires manually setting the emission, for now)
Before: <img width="1392" alt="Screenshot 2023-03-04 at 18 21 25" src="https://user-images.githubusercontent.com/418473/222929455-c7363d52-7133-4d4e-9d6a-562098f6bbe8.png">
After: <img width="1392" alt="Screenshot 2023-03-04 at 18 20 57" src="https://user-images.githubusercontent.com/418473/222929454-3ea20ecb-0773-4aad-978c-3832353b6871.png">
Tagging @JMS55 as a co-author, since this fix is based on their experiments with emission.
# Objective
- Have more accurate results for the `EmissiveStrengthTest` glTF test case.
## Solution
- Make sure we send the emissive color as linear instead of sRGB.
---
## Changelog
- Emission strength is now correctly interpreted by the `StandardMaterial` as linear instead of sRGB.
## Migration Guide
- If you have previously manually specified emissive values with `Color::rgb()` and would like to retain the old visual results, you must now use `Color::rgb_linear()` instead;
- If you have previously manually specified emissive values with `Color::rgb_linear()` and would like to retain the old visual results, you'll need to apply a one-time gamma calculation to your channels manually to get the _actual_ linear RGB value:
- For channel values greater than `0.0031308`, use `(1.055 * value.powf(1.0 / 2.4)) - 0.055`;
- For channel values lower than or equal to `0.0031308`, use `value * 12.92`;
- Otherwise, the results should now be more consistent with other tools/engines.
# Objective
Current `Node` doc comment:
```rust
/// The size of the node as width and height in pixels
/// automatically calculated by [`super::flex::flex_node_system`]
```
It should be changed to make it clear that `Node` stores the size in logical pixels, not physical.
# Objective
- Example `transparent_window` doesn't display a transparent window on macOS
- Fixes#6330
## Solution
- Set the `composite_alpha_mode` of the window to the correct value
- Update docs
# Objective
Upgrade to Taffy 0.3.3
Fixes: #7712
## Solution
Upgrade to Taffy 0.3.3 with the `grid` feature disabled.
---
## Changelog
* Changed Taffy version to 0.3.3 and disabled its `grid` feature.
* Added the `Start` and `End` variants to `AlignItems`, `AlignSelf`, `AlignContent` and `JustifyContent`.
* Added the `SpaceEvenly` variant to `AlignContent`.
* Updated `from_style` for Taffy 0.3.3.
# Objective
the current depth bias only adjusts ordering, so it doesn't work for opaque meshes vs alpha-blend meshes, and it doesn't help when two meshes are infinitesimally offset from one another.
## Solution
pass the material's depth bias into the pipeline depth stencil `constant` field.
# Objective
- Fixes#7889.
## Solution
- Change the glTF loader to insert a `Camera3dBundle` instead of a manually constructed bundle. This might prevent future issues when new components are required for a 3D Camera to work correctly.
- Register the `ColorGrading` type because `bevy_scene` was complaining about it.
Huge credit to @StarLederer, who did almost all of the work on this. We're just reusing this PR to keep everything in one place.
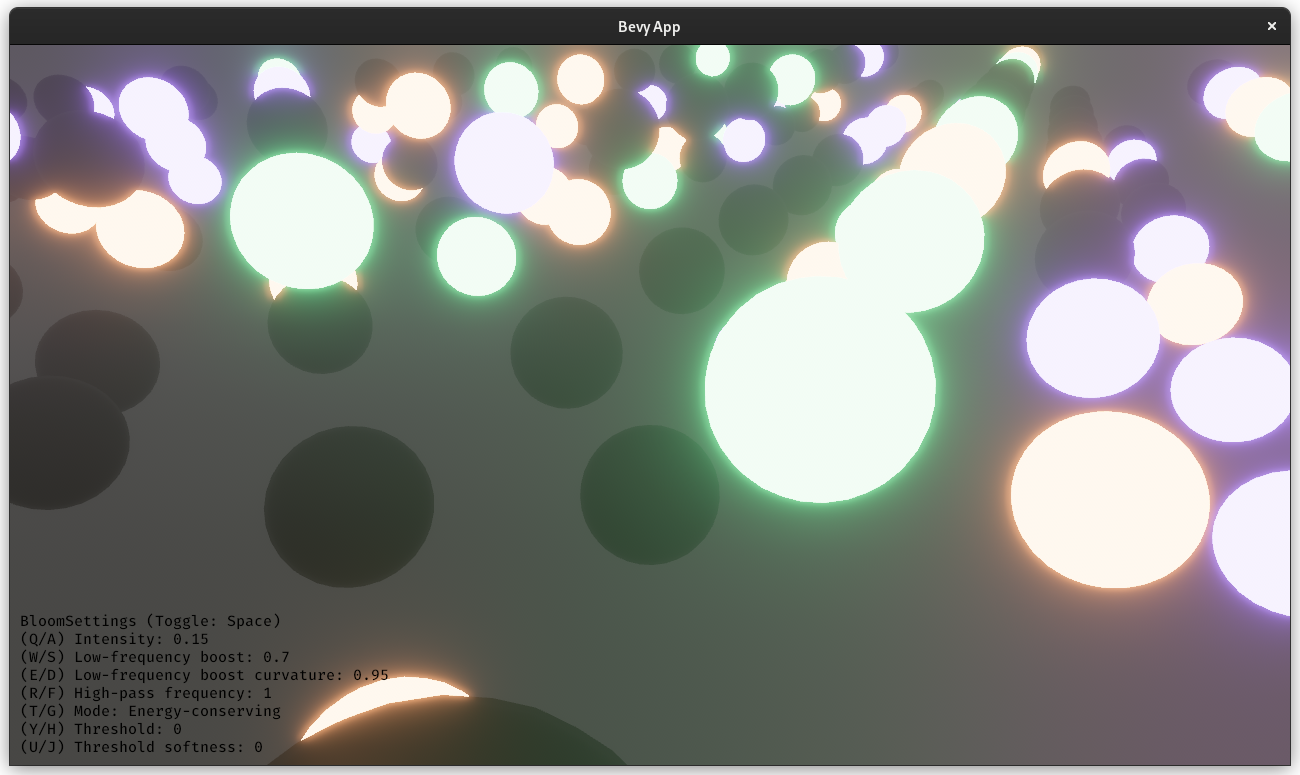
# Objective
1. Make bloom more physically based.
1. Improve artistic control.
1. Allow to use bloom as screen blur.
1. Fix#6634.
1. Address #6655 (although the author makes incorrect conclusions).
## Solution
1. Set the default threshold to 0.
2. Lerp between bloom textures when `composite_mode: BloomCompositeMode::EnergyConserving`.
1. Use [a parametric function](https://starlederer.github.io/bloom) to control blend levels for each bloom texture. In the future this can be controlled per-pixel for things like lens dirt.
3. Implement BloomCompositeMode::Additive` for situations where the old school look is desired.
## Changelog
* Bloom now looks different.
* Added `BloomSettings:lf_boost`, `BloomSettings:lf_boost_curvature`, `BloomSettings::high_pass_frequency` and `BloomSettings::composite_mode`.
* `BloomSettings::scale` removed.
* `BloomSettings::knee` renamed to `BloomPrefilterSettings::softness`.
* `BloomSettings::threshold` renamed to `BloomPrefilterSettings::threshold`.
* The bloom example has been renamed to bloom_3d and improved. A bloom_2d example was added.
## Migration Guide
* Refactor mentions of `BloomSettings::knee` and `BloomSettings::threshold` as `BloomSettings::prefilter_settings` where knee is now `softness`.
* If defined without `..default()` add `..default()` to definitions of `BloomSettings` instances or manually define missing fields.
* Adapt to Bloom looking visually different (if needed).
Co-authored-by: Herman Lederer <germans.lederers@gmail.com>
# Objective
- Update `glam` to the latest version.
## Solution
- Update `glam` to version `0.23`.
Since the breaking change in `glam` only affects the `scalar-math` feature, this should cause no issues.
# Objective
- Make cubic splines more flexible and more performant
- Remove the existing spline implementation that is generic over many degrees
- This is a potential performance footgun and adds type complexity for negligible gain.
- Add implementations of:
- Bezier splines
- Cardinal splines (inc. Catmull-Rom)
- B-Splines
- Hermite splines
https://user-images.githubusercontent.com/2632925/221780519-495d1b20-ab46-45b4-92a3-32c46da66034.mp4https://user-images.githubusercontent.com/2632925/221780524-2b154016-699f-404f-9c18-02092f589b04.mp4https://user-images.githubusercontent.com/2632925/221780525-f934f99d-9ad4-4999-bae2-75d675f5644f.mp4
## Solution
- Implements the concept that splines are curve generators (e.g. https://youtu.be/jvPPXbo87ds?t=3488) via the `CubicGenerator` trait.
- Common splines are bespoke data types that implement this trait. This gives us flexibility to add custom spline-specific methods on these types, while ultimately all generating a `CubicCurve`.
- All splines generate `CubicCurve`s, which are a chain of precomputed polynomial coefficients. This means that all splines have the same evaluation cost, as the calculations for determining position, velocity, and acceleration are all identical. In addition, `CubicCurve`s are simply a list of `CubicSegment`s, which are evaluated from t=0 to t=1. This also means cubic splines of different type can be chained together, as ultimately they all are simply a collection of `CubicSegment`s.
- Because easing is an operation on a singe segment of a Bezier curve, we can simply implement easing on `Beziers` that use the `Vec2` type for points. Higher level crates such as `bevy_ui` can wrap this in a more ergonomic interface as needed.
### Performance
Measured on a desktop i5 8600K (6-year-old CPU):
- easing: 2.7x faster (19ns)
- cubic vec2 position sample: 1.5x faster (1.8ns)
- cubic vec3 position sample: 1.5x faster (2.6ns)
- cubic vec3a position sample: 1.9x faster (1.4ns)
On a laptop i7 11800H:
- easing: 16ns
- cubic vec2 position sample: 1.6ns
- cubic vec3 position sample: 2.3ns
- cubic vec3a position sample: 1.2ns
---
## Changelog
- Added a generic cubic curve trait, and implementation for Cardinal splines (including Catmull-Rom), B-Splines, Beziers, and Hermite Splines. 2D cubic curve segments also implement easing functionality for animation.
# Objective
Unfortunately, there are three issues with my changes introduced by #7784.
1. The changes left some dead code. This is already taken care of here: #7875.
2. Disabling prepass causes failures because the shadow mapping relies on the `PrepassPlugin` now.
3. Custom materials use the `prepass.wgsl` shader, but this does not always define a fragment entry point.
This PR fixes 2. and 3. and resolves#7879.
## Solution
- Add a regression test with disabled prepass.
- Split `PrepassPlugin` into two plugins:
- `PrepassPipelinePlugin` contains the part that is required for the shadow mapping to work and is unconditionally added.
- `PrepassPlugin` now only adds the systems and resources required for the "real" prepasses.
- Add a noop fragment entry point to `prepass.wgsl`, used if `NORMAL_PASS` is not defined.
Co-authored-by: Edgar Geier <geieredgar@gmail.com>
# Objective
#7863 introduced a potential footgun. When trying to incorrectly add a user-defined type using `in_base_set`, the compiler will suggest that the user implement `BaseSystemSet` for their type. This is a reasonable-sounding suggestion, however this is not the correct way to make a base set, and will lead to a confusing panic message when a marker trait is implemented for the wrong type.
## Solution
Rewrite the documentation for these traits, making it more clear that `BaseSystemSet` is a marker for types that are already base sets, and not a way to define a base set.
# Objective
- Fixes#7874.
- The `bevy_text` dependency is optional for `bevy_ui`, but the `accessibility` module depended on it.
## Solution
- Guard the `accessibility` module behind the `bevy_text` feature and only add the plugin when it's enabled.
# Objective
- Remove dead code after #7784
# Changelog
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Migration Guide
- Removed `SetShadowViewBindGroup`, `queue_shadow_view_bind_group()`, and `LightMeta::shadow_view_bind_group` in favor of reusing the prepass view bind group.
# Objective
The trait `IntoSystemConfig<>` requires each implementer to repeat every single member method, even though they can all be implemented by just deferring to `SystemConfig`.
## Solution
Add default implementations to most member methods.
# Objective
Base sets, added in #7466 are a special type of system set. Systems can only be added to base sets via `in_base_set`, while non-base sets can only be added via `in_set`. Unfortunately this is currently guarded by a runtime panic, which presents an unfortunate toe-stub when the wrong method is used. The delayed response between writing code and encountering the error (possibly hours) makes the distinction between base sets and other sets much more difficult to learn.
## Solution
Add the marker traits `BaseSystemSet` and `FreeSystemSet`. `in_base_set` and `in_set` now respectively accept these traits, which moves the runtime panic to a compile time error.
---
## Changelog
+ Added the marker trait `BaseSystemSet`, which is distinguished from a `FreeSystemSet`. These are both subtraits of `SystemSet`.
## Migration Guide
None if merged with 0.10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}